 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Representation in Neural Language Models: Suppression and Recovery of Expectations
Jun 10, 2019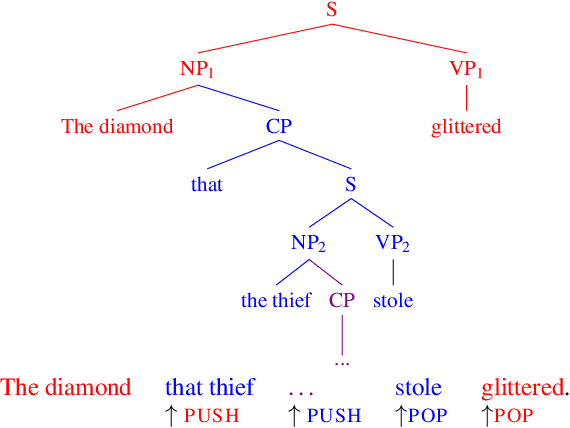
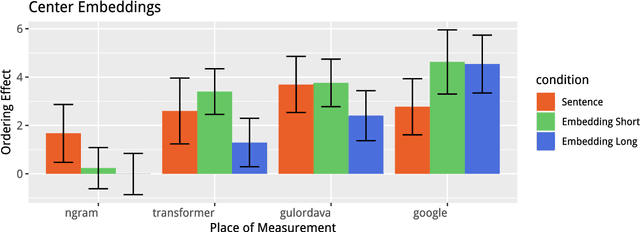
Deep learning sequence models have led to a marked increase in performance for a range of Natural Language Processing tasks, but it remains an open question whether they are able to induce proper hierarchical generalizations for representing natural language from linear input alone. Work using artificial languages as training input has shown that LSTMs are capable of inducing the stack-like data structures required to represent context-free and certain mildly context-sensitive languages---formal language classes which correspond in theory to the hierarchical structures of natural language. Here we present a suite of experiments probing whether neural language models trained on linguistic data induce these stack-like data structures and deploy them while incrementally predicting words. We study two natural language phenomena: center embedding sentences and syntactic island constraints on the filler--gap dependency. In order to properly predict words in these structures, a model must be able to temporarily suppress certain expectations and then recover those expectations later, essentially pushing and popping these expectations on a stack. Our results provide evidence that models can successfully suppress and recover expectations in many cases, but do not fully recover their previous grammatical state.
What Syntactic Structures block Dependencies in RNN Language Models?
May 24, 2019
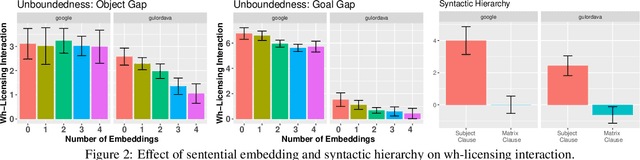
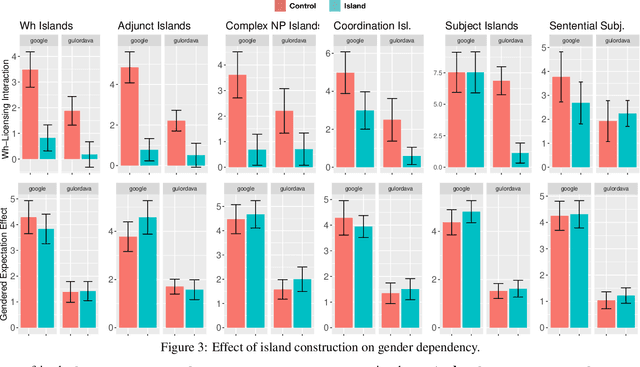
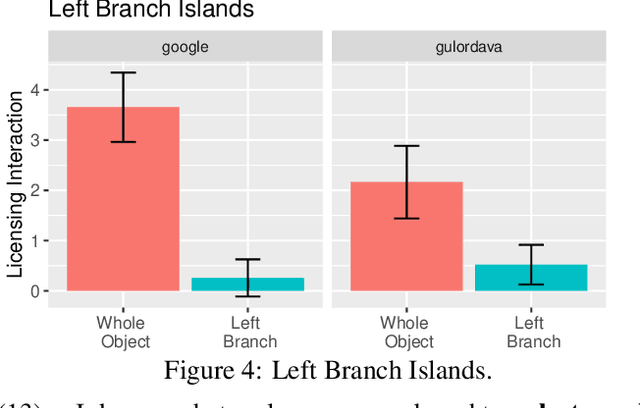
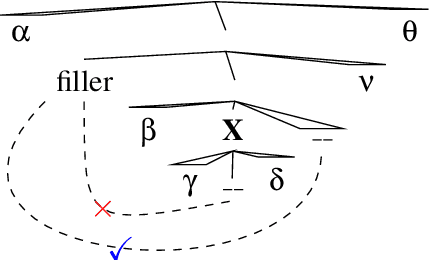
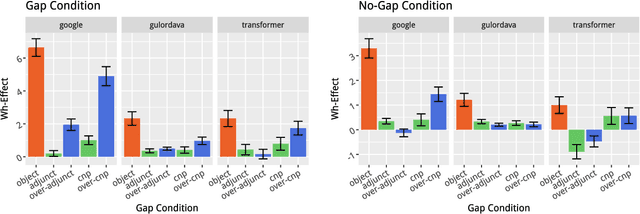
Recurrent Neural Networks (RNNs) trained on a language modeling task have been shown to acquire a number of non-local grammatical dependencies with some success. Here, we provide new evidence that RNN language models are sensitive to hierarchical syntactic structure by investigating the filler--gap dependency and constraints on it, known as syntactic islands. Previous work is inconclusive about whether RNNs learn to attenuate their expectations for gaps in island constructions in particular or in any sufficiently complex syntactic environment. This paper gives new evidence for the former by providing control studies that have been lacking so far. We demonstrate that two state-of-the-art RNN models are are able to maintain the filler--gap dependency through unbounded sentential embeddings and are also sensitive to the hierarchical relationship between the filler and the gap. Next, we demonstrate that the models are able to maintain possessive pronoun gender expectations through island constructions---this control case rules out the possibility that island constructions block all information flow in these networks. We also evaluate three untested islands constraints: coordination islands, left branch islands, and sentential subject islands. Models are able to learn left branch islands and learn coordination islands gradiently, but fail to learn sentential subject islands. Through these controls and new tests, we provide evidence that model behavior is due to finer-grained expectations than gross syntactic complexity, but also that the models are conspicuously un-humanlike in some of their performance characteristics.
Availability-Based Production Predicts Speakers' Real-time Choices of Mandarin Classifiers
May 17, 2019
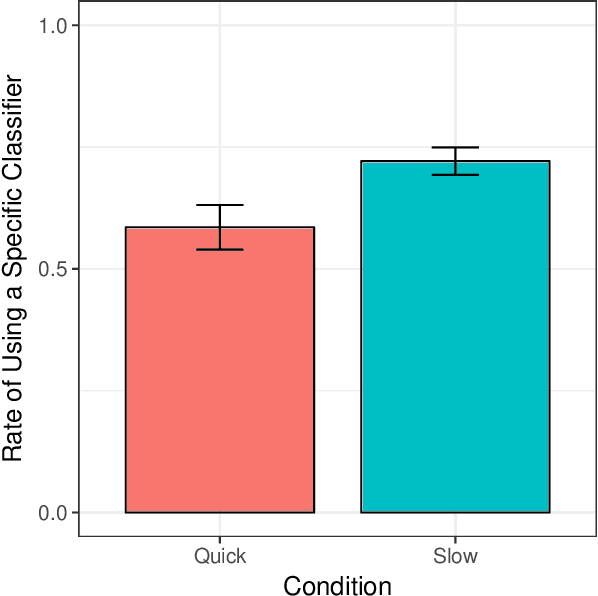
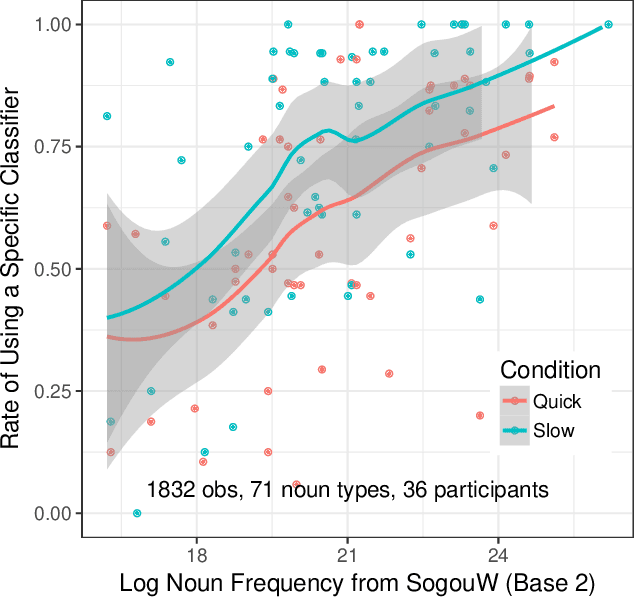
Speakers often face choices as to how to structure their intended message into an utterance. Here we investigate the influence of contextual predictability on the encoding of linguistic content manifested by speaker choice in a classifier language. In English, a numeral modifies a noun directly (e.g., three computers). In classifier languages such as Mandarin Chinese, it is obligatory to use a classifier (CL) with the numeral and the noun (e.g., three CL.machinery computer, three CL.general computer). While different nouns are compatible with different specific classifiers, there is a general classifier "ge" (CL.general) that can be used with most nouns. When the upcoming noun is less predictable, the use of a more specific classifier would reduce surprisal at the noun thus potentially facilitate comprehension (predicted by Uniform Information Density, Levy & Jaeger, 2007), but the use of that more specific classifier may be dispreferred from a production standpoint if accessing the general classifier is always available (predicted by Availability-Based Production; Bock, 1987; Ferreira & Dell, 2000). Here we use a picture-naming experiment showing that Availability-Based Production predicts speakers' real-time choices of Mandarin classifiers.
Structural Supervision Improves Learning of Non-Local Grammatical Dependencies
Apr 06, 2019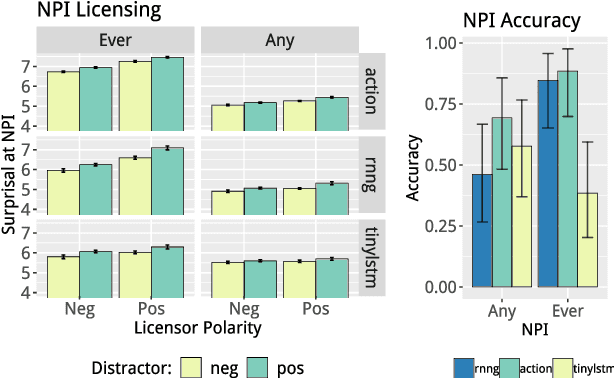
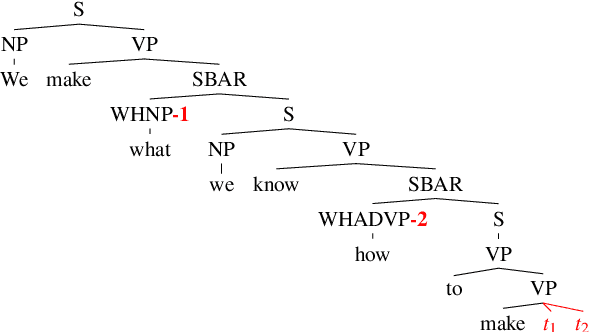
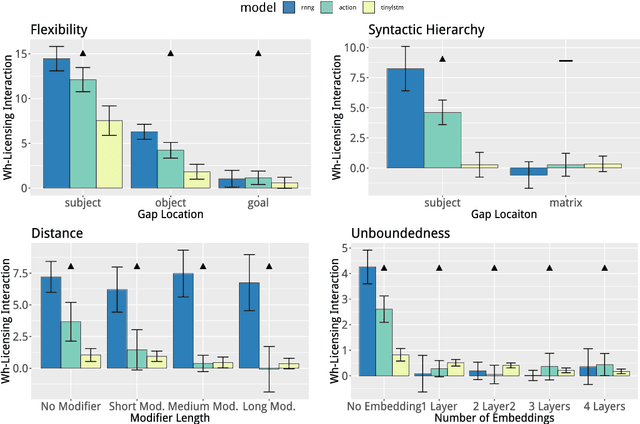
State-of-the-art LSTM language models trained on large corpora learn sequential contingencies in impressive detail and have been shown to acquire a number of non-local grammatical dependencies with some success. Here we investigate whether supervision with hierarchical structure enhances learning of a range of grammatical dependencies, a question that has previously been addressed only for subject-verb agreement. Using controlled experimental methods from psycholinguistics, we compare the performance of word-based LSTM models versus two models that represent hierarchical structure and deploy it in left-to-right processing: Recurrent Neural Network Grammars (RNNGs) (Dyer et al., 2016) and a incrementalized version of the Parsing-as-Language-Modeling configuration from Chariak et al., (2016). Models are tested on a diverse range of configurations for two classes of non-local grammatical dependencies in English---Negative Polarity licensing and Filler--Gap Dependencies. Using the same training data across models, we find that structurally-supervised models outperform the LSTM, with the RNNG demonstrating best results on both types of grammatical dependencies and even learning many of the Island Constraints on the filler--gap dependency. Structural supervision thus provides data efficiency advantages over purely string-based training of neural language models in acquiring human-like generalizations about non-local grammatical dependencies.
Neural Language Models as Psycholinguistic Subjects: Representations of Syntactic State
Mar 08, 2019
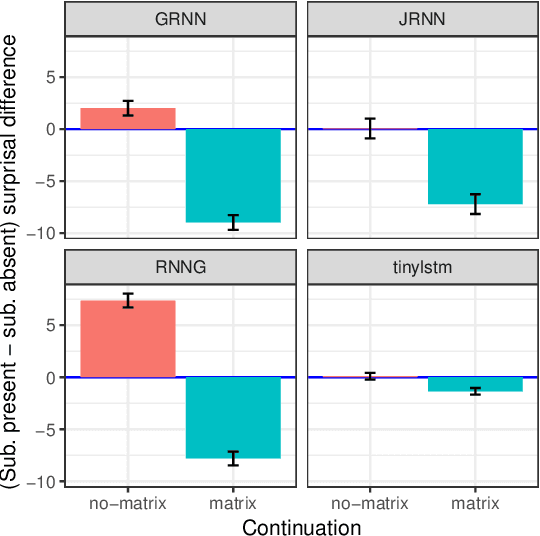


We deploy the methods of controlled psycholinguistic experimentation to shed light on the extent to which the behavior of neural network language models reflects incremental representations of syntactic state. To do so, we examine model behavior on artificial sentences containing a variety of syntactically complex structures. We test four models: two publicly available LSTM sequence models of English (Jozefowicz et al., 2016; Gulordava et al., 2018) trained on large datasets; an RNNG (Dyer et al., 2016) trained on a small, parsed dataset; and an LSTM trained on the same small corpus as the RNNG. We find evidence that the LSTMs trained on large datasets represent syntactic state over large spans of text in a way that is comparable to the RNNG, while the LSTM trained on the small dataset does not or does so only weakly.
Comparing Models of Associative Meaning: An Empirical Investigation of Reference in Simple Language Games
Oct 08, 2018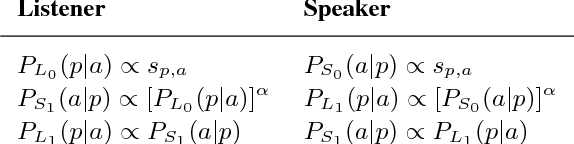
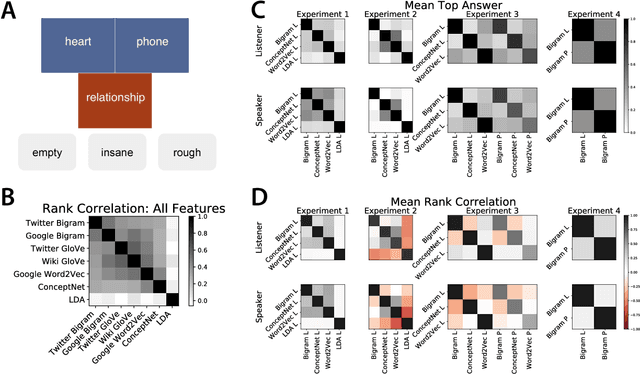
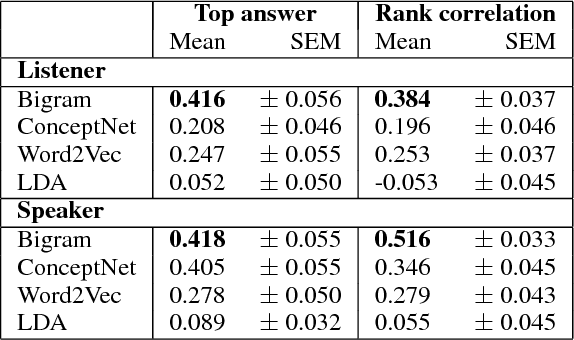
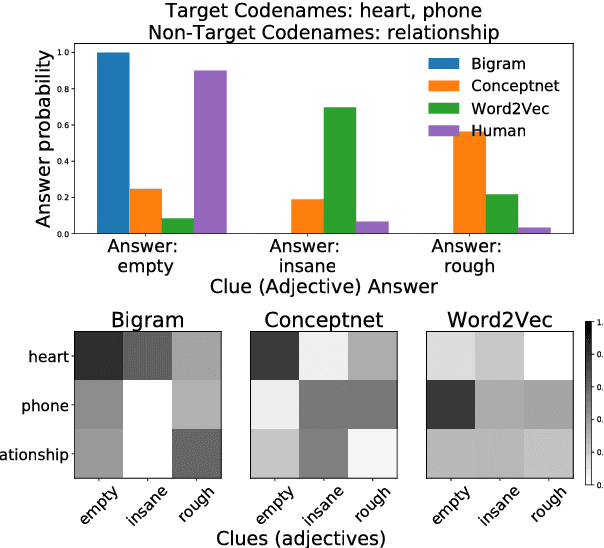
Simple reference games are of central theoretical and empirical importance in the study of situated language use. Although language provides rich, compositional truth-conditional semantics to facilitate reference, speakers and listeners may sometimes lack the overall lexical and cognitive resources to guarantee successful reference through these means alone. However, language also has rich associational structures that can serve as a further resource for achieving successful reference. Here we investigate this use of associational information in a setting where only associational information is available: a simplified version of the popular game Codenames. Using optimal experiment design techniques, we compare a range of models varying in the type of associative information deployed and in level of pragmatic sophistication against human behavior. In this setting, we find that listeners' behavior reflects direct bigram collocational associations more strongly than word-embedding or semantic knowledge graph-based associations and that there is little evidence for pragmatically sophisticated behavior by either speakers or listeners of the type that might be predicted by recursive-reasoning models such as the Rational Speech Acts theory. These results shed light on the nature of the lexical resources that speakers and listeners can bring to bear in achieving reference through associative meaning alone.
RNNs as psycholinguistic subjects: Syntactic state and grammatical dependency
Sep 05, 2018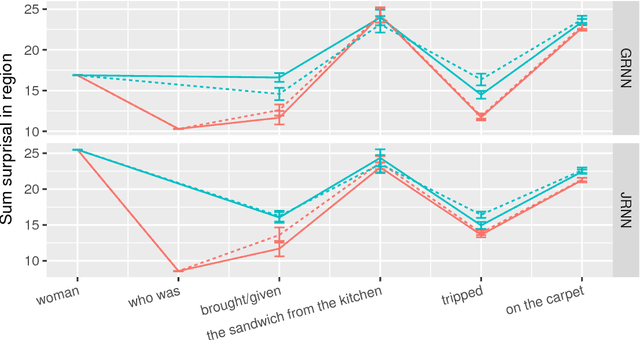
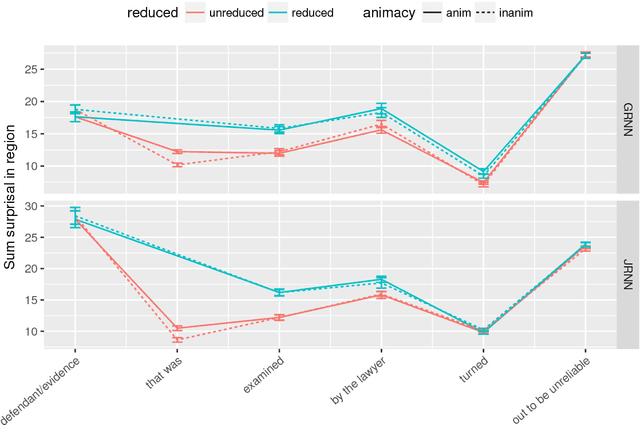
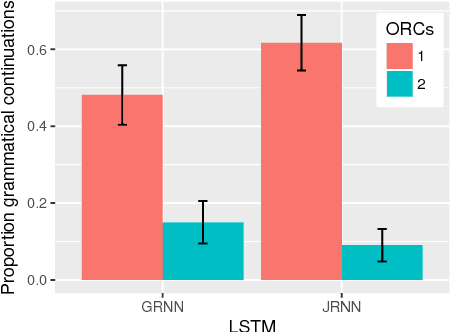
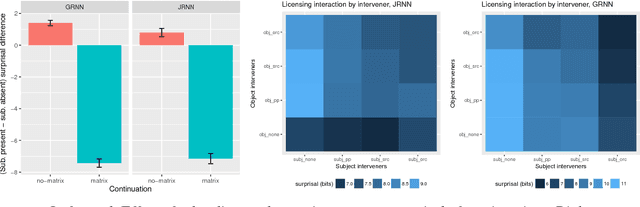
Recurrent neural networks (RNNs) are the state of the art in sequence modeling for natural language. However, it remains poorly understood what grammatical characteristics of natural language they implicitly learn and represent as a consequence of optimizing the language modeling objective. Here we deploy the methods of controlled psycholinguistic experimentation to shed light on to what extent RNN behavior reflects incremental syntactic state and grammatical dependency representations known to characterize human linguistic behavior. We broadly test two publicly available long short-term memory (LSTM) English sequence models, and learn and test a new Japanese LSTM. We demonstrate that these models represent and maintain incremental syntactic state, but that they do not always generalize in the same way as humans. Furthermore, none of our models learn the appropriate grammatical dependency configurations licensing reflexive pronouns or negative polarity items.
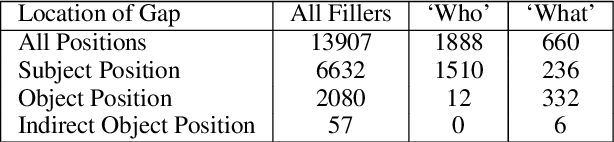
What do RNN Language Models Learn about Filler-Gap Dependencies?
Aug 31, 2018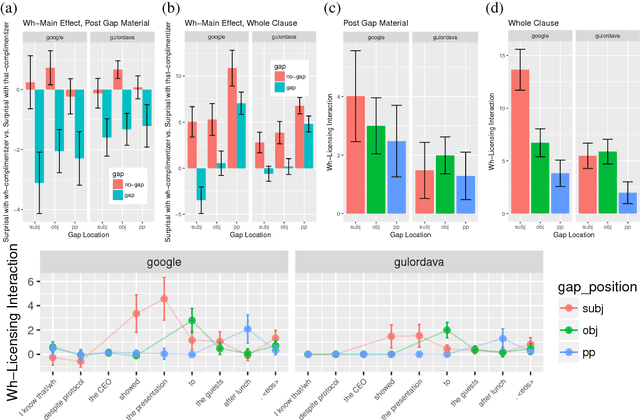
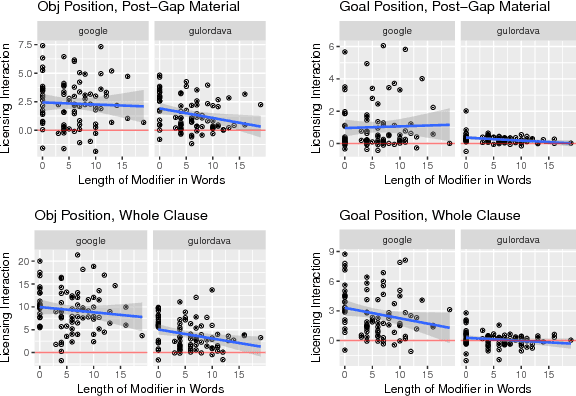
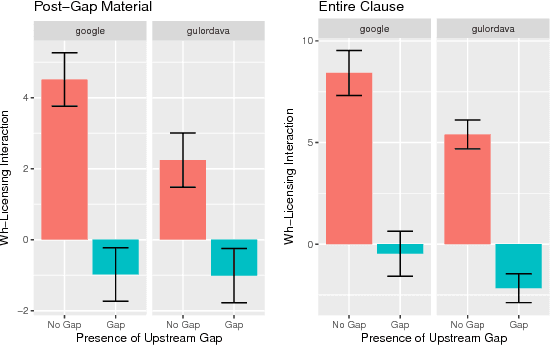
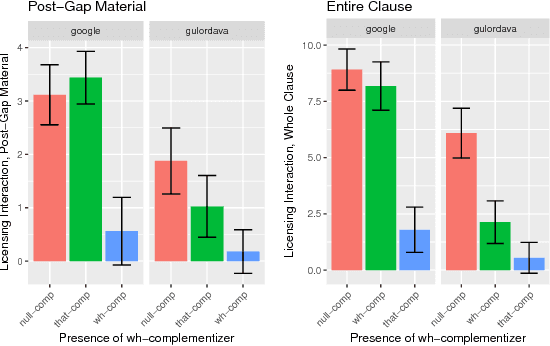
RNN language models have achieved state-of-the-art perplexity results and have proven useful in a suite of NLP tasks, but it is as yet unclear what syntactic generalizations they learn. Here we investigate whether state-of-the-art RNN language models represent long-distance filler-gap dependencies and constraints on them. Examining RNN behavior on experimentally controlled sentences designed to expose filler-gap dependencies, we show that RNNs can represent the relationship in multiple syntactic positions and over large spans of text. Furthermore, we show that RNNs learn a subset of the known restrictions on filler-gap dependencies, known as island constraints: RNNs show evidence for wh-islands, adjunct islands, and complex NP islands. These studies demonstrates that state-of-the-art RNN models are able to learn and generalize about empty syntactic positions.
Word learning and the acquisition of syntactic--semantic overhypotheses
May 14, 2018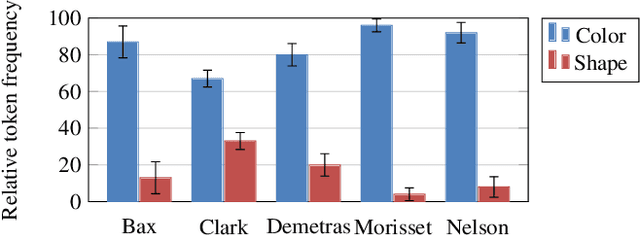

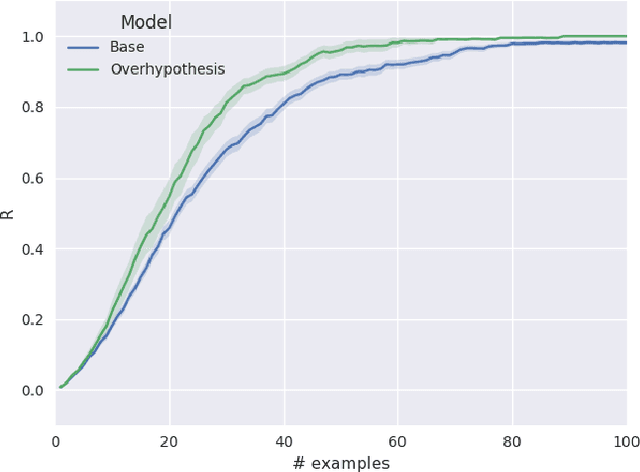
Children learning their first language face multiple problems of induction: how to learn the meanings of words, and how to build meaningful phrases from those words according to syntactic rules. We consider how children might solve these problems efficiently by solving them jointly, via a computational model that learns the syntax and semantics of multi-word utterances in a grounded reference game. We select a well-studied empirical case in which children are aware of patterns linking the syntactic and semantic properties of words --- that the properties picked out by base nouns tend to be related to shape, while prenominal adjectives tend to refer to other properties such as color. We show that children applying such inductive biases are accurately reflecting the statistics of child-directed speech, and that inducing similar biases in our computational model captures children's behavior in a classic adjective learning experiment. Our model incorporating such biases also demonstrates a clear data efficiency in learning, relative to a baseline model that learns without forming syntax-sensitive overhypotheses of word meaning. Thus solving a more complex joint inference problem may make the full problem of language acquisition easier, not harder.
Assessing Language Proficiency from Eye Movements in Reading
Apr 24, 2018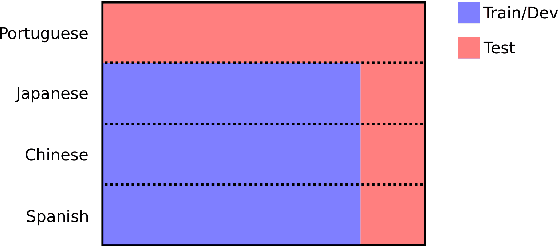
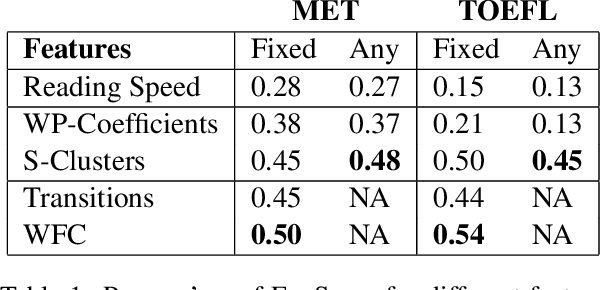
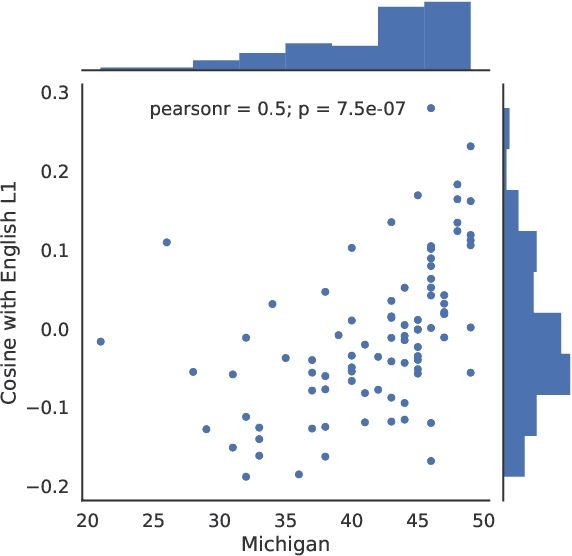
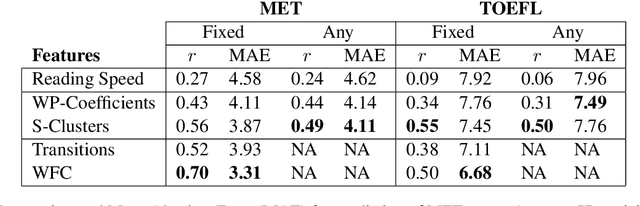
We present a novel approach for determining learners' second language proficiency which utilizes behavioral traces of eye movements during reading. Our approach provides stand-alone eyetracking based English proficiency scores which reflect the extent to which the learner's gaze patterns in reading are similar to those of native English speakers. We show that our scores correlate strongly with standardized English proficiency tests. We also demonstrate that gaze information can be used to accurately predict the outcomes of such tests. Our approach yields the strongest performance when the test taker is presented with a suite of sentences for which we have eyetracking data from other readers. However, it remains effective even using eyetracking with sentences for which eye movement data have not been previously collected. By deriving proficiency as an automatic byproduct of eye movements during ordinary reading, our approach offers a potentially valuable new tool for second language proficiency assessment. More broadly, our results open the door to future methods for inferring reader characteristics from the behavioral traces of reading.