 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSINA: A Fully Automated Circuit Schematic Image to Netlist Generator Using Artificial Intelligence
Jul 02, 2026Recent advances in Artificial Intelligence (AI) have revolutionized Electronic Design Automation (EDA), particularly through Large Language Models (LLMs) for circuit design tasks. However, their application to analog and mixed-signal domains remains limited by the lack of machine-readable representations of existing circuit design knowledge. Circuit schematic images found in research manuscripts, textbooks, and websites constitute a vast repository of validated designs; however, these visual representations cannot be directly processed by EDA tools. Converting them into machine-readable netlists is essential for enabling simulation, verification, and building comprehensive databases for AI-based models. Current conversion methods lack generalization across both Integrated Circuit (IC) and Printed Circuit Board (PCB) level schematics. Moreover, they struggle with component recognition and connectivity inference, and fail to distinguish between connected junctions and crossing wires. In this paper, we propose SINA, an open-source circuit schematic image-to-netlist generator. SINA is a fully automated pipeline that integrates deep learning for robust component detection, connected-component labeling for accurate connectivity inference, Optical Character Recognition (OCR) for component reference designator extraction, and a Vision-Language Model (VLM) for reliable reference designator assignment. SINA handles both IC- and PCB-level schematics and incorporates dedicated crossing-wires detection to differentiate wire intersections from connections. We validate the correctness of the generated netlists using graph isomorphism techniques. Our experiments demonstrate an overall netlist generation accuracy of 96.67%, which is 2.72x higher compared to state-of-the-art approaches.
SINA: A Circuit Schematic Image-to-Netlist Generator Using Artificial Intelligence
Jan 29, 2026Current methods for converting circuit schematic images into machine-readable netlists struggle with component recognition and connectivity inference. In this paper, we present SINA, an open-source, fully automated circuit schematic image-to-netlist generator. SINA integrates deep learning for accurate component detection, Connected-Component Labeling (CCL) for precise connectivity extraction, and Optical Character Recognition (OCR) for component reference designator retrieval, while employing a Vision-Language Model (VLM) for reliable reference designator assignments. In our experiments, SINA achieves 96.47% overall netlist-generation accuracy, which is 2.72x higher than state-of-the-art approaches.
MuaLLM: A Multimodal Large Language Model Agent for Circuit Design Assistance with Hybrid Contextual Retrieval-Augmented Generation
Aug 11, 2025



Conducting a comprehensive literature review is crucial for advancing circuit design methodologies. However, the rapid influx of state-of-the-art research, inconsistent data representation, and the complexity of optimizing circuit design objectives make this task significantly challenging. In this paper, we propose MuaLLM, an open-source multimodal Large Language Model (LLM) agent for circuit design assistance that integrates a hybrid Retrieval-Augmented Generation (RAG) framework with an adaptive vector database of circuit design research papers. Unlike conventional LLMs, the MuaLLM agent employs a Reason + Act (ReAct) workflow for iterative reasoning, goal-setting, and multi-step information retrieval. It functions as a question-answering design assistant, capable of interpreting complex queries and providing reasoned responses grounded in circuit literature. Its multimodal capabilities enable processing of both textual and visual data, facilitating more efficient and comprehensive analysis. The system dynamically adapts using intelligent search tools, automated document retrieval from the internet, and real-time database updates. Unlike conventional approaches constrained by model context limits, MuaLLM decouples retrieval from inference, enabling scalable reasoning over arbitrarily large corpora. At the maximum context length supported by standard LLMs, MuaLLM remains up to 10x less costly and 1.6x faster while maintaining the same accuracy. This allows rapid, no-human-in-the-loop database generation, overcoming the bottleneck of simulation-based dataset creation for circuits. To evaluate MuaLLM, we introduce two custom datasets: RAG-250, targeting retrieval and citation performance, and Reasoning-100 (Reas-100), focused on multistep reasoning in circuit design. MuaLLM achieves 90.1% recall on RAG-250, and 86.8% accuracy on Reas-100.
Open Information Extraction: A Review of Baseline Techniques, Approaches, and Applications
Oct 18, 2023



With the abundant amount of available online and offline text data, there arises a crucial need to extract the relation between phrases and summarize the main content of each document in a few words. For this purpose, there have been many studies recently in Open Information Extraction (OIE). OIE improves upon relation extraction techniques by analyzing relations across different domains and avoids requiring hand-labeling pre-specified relations in sentences. This paper surveys recent approaches of OIE and its applications on Knowledge Graph (KG), text summarization, and Question Answering (QA). Moreover, the paper describes OIE basis methods in relation extraction. It briefly discusses the main approaches and the pros and cons of each method. Finally, it gives an overview about challenges, open issues, and future work opportunities for OIE, relation extraction, and OIE applications.
FuNToM: Functional Modeling of RF Circuits Using a Neural Network Assisted Two-Port Analysis Method
Aug 03, 2023



Automatic synthesis of analog and Radio Frequency (RF) circuits is a trending approach that requires an efficient circuit modeling method. This is due to the expensive cost of running a large number of simulations at each synthesis cycle. Artificial intelligence methods are promising approaches for circuit modeling due to their speed and relative accuracy. However, existing approaches require a large amount of training data, which is still collected using simulation runs. In addition, such approaches collect a whole separate dataset for each circuit topology even if a single element is added or removed. These matters are only exacerbated by the need for post-layout modeling simulations, which take even longer. To alleviate these drawbacks, in this paper, we present FuNToM, a functional modeling method for RF circuits. FuNToM leverages the two-port analysis method for modeling multiple topologies using a single main dataset and multiple small datasets. It also leverages neural networks which have shown promising results in predicting the behavior of circuits. Our results show that for multiple RF circuits, in comparison to the state-of-the-art works, while maintaining the same accuracy, the required training data is reduced by 2.8x - 10.9x. In addition, FuNToM needs 176.8x - 188.6x less time for collecting the training set in post-layout modeling.
Tablext: A Combined Neural Network And Heuristic Based Table Extractor
Apr 22, 2021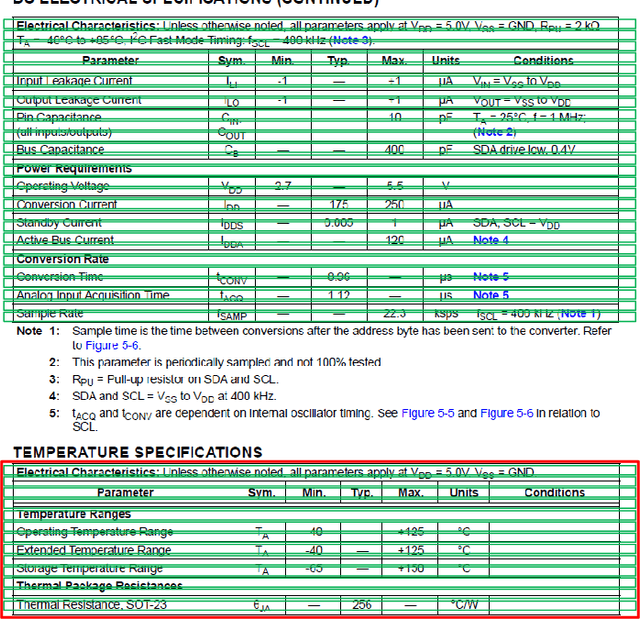
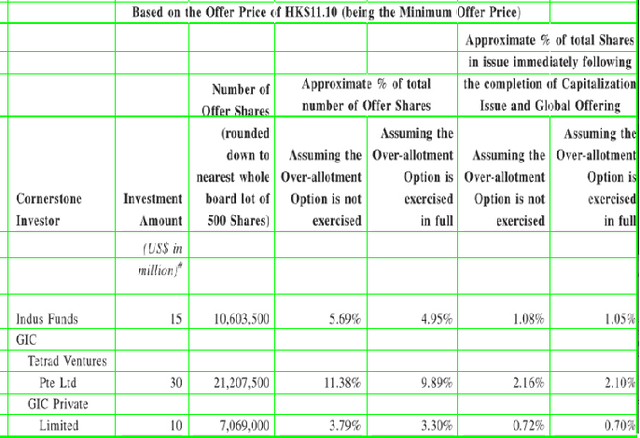
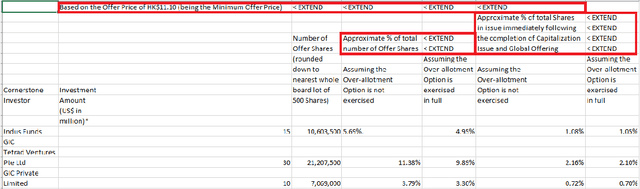
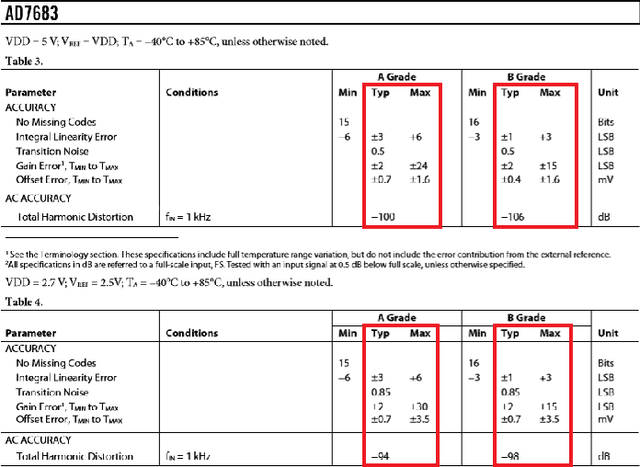
A significant portion of the data available today is found within tables. Therefore, it is necessary to use automated table extraction to obtain thorough results when data-mining. Today's popular state-of-the-art methods for table extraction struggle to adequately extract tables with machine-readable text and structural data. To make matters worse, many tables do not have machine-readable data, such as tables saved as images, making most extraction methods completely ineffective. In order to address these issues, a novel, general format table extractor tool, Tablext, is proposed. This tool uses a combination of computer vision techniques and machine learning methods to efficiently and effectively identify and extract data from tables. Tablext begins by using a custom Convolutional Neural Network (CNN) to identify and separate all potential tables. The identification process is optimized by combining the custom CNN with the YOLO object detection network. Then, the high-level structure of each table is identified with computer vision methods. This high-level, structural meta-data is used by another CNN to identify exact cell locations. As a final step, Optical Characters Recognition (OCR) is performed on every individual cell to extract their content without needing machine-readable text. This multi-stage algorithm allows for the neural networks to focus on completing complex tasks, while letting image processing methods efficiently complete the simpler ones. This leads to the proposed approach to be general-purpose enough to handle a large batch of tables regardless of their internal encodings or their layout complexity. Additionally, it becomes accurate enough to outperform competing state-of-the-art table extractors on the ICDAR 2013 table dataset.