 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNesT: Local Spatial Representation Learning with Hierarchical Transformer for Efficient Medical Segmentation
Sep 28, 2022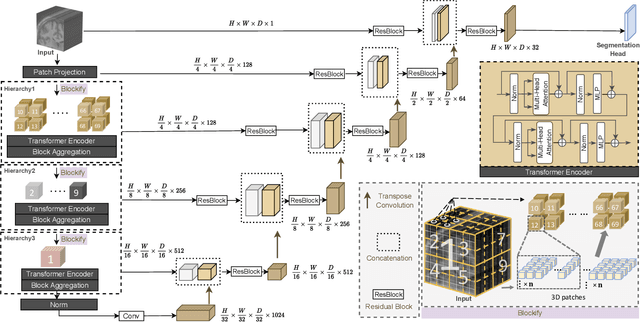

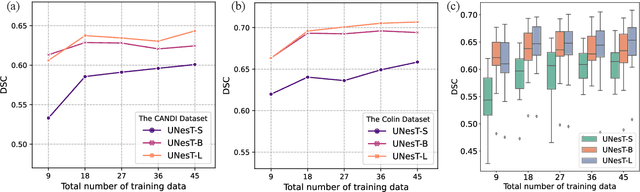
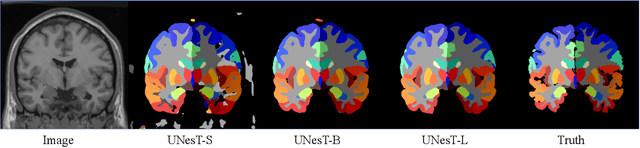
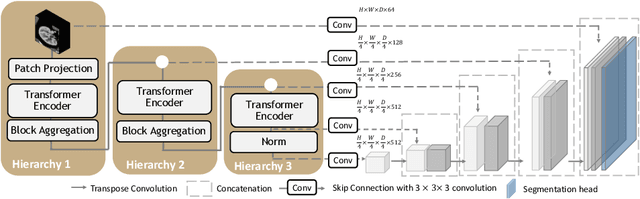
Transformer-based models, capable of learning better global dependencies, have recently demonstrated exceptional representation learning capabilities in computer vision and medical image analysis. Transformer reformats the image into separate patches and realize global communication via the self-attention mechanism. However, positional information between patches is hard to preserve in such 1D sequences, and loss of it can lead to sub-optimal performance when dealing with large amounts of heterogeneous tissues of various sizes in 3D medical image segmentation. Additionally, current methods are not robust and efficient for heavy-duty medical segmentation tasks such as predicting a large number of tissue classes or modeling globally inter-connected tissues structures. Inspired by the nested hierarchical structures in vision transformer, we proposed a novel 3D medical image segmentation method (UNesT), employing a simplified and faster-converging transformer encoder design that achieves local communication among spatially adjacent patch sequences by aggregating them hierarchically. We extensively validate our method on multiple challenging datasets, consisting anatomies of 133 structures in brain, 14 organs in abdomen, 4 hierarchical components in kidney, and inter-connected kidney tumors). We show that UNesT consistently achieves state-of-the-art performance and evaluate its generalizability and data efficiency. Particularly, the model achieves whole brain segmentation task complete ROI with 133 tissue classes in single network, outperforms prior state-of-the-art method SLANT27 ensembled with 27 network tiles, our model performance increases the mean DSC score of the publicly available Colin and CANDI dataset from 0.7264 to 0.7444 and from 0.6968 to 0.7025, respectively.
Longitudinal Variability Analysis on Low-dose Abdominal CT with Deep Learning-based Segmentation
Sep 28, 2022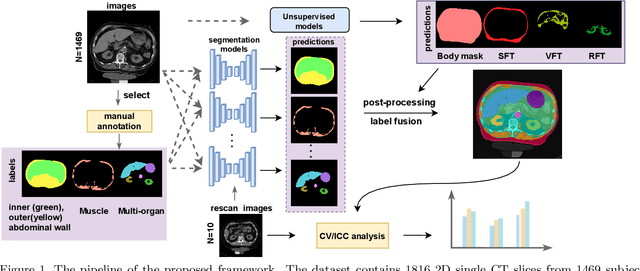

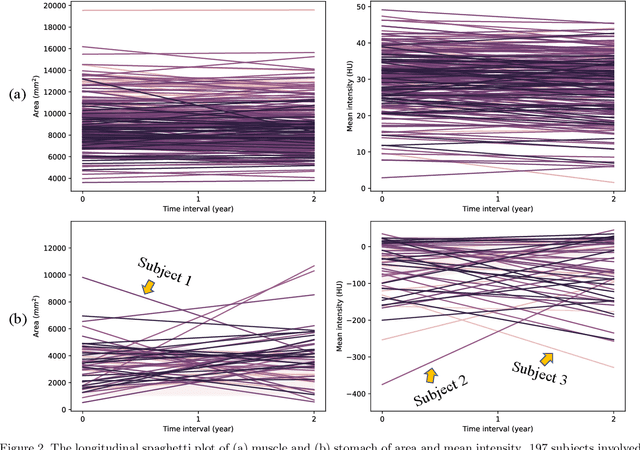
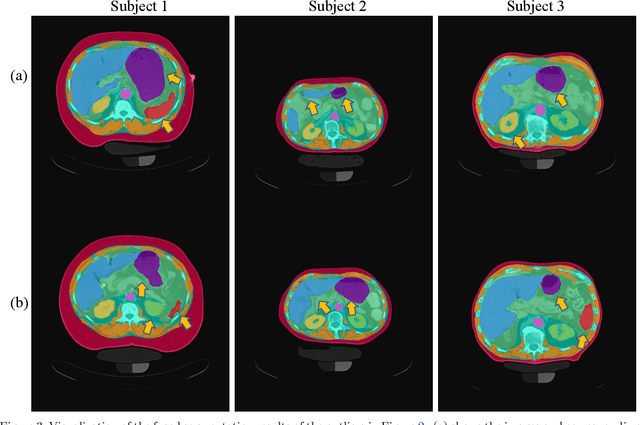
Metabolic health is increasingly implicated as a risk factor across conditions from cardiology to neurology, and efficiency assessment of body composition is critical to quantitatively characterizing these relationships. 2D low dose single slice computed tomography (CT) provides a high resolution, quantitative tissue map, albeit with a limited field of view. Although numerous potential analyses have been proposed in quantifying image context, there has been no comprehensive study for low-dose single slice CT longitudinal variability with automated segmentation. We studied a total of 1816 slices from 1469 subjects of Baltimore Longitudinal Study on Aging (BLSA) abdominal dataset using supervised deep learning-based segmentation and unsupervised clustering method. 300 out of 1469 subjects that have two year gap in their first two scans were pick out to evaluate longitudinal variability with measurements including intraclass correlation coefficient (ICC) and coefficient of variation (CV) in terms of tissues/organs size and mean intensity. We showed that our segmentation methods are stable in longitudinal settings with Dice ranged from 0.821 to 0.962 for thirteen target abdominal tissues structures. We observed high variability in most organ with ICC<0.5, low variability in the area of muscle, abdominal wall, fat and body mask with average ICC>0.8. We found that the variability in organ is highly related to the cross-sectional position of the 2D slice. Our efforts pave quantitative exploration and quality control to reduce uncertainties in longitudinal analysis.
Time-distance vision transformers in lung cancer diagnosis from longitudinal computed tomography
Sep 04, 2022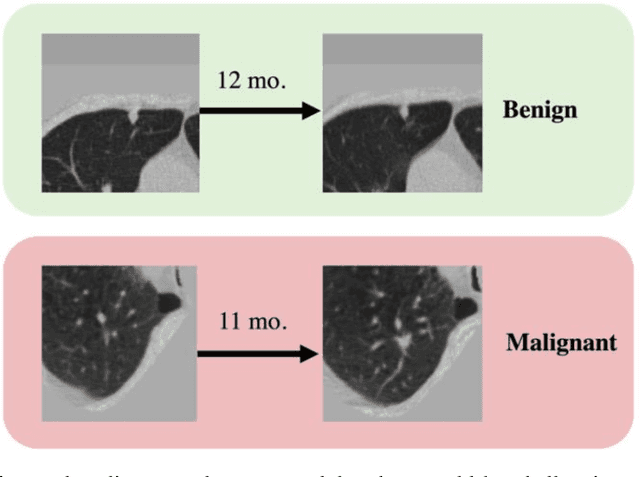

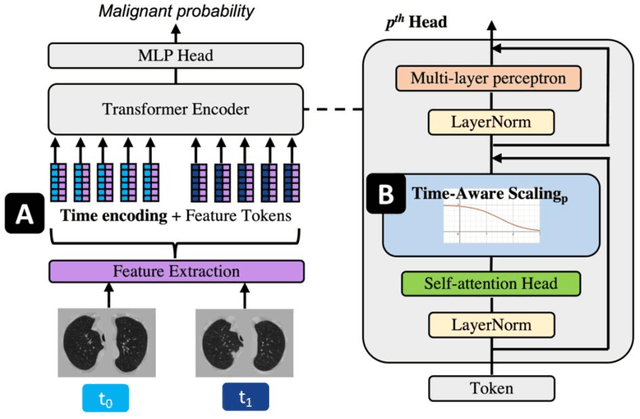

Features learned from single radiologic images are unable to provide information about whether and how much a lesion may be changing over time. Time-dependent features computed from repeated images can capture those changes and help identify malignant lesions by their temporal behavior. However, longitudinal medical imaging presents the unique challenge of sparse, irregular time intervals in data acquisition. While self-attention has been shown to be a versatile and efficient learning mechanism for time series and natural images, its potential for interpreting temporal distance between sparse, irregularly sampled spatial features has not been explored. In this work, we propose two interpretations of a time-distance vision transformer (ViT) by using (1) vector embeddings of continuous time and (2) a temporal emphasis model to scale self-attention weights. The two algorithms are evaluated based on benign versus malignant lung cancer discrimination of synthetic pulmonary nodules and lung screening computed tomography studies from the National Lung Screening Trial (NLST). Experiments evaluating the time-distance ViTs on synthetic nodules show a fundamental improvement in classifying irregularly sampled longitudinal images when compared to standard ViTs. In cross-validation on screening chest CTs from the NLST, our methods (0.785 and 0.786 AUC respectively) significantly outperform a cross-sectional approach (0.734 AUC) and match the discriminative performance of the leading longitudinal medical imaging algorithm (0.779 AUC) on benign versus malignant classification. This work represents the first self-attention-based framework for classifying longitudinal medical images. Our code is available at https://github.com/tom1193/time-distance-transformer.
Body Composition Assessment with Limited Field-of-view Computed Tomography: A Semantic Image Extension Perspective
Jul 13, 2022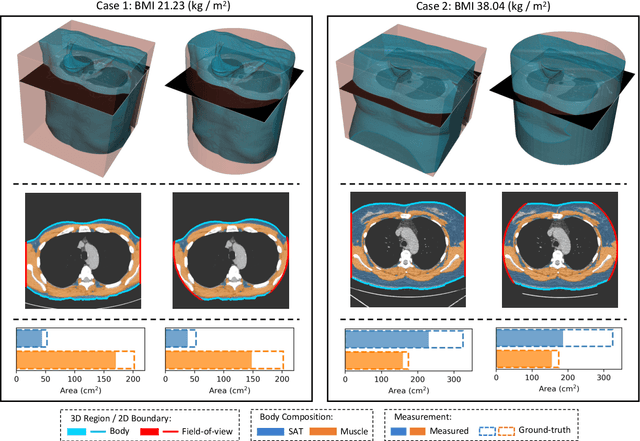
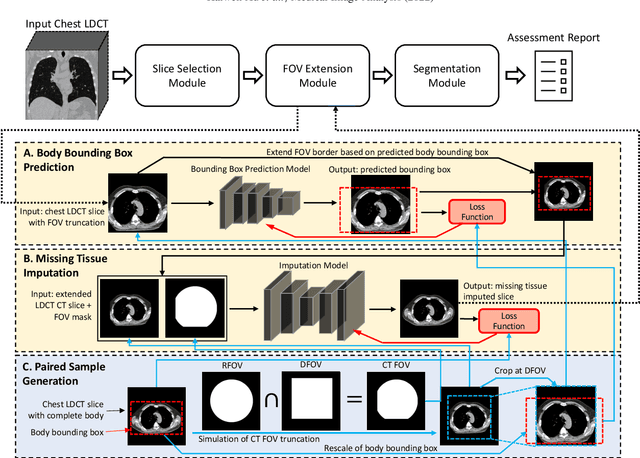
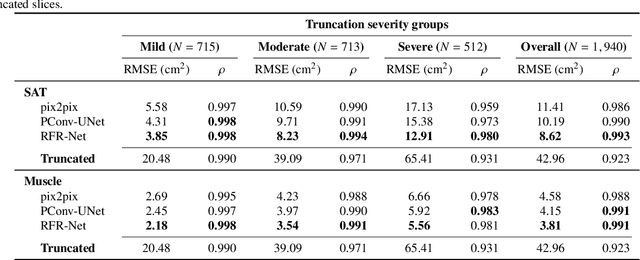
Field-of-view (FOV) tissue truncation beyond the lungs is common in routine lung screening computed tomography (CT). This poses limitations for opportunistic CT- based body composition (BC) assessment as key anatomical structures are missing. Traditionally, extending the FOV of CT is considered as a CT reconstruction problem using limited data. However, this approach relies on the projection domain data which might not be available in application. In this work, we formulate the problem from the semantic image extension perspective which only requires image data as inputs. The proposed two-stage method identifies a new FOV border based on the estimated extent of the complete body and imputes missing tissues in the truncated region. The training samples are simulated using CT slices with complete body in FOV, making the model development self-supervised. We evaluate the validity of the proposed method in automatic BC assessment using lung screening CT with limited FOV. The proposed method effectively restores the missing tissues and reduces BC assessment error introduced by FOV tissue truncation. In the BC assessment for a large-scale lung screening CT dataset, this correction improves both the intra-subject consistency and the correlation with anthropometric approximations. The developed method is available at https://github.com/MASILab/S-EFOV.
A Comparative Study of Confidence Calibration in Deep Learning: From Computer Vision to Medical Imaging
Jun 17, 2022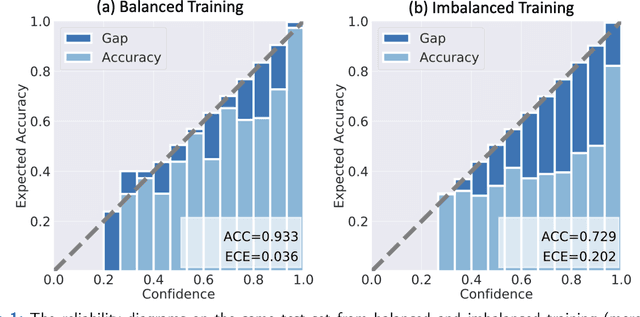
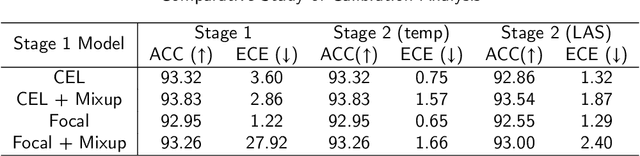
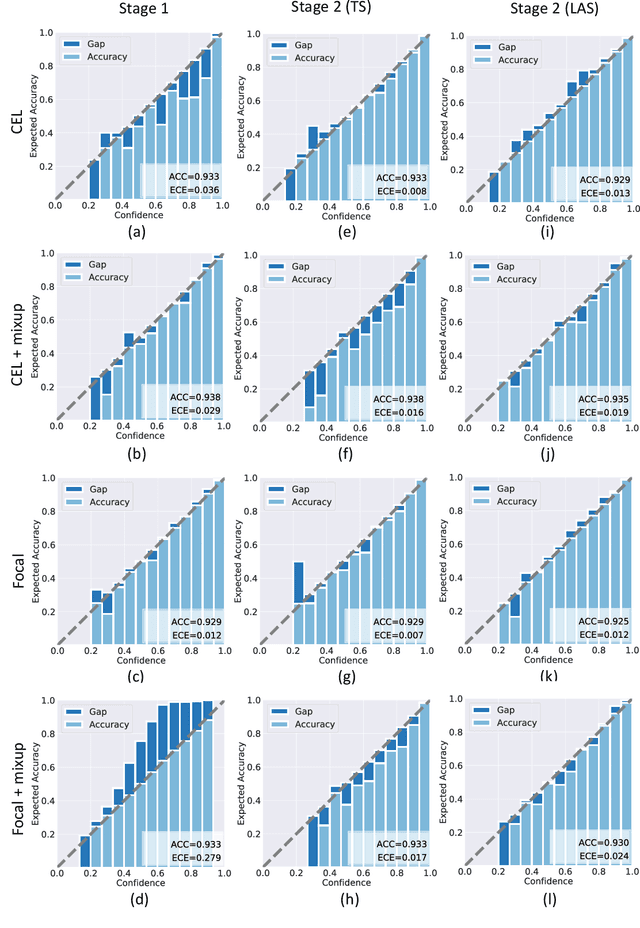
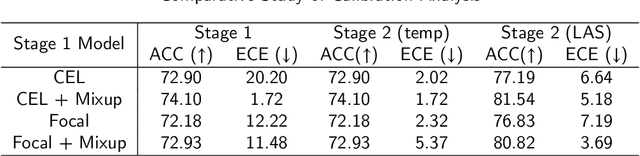
Although deep learning prediction models have been successful in the discrimination of different classes, they can often suffer from poor calibration across challenging domains including healthcare. Moreover, the long-tail distribution poses great challenges in deep learning classification problems including clinical disease prediction. There are approaches proposed recently to calibrate deep prediction in computer vision, but there are no studies found to demonstrate how the representative models work in different challenging contexts. In this paper, we bridge the confidence calibration from computer vision to medical imaging with a comparative study of four high-impact calibration models. Our studies are conducted in different contexts (natural image classification and lung cancer risk estimation) including in balanced vs. imbalanced training sets and in computer vision vs. medical imaging. Our results support key findings: (1) We achieve new conclusions which are not studied under different learning contexts, e.g., combining two calibration models that both mitigate the overconfident prediction can lead to under-confident prediction, and simpler calibration models from the computer vision domain tend to be more generalizable to medical imaging. (2) We highlight the gap between general computer vision tasks and medical imaging prediction, e.g., calibration methods ideal for general computer vision tasks may in fact damage the calibration of medical imaging prediction. (3) We also reinforce previous conclusions in natural image classification settings. We believe that this study has merits to guide readers to choose calibration models and understand gaps between general computer vision and medical imaging domains.
Pseudo-Label Guided Multi-Contrast Generalization for Non-Contrast Organ-Aware Segmentation
May 12, 2022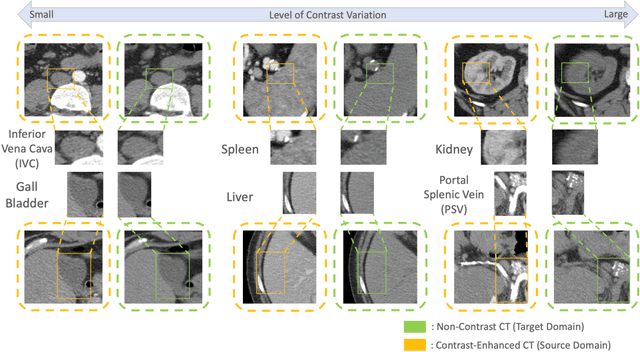
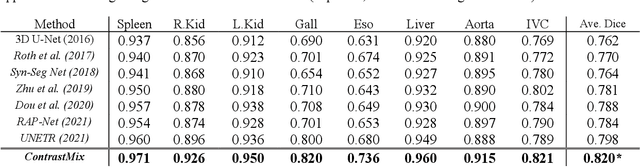
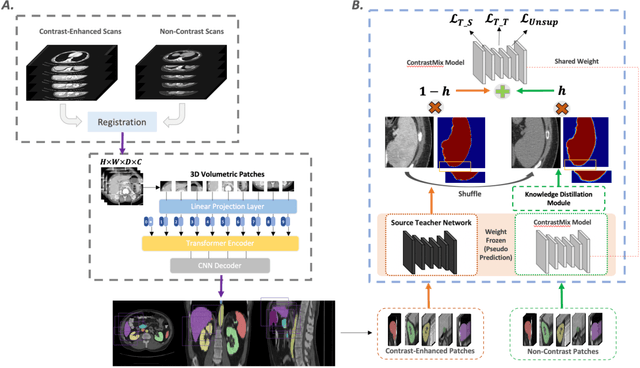
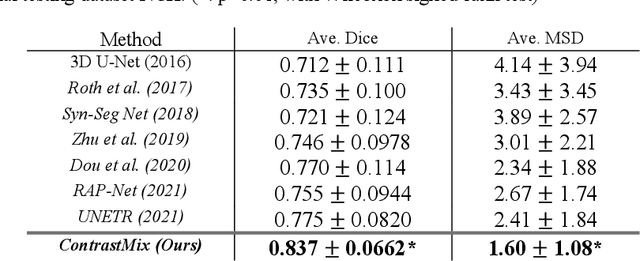
Non-contrast computed tomography (NCCT) is commonly acquired for lung cancer screening, assessment of general abdominal pain or suspected renal stones, trauma evaluation, and many other indications. However, the absence of contrast limits distinguishing organ in-between boundaries. In this paper, we propose a novel unsupervised approach that leverages pairwise contrast-enhanced CT (CECT) context to compute non-contrast segmentation without ground-truth label. Unlike generative adversarial approaches, we compute the pairwise morphological context with CECT to provide teacher guidance instead of generating fake anatomical context. Additionally, we further augment the intensity correlations in 'organ-specific' settings and increase the sensitivity to organ-aware boundary. We validate our approach on multi-organ segmentation with paired non-contrast & contrast-enhanced CT scans using five-fold cross-validation. Full external validations are performed on an independent non-contrast cohort for aorta segmentation. Compared with current abdominal organs segmentation state-of-the-art in fully supervised setting, our proposed pipeline achieves a significantly higher Dice by 3.98% (internal multi-organ annotated), and 8.00% (external aorta annotated) for abdominal organs segmentation. The code and pretrained models are publicly available at https://github.com/MASILab/ContrastMix.
Characterizing Renal Structures with 3D Block Aggregate Transformers
Mar 04, 2022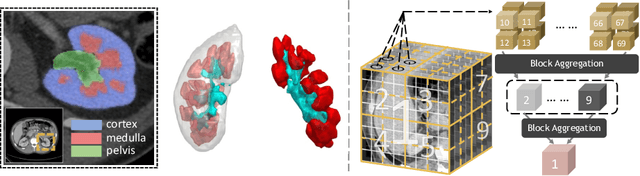
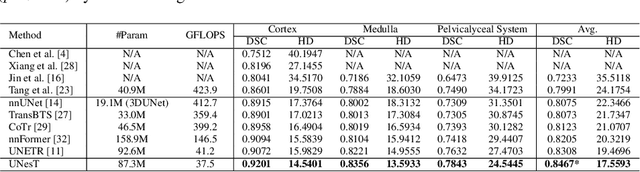

Efficiently quantifying renal structures can provide distinct spatial context and facilitate biomarker discovery for kidney morphology. However, the development and evaluation of the transformer model to segment the renal cortex, medulla, and collecting system remains challenging due to data inefficiency. Inspired by the hierarchical structures in vision transformer, we propose a novel method using a 3D block aggregation transformer for segmenting kidney components on contrast-enhanced CT scans. We construct the first cohort of renal substructures segmentation dataset with 116 subjects under institutional review board (IRB) approval. Our method yields the state-of-the-art performance (Dice of 0.8467) against the baseline approach of 0.8308 with the data-efficient design. The Pearson R achieves 0.9891 between the proposed method and manual standards and indicates the strong correlation and reproducibility for volumetric analysis. We extend the proposed method to the public KiTS dataset, the method leads to improved accuracy compared to transformer-based approaches. We show that the 3D block aggregation transformer can achieve local communication between sequence representations without modifying self-attention, and it can serve as an accurate and efficient quantification tool for characterizing renal structures.
Random Multi-Channel Image Synthesis for Multiplexed Immunofluorescence Imaging
Sep 18, 2021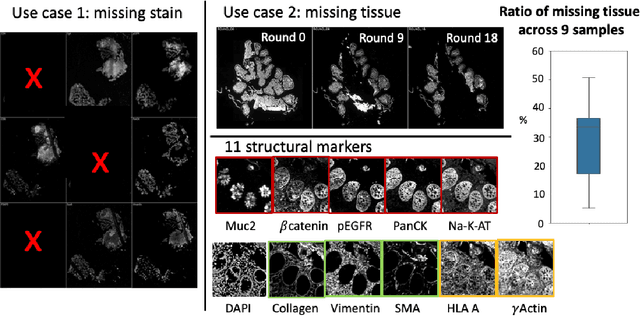
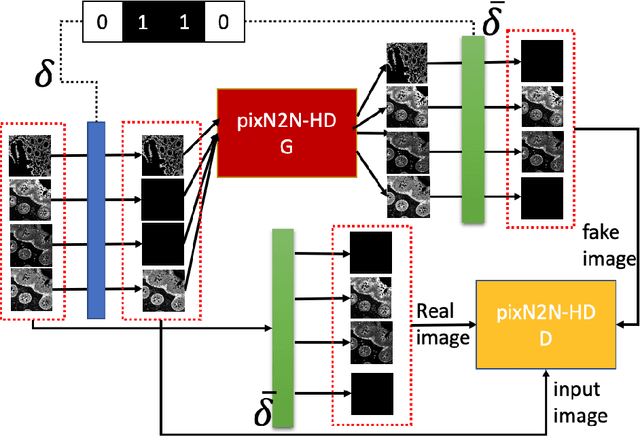
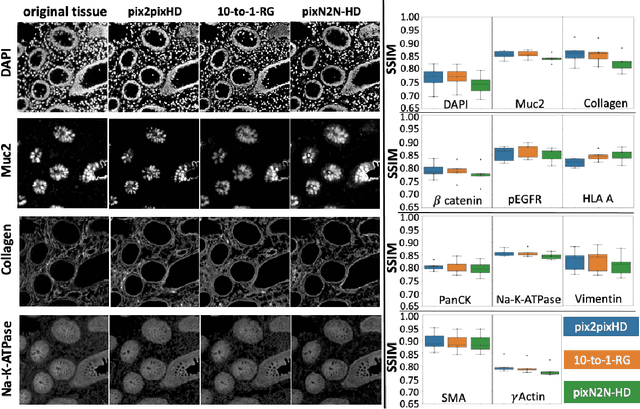
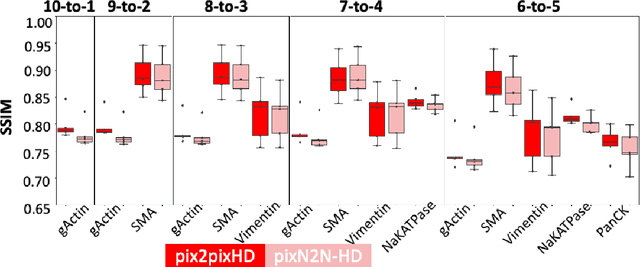
Multiplex immunofluorescence (MxIF) is an emerging imaging technique that produces the high sensitivity and specificity of single-cell mapping. With a tenet of 'seeing is believing', MxIF enables iterative staining and imaging extensive antibodies, which provides comprehensive biomarkers to segment and group different cells on a single tissue section. However, considerable depletion of the scarce tissue is inevitable from extensive rounds of staining and bleaching ('missing tissue'). Moreover, the immunofluorescence (IF) imaging can globally fail for particular rounds ('missing stain''). In this work, we focus on the 'missing stain' issue. It would be appealing to develop digital image synthesis approaches to restore missing stain images without losing more tissue physically. Herein, we aim to develop image synthesis approaches for eleven MxIF structural molecular markers (i.e., epithelial and stromal) on real samples. We propose a novel multi-channel high-resolution image synthesis approach, called pixN2N-HD, to tackle possible missing stain scenarios via a high-resolution generative adversarial network (GAN). Our contribution is three-fold: (1) a single deep network framework is proposed to tackle missing stain in MxIF; (2) the proposed 'N-to-N' strategy reduces theoretical four years of computational time to 20 hours when covering all possible missing stains scenarios, with up to five missing stains (e.g., '(N-1)-to-1', '(N-2)-to-2'); and (3) this work is the first comprehensive experimental study of investigating cross-stain synthesis in MxIF. Our results elucidate a promising direction of advancing MxIF imaging with deep image synthesis.
Technical Report: Quality Assessment Tool for Machine Learning with Clinical CT
Jul 27, 2021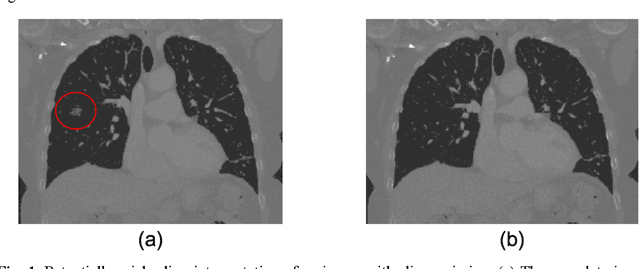

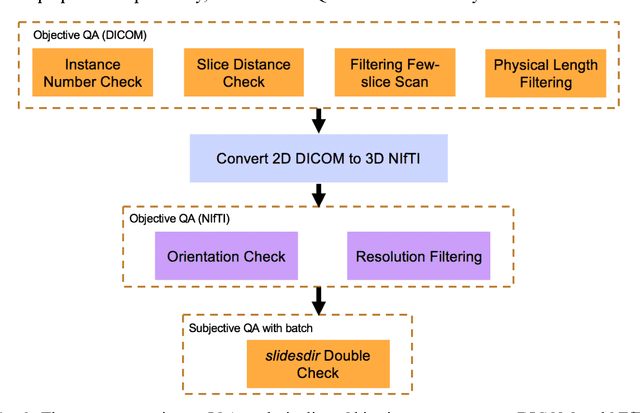

Image Quality Assessment (IQA) is important for scientific inquiry, especially in medical imaging and machine learning. Potential data quality issues can be exacerbated when human-based workflows use limited views of the data that may obscure digital artifacts. In practice, multiple factors such as network issues, accelerated acquisitions, motion artifacts, and imaging protocol design can impede the interpretation of image collections. The medical image processing community has developed a wide variety of tools for the inspection and validation of imaging data. Yet, IQA of computed tomography (CT) remains an under-recognized challenge, and no user-friendly tool is commonly available to address these potential issues. Here, we create and illustrate a pipeline specifically designed to identify and resolve issues encountered with large-scale data mining of clinically acquired CT data. Using the widely studied National Lung Screening Trial (NLST), we have identified approximately 4% of image volumes with quality concerns out of 17,392 scans. To assess robustness, we applied the proposed pipeline to our internal datasets where we find our tool is generalizable to clinically acquired medical images. In conclusion, the tool has been useful and time-saving for research study of clinical data, and the code and tutorials are publicly available at https://github.com/MASILab/QA_tool.
Lung Cancer Risk Estimation with Incomplete Data: A Joint Missing Imputation Perspective
Jul 25, 2021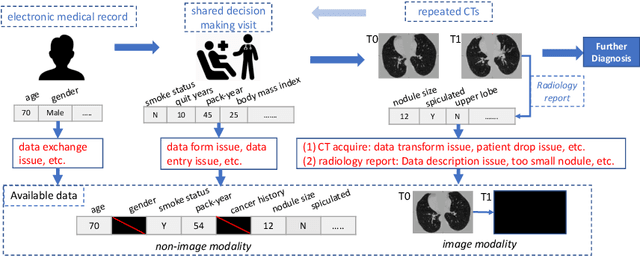
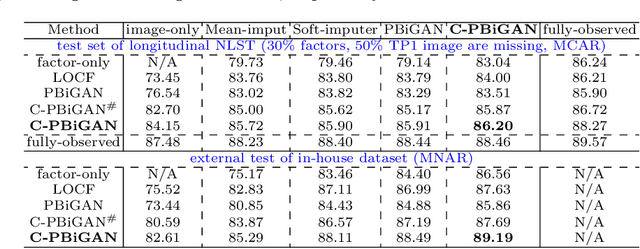
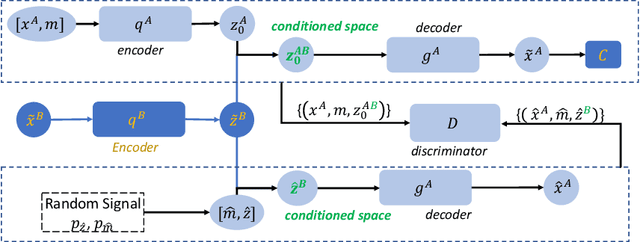
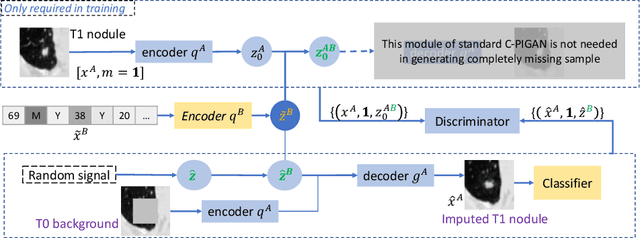
Data from multi-modality provide complementary information in clinical prediction, but missing data in clinical cohorts limits the number of subjects in multi-modal learning context. Multi-modal missing imputation is challenging with existing methods when 1) the missing data span across heterogeneous modalities (e.g., image vs. non-image); or 2) one modality is largely missing. In this paper, we address imputation of missing data by modeling the joint distribution of multi-modal data. Motivated by partial bidirectional generative adversarial net (PBiGAN), we propose a new Conditional PBiGAN (C-PBiGAN) method that imputes one modality combining the conditional knowledge from another modality. Specifically, C-PBiGAN introduces a conditional latent space in a missing imputation framework that jointly encodes the available multi-modal data, along with a class regularization loss on imputed data to recover discriminative information. To our knowledge, it is the first generative adversarial model that addresses multi-modal missing imputation by modeling the joint distribution of image and non-image data. We validate our model with both the national lung screening trial (NLST) dataset and an external clinical validation cohort. The proposed C-PBiGAN achieves significant improvements in lung cancer risk estimation compared with representative imputation methods (e.g., AUC values increase in both NLST (+2.9\%) and in-house dataset (+4.3\%) compared with PBiGAN, p$<$0.05).