 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Prosocial Ranking Challenge: Reducing Polarization on Social Media without Sacrificing Engagement
Mar 20, 2026We report the first direct comparisons of multiple alternative social media algorithms on multiple platforms on outcomes of societal interest. We used a browser extension to modify which posts were shown to desktop social media users, randomly assigning 9,386 users to a control group or one of five alternative ranking algorithms which simultaneously altered content across three platforms for six months during the US 2024 presidential election. This reduced our preregistered index of affective polarization by an average of 0.03 standard deviations (p < 0.05), including a 1.5 degree decrease in differences between the 100 point inparty and outparty feeling thermometers. We saw reductions in active use time for Facebook (-0.37 min/day) and Reddit (-0.2 min/day), but an increase of 0.32 min/day (p < 0.01) for X/Twitter. We saw an increase in reports of negative social media experiences but found no effects on well-being, news knowledge, outgroup empathy, perceptions of and support for partisan violence. This implies that bridging content can improve some societal outcomes without necessarily conflicting with the engagement-driven business model of social media.
Labeling Messages as AI-Generated Does Not Reduce Their Persuasive Effects
Apr 14, 2025



As generative artificial intelligence (AI) enables the creation and dissemination of information at massive scale and speed, it is increasingly important to understand how people perceive AI-generated content. One prominent policy proposal requires explicitly labeling AI-generated content to increase transparency and encourage critical thinking about the information, but prior research has not yet tested the effects of such labels. To address this gap, we conducted a survey experiment (N=1601) on a diverse sample of Americans, presenting participants with an AI-generated message about several public policies (e.g., allowing colleges to pay student-athletes), randomly assigning whether participants were told the message was generated by (a) an expert AI model, (b) a human policy expert, or (c) no label. We found that messages were generally persuasive, influencing participants' views of the policies by 9.74 percentage points on average. However, while 94.6% of participants assigned to the AI and human label conditions believed the authorship labels, labels had no significant effects on participants' attitude change toward the policies, judgments of message accuracy, nor intentions to share the message with others. These patterns were robust across a variety of participant characteristics, including prior knowledge of the policy, prior experience with AI, political party, education level, or age. Taken together, these results imply that, while authorship labels would likely enhance transparency, they are unlikely to substantially affect the persuasiveness of the labeled content, highlighting the need for alternative strategies to address challenges posed by AI-generated information.
Generative Agent Simulations of 1,000 People
Nov 15, 2024



The promise of human behavioral simulation--general-purpose computational agents that replicate human behavior across domains--could enable broad applications in policymaking and social science. We present a novel agent architecture that simulates the attitudes and behaviors of 1,052 real individuals--applying large language models to qualitative interviews about their lives, then measuring how well these agents replicate the attitudes and behaviors of the individuals that they represent. The generative agents replicate participants' responses on the General Social Survey 85% as accurately as participants replicate their own answers two weeks later, and perform comparably in predicting personality traits and outcomes in experimental replications. Our architecture reduces accuracy biases across racial and ideological groups compared to agents given demographic descriptions. This work provides a foundation for new tools that can help investigate individual and collective behavior.
Regional Negative Bias in Word Embeddings Predicts Racial Animus--but only via Name Frequency
Jan 20, 2022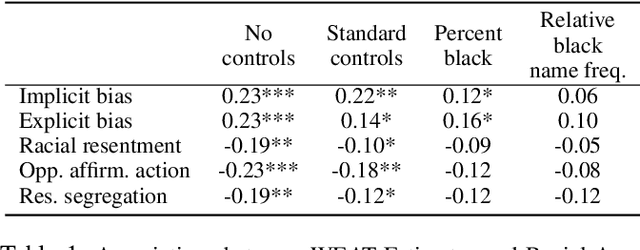
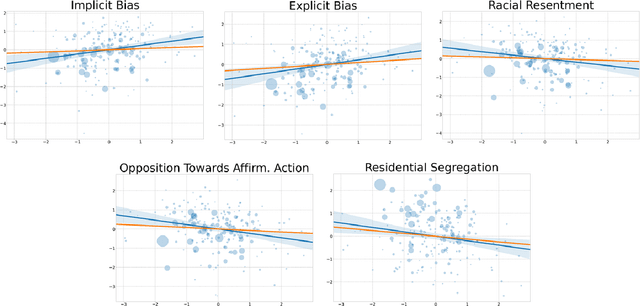
The word embedding association test (WEAT) is an important method for measuring linguistic biases against social groups such as ethnic minorities in large text corpora. It does so by comparing the semantic relatedness of words prototypical of the groups (e.g., names unique to those groups) and attribute words (e.g., 'pleasant' and 'unpleasant' words). We show that anti-black WEAT estimates from geo-tagged social media data at the level of metropolitan statistical areas strongly correlate with several measures of racial animus--even when controlling for sociodemographic covariates. However, we also show that every one of these correlations is explained by a third variable: the frequency of Black names in the underlying corpora relative to White names. This occurs because word embeddings tend to group positive (negative) words and frequent (rare) words together in the estimated semantic space. As the frequency of Black names on social media is strongly correlated with Black Americans' prevalence in the population, this results in spurious anti-Black WEAT estimates wherever few Black Americans live. This suggests that research using the WEAT to measure bias should consider term frequency, and also demonstrates the potential consequences of using black-box models like word embeddings to study human cognition and behavior.