 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevelopment and Characterization of a Chest CT Atlas
Dec 05, 2020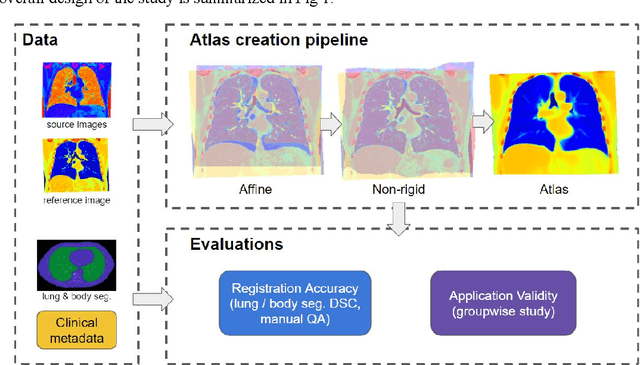

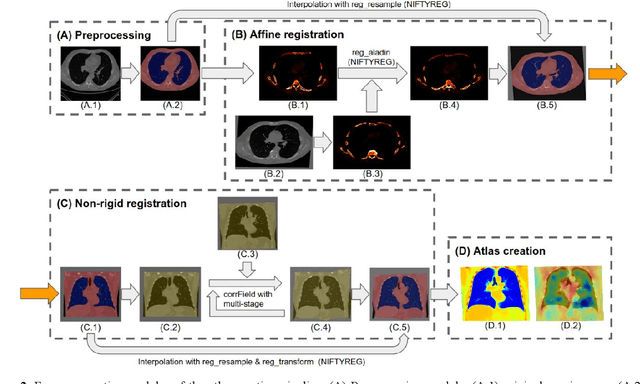
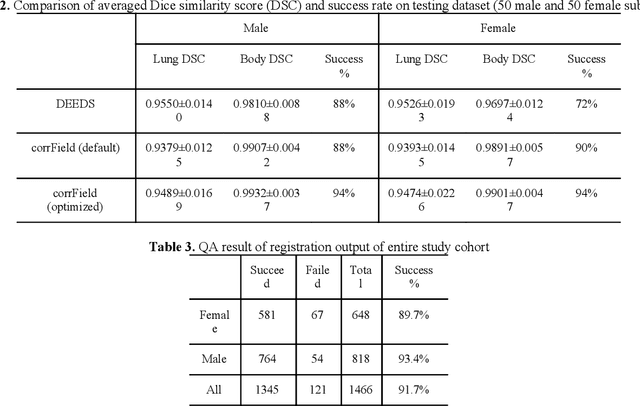
A major goal of lung cancer screening is to identify individuals with particular phenotypes that are associated with high risk of cancer. Identifying relevant phenotypes is complicated by the variation in body position and body composition. In the brain, standardized coordinate systems (e.g., atlases) have enabled separate consideration of local features from gross/global structure. To date, no analogous standard atlas has been presented to enable spatial mapping and harmonization in chest computational tomography (CT). In this paper, we propose a thoracic atlas built upon a large low dose CT (LDCT) database of lung cancer screening program. The study cohort includes 466 male and 387 female subjects with no screening detected malignancy (age 46-79 years, mean 64.9 years). To provide spatial mapping, we optimize a multi-stage inter-subject non-rigid registration pipeline for the entire thoracic space. We evaluate the optimized pipeline relative to two baselines with alternative non-rigid registration module: the same software with default parameters and an alternative software. We achieve a significant improvement in terms of registration success rate based on manual QA. For the entire study cohort, the optimized pipeline achieves a registration success rate of 91.7%. The application validity of the developed atlas is evaluated in terms of discriminative capability for different anatomic phenotypes, including body mass index (BMI), chronic obstructive pulmonary disease (COPD), and coronary artery calcification (CAC).
Deep Multi-path Network Integrating Incomplete Biomarker and Chest CT Data for Evaluating Lung Cancer Risk
Oct 19, 2020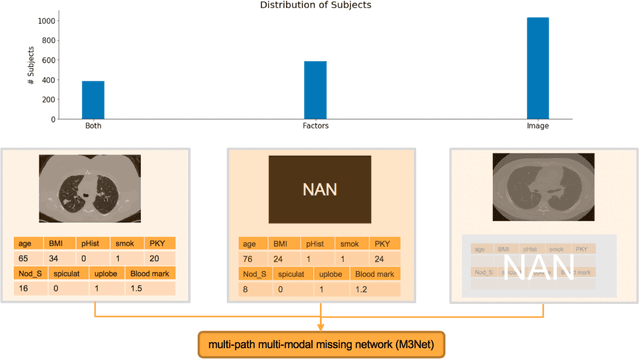
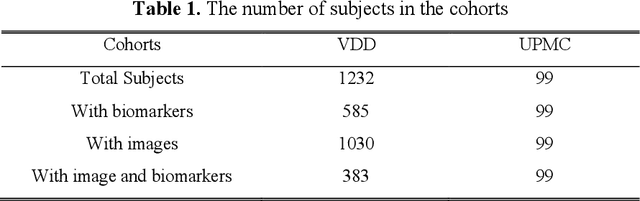
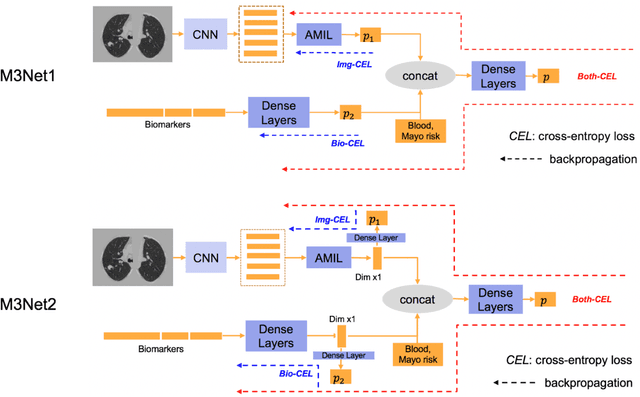
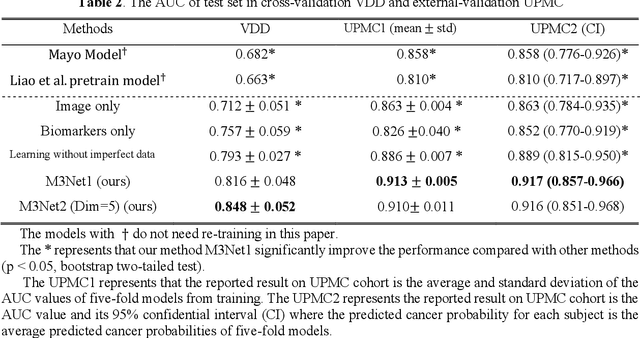
Clinical data elements (CDEs) (e.g., age, smoking history), blood markers and chest computed tomography (CT) structural features have been regarded as effective means for assessing lung cancer risk. These independent variables can provide complementary information and we hypothesize that combining them will improve the prediction accuracy. In practice, not all patients have all these variables available. In this paper, we propose a new network design, termed as multi-path multi-modal missing network (M3Net), to integrate the multi-modal data (i.e., CDEs, biomarker and CT image) considering missing modality with multiple paths neural network. Each path learns discriminative features of one modality, and different modalities are fused in a second stage for an integrated prediction. The network can be trained end-to-end with both medical image features and CDEs/biomarkers, or make a prediction with single modality. We evaluate M3Net with datasets including three sites from the Consortium for Molecular and Cellular Characterization of Screen-Detected Lesions (MCL) project. Our method is cross validated within a cohort of 1291 subjects (383 subjects with complete CDEs/biomarkers and CT images), and externally validated with a cohort of 99 subjects (99 with complete CDEs/biomarkers and CT images). Both cross-validation and external-validation results show that combining multiple modality significantly improves the predicting performance of single modality. The results suggest that integrating subjects with missing either CDEs/biomarker or CT imaging features can contribute to the discriminatory power of our model (p < 0.05, bootstrap two-tailed test). In summary, the proposed M3Net framework provides an effective way to integrate image and non-image data in the context of missing information.
Validation and Optimization of Multi-Organ Segmentation on Clinical Imaging Archives
Feb 10, 2020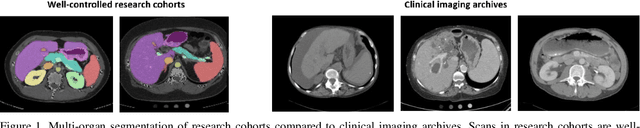
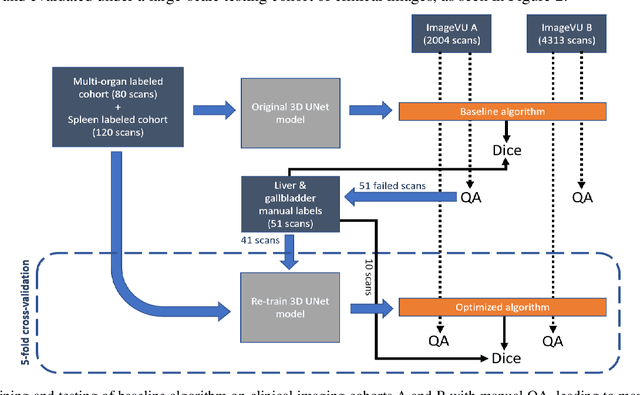
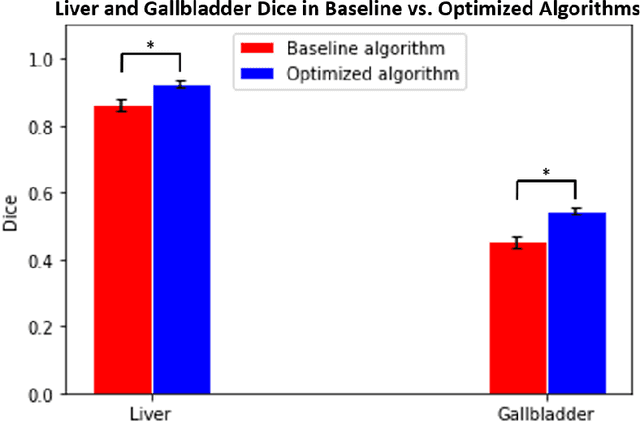
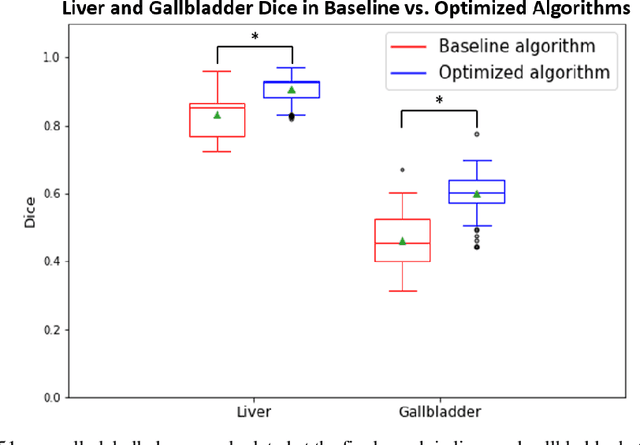
Segmentation of abdominal computed tomography(CT) provides spatial context, morphological properties, and a framework for tissue-specific radiomics to guide quantitative Radiological assessment. A 2015 MICCAI challenge spurred substantial innovation in multi-organ abdominal CT segmentation with both traditional and deep learning methods. Recent innovations in deep methods have driven performance toward levels for which clinical translation is appealing. However, continued cross-validation on open datasets presents the risk of indirect knowledge contamination and could result in circular reasoning. Moreover, 'real world' segmentations can be challenging due to the wide variability of abdomen physiology within patients. Herein, we perform two data retrievals to capture clinically acquired deidentified abdominal CT cohorts with respect to a recently published variation on 3D U-Net (baseline algorithm). First, we retrieved 2004 deidentified studies on 476 patients with diagnosis codes involving spleen abnormalities (cohort A). Second, we retrieved 4313 deidentified studies on 1754 patients without diagnosis codes involving spleen abnormalities (cohort B). We perform prospective evaluation of the existing algorithm on both cohorts, yielding 13% and 8% failure rate, respectively. Then, we identified 51 subjects in cohort A with segmentation failures and manually corrected the liver and gallbladder labels. We re-trained the model adding the manual labels, resulting in performance improvement of 9% and 6% failure rate for the A and B cohorts, respectively. In summary, the performance of the baseline on the prospective cohorts was similar to that on previously published datasets. Moreover, adding data from the first cohort substantively improved performance when evaluated on the second withheld validation cohort.
Outlier Guided Optimization of Abdominal Segmentation
Feb 10, 2020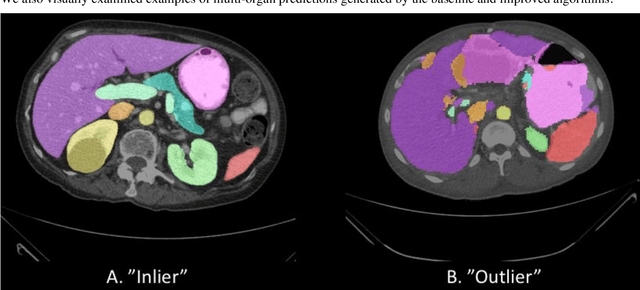
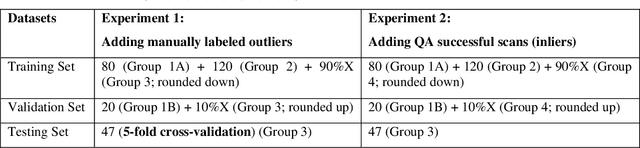
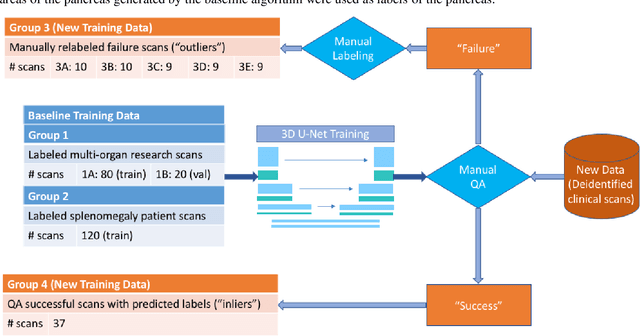
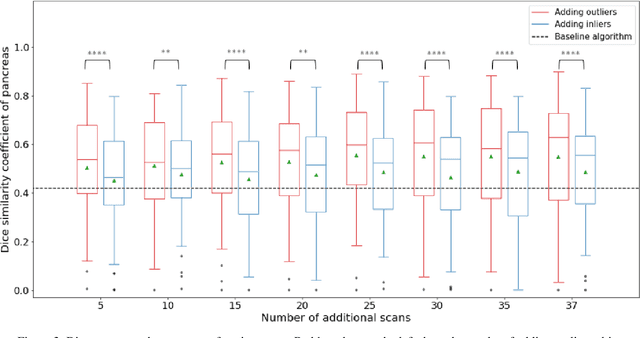
Abdominal multi-organ segmentation of computed tomography (CT) images has been the subject of extensive research interest. It presents a substantial challenge in medical image processing, as the shape and distribution of abdominal organs can vary greatly among the population and within an individual over time. While continuous integration of novel datasets into the training set provides potential for better segmentation performance, collection of data at scale is not only costly, but also impractical in some contexts. Moreover, it remains unclear what marginal value additional data have to offer. Herein, we propose a single-pass active learning method through human quality assurance (QA). We built on a pre-trained 3D U-Net model for abdominal multi-organ segmentation and augmented the dataset either with outlier data (e.g., exemplars for which the baseline algorithm failed) or inliers (e.g., exemplars for which the baseline algorithm worked). The new models were trained using the augmented datasets with 5-fold cross-validation (for outlier data) and withheld outlier samples (for inlier data). Manual labeling of outliers increased Dice scores with outliers by 0.130, compared to an increase of 0.067 with inliers (p<0.001, two-tailed paired t-test). By adding 5 to 37 inliers or outliers to training, we find that the marginal value of adding outliers is higher than that of adding inliers. In summary, improvement on single-organ performance was obtained without diminishing multi-organ performance or significantly increasing training time. Hence, identification and correction of baseline failure cases present an effective and efficient method of selecting training data to improve algorithm performance.
Internal-transfer Weighting of Multi-task Learning for Lung Cancer Detection
Dec 16, 2019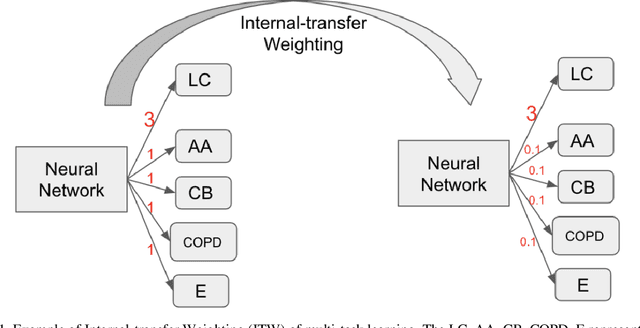
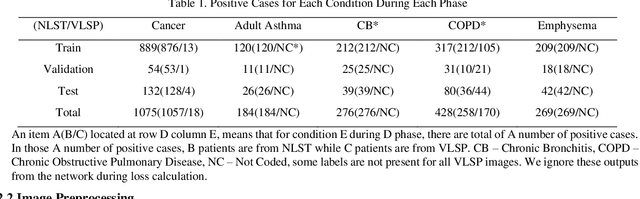
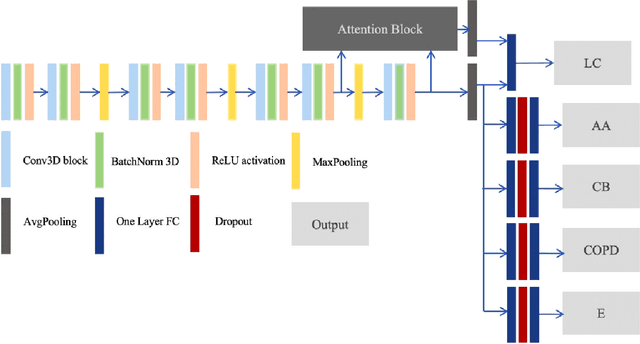
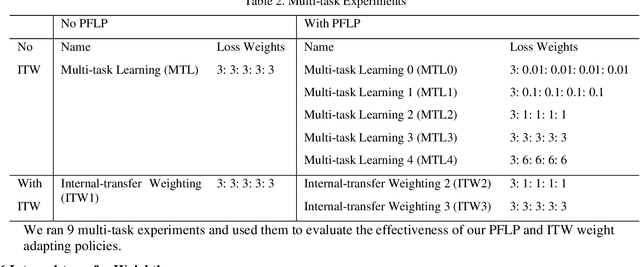
Recently, multi-task networks have shown to both offer additional estimation capabilities, and, perhaps more importantly, increased performance over single-task networks on a "main/primary" task. However, balancing the optimization criteria of multi-task networks across different tasks is an area of active exploration. Here, we extend a previously proposed 3D attention-based network with four additional multi-task subnetworks for the detection of lung cancer and four auxiliary tasks (diagnosis of asthma, chronic bronchitis, chronic obstructive pulmonary disease, and emphysema). We introduce and evaluate a learning policy, Periodic Focusing Learning Policy (PFLP), that alternates the dominance of tasks throughout the training. To improve performance on the primary task, we propose an Internal-Transfer Weighting (ITW) strategy to suppress the loss functions on auxiliary tasks for the final stages of training. To evaluate this approach, we examined 3386 patients (single scan per patient) from the National Lung Screening Trial (NLST) and de-identified data from the Vanderbilt Lung Screening Program, with a 2517/277/592 (scans) split for training, validation, and testing. Baseline networks include a single-task strategy and a multi-task strategy without adaptive weights (PFLP/ITW), while primary experiments are multi-task trials with either PFLP or ITW or both. On the test set for lung cancer prediction, the baseline single-task network achieved prediction AUC of 0.8080 and the multi-task baseline failed to converge (AUC 0.6720). However, applying PFLP helped multi-task network clarify and achieved test set lung cancer prediction AUC of 0.8402. Furthermore, our ITW technique boosted the PFLP enabled multi-task network and achieved an AUC of 0.8462 (McNemar test, p < 0.01).
Contrast Phase Classification with a Generative Adversarial Network
Nov 14, 2019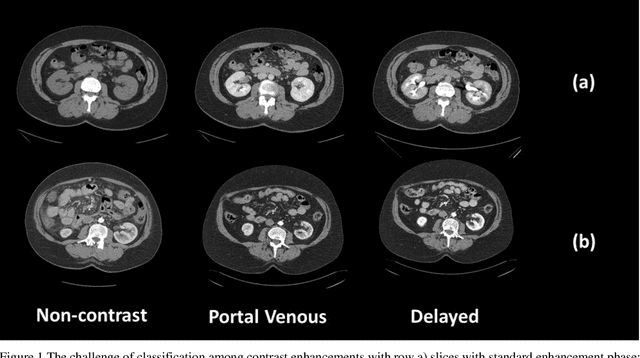
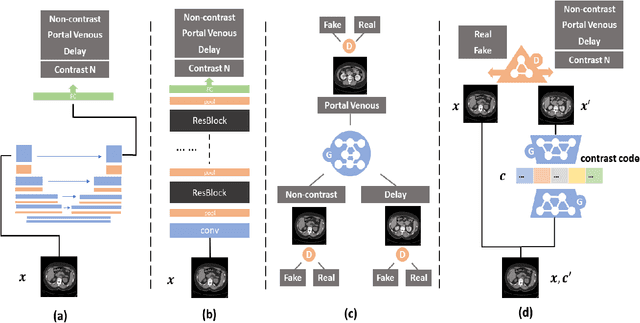
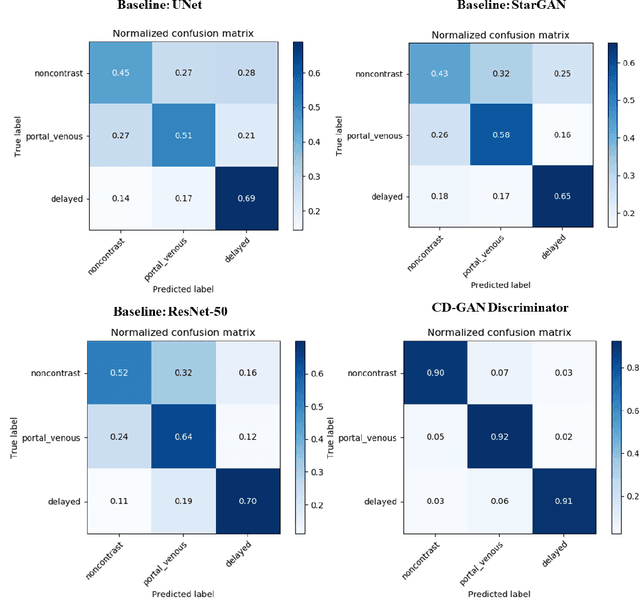
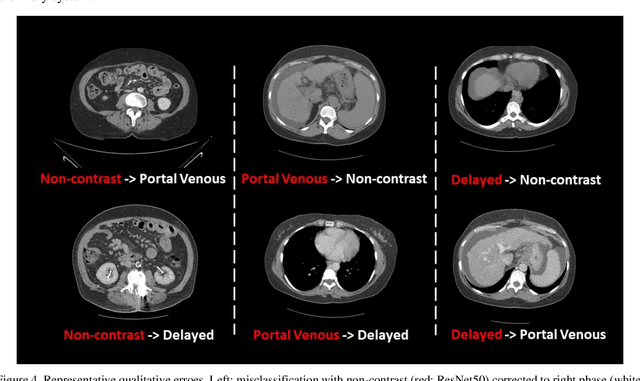
Dynamic contrast enhanced computed tomography (CT) is an imaging technique that provides critical information on the relationship of vascular structure and dynamics in the context of underlying anatomy. A key challenge for image processing with contrast enhanced CT is that phase discrepancies are latent in different tissues due to contrast protocols, vascular dynamics, and metabolism variance. Previous studies with deep learning frameworks have been proposed for classifying contrast enhancement with networks inspired by computer vision. Here, we revisit the challenge in the context of whole abdomen contrast enhanced CTs. To capture and compensate for the complex contrast changes, we propose a novel discriminator in the form of a multi-domain disentangled representation learning network. The goal of this network is to learn an intermediate representation that separates contrast enhancement from anatomy and enables classification of images with varying contrast time. Briefly, our unpaired contrast disentangling GAN(CD-GAN) Discriminator follows the ResNet architecture to classify a CT scan from different enhancement phases. To evaluate the approach, we trained the enhancement phase classifier on 21060 slices from two clinical cohorts of 230 subjects. Testing was performed on 9100 slices from 30 independent subjects who had been imaged with CT scans from all contrast phases. Performance was quantified in terms of the multi-class normalized confusion matrix. The proposed network significantly improved correspondence over baseline UNet, ResNet50 and StarGAN performance of accuracy scores 0.54. 0.55, 0.62 and 0.91, respectively. The proposed discriminator from the disentangled network presents a promising technique that may allow deeper modeling of dynamic imaging against patient specific anatomies.
* 8 pages, 4 figures
Deep Multi-task Prediction of Lung Cancer and Cancer-free Progression from Censored Heterogenous Clinical Imaging
Nov 12, 2019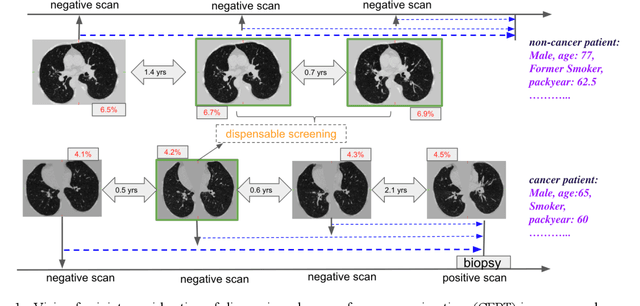
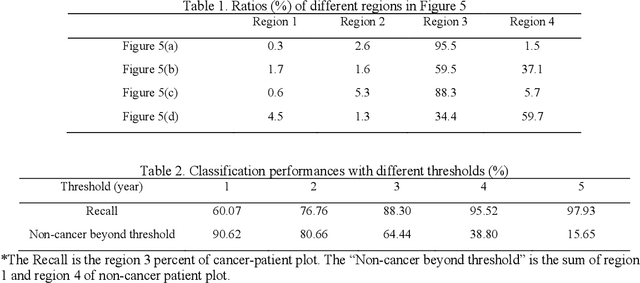
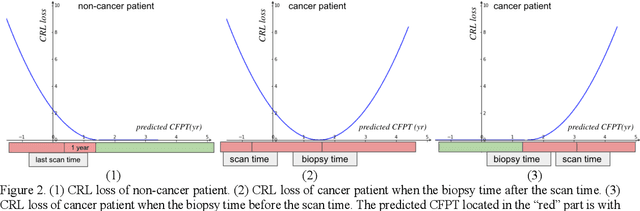
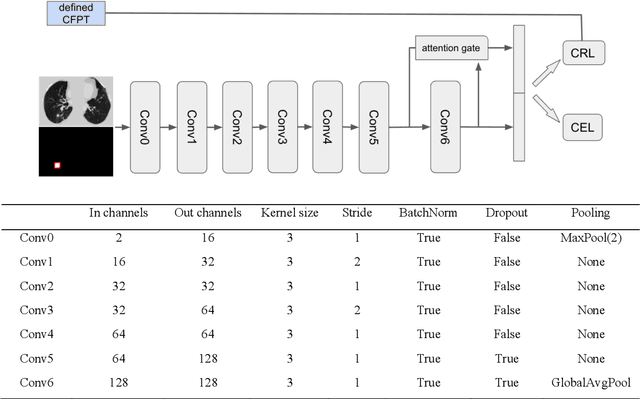
Annual low dose computed tomography (CT) lung screening is currently advised for individuals at high risk of lung cancer (e.g., heavy smokers between 55 and 80 years old). The recommended screening practice significantly reduces all-cause mortality, but the vast majority of screening results are negative for cancer. If patients at very low risk could be identified based on individualized, image-based biomarkers, the health care resources could be more efficiently allocated to higher risk patients and reduce overall exposure to ionizing radiation. In this work, we propose a multi-task (diagnosis and prognosis) deep convolutional neural network to improve the diagnostic accuracy over a baseline model while simultaneously estimating a personalized cancer-free progression time (CFPT). A novel Censored Regression Loss (CRL) is proposed to perform weakly supervised regression so that even single negative screening scans can provide small incremental value. Herein, we study 2287 scans from 1433 de-identified patients from the Vanderbilt Lung Screening Program (VLSP) and Molecular Characterization Laboratories (MCL) cohorts. Using five-fold cross-validation, we train a 3D attention-based network under two scenarios: (1) single-task learning with only classification, and (2) multi-task learning with both classification and regression. The single-task learning leads to a higher AUC compared with the Kaggle challenge winner pre-trained model (0.878 v. 0.856), and multi-task learning significantly improves the single-task one (AUC 0.895, p<0.01, McNemar test). In summary, the image-based predicted CFPT can be used in follow-up year lung cancer prediction and data assessment.
Semi-Supervised Multi-Organ Segmentation through Quality Assurance Supervision
Nov 12, 2019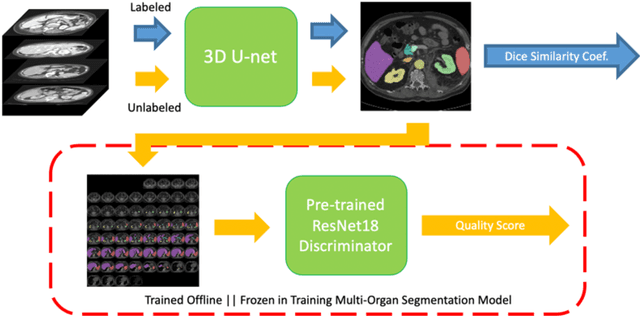
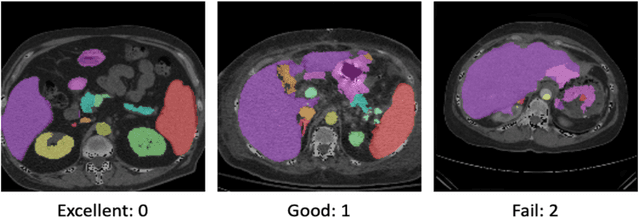
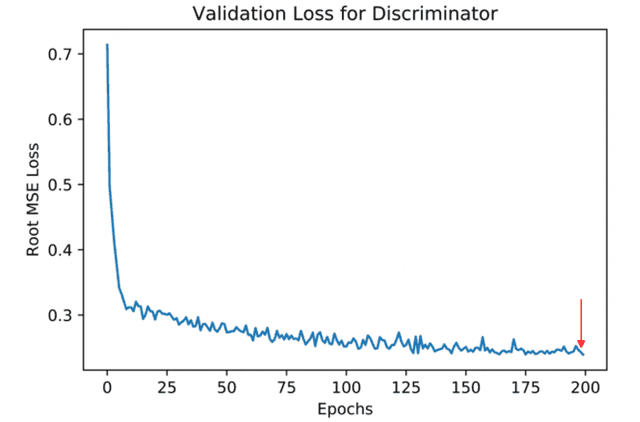
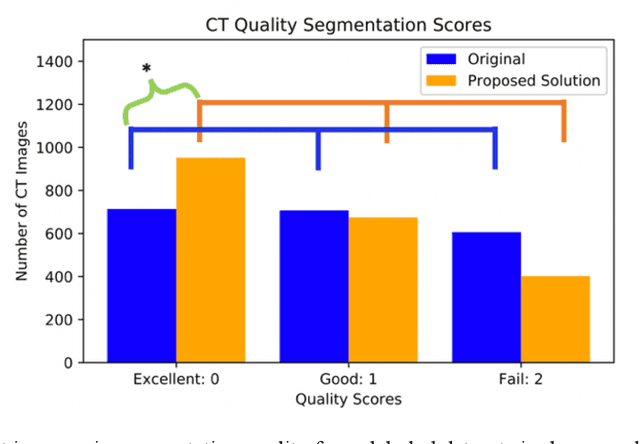
Human in-the-loop quality assurance (QA) is typically performed after medical image segmentation to ensure that the systems are performing as intended, as well as identifying and excluding outliers. By performing QA on large-scale, previously unlabeled testing data, categorical QA scores can be generatedIn this paper, we propose a semi-supervised multi-organ segmentation deep neural network consisting of a traditional segmentation model generator and a QA involved discriminator. A large-scale dataset of 2027 volumes are used to train the generator, whose 2-D montage images and segmentation mask with QA scores are used to train the discriminator. To generate the QA scores, the 2-D montage images were reviewed manually and coded 0 (success), 1 (errors consistent with published performance), and 2 (gross failure). Then, the ResNet-18 network was trained with 1623 montage images in equal distribution of all three code labels and achieved an accuracy 94% for classification predictions with 404 montage images withheld for the test cohort. To assess the performance of using the QA supervision, the discriminator was used as a loss function in a multi-organ segmentation pipeline. The inclusion of QA-loss function boosted performance on the unlabeled test dataset from 714 patients to 951 patients over the baseline model. Additionally, the number of failures decreased from 606 (29.90%) to 402 (19.83%). The contributions of the proposed method are threefold: We show that (1) the QA scores can be used as a loss function to perform semi-supervised learning for unlabeled data, (2) the well trained discriminator is learnt by QA score rather than traditional true/false, and (3) the performance of multi-organ segmentation on unlabeled datasets can be fine-tuned with more robust and higher accuracy than the original baseline method.
Distanced LSTM: Time-Distanced Gates in Long Short-Term Memory Models for Lung Cancer Detection
Sep 11, 2019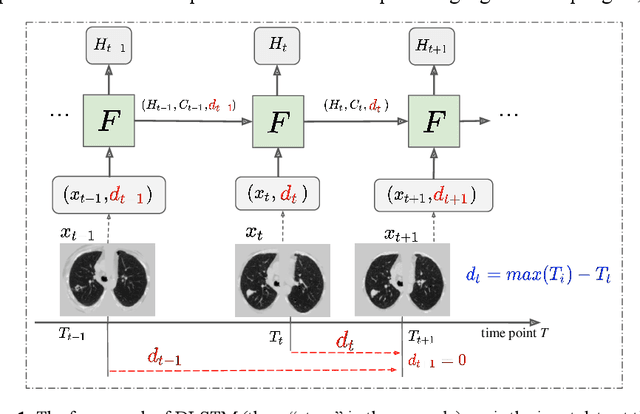
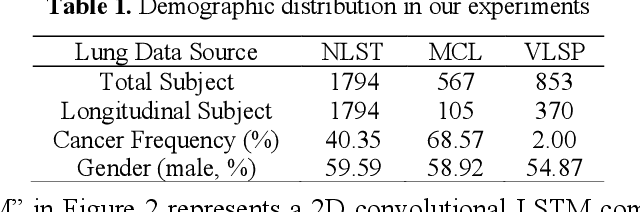
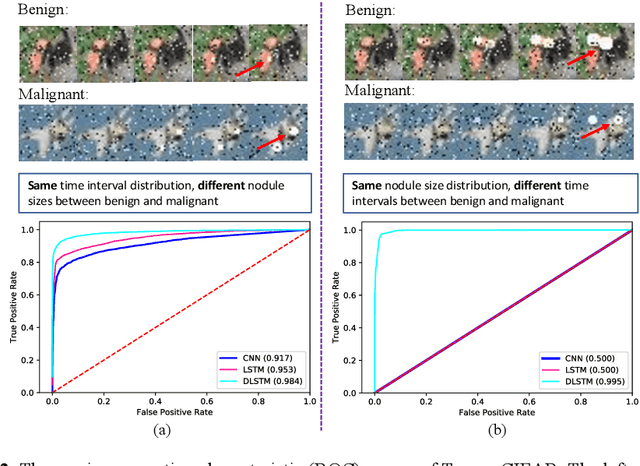
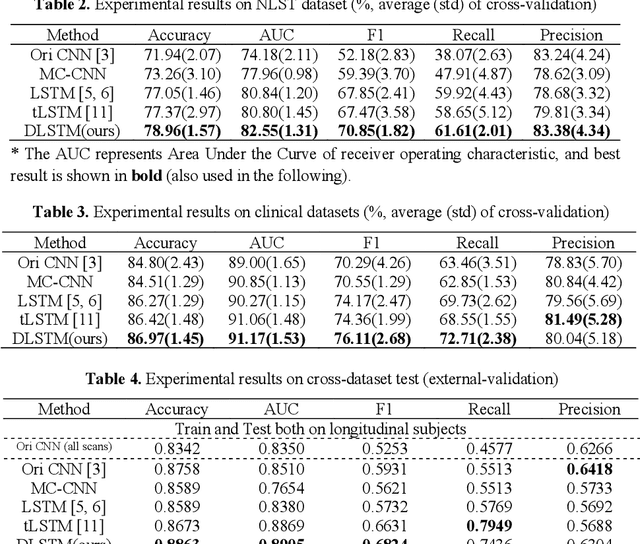
The field of lung nodule detection and cancer prediction has been rapidly developing with the support of large public data archives. Previous studies have largely focused on cross-sectional (single) CT data. Herein, we consider longitudinal data. The Long Short-Term Memory (LSTM) model addresses learning with regularly spaced time points (i.e., equal temporal intervals). However, clinical imaging follows patient needs with often heterogeneous, irregular acquisitions. To model both regular and irregular longitudinal samples, we generalize the LSTM model with the Distanced LSTM (DLSTM) for temporally varied acquisitions. The DLSTM includes a Temporal Emphasis Model (TEM) that enables learning across regularly and irregularly sampled intervals. Briefly, (1) the time intervals between longitudinal scans are modeled explicitly, (2) temporally adjustable forget and input gates are introduced for irregular temporal sampling; and (3) the latest longitudinal scan has an additional emphasis term. We evaluate the DLSTM framework in three datasets including simulated data, 1794 National Lung Screening Trial (NLST) scans, and 1420 clinically acquired data with heterogeneous and irregular temporal accession. The experiments on the first two datasets demonstrate that our method achieves competitive performance on both simulated and regularly sampled datasets (e.g. improve LSTM from 0.6785 to 0.7085 on F1 score in NLST). In external validation of clinically and irregularly acquired data, the benchmarks achieved 0.8350 (CNN feature) and 0.8380 (LSTM) on the area under the ROC curve (AUC) score, while the proposed DLSTM achieves 0.8905.
Lung Cancer Detection using Co-learning from Chest CT Images and Clinical Demographics
Feb 21, 2019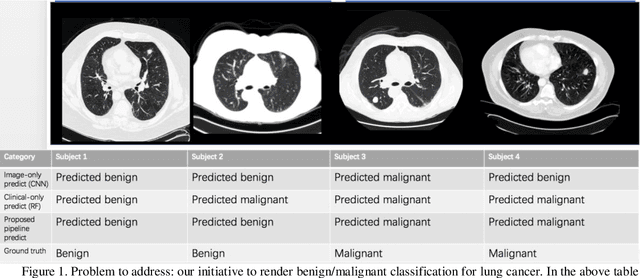
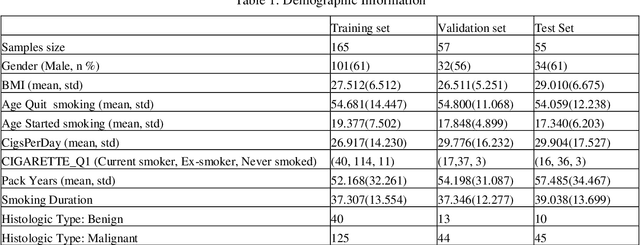
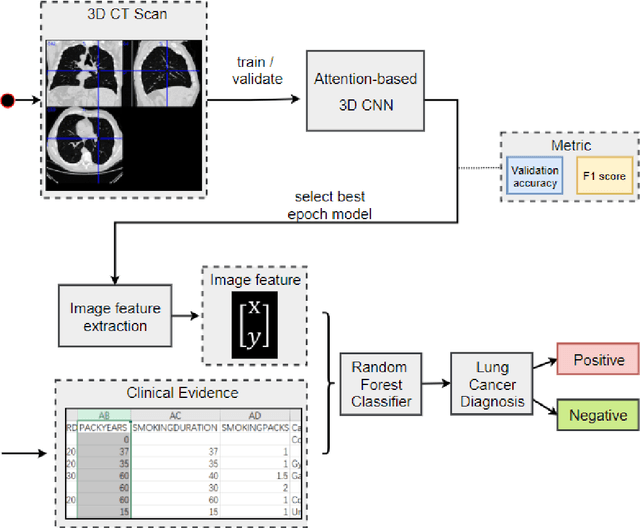
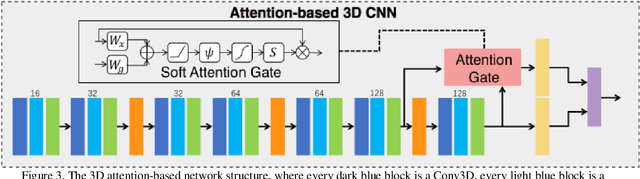
Early detection of lung cancer is essential in reducing mortality. Recent studies have demonstrated the clinical utility of low-dose computed tomography (CT) to detect lung cancer among individuals selected based on very limited clinical information. However, this strategy yields high false positive rates, which can lead to unnecessary and potentially harmful procedures. To address such challenges, we established a pipeline that co-learns from detailed clinical demographics and 3D CT images. Toward this end, we leveraged data from the Consortium for Molecular and Cellular Characterization of Screen-Detected Lesions (MCL), which focuses on early detection of lung cancer. A 3D attention-based deep convolutional neural net (DCNN) is proposed to identify lung cancer from the chest CT scan without prior anatomical location of the suspicious nodule. To improve upon the non-invasive discrimination between benign and malignant, we applied a random forest classifier to a dataset integrating clinical information to imaging data. The results show that the AUC obtained from clinical demographics alone was 0.635 while the attention network alone reached an accuracy of 0.687. In contrast when applying our proposed pipeline integrating clinical and imaging variables, we reached an AUC of 0.787 on the testing dataset. The proposed network both efficiently captures anatomical information for classification and also generates attention maps that explain the features that drive performance.