 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs nasty noise actually harder than malicious noise?
Nov 12, 2025We consider the relative abilities and limitations of computationally efficient algorithms for learning in the presence of noise, under two well-studied and challenging adversarial noise models for learning Boolean functions: malicious noise, in which an adversary can arbitrarily corrupt a random subset of examples given to the learner; and nasty noise, in which an adversary can arbitrarily corrupt an adversarially chosen subset of examples given to the learner. We consider both the distribution-independent and fixed-distribution settings. Our main results highlight a dramatic difference between these two settings: For distribution-independent learning, we prove a strong equivalence between the two noise models: If a class ${\cal C}$ of functions is efficiently learnable in the presence of $η$-rate malicious noise, then it is also efficiently learnable in the presence of $η$-rate nasty noise. In sharp contrast, for the fixed-distribution setting we show an arbitrarily large separation: Under a standard cryptographic assumption, for any arbitrarily large value $r$ there exists a concept class for which there is a ratio of $r$ between the rate $η_{malicious}$ of malicious noise that polynomial-time learning algorithms can tolerate, versus the rate $η_{nasty}$ of nasty noise that such learning algorithms can tolerate. To offset the negative result for the fixed-distribution setting, we define a broad and natural class of algorithms, namely those that ignore contradictory examples (ICE). We show that for these algorithms, malicious noise and nasty noise are equivalent up to a factor of two in the noise rate: Any efficient ICE learner that succeeds with $η$-rate malicious noise can be converted to an efficient learner that succeeds with $η/2$-rate nasty noise. We further show that the above factor of two is necessary, again under a standard cryptographic assumption.
The Probably Approximately Correct Learning Model in Computational Learning Theory
Nov 11, 2025This survey paper gives an overview of various known results on learning classes of Boolean functions in Valiant's Probably Approximately Correct (PAC) learning model and its commonly studied variants.
Sparsifying Suprema of Gaussian Processes
Nov 22, 2024We give a dimension-independent sparsification result for suprema of centered Gaussian processes: Let $T$ be any (possibly infinite) bounded set of vectors in $\mathbb{R}^n$, and let $\{{\boldsymbol{X}}_t\}_{t\in T}$ be the canonical Gaussian process on $T$. We show that there is an $O_\varepsilon(1)$-size subset $S \subseteq T$ and a set of real values $\{c_s\}_{s \in S}$ such that $\sup_{s \in S} \{{\boldsymbol{X}}_s + c_s\}$ is an $\varepsilon$-approximator of $\sup_{t \in T} {\boldsymbol{X}}_t$. Notably, the size of $S$ is completely independent of both the size of $T$ and of the ambient dimension $n$. We use this to show that every norm is essentially a junta when viewed as a function over Gaussian space: Given any norm $\nu(x)$ on $\mathbb{R}^n$, there is another norm $\psi(x)$ which depends only on the projection of $x$ along $O_\varepsilon(1)$ directions, for which $\psi({\boldsymbol{g}})$ is a multiplicative $(1 \pm \varepsilon)$-approximation of $\nu({\boldsymbol{g}})$ with probability $1-\varepsilon$ for ${\boldsymbol{g}} \sim N(0,I_n)$. We also use our sparsification result for suprema of centered Gaussian processes to give a sparsification lemma for convex sets of bounded geometric width: Any intersection of (possibly infinitely many) halfspaces in $\mathbb{R}^n$ that are at distance $O(1)$ from the origin is $\varepsilon$-close, under $N(0,I_n)$, to an intersection of only $O_\varepsilon(1)$ many halfspaces. We describe applications to agnostic learning and tolerant property testing.
The perils of being unhinged: On the accuracy of classifiers minimizing a noise-robust convex loss
Dec 08, 2021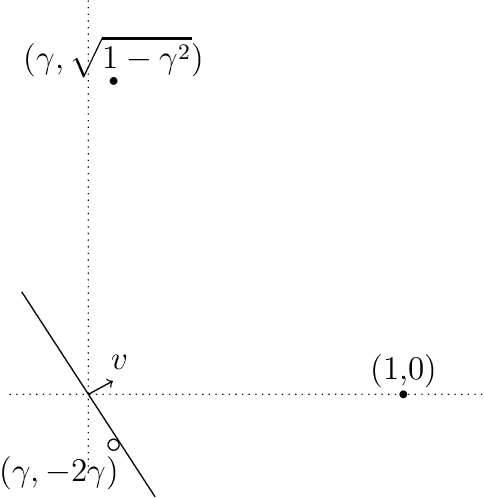
van Rooyen et al. introduced a notion of convex loss functions being robust to random classification noise, and established that the "unhinged" loss function is robust in this sense. In this note we study the accuracy of binary classifiers obtained by minimizing the unhinged loss, and observe that even for simple linearly separable data distributions, minimizing the unhinged loss may only yield a binary classifier with accuracy no better than random guessing.
On the Approximation Power of Two-Layer Networks of Random ReLUs
Feb 03, 2021

This paper considers the following question: how well can depth-two ReLU networks with randomly initialized bottom-level weights represent smooth functions? We give near-matching upper- and lower-bounds for $L_2$-approximation in terms of the Lipschitz constant, the desired accuracy, and the dimension of the problem, as well as similar results in terms of Sobolev norms. Our positive results employ tools from harmonic analysis and ridgelet representation theory, while our lower-bounds are based on (robust versions of) dimensionality arguments.
Efficient average-case population recovery in the presence of insertions and deletions
Jul 12, 2019

Several recent works have considered the \emph{trace reconstruction problem}, in which an unknown source string $x\in\{0,1\}^n$ is transmitted through a probabilistic channel which may randomly delete coordinates or insert random bits, resulting in a \emph{trace} of $x$. The goal is to reconstruct the original string~$x$ from independent traces of $x$. While the best algorithms known for worst-case strings use $\exp(O(n^{1/3}))$ traces \cite{DOS17,NazarovPeres17}, highly efficient algorithms are known \cite{PZ17,HPP18} for the \emph{average-case} version, in which $x$ is uniformly random. We consider a generalization of this average-case trace reconstruction problem, which we call \emph{average-case population recovery in the presence of insertions and deletions}. In this problem, there is an unknown distribution $\cal{D}$ over $s$ unknown source strings $x^1,\dots,x^s \in \{0,1\}^n$, and each sample is independently generated by drawing some $x^i$ from $\cal{D}$ and returning an independent trace of $x^i$. Building on \cite{PZ17} and \cite{HPP18}, we give an efficient algorithm for this problem. For any support size $s \leq \smash{\exp(\Theta(n^{1/3}))}$, for a $1-o(1)$ fraction of all $s$-element support sets $\{x^1,\dots,x^s\} \subset \{0,1\}^n$, for every distribution $\cal{D}$ supported on $\{x^1,\dots,x^s\}$, our algorithm efficiently recovers ${\cal D}$ up to total variation distance $\epsilon$ with high probability, given access to independent traces of independent draws from $\cal{D}$. The algorithm runs in time poly$(n,s,1/\epsilon)$ and its sample complexity is poly$(s,1/\epsilon,\exp(\log^{1/3}n)).$ This polynomial dependence on the support size $s$ is in sharp contrast with the \emph{worst-case} version (when $x^1,\dots,x^s$ may be any strings in $\{0,1\}^n$), in which the sample complexity of the most efficient known algorithm \cite{BCFSS19} is doubly exponential in $s$.
Learning from satisfying assignments under continuous distributions
Jul 02, 2019What kinds of functions are learnable from their satisfying assignments? Motivated by this simple question, we extend the framework of De, Diakonikolas, and Servedio [DDS15], which studied the learnability of probability distributions over $\{0,1\}^n$ defined by the set of satisfying assignments to "low-complexity" Boolean functions, to Boolean-valued functions defined over continuous domains. In our learning scenario there is a known "background distribution" $\mathcal{D}$ over $\mathbb{R}^n$ (such as a known normal distribution or a known log-concave distribution) and the learner is given i.i.d. samples drawn from a target distribution $\mathcal{D}_f$, where $\mathcal{D}_f$ is $\mathcal{D}$ restricted to the satisfying assignments of an unknown low-complexity Boolean-valued function $f$. The problem is to learn an approximation $\mathcal{D}'$ of the target distribution $\mathcal{D}_f$ which has small error as measured in total variation distance. We give a range of efficient algorithms and hardness results for this problem, focusing on the case when $f$ is a low-degree polynomial threshold function (PTF). When the background distribution $\mathcal{D}$ is log-concave, we show that this learning problem is efficiently solvable for degree-1 PTFs (i.e.,~linear threshold functions) but not for degree-2 PTFs. In contrast, when $\mathcal{D}$ is a normal distribution, we show that this learning problem is efficiently solvable for degree-2 PTFs but not for degree-4 PTFs. Our hardness results rely on standard assumptions about secure signature schemes.
Density estimation for shift-invariant multidimensional distributions
Nov 09, 2018We study density estimation for classes of shift-invariant distributions over $\mathbb{R}^d$. A multidimensional distribution is "shift-invariant" if, roughly speaking, it is close in total variation distance to a small shift of it in any direction. Shift-invariance relaxes smoothness assumptions commonly used in non-parametric density estimation to allow jump discontinuities. The different classes of distributions that we consider correspond to different rates of tail decay. For each such class we give an efficient algorithm that learns any distribution in the class from independent samples with respect to total variation distance. As a special case of our general result, we show that $d$-dimensional shift-invariant distributions which satisfy an exponential tail bound can be learned to total variation distance error $\epsilon$ using $\tilde{O}_d(1/ \epsilon^{d+2})$ examples and $\tilde{O}_d(1/ \epsilon^{2d+2})$ time. This implies that, for constant $d$, multivariate log-concave distributions can be learned in $\tilde{O}_d(1/\epsilon^{2d+2})$ time using $\tilde{O}_d(1/\epsilon^{d+2})$ samples, answering a question of [Diakonikolas, Kane and Stewart, 2016] All of our results extend to a model of noise-tolerant density estimation using Huber's contamination model, in which the target distribution to be learned is a $(1-\epsilon,\epsilon)$ mixture of some unknown distribution in the class with some other arbitrary and unknown distribution, and the learning algorithm must output a hypothesis distribution with total variation distance error $O(\epsilon)$ from the target distribution. We show that our general results are close to best possible by proving a simple $\Omega\left(1/\epsilon^d\right)$ information-theoretic lower bound on sample complexity even for learning bounded distributions that are shift-invariant.
Learning Poisson Binomial Distributions
Feb 17, 2015



We consider a basic problem in unsupervised learning: learning an unknown \emph{Poisson Binomial Distribution}. A Poisson Binomial Distribution (PBD) over $\{0,1,\dots,n\}$ is the distribution of a sum of $n$ independent Bernoulli random variables which may have arbitrary, potentially non-equal, expectations. These distributions were first studied by S. Poisson in 1837 \cite{Poisson:37} and are a natural $n$-parameter generalization of the familiar Binomial Distribution. Surprisingly, prior to our work this basic learning problem was poorly understood, and known results for it were far from optimal. We essentially settle the complexity of the learning problem for this basic class of distributions. As our first main result we give a highly efficient algorithm which learns to $\eps$-accuracy (with respect to the total variation distance) using $\tilde{O}(1/\eps^3)$ samples \emph{independent of $n$}. The running time of the algorithm is \emph{quasilinear} in the size of its input data, i.e., $\tilde{O}(\log(n)/\eps^3)$ bit-operations. (Observe that each draw from the distribution is a $\log(n)$-bit string.) Our second main result is a {\em proper} learning algorithm that learns to $\eps$-accuracy using $\tilde{O}(1/\eps^2)$ samples, and runs in time $(1/\eps)^{\poly (\log (1/\eps))} \cdot \log n$. This is nearly optimal, since any algorithm {for this problem} must use $\Omega(1/\eps^2)$ samples. We also give positive and negative results for some extensions of this learning problem to weighted sums of independent Bernoulli random variables.
Near-Optimal Density Estimation in Near-Linear Time Using Variable-Width Histograms
Nov 01, 2014Let $p$ be an unknown and arbitrary probability distribution over $[0,1)$. We consider the problem of {\em density estimation}, in which a learning algorithm is given i.i.d. draws from $p$ and must (with high probability) output a hypothesis distribution that is close to $p$. The main contribution of this paper is a highly efficient density estimation algorithm for learning using a variable-width histogram, i.e., a hypothesis distribution with a piecewise constant probability density function. In more detail, for any $k$ and $\epsilon$, we give an algorithm that makes $\tilde{O}(k/\epsilon^2)$ draws from $p$, runs in $\tilde{O}(k/\epsilon^2)$ time, and outputs a hypothesis distribution $h$ that is piecewise constant with $O(k \log^2(1/\epsilon))$ pieces. With high probability the hypothesis $h$ satisfies $d_{\mathrm{TV}}(p,h) \leq C \cdot \mathrm{opt}_k(p) + \epsilon$, where $d_{\mathrm{TV}}$ denotes the total variation distance (statistical distance), $C$ is a universal constant, and $\mathrm{opt}_k(p)$ is the smallest total variation distance between $p$ and any $k$-piecewise constant distribution. The sample size and running time of our algorithm are optimal up to logarithmic factors. The "approximation factor" $C$ in our result is inherent in the problem, as we prove that no algorithm with sample size bounded in terms of $k$ and $\epsilon$ can achieve $C<2$ regardless of what kind of hypothesis distribution it uses.