 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisAgg: Distributed Aggregators for Efficient Secure Aggregation in Federated Learning
May 13, 2026Federated learning enables collaborative model training across distributed clients, yet vanilla FL exposes client updates to the central server. Secure-aggregation schemes protect privacy against an honest-but-curious server, but existing approaches often suffer from many communication rounds, heavy public-key operations, or difficulty handling client dropouts. Recent methods like One-Shot Private Aggregation (OPA) cut rounds to a single server interaction per FL iteration, yet they impose substantial cryptographic and computational overhead on both server and clients. We propose a new protocol called DisAgg that leverages a small committee of clients called Aggregators to perform the aggregation itself: each client secret-shares its update vector to Aggregators, which locally compute partial sums and return only aggregated shares for server-side reconstruction. This design eliminates local masking and expensive homomorphic encryption, reducing endpoint computation while preserving privacy against a curious server and a limited fraction of colluding clients. By leveraging optimal trade-offs between communication and computation costs, DisAgg processes 100k-dimensional update vectors from 100k 5G clients with a 4.6x speedup compared to OPA, the previous best protocol.
DP-LAC: Lightweight Adaptive Clipping for Differentially Private Federated Fine-tuning of Language Models
May 11, 2026Federated learning (FL) enables the collaborative training of large-scale language models (LLMs) across edge devices while keeping user data on-device. However, FL still exposes sensitive information through client-provided gradients. Differentially private stochastic gradient descent (DP-SGD) mitigates this risk by clipping each client's contribution to a threshold $C$ and adding noise proportional to $C$. Existing adaptive clipping techniques dynamically adjust $C$ but demand tedious hyperparameter tuning, which can erode the privacy budget. In this paper, we introduce DP-LAC, a method that first estimates an initial clipping threshold within an order of magnitude of the optimum using private histogram estimation, and then adapts this threshold during training without consuming additional privacy budget or introducing new hyperparameters. Empirical results show that DP-LAC outperforms both state-of-the-art adaptive clipping methods and vanilla DP-SGD, achieving an average accuracy gain of $6.6\%$.
Differentially Private Clustered Federated Learning with Privacy-Preserving Initialization and Normality-Driven Aggregation
Apr 22, 2026Federated learning (FL) enables training of a global model while keeping raw data on end-devices. Despite this, FL has shown to leak private user information and thus in practice, it is often coupled with methods such as differential privacy (DP) and secure vector sum to provide formal privacy guarantees to its participants. In realistic cross-device deployments, the data are highly heterogeneous, so vanilla federated learning converges slowly and generalizes poorly. Clustered federated learning (CFL) mitigates this by segregating users into clusters, leading to lower intra-cluster data heterogeneity. Nevertheless, coupling CFL with DP remains challenging: the injected DP noise makes individual client updates excessively noisy, and the server is unable to initialize cluster centroids with the less noisy aggregated updates. To address this challenge, we propose PINA, a two-stage framework that first lets each client fine-tune a lightweight low-rank adaptation (LoRA) adapter and privately share a compressed sketch of the update. The server leverages these sketches to construct robust cluster centroids. In the second stage, PINA introduces a normality-driven aggregation mechanism that improves convergence and robustness. Our method retains the benefits of clustered FL while providing formal privacy guarantees against an untrusted server. Extensive evaluations show that our proposed method outperforms state-of-the-art DP-FL algorithms by an average of 2.9% in accuracy for privacy budgets (epsilon in {2, 8}).
ValSub: Subsampling Validation Data to Mitigate Forgetting during ASR Personalization
Mar 12, 2025



Automatic Speech Recognition (ASR) is widely used within consumer devices such as mobile phones. Recently, personalization or on-device model fine-tuning has shown that adaptation of ASR models towards target user speech improves their performance over rare words or accented speech. Despite these gains, fine-tuning on user data (target domain) risks the personalized model to forget knowledge about its original training distribution (source domain) i.e. catastrophic forgetting, leading to subpar general ASR performance. A simple and efficient approach to combat catastrophic forgetting is to measure forgetting via a validation set that represents the source domain distribution. However, such validation sets are large and impractical for mobile devices. Towards this, we propose a novel method to subsample a substantially large validation set into a smaller one while maintaining the ability to estimate forgetting. We demonstrate the efficacy of such a dataset in mitigating forgetting by utilizing it to dynamically determine the number of ideal fine-tuning epochs. When measuring the deviations in per user fine-tuning epochs against a 50x larger validation set (oracle), our method achieves a lower mean-absolute-error (3.39) compared to randomly selected subsets of the same size (3.78-8.65). Unlike random baselines, our method consistently tracks the oracle's behaviour across three different forgetting thresholds.
DP-DyLoRA: Fine-Tuning Transformer-Based Models On-Device under Differentially Private Federated Learning using Dynamic Low-Rank Adaptation
May 10, 2024



Federated learning (FL) allows clients in an Internet of Things (IoT) system to collaboratively train a global model without sharing their local data with a server. However, clients' contributions to the server can still leak sensitive information. Differential privacy (DP) addresses such leakage by providing formal privacy guarantees, with mechanisms that add randomness to the clients' contributions. The randomness makes it infeasible to train large transformer-based models, common in modern IoT systems. In this work, we empirically evaluate the practicality of fine-tuning large scale on-device transformer-based models with differential privacy in a federated learning system. We conduct comprehensive experiments on various system properties for tasks spanning a multitude of domains: speech recognition, computer vision (CV) and natural language understanding (NLU). Our results show that full fine-tuning under differentially private federated learning (DP-FL) generally leads to huge performance degradation which can be alleviated by reducing the dimensionality of contributions through parameter-efficient fine-tuning (PEFT). Our benchmarks of existing DP-PEFT methods show that DP-Low-Rank Adaptation (DP-LoRA) consistently outperforms other methods. An even more promising approach, DyLoRA, which makes the low rank variable, when naively combined with FL would straightforwardly break differential privacy. We therefore propose an adaptation method that can be combined with differential privacy and call it DP-DyLoRA. Finally, we are able to reduce the accuracy degradation and word error rate (WER) increase due to DP to less than 2% and 7% respectively with 1 million clients and a stringent privacy budget of {\epsilon}=2.
Consistency Based Unsupervised Self-training For ASR Personalisation
Jan 22, 2024



On-device Automatic Speech Recognition (ASR) models trained on speech data of a large population might underperform for individuals unseen during training. This is due to a domain shift between user data and the original training data, differed by user's speaking characteristics and environmental acoustic conditions. ASR personalisation is a solution that aims to exploit user data to improve model robustness. The majority of ASR personalisation methods assume labelled user data for supervision. Personalisation without any labelled data is challenging due to limited data size and poor quality of recorded audio samples. This work addresses unsupervised personalisation by developing a novel consistency based training method via pseudo-labelling. Our method achieves a relative Word Error Rate Reduction (WERR) of 17.3% on unlabelled training data and 8.1% on held-out data compared to a pre-trained model, and outperforms the current state-of-the art methods.
FedNST: Federated Noisy Student Training for Automatic Speech Recognition
Jun 06, 2022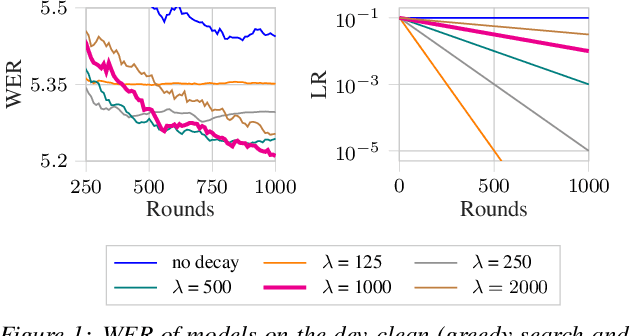
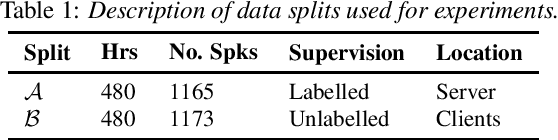
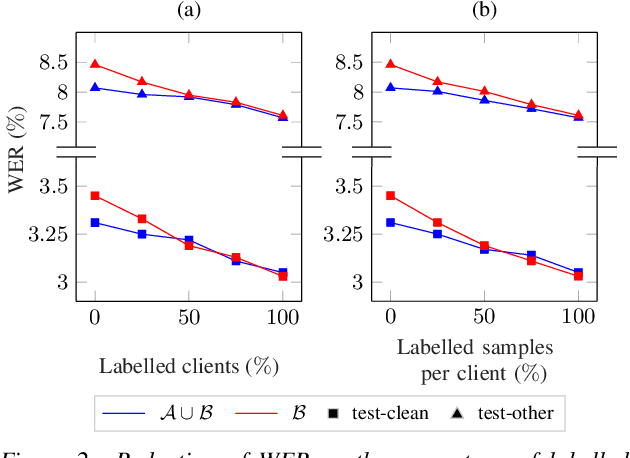
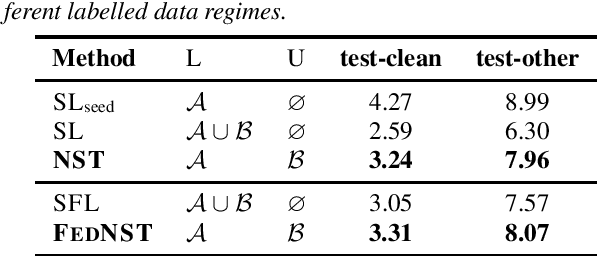
Federated Learning (FL) enables training state-of-the-art Automatic Speech Recognition (ASR) models on user devices (clients) in distributed systems, hence preventing transmission of raw user data to a central server. A key challenge facing practical adoption of FL for ASR is obtaining ground-truth labels on the clients. Existing approaches rely on clients to manually transcribe their speech, which is impractical for obtaining large training corpora. A promising alternative is using semi-/self-supervised learning approaches to leverage unlabelled user data. To this end, we propose a new Federated ASR method called FedNST for noisy student training of distributed ASR models with private unlabelled user data. We explore various facets of FedNST , such as training models with different proportions of unlabelled and labelled data, and evaluate the proposed approach on 1173 simulated clients. Evaluating FedNST on LibriSpeech, where 960 hours of speech data is split equally into server (labelled) and client (unlabelled) data, showed a 22.5% relative word error rate reduction (WERR) over a supervised baseline trained only on server data.