 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning for Mediation in Armed Conflicts
Aug 26, 2021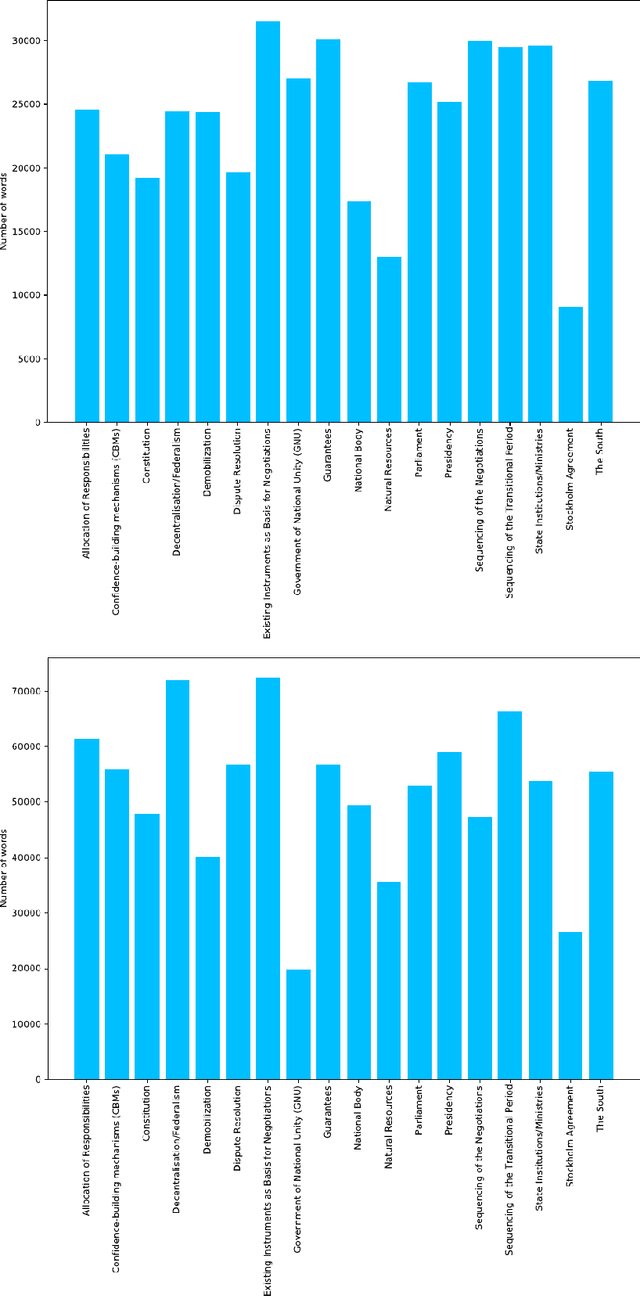
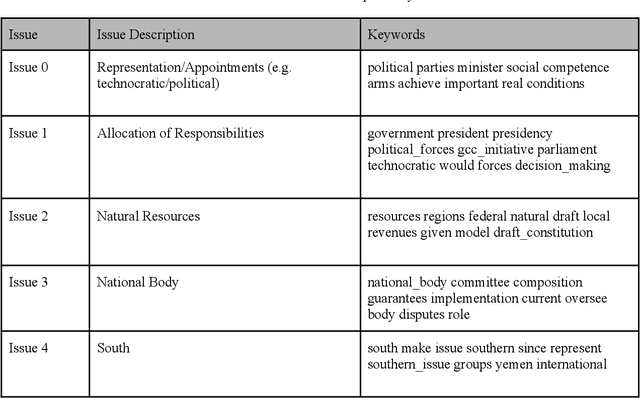
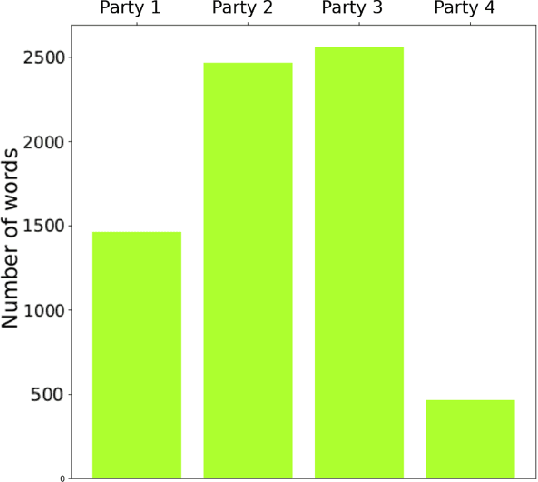
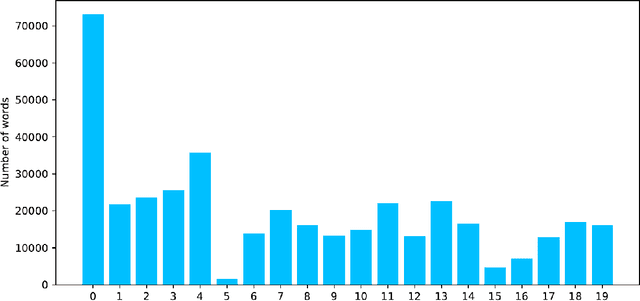
Today's conflicts are becoming increasingly complex, fluid and fragmented, often involving a host of national and international actors with multiple and often divergent interests. This development poses significant challenges for conflict mediation, as mediators struggle to make sense of conflict dynamics, such as the range of conflict parties and the evolution of their political positions, the distinction between relevant and less relevant actors in peace making, or the identification of key conflict issues and their interdependence. International peace efforts appear increasingly ill-equipped to successfully address these challenges. While technology is being increasingly used in a range of conflict related fields, such as conflict predicting or information gathering, less attention has been given to how technology can contribute to conflict mediation. This case study is the first to apply state-of-the-art machine learning technologies to data from an ongoing mediation process. Using dialogue transcripts from peace negotiations in Yemen, this study shows how machine-learning tools can effectively support international mediators by managing knowledge and offering additional conflict analysis tools to assess complex information. Apart from illustrating the potential of machine learning tools in conflict mediation, the paper also emphasises the importance of interdisciplinary and participatory research design for the development of context-sensitive and targeted tools and to ensure meaningful and responsible implementation.
Evaluation of Thematic Coherence in Microblogs
Jun 30, 2021
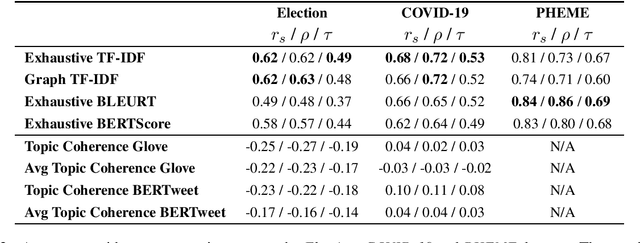


Collecting together microblogs representing opinions about the same topics within the same timeframe is useful to a number of different tasks and practitioners. A major question is how to evaluate the quality of such thematic clusters. Here we create a corpus of microblog clusters from three different domains and time windows and define the task of evaluating thematic coherence. We provide annotation guidelines and human annotations of thematic coherence by journalist experts. We subsequently investigate the efficacy of different automated evaluation metrics for the task. We consider a range of metrics including surface level metrics, ones for topic model coherence and text generation metrics (TGMs). While surface level metrics perform well, outperforming topic coherence metrics, they are not as consistent as TGMs. TGMs are more reliable than all other metrics considered for capturing thematic coherence in microblog clusters due to being less sensitive to the effect of time windows.
A Query-Driven Topic Model
Jun 22, 2021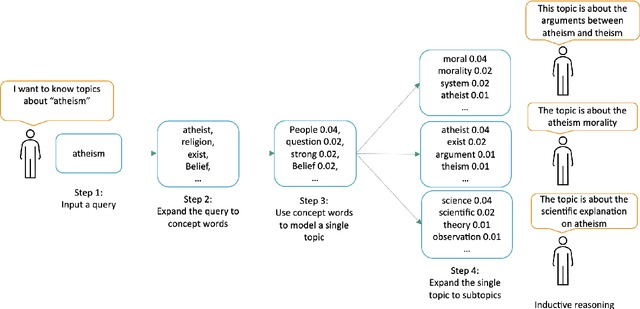
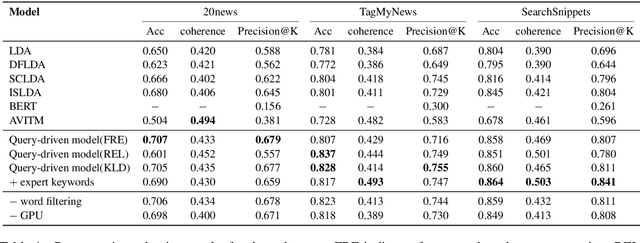
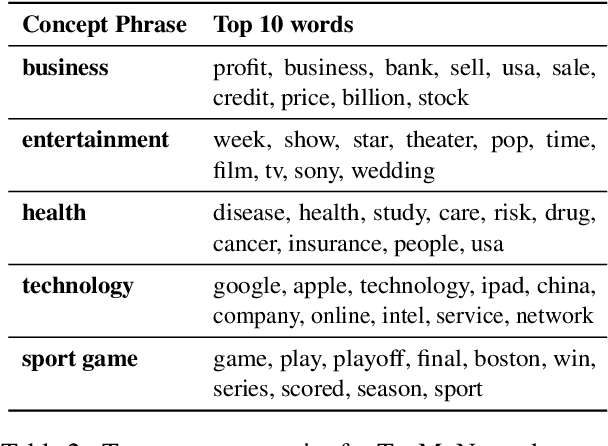

Topic modeling is an unsupervised method for revealing the hidden semantic structure of a corpus. It has been increasingly widely adopted as a tool in the social sciences, including political science, digital humanities and sociological research in general. One desirable property of topic models is to allow users to find topics describing a specific aspect of the corpus. A possible solution is to incorporate domain-specific knowledge into topic modeling, but this requires a specification from domain experts. We propose a novel query-driven topic model that allows users to specify a simple query in words or phrases and return query-related topics, thus avoiding tedious work from domain experts. Our proposed approach is particularly attractive when the user-specified query has a low occurrence in a text corpus, making it difficult for traditional topic models built on word cooccurrence patterns to identify relevant topics. Experimental results demonstrate the effectiveness of our model in comparison with both classical topic models and neural topic models.
Citizen Participation and Machine Learning for a Better Democracy
Feb 28, 2021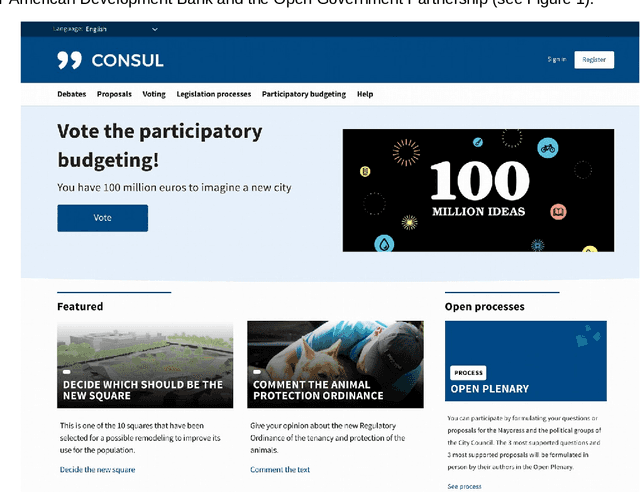

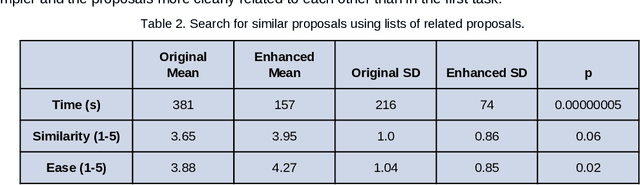
The development of democratic systems is a crucial task as confirmed by its selection as one of the Millennium Sustainable Development Goals by the United Nations. In this article, we report on the progress of a project that aims to address barriers, one of which is information overload, to achieving effective direct citizen participation in democratic decision-making processes. The main objectives are to explore if the application of Natural Language Processing (NLP) and machine learning can improve citizens' experience of digital citizen participation platforms. Taking as a case study the "Decide Madrid" Consul platform, which enables citizens to post proposals for policies they would like to see adopted by the city council, we used NLP and machine learning to provide new ways to (a) suggest to citizens proposals they might wish to support; (b) group citizens by interests so that they can more easily interact with each other; (c) summarise comments posted in response to proposals; (d) assist citizens in aggregating and developing proposals. Evaluation of the results confirms that NLP and machine learning have a role to play in addressing some of the barriers users of platforms such as Consul currently experience.
Detection and Resolution of Rumours in Social Media: A Survey
Apr 03, 2018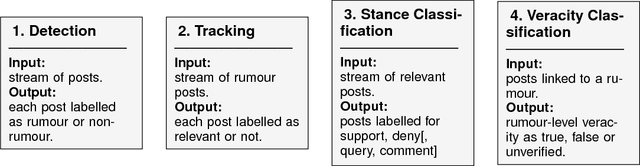
Despite the increasing use of social media platforms for information and news gathering, its unmoderated nature often leads to the emergence and spread of rumours, i.e. pieces of information that are unverified at the time of posting. At the same time, the openness of social media platforms provides opportunities to study how users share and discuss rumours, and to explore how natural language processing and data mining techniques may be used to find ways of determining their veracity. In this survey we introduce and discuss two types of rumours that circulate on social media; long-standing rumours that circulate for long periods of time, and newly-emerging rumours spawned during fast-paced events such as breaking news, where reports are released piecemeal and often with an unverified status in their early stages. We provide an overview of research into social media rumours with the ultimate goal of developing a rumour classification system that consists of four components: rumour detection, rumour tracking, rumour stance classification and rumour veracity classification. We delve into the approaches presented in the scientific literature for the development of each of these four components. We summarise the efforts and achievements so far towards the development of rumour classification systems and conclude with suggestions for avenues for future research in social media mining for detection and resolution of rumours.
* ACM Computing Surveys
Political Homophily in Independence Movements: Analysing and Classifying Social Media Users by National Identity
Mar 21, 2018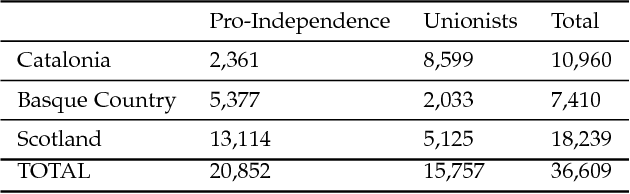
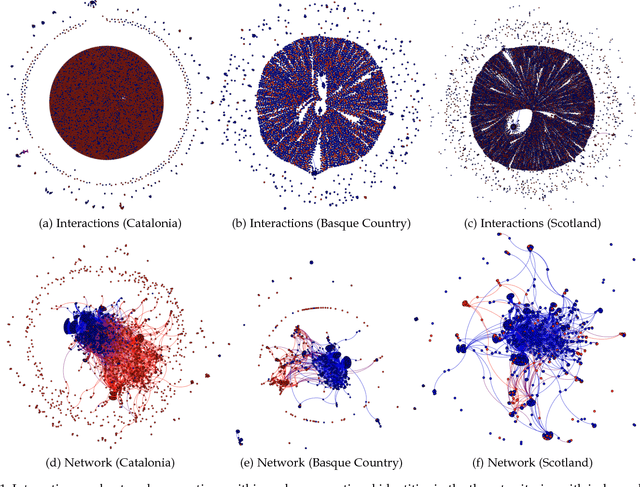
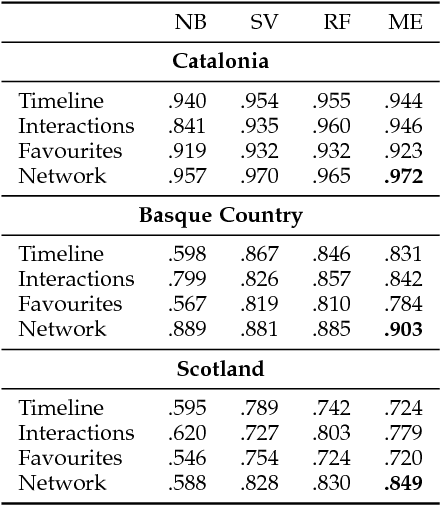
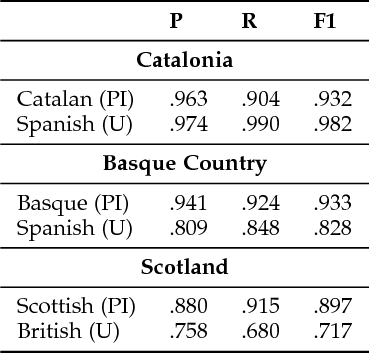
Social media and data mining are increasingly being used to analyse political and societal issues. Here we undertake the classification of social media users as supporting or opposing ongoing independence movements in their territories. Independence movements occur in territories whose citizens have conflicting national identities; users with opposing national identities will then support or oppose the sense of being part of an independent nation that differs from the officially recognised country. We describe a methodology that relies on users' self-reported location to build large-scale datasets for three territories -- Catalonia, the Basque Country and Scotland. An analysis of these datasets shows that homophily plays an important role in determining who people connect with, as users predominantly choose to follow and interact with others from the same national identity. We show that a classifier relying on users' follow networks can achieve accurate, language-independent classification performances ranging from 85% to 97% for the three territories.
Discourse-Aware Rumour Stance Classification in Social Media Using Sequential Classifiers
Dec 06, 2017
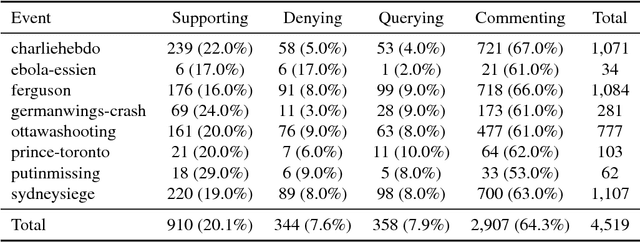
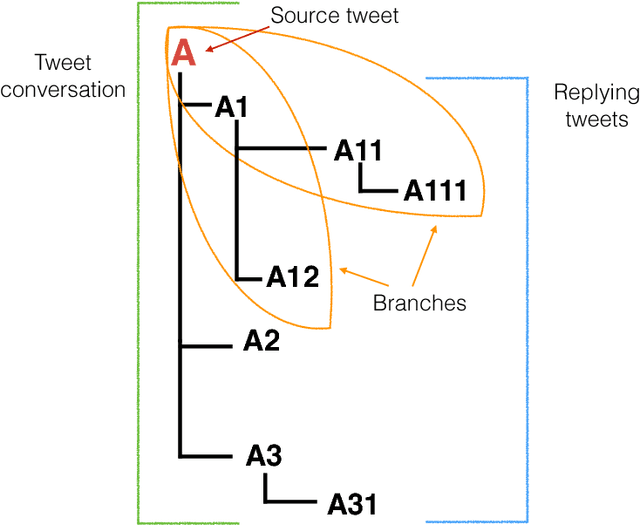
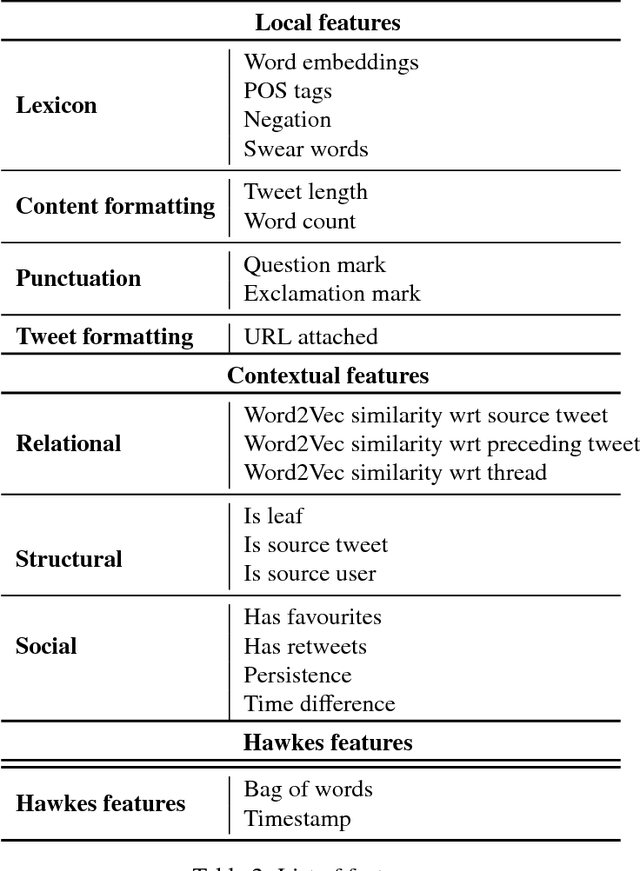
Rumour stance classification, defined as classifying the stance of specific social media posts into one of supporting, denying, querying or commenting on an earlier post, is becoming of increasing interest to researchers. While most previous work has focused on using individual tweets as classifier inputs, here we report on the performance of sequential classifiers that exploit the discourse features inherent in social media interactions or 'conversational threads'. Testing the effectiveness of four sequential classifiers -- Hawkes Processes, Linear-Chain Conditional Random Fields (Linear CRF), Tree-Structured Conditional Random Fields (Tree CRF) and Long Short Term Memory networks (LSTM) -- on eight datasets associated with breaking news stories, and looking at different types of local and contextual features, our work sheds new light on the development of accurate stance classifiers. We show that sequential classifiers that exploit the use of discourse properties in social media conversations while using only local features, outperform non-sequential classifiers. Furthermore, we show that LSTM using a reduced set of features can outperform the other sequential classifiers; this performance is consistent across datasets and across types of stances. To conclude, our work also analyses the different features under study, identifying those that best help characterise and distinguish between stances, such as supporting tweets being more likely to be accompanied by evidence than denying tweets. We also set forth a number of directions for future research.
Towards Real-Time, Country-Level Location Classification of Worldwide Tweets
Apr 25, 2017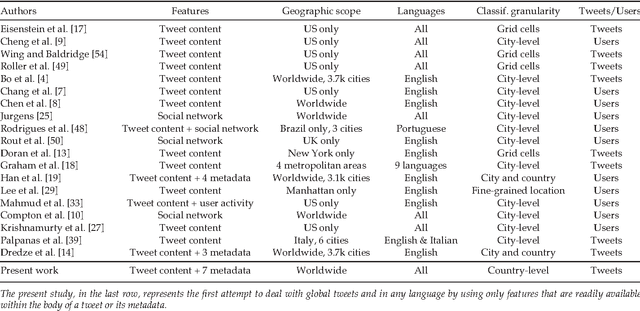
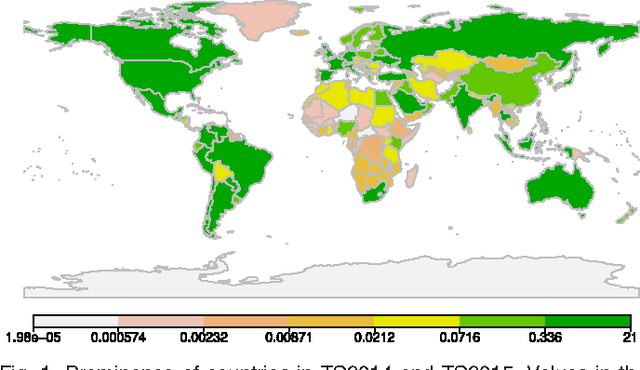

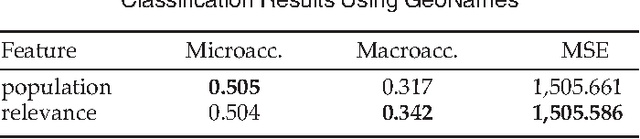
In contrast to much previous work that has focused on location classification of tweets restricted to a specific country, here we undertake the task in a broader context by classifying global tweets at the country level, which is so far unexplored in a real-time scenario. We analyse the extent to which a tweet's country of origin can be determined by making use of eight tweet-inherent features for classification. Furthermore, we use two datasets, collected a year apart from each other, to analyse the extent to which a model trained from historical tweets can still be leveraged for classification of new tweets. With classification experiments on all 217 countries in our datasets, as well as on the top 25 countries, we offer some insights into the best use of tweet-inherent features for an accurate country-level classification of tweets. We find that the use of a single feature, such as the use of tweet content alone -- the most widely used feature in previous work -- leaves much to be desired. Choosing an appropriate combination of both tweet content and metadata can actually lead to substantial improvements of between 20\% and 50\%. We observe that tweet content, the user's self-reported location and the user's real name, all of which are inherent in a tweet and available in a real-time scenario, are particularly useful to determine the country of origin. We also experiment on the applicability of a model trained on historical tweets to classify new tweets, finding that the choice of a particular combination of features whose utility does not fade over time can actually lead to comparable performance, avoiding the need to retrain. However, the difficulty of achieving accurate classification increases slightly for countries with multiple commonalities, especially for English and Spanish speaking countries.
SemEval-2017 Task 8: RumourEval: Determining rumour veracity and support for rumours
Apr 20, 2017
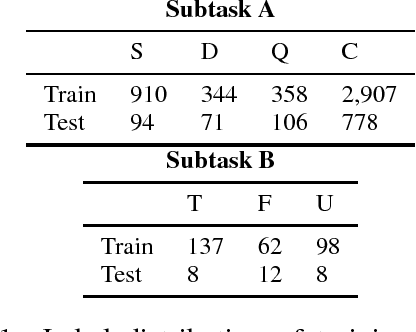

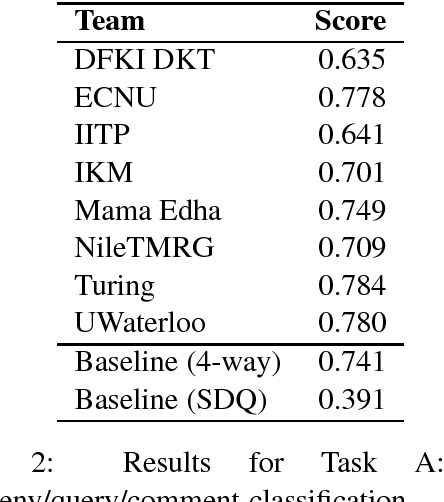
Media is full of false claims. Even Oxford Dictionaries named "post-truth" as the word of 2016. This makes it more important than ever to build systems that can identify the veracity of a story, and the kind of discourse there is around it. RumourEval is a SemEval shared task that aims to identify and handle rumours and reactions to them, in text. We present an annotation scheme, a large dataset covering multiple topics - each having their own families of claims and replies - and use these to pose two concrete challenges as well as the results achieved by participants on these challenges.
Learning Reporting Dynamics during Breaking News for Rumour Detection in Social Media
Oct 24, 2016
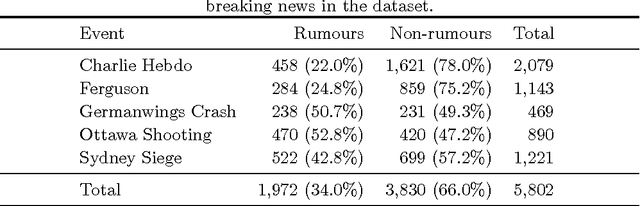
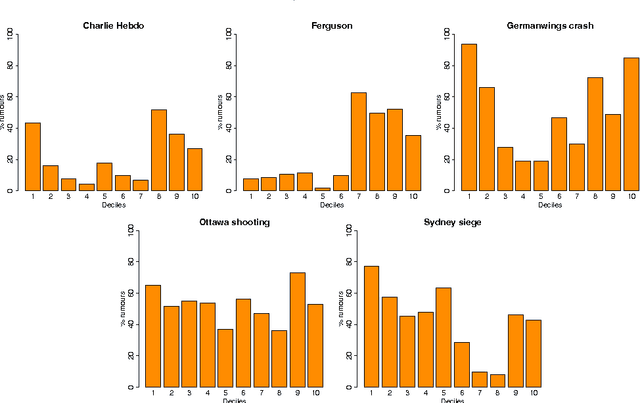
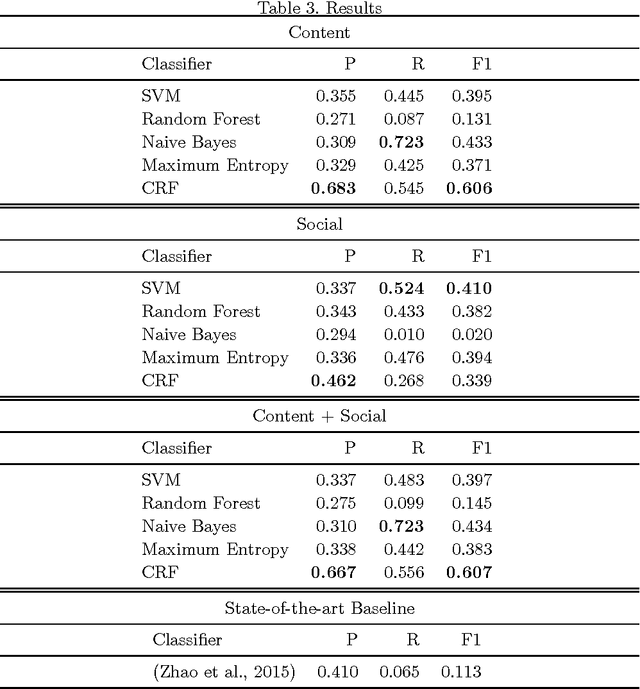
Breaking news leads to situations of fast-paced reporting in social media, producing all kinds of updates related to news stories, albeit with the caveat that some of those early updates tend to be rumours, i.e., information with an unverified status at the time of posting. Flagging information that is unverified can be helpful to avoid the spread of information that may turn out to be false. Detection of rumours can also feed a rumour tracking system that ultimately determines their veracity. In this paper we introduce a novel approach to rumour detection that learns from the sequential dynamics of reporting during breaking news in social media to detect rumours in new stories. Using Twitter datasets collected during five breaking news stories, we experiment with Conditional Random Fields as a sequential classifier that leverages context learnt during an event for rumour detection, which we compare with the state-of-the-art rumour detection system as well as other baselines. In contrast to existing work, our classifier does not need to observe tweets querying a piece of information to deem it a rumour, but instead we detect rumours from the tweet alone by exploiting context learnt during the event. Our classifier achieves competitive performance, beating the state-of-the-art classifier that relies on querying tweets with improved precision and recall, as well as outperforming our best baseline with nearly 40% improvement in terms of F1 score. The scale and diversity of our experiments reinforces the generalisability of our classifier.