 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Data Preconditioning for Regularized Loss Minimization
Sep 25, 2015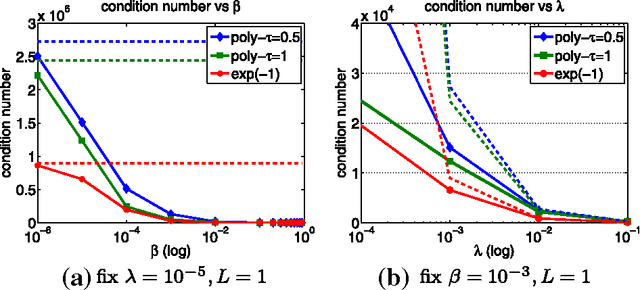
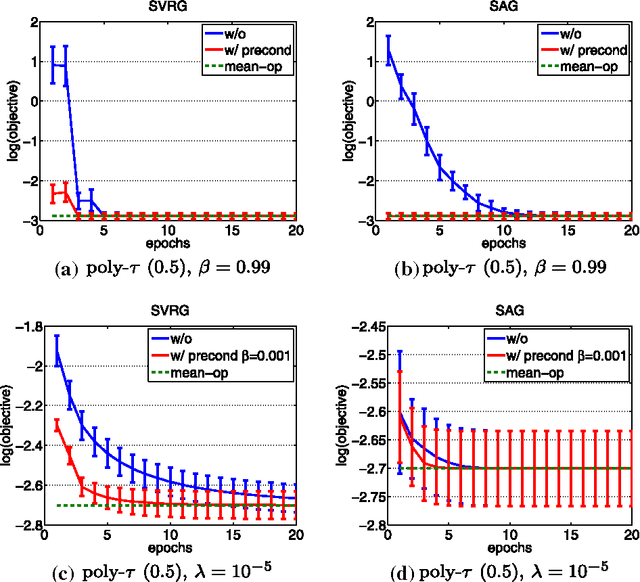

In this work, we study data preconditioning, a well-known and long-existing technique, for boosting the convergence of first-order methods for regularized loss minimization. It is well understood that the condition number of the problem, i.e., the ratio of the Lipschitz constant to the strong convexity modulus, has a harsh effect on the convergence of the first-order optimization methods. Therefore, minimizing a small regularized loss for achieving good generalization performance, yielding an ill conditioned problem, becomes the bottleneck for big data problems. We provide a theory on data preconditioning for regularized loss minimization. In particular, our analysis exhibits an appropriate data preconditioner and characterizes the conditions on the loss function and on the data under which data preconditioning can reduce the condition number and therefore boost the convergence for minimizing the regularized loss. To make the data preconditioning practically useful, we endeavor to employ and analyze a random sampling approach to efficiently compute the preconditioned data. The preliminary experiments validate our theory.
Online Stochastic Linear Optimization under One-bit Feedback
Sep 25, 2015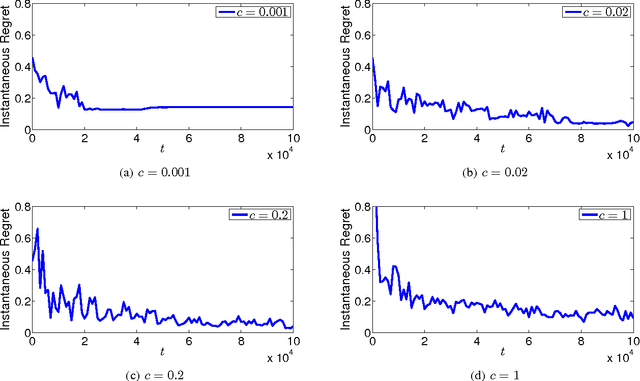
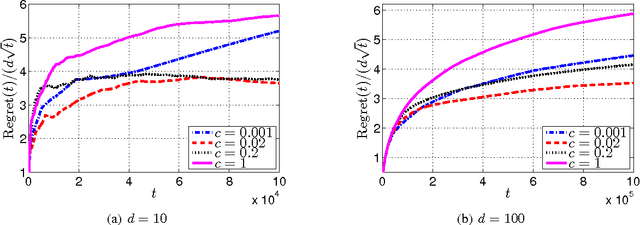
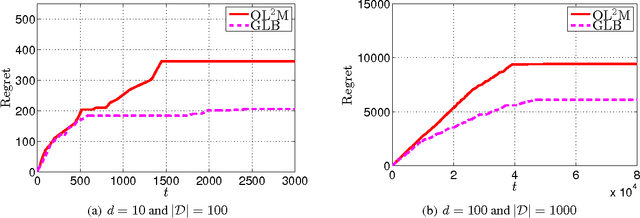
In this paper, we study a special bandit setting of online stochastic linear optimization, where only one-bit of information is revealed to the learner at each round. This problem has found many applications including online advertisement and online recommendation. We assume the binary feedback is a random variable generated from the logit model, and aim to minimize the regret defined by the unknown linear function. Although the existing method for generalized linear bandit can be applied to our problem, the high computational cost makes it impractical for real-world problems. To address this challenge, we develop an efficient online learning algorithm by exploiting particular structures of the observation model. Specifically, we adopt online Newton step to estimate the unknown parameter and derive a tight confidence region based on the exponential concavity of the logistic loss. Our analysis shows that the proposed algorithm achieves a regret bound of $O(d\sqrt{T})$, which matches the optimal result of stochastic linear bandits.
Towards Making High Dimensional Distance Metric Learning Practical
Sep 15, 2015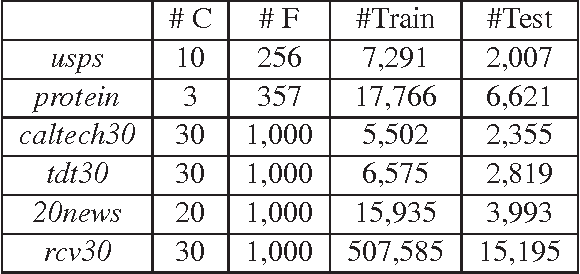
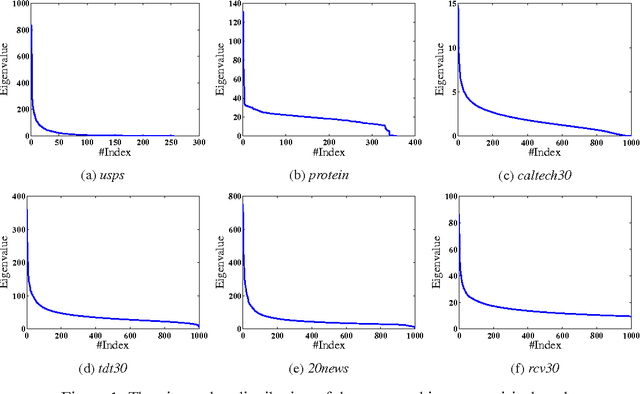
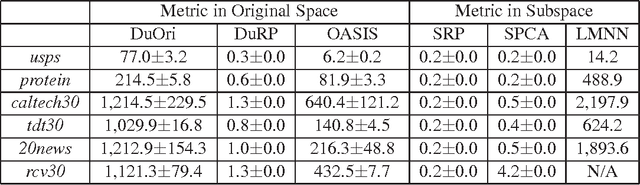
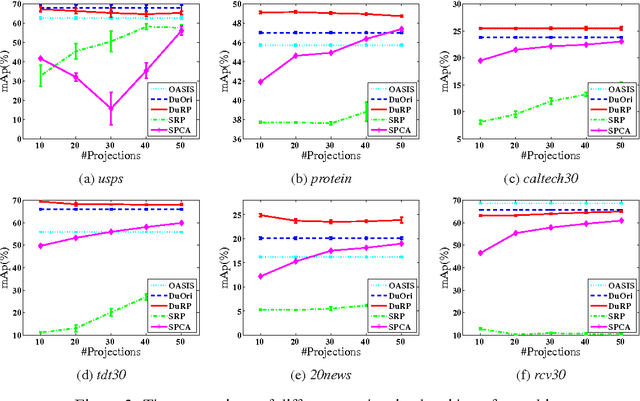
In this work, we study distance metric learning (DML) for high dimensional data. A typical approach for DML with high dimensional data is to perform the dimensionality reduction first before learning the distance metric. The main shortcoming of this approach is that it may result in a suboptimal solution due to the subspace removed by the dimensionality reduction method. In this work, we present a dual random projection frame for DML with high dimensional data that explicitly addresses the limitation of dimensionality reduction for DML. The key idea is to first project all the data points into a low dimensional space by random projection, and compute the dual variables using the projected vectors. It then reconstructs the distance metric in the original space using the estimated dual variables. The proposed method, on one hand, enjoys the light computation of random projection, and on the other hand, alleviates the limitation of most dimensionality reduction methods. We verify both empirically and theoretically the effectiveness of the proposed algorithm for high dimensional DML.
Theory of Dual-sparse Regularized Randomized Reduction
Jul 18, 2015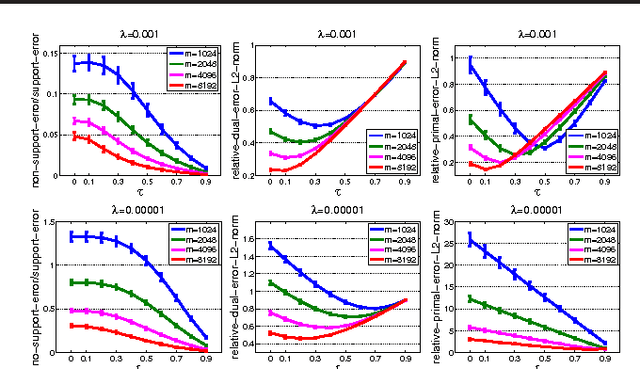

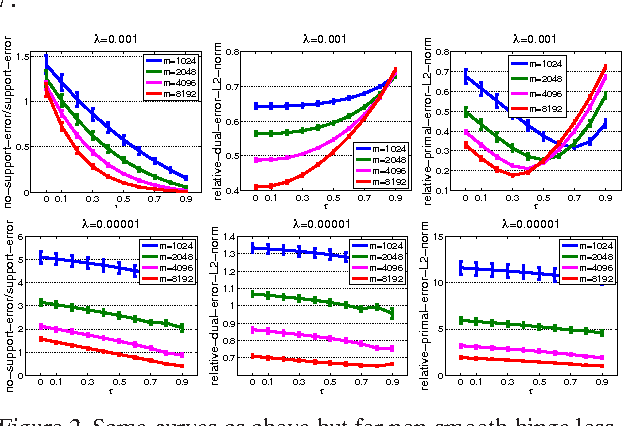
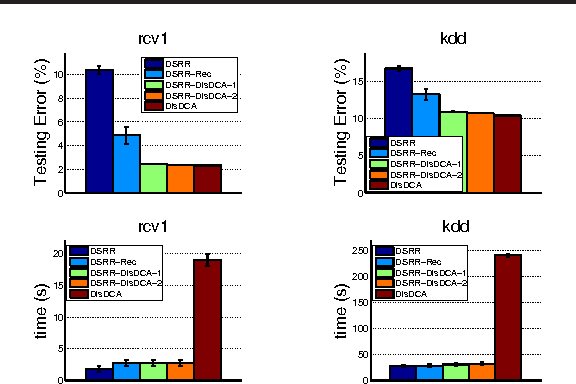
In this paper, we study randomized reduction methods, which reduce high-dimensional features into low-dimensional space by randomized methods (e.g., random projection, random hashing), for large-scale high-dimensional classification. Previous theoretical results on randomized reduction methods hinge on strong assumptions about the data, e.g., low rank of the data matrix or a large separable margin of classification, which hinder their applications in broad domains. To address these limitations, we propose dual-sparse regularized randomized reduction methods that introduce a sparse regularizer into the reduced dual problem. Under a mild condition that the original dual solution is a (nearly) sparse vector, we show that the resulting dual solution is close to the original dual solution and concentrates on its support set. In numerical experiments, we present an empirical study to support the analysis and we also present a novel application of the dual-sparse regularized randomized reduction methods to reducing the communication cost of distributed learning from large-scale high-dimensional data.
Fast Sparse Least-Squares Regression with Non-Asymptotic Guarantees
Jul 18, 2015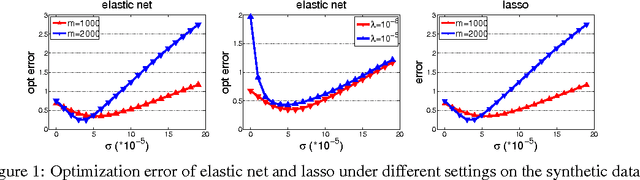
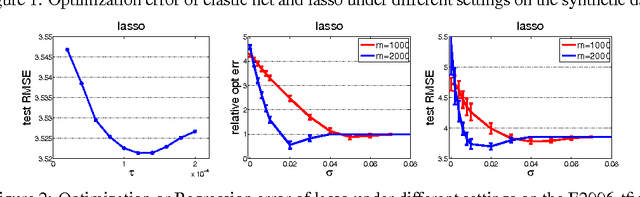
In this paper, we study a fast approximation method for {\it large-scale high-dimensional} sparse least-squares regression problem by exploiting the Johnson-Lindenstrauss (JL) transforms, which embed a set of high-dimensional vectors into a low-dimensional space. In particular, we propose to apply the JL transforms to the data matrix and the target vector and then to solve a sparse least-squares problem on the compressed data with a {\it slightly larger regularization parameter}. Theoretically, we establish the optimization error bound of the learned model for two different sparsity-inducing regularizers, i.e., the elastic net and the $\ell_1$ norm. Compared with previous relevant work, our analysis is {\it non-asymptotic and exhibits more insights} on the bound, the sample complexity and the regularization. As an illustration, we also provide an error bound of the {\it Dantzig selector} under JL transforms.
Fine-Grained Visual Categorization via Multi-stage Metric Learning
Jun 04, 2015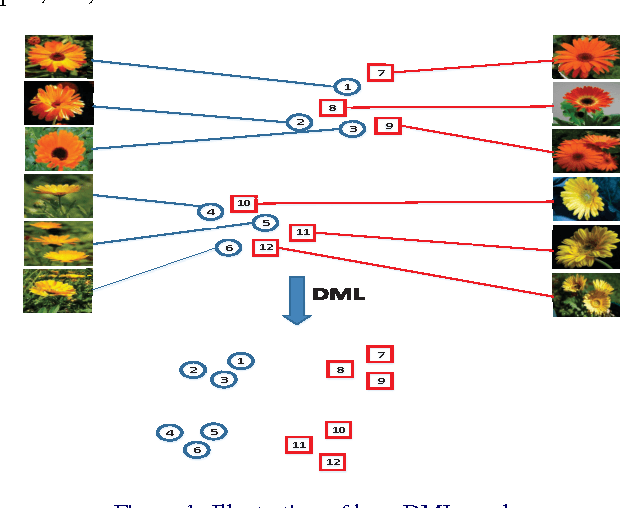
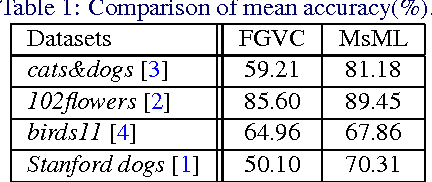
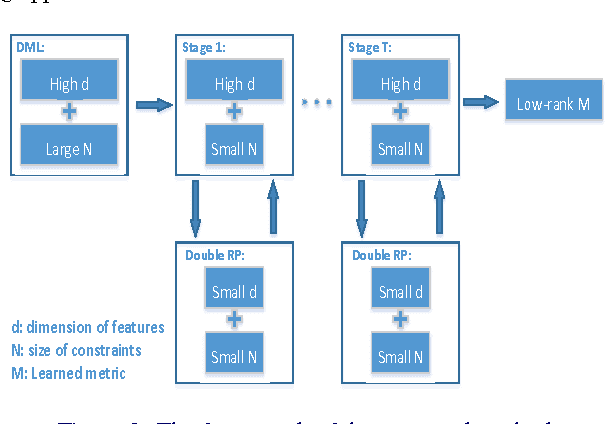
Fine-grained visual categorization (FGVC) is to categorize objects into subordinate classes instead of basic classes. One major challenge in FGVC is the co-occurrence of two issues: 1) many subordinate classes are highly correlated and are difficult to distinguish, and 2) there exists the large intra-class variation (e.g., due to object pose). This paper proposes to explicitly address the above two issues via distance metric learning (DML). DML addresses the first issue by learning an embedding so that data points from the same class will be pulled together while those from different classes should be pushed apart from each other; and it addresses the second issue by allowing the flexibility that only a portion of the neighbors (not all data points) from the same class need to be pulled together. However, feature representation of an image is often high dimensional, and DML is known to have difficulty in dealing with high dimensional feature vectors since it would require $\mathcal{O}(d^2)$ for storage and $\mathcal{O}(d^3)$ for optimization. To this end, we proposed a multi-stage metric learning framework that divides the large-scale high dimensional learning problem to a series of simple subproblems, achieving $\mathcal{O}(d)$ computational complexity. The empirical study with FVGC benchmark datasets verifies that our method is both effective and efficient compared to the state-of-the-art FGVC approaches.
An Explicit Sampling Dependent Spectral Error Bound for Column Subset Selection
May 04, 2015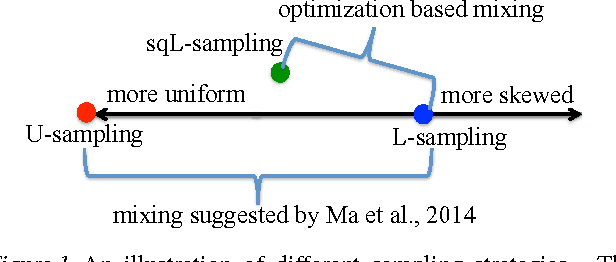
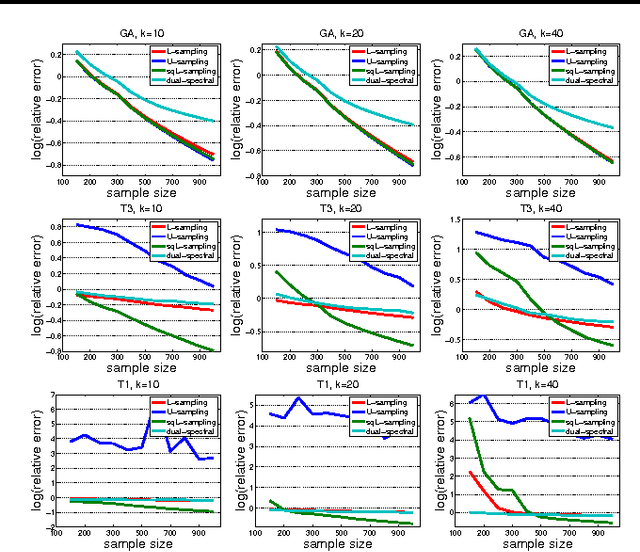
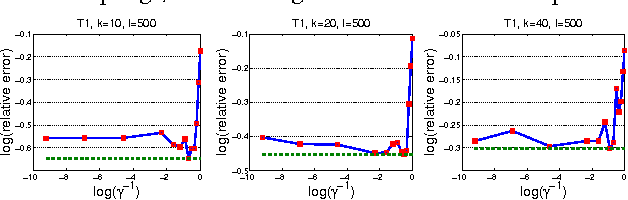
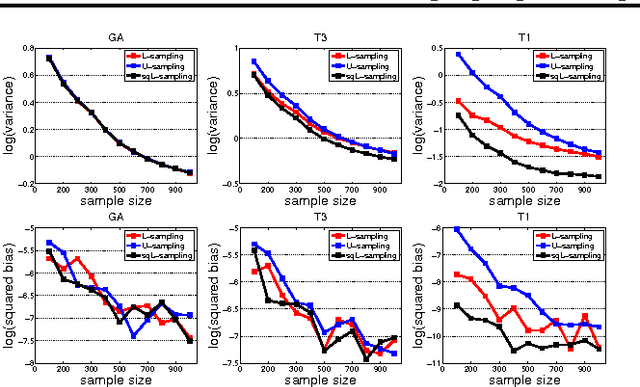
In this paper, we consider the problem of column subset selection. We present a novel analysis of the spectral norm reconstruction for a simple randomized algorithm and establish a new bound that depends explicitly on the sampling probabilities. The sampling dependent error bound (i) allows us to better understand the tradeoff in the reconstruction error due to sampling probabilities, (ii) exhibits more insights than existing error bounds that exploit specific probability distributions, and (iii) implies better sampling distributions. In particular, we show that a sampling distribution with probabilities proportional to the square root of the statistical leverage scores is always better than uniform sampling and is better than leverage-based sampling when the statistical leverage scores are very nonuniform. And by solving a constrained optimization problem related to the error bound with an efficient bisection search we are able to achieve better performance than using either the leverage-based distribution or that proportional to the square root of the statistical leverage scores. Numerical simulations demonstrate the benefits of the new sampling distributions for low-rank matrix approximation and least square approximation compared to state-of-the art algorithms.
Analysis of Nuclear Norm Regularization for Full-rank Matrix Completion
Apr 26, 2015In this paper, we provide a theoretical analysis of the nuclear-norm regularized least squares for full-rank matrix completion. Although similar formulations have been examined by previous studies, their results are unsatisfactory because only additive upper bounds are provided. Under the assumption that the top eigenspaces of the target matrix are incoherent, we derive a relative upper bound for recovering the best low-rank approximation of the unknown matrix. Our relative upper bound is tighter than previous additive bounds of other methods if the mass of the target matrix is concentrated on its top eigenspaces, and also implies perfect recovery if it is low-rank. The analysis is built upon the optimality condition of the regularized formulation and existing guarantees for low-rank matrix completion. To the best of our knowledge, this is first time such a relative bound is proved for the regularized formulation of matrix completion.
CUR Algorithm for Partially Observed Matrices
Nov 04, 2014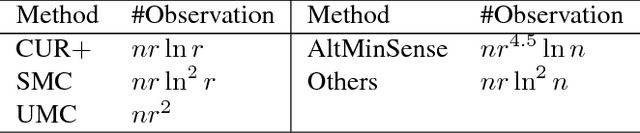
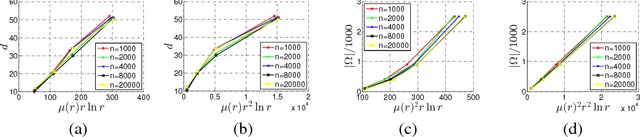
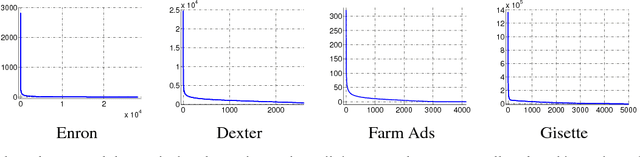
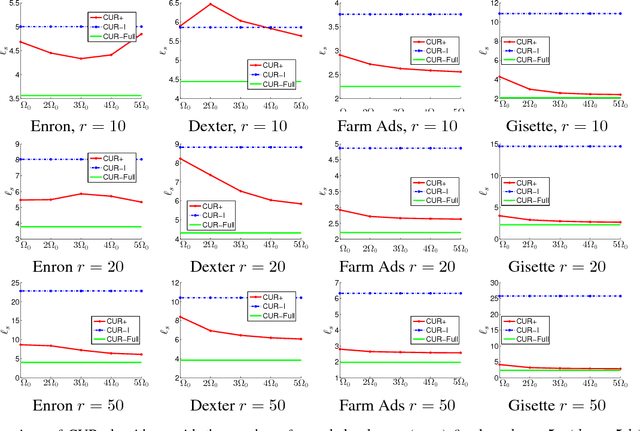
CUR matrix decomposition computes the low rank approximation of a given matrix by using the actual rows and columns of the matrix. It has been a very useful tool for handling large matrices. One limitation with the existing algorithms for CUR matrix decomposition is that they need an access to the {\it full} matrix, a requirement that can be difficult to fulfill in many real world applications. In this work, we alleviate this limitation by developing a CUR decomposition algorithm for partially observed matrices. In particular, the proposed algorithm computes the low rank approximation of the target matrix based on (i) the randomly sampled rows and columns, and (ii) a subset of observed entries that are randomly sampled from the matrix. Our analysis shows the relative error bound, measured by spectral norm, for the proposed algorithm when the target matrix is of full rank. We also show that only $O(n r\ln r)$ observed entries are needed by the proposed algorithm to perfectly recover a rank $r$ matrix of size $n\times n$, which improves the sample complexity of the existing algorithms for matrix completion. Empirical studies on both synthetic and real-world datasets verify our theoretical claims and demonstrate the effectiveness of the proposed algorithm.
Top Rank Optimization in Linear Time
Oct 06, 2014
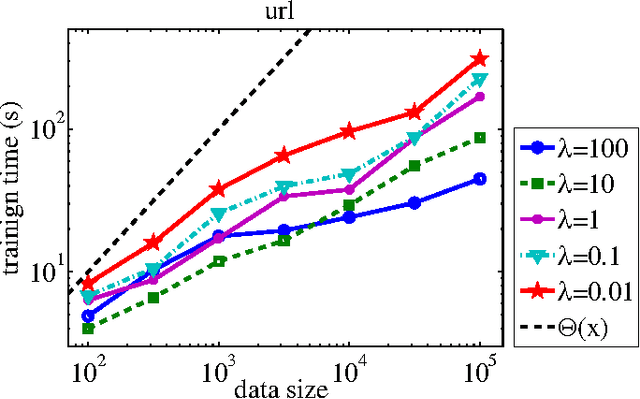
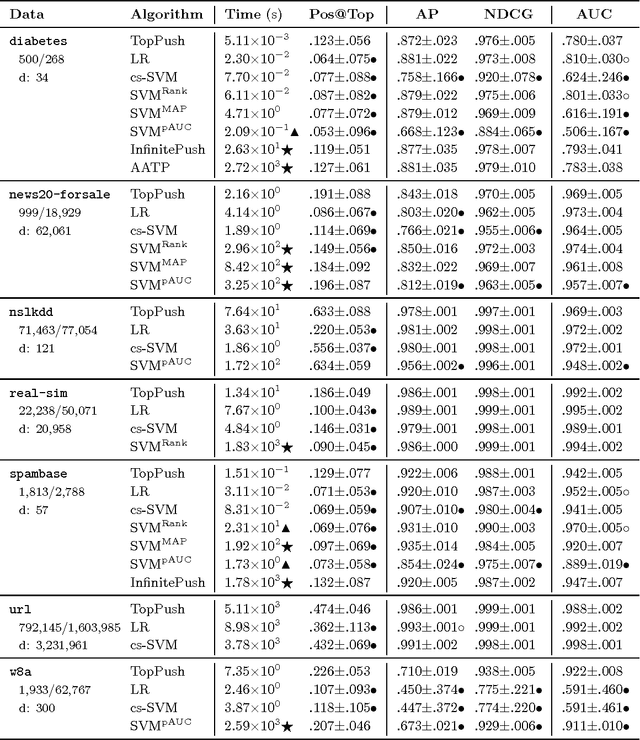
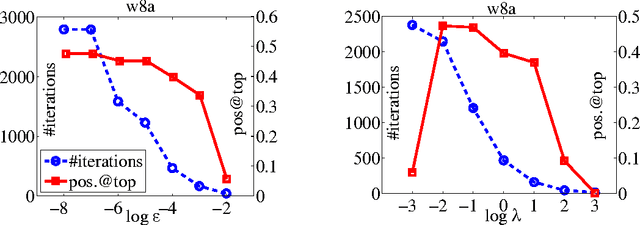
Bipartite ranking aims to learn a real-valued ranking function that orders positive instances before negative instances. Recent efforts of bipartite ranking are focused on optimizing ranking accuracy at the top of the ranked list. Most existing approaches are either to optimize task specific metrics or to extend the ranking loss by emphasizing more on the error associated with the top ranked instances, leading to a high computational cost that is super-linear in the number of training instances. We propose a highly efficient approach, titled TopPush, for optimizing accuracy at the top that has computational complexity linear in the number of training instances. We present a novel analysis that bounds the generalization error for the top ranked instances for the proposed approach. Empirical study shows that the proposed approach is highly competitive to the state-of-the-art approaches and is 10-100 times faster.