 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Word Sense Disambiguation Biases in Machine Translation for Model-Agnostic Adversarial Attacks
Nov 03, 2020
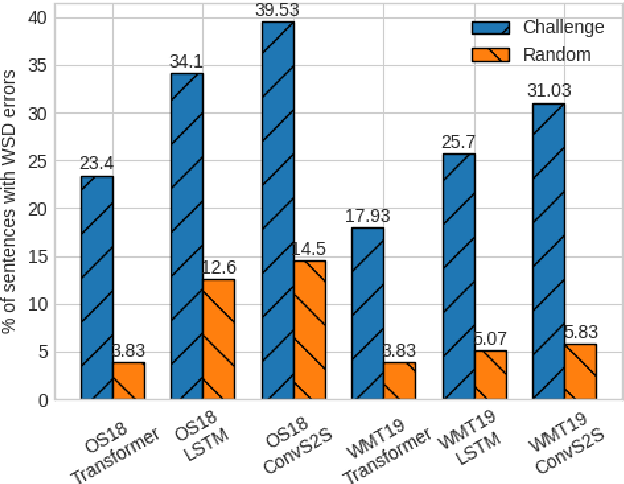
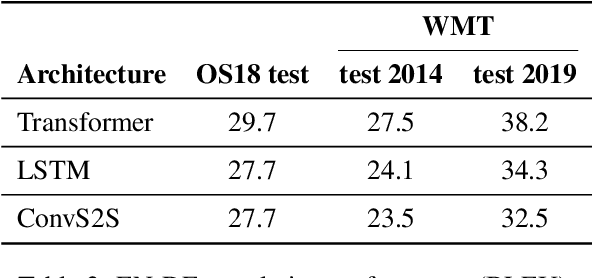
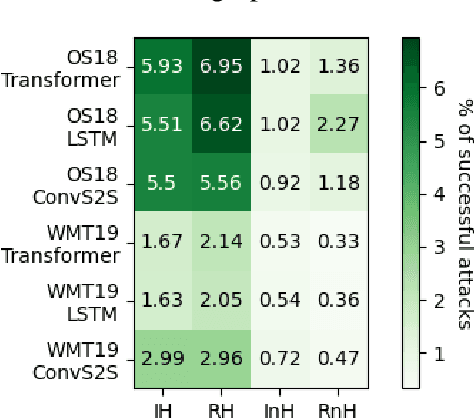
Word sense disambiguation is a well-known source of translation errors in NMT. We posit that some of the incorrect disambiguation choices are due to models' over-reliance on dataset artifacts found in training data, specifically superficial word co-occurrences, rather than a deeper understanding of the source text. We introduce a method for the prediction of disambiguation errors based on statistical data properties, demonstrating its effectiveness across several domains and model types. Moreover, we develop a simple adversarial attack strategy that minimally perturbs sentences in order to elicit disambiguation errors to further probe the robustness of translation models. Our findings indicate that disambiguation robustness varies substantially between domains and that different models trained on the same data are vulnerable to different attacks.
Subword Segmentation and a Single Bridge Language Affect Zero-Shot Neural Machine Translation
Nov 03, 2020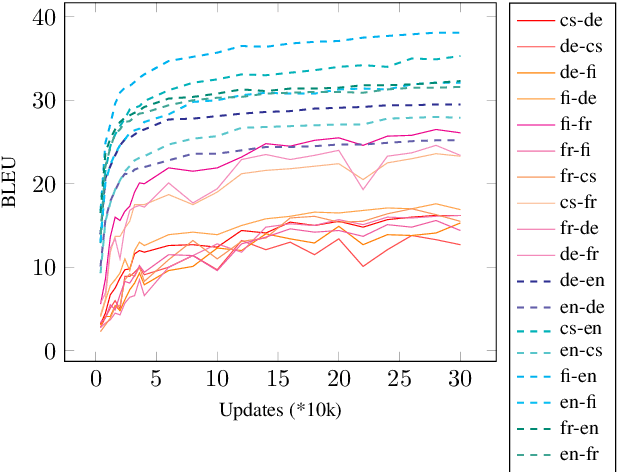
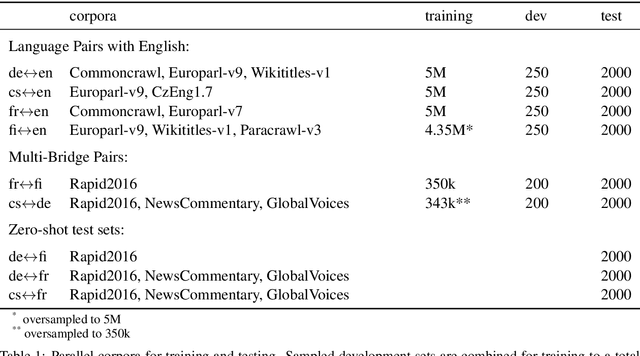
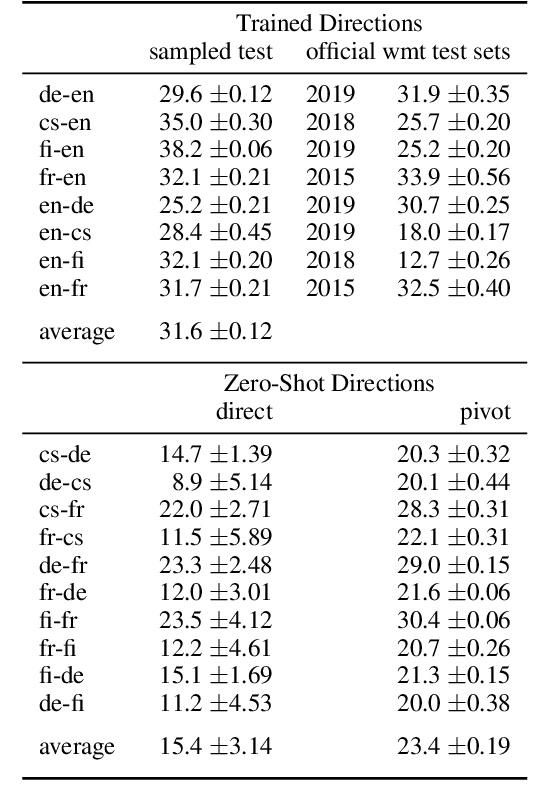
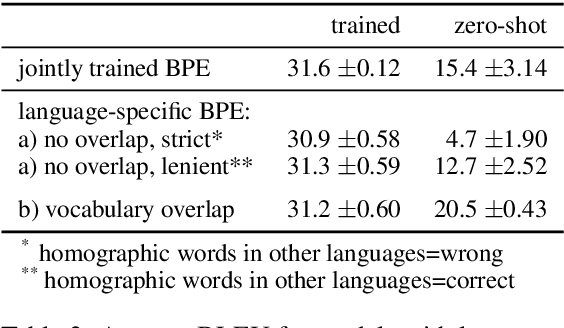
Zero-shot neural machine translation is an attractive goal because of the high cost of obtaining data and building translation systems for new translation directions. However, previous papers have reported mixed success in zero-shot translation. It is hard to predict in which settings it will be effective, and what limits performance compared to a fully supervised system. In this paper, we investigate zero-shot performance of a multilingual EN$\leftrightarrow${FR,CS,DE,FI} system trained on WMT data. We find that zero-shot performance is highly unstable and can vary by more than 6 BLEU between training runs, making it difficult to reliably track improvements. We observe a bias towards copying the source in zero-shot translation, and investigate how the choice of subword segmentation affects this bias. We find that language-specific subword segmentation results in less subword copying at training time, and leads to better zero-shot performance compared to jointly trained segmentation. A recent trend in multilingual models is to not train on parallel data between all language pairs, but have a single bridge language, e.g. English. We find that this negatively affects zero-shot translation and leads to a failure mode where the model ignores the language tag and instead produces English output in zero-shot directions. We show that this bias towards English can be effectively reduced with even a small amount of parallel data in some of the non-English pairs.
Fast Interleaved Bidirectional Sequence Generation
Oct 27, 2020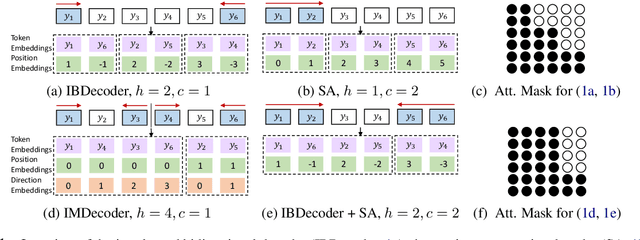
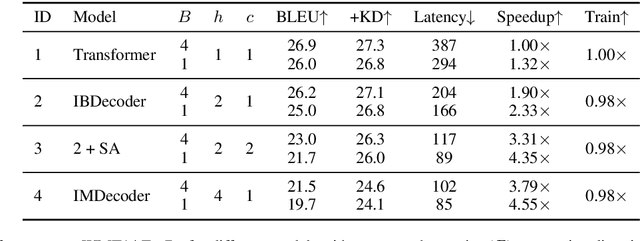

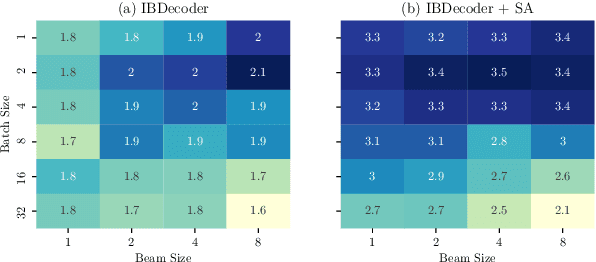
Independence assumptions during sequence generation can speed up inference, but parallel generation of highly inter-dependent tokens comes at a cost in quality. Instead of assuming independence between neighbouring tokens (semi-autoregressive decoding, SA), we take inspiration from bidirectional sequence generation and introduce a decoder that generates target words from the left-to-right and right-to-left directions simultaneously. We show that we can easily convert a standard architecture for unidirectional decoding into a bidirectional decoder by simply interleaving the two directions and adapting the word positions and self-attention masks. Our interleaved bidirectional decoder (IBDecoder) retains the model simplicity and training efficiency of the standard Transformer, and on five machine translation tasks and two document summarization tasks, achieves a decoding speedup of ~2X compared to autoregressive decoding with comparable quality. Notably, it outperforms left-to-right SA because the independence assumptions in IBDecoder are more felicitous. To achieve even higher speedups, we explore hybrid models where we either simultaneously predict multiple neighbouring tokens per direction, or perform multi-directional decoding by partitioning the target sequence. These methods achieve speedups to 4X-11X across different tasks at the cost of <1 BLEU or <0.5 ROUGE (on average). Source code is released at https://github.com/bzhangGo/zero.
Analyzing the Source and Target Contributions to Predictions in Neural Machine Translation
Oct 21, 2020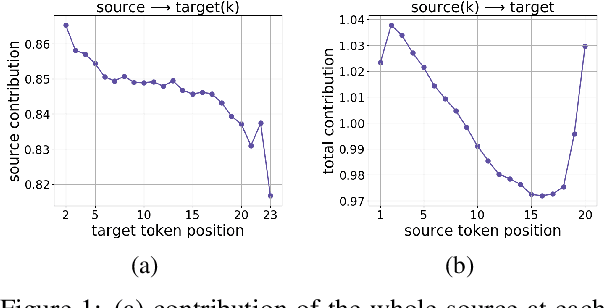
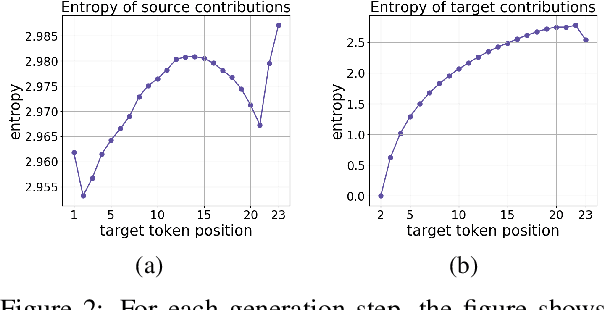
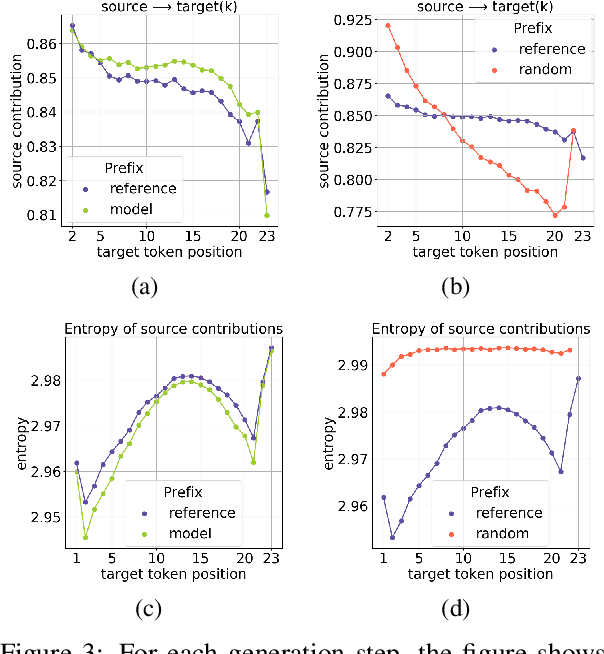
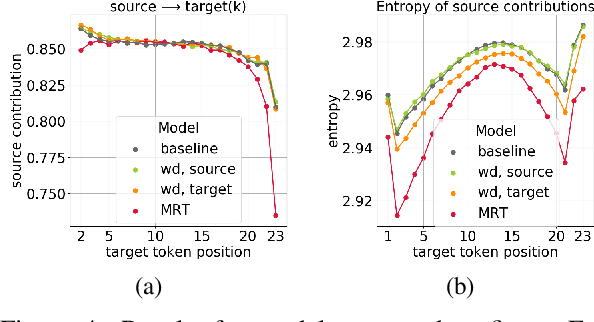
In Neural Machine Translation (and, more generally, conditional language modeling), the generation of a target token is influenced by two types of context: the source and the prefix of the target sequence. While many attempts to understand the internal workings of NMT models have been made, none of them explicitly evaluates relative source and target contributions to a generation decision. We argue that this relative contribution can be evaluated by adopting a variant of Layerwise Relevance Propagation (LRP). Its underlying 'conservation principle' makes relevance propagation unique: differently from other methods, it evaluates not an abstract quantity reflecting token importance, but the proportion of each token's influence. We extend LRP to the Transformer and conduct an analysis of NMT models which explicitly evaluates the source and target relative contributions to the generation process. We analyze changes in these contributions when conditioning on different types of prefixes, when varying the training objective or the amount of training data, and during the training process. We find that models trained with more data tend to rely on source information more and to have more sharp token contributions; the training process is non-monotonic with several stages of different nature.
Adaptive Feature Selection for End-to-End Speech Translation
Oct 20, 2020
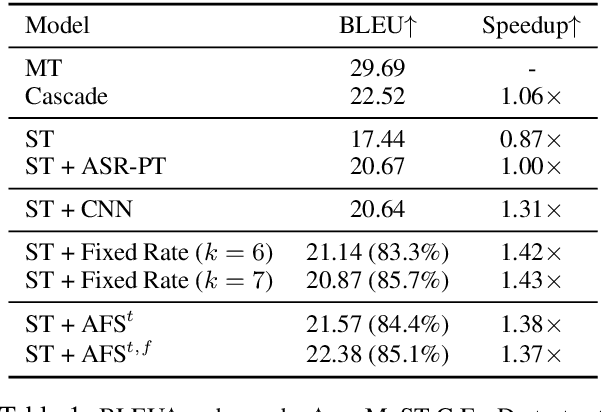
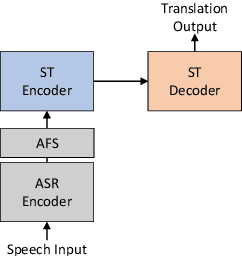
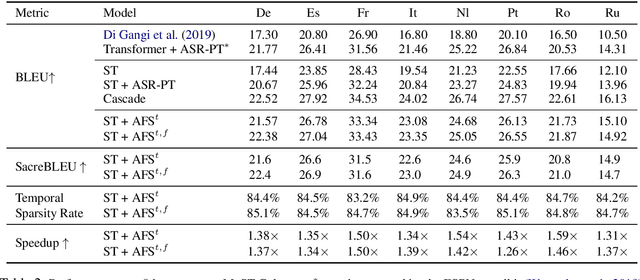
Information in speech signals is not evenly distributed, making it an additional challenge for end-to-end (E2E) speech translation (ST) to learn to focus on informative features. In this paper, we propose adaptive feature selection (AFS) for encoder-decoder based E2E ST. We first pre-train an ASR encoder and apply AFS to dynamically estimate the importance of each encoded speech feature to SR. A ST encoder, stacked on top of the ASR encoder, then receives the filtered features from the (frozen) ASR encoder. We take L0DROP (Zhang et al., 2020) as the backbone for AFS, and adapt it to sparsify speech features with respect to both temporal and feature dimensions. Results on LibriSpeech En-Fr and MuST-C benchmarks show that AFS facilitates learning of ST by pruning out ~84% temporal features, yielding an average translation gain of ~1.3-1.6 BLEU and a decoding speedup of ~1.4x. In particular, AFS reduces the performance gap compared to the cascade baseline, and outperforms it on LibriSpeech En-Fr with a BLEU score of 18.56 (without data augmentation)
On Romanization for Model Transfer Between Scripts in Neural Machine Translation
Sep 30, 2020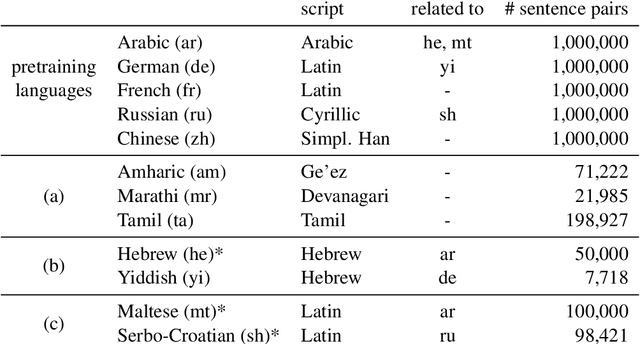
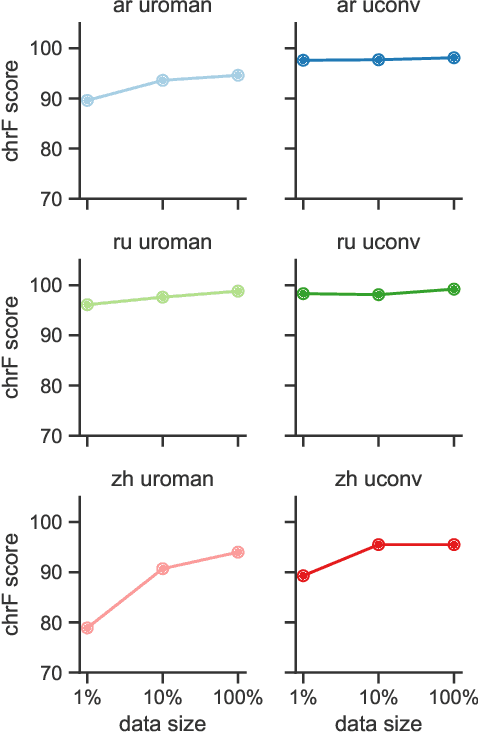

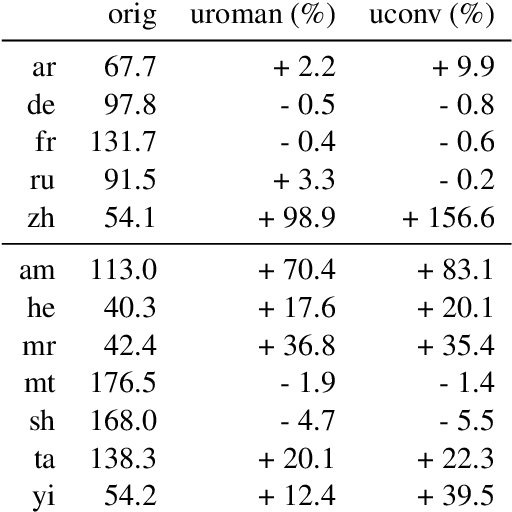
Transfer learning is a popular strategy to improve the quality of low-resource machine translation. For an optimal transfer of the embedding layer, the child and parent model should share a substantial part of the vocabulary. This is not the case when transferring to languages with a different script. We explore the benefit of romanization in this scenario. Our results show that romanization entails information loss and is thus not always superior to simpler vocabulary transfer methods, but can improve the transfer between related languages with different scripts. We compare two romanization tools and find that they exhibit different degrees of information loss, which affects translation quality. Finally, we extend romanization to the target side, showing that this can be a successful strategy when coupled with a simple deromanization model.
On Exposure Bias, Hallucination and Domain Shift in Neural Machine Translation
May 07, 2020
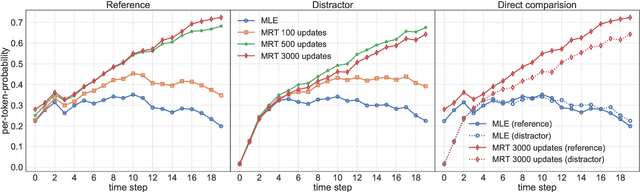
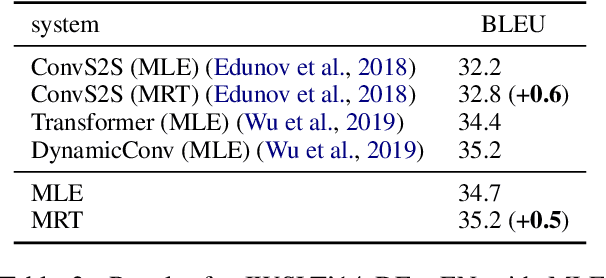
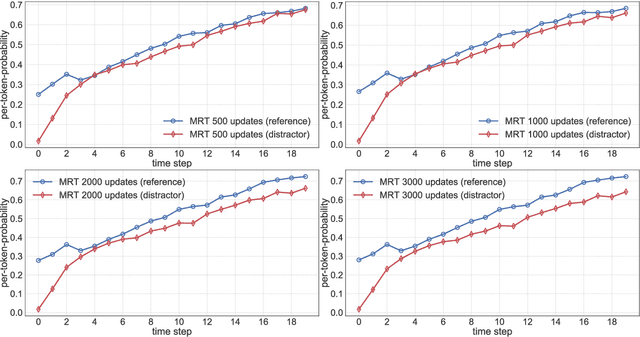
The standard training algorithm in neural machine translation (NMT) suffers from exposure bias, and alternative algorithms have been proposed to mitigate this. However, the practical impact of exposure bias is under debate. In this paper, we link exposure bias to another well-known problem in NMT, namely the tendency to generate hallucinations under domain shift. In experiments on three datasets with multiple test domains, we show that exposure bias is partially to blame for hallucinations, and that training with Minimum Risk Training, which avoids exposure bias, can mitigate this. Our analysis explains why exposure bias is more problematic under domain shift, and also links exposure bias to the beam search problem, i.e. performance deterioration with increasing beam size. Our results provide a new justification for methods that reduce exposure bias: even if they do not increase performance on in-domain test sets, they can increase model robustness to domain shift.
Improving Massively Multilingual Neural Machine Translation and Zero-Shot Translation
Apr 24, 2020
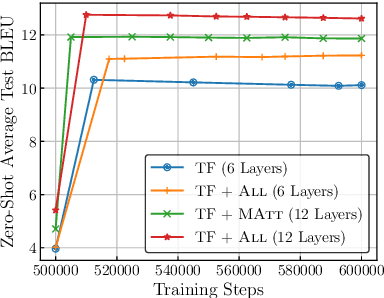
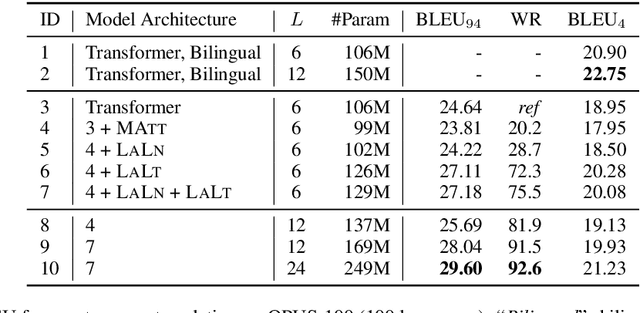
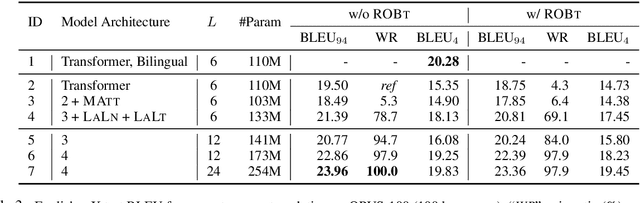
Massively multilingual models for neural machine translation (NMT) are theoretically attractive, but often underperform bilingual models and deliver poor zero-shot translations. In this paper, we explore ways to improve them. We argue that multilingual NMT requires stronger modeling capacity to support language pairs with varying typological characteristics, and overcome this bottleneck via language-specific components and deepening NMT architectures. We identify the off-target translation issue (i.e. translating into a wrong target language) as the major source of the inferior zero-shot performance, and propose random online backtranslation to enforce the translation of unseen training language pairs. Experiments on OPUS-100 (a novel multilingual dataset with 100 languages) show that our approach substantially narrows the performance gap with bilingual models in both one-to-many and many-to-many settings, and improves zero-shot performance by ~10 BLEU, approaching conventional pivot-based methods.
On Sparsifying Encoder Outputs in Sequence-to-Sequence Models
Apr 24, 2020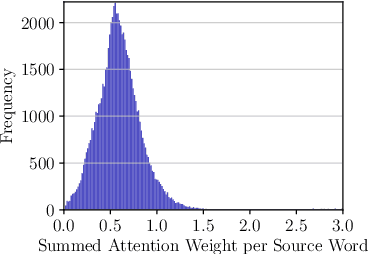
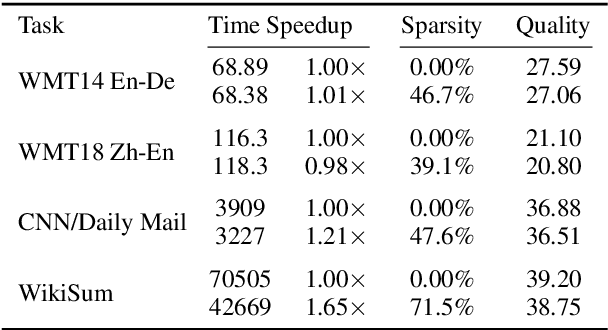
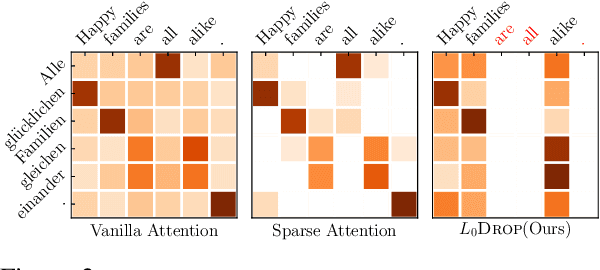
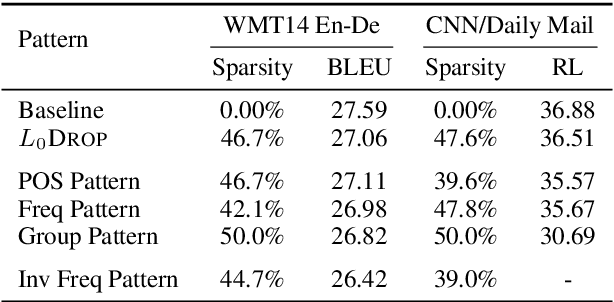
Sequence-to-sequence models usually transfer all encoder outputs to the decoder for generation. In this work, by contrast, we hypothesize that these encoder outputs can be compressed to shorten the sequence delivered for decoding. We take Transformer as the testbed and introduce a layer of stochastic gates in-between the encoder and the decoder. The gates are regularized using the expected value of the sparsity-inducing L0penalty, resulting in completely masking-out a subset of encoder outputs. In other words, via joint training, the L0DROP layer forces Transformer to route information through a subset of its encoder states. We investigate the effects of this sparsification on two machine translation and two summarization tasks. Experiments show that, depending on the task, around 40-70% of source encodings can be pruned without significantly compromising quality. The decrease of the output length endows L0DROP with the potential of improving decoding efficiency, where it yields a speedup of up to 1.65x on document summarization tasks against the standard Transformer. We analyze the L0DROP behaviour and observe that it exhibits systematic preferences for pruning certain word types, e.g., function words and punctuation get pruned most. Inspired by these observations, we explore the feasibility of specifying rule-based patterns that mask out encoder outputs based on information such as part-of-speech tags, word frequency and word position.
A Set of Recommendations for Assessing Human-Machine Parity in Language Translation
Apr 03, 2020

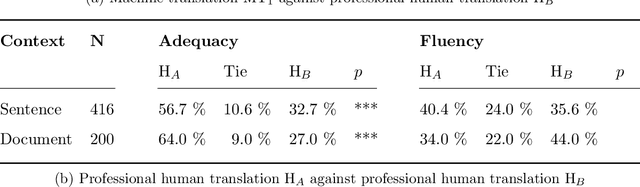
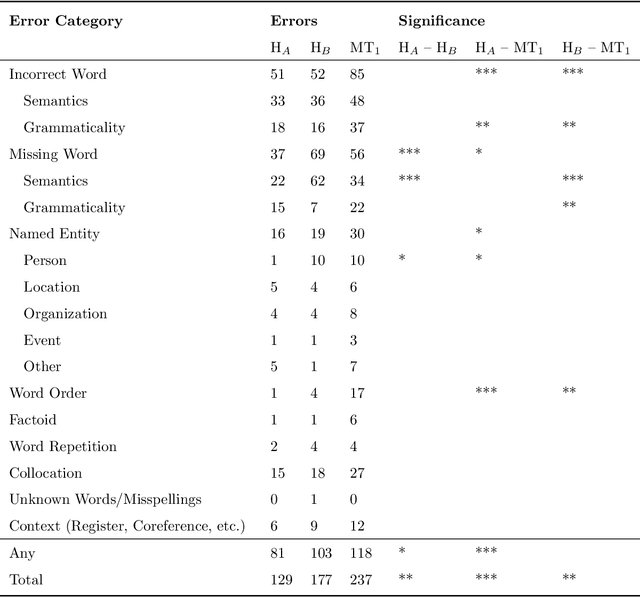
The quality of machine translation has increased remarkably over the past years, to the degree that it was found to be indistinguishable from professional human translation in a number of empirical investigations. We reassess Hassan et al.'s 2018 investigation into Chinese to English news translation, showing that the finding of human-machine parity was owed to weaknesses in the evaluation design - which is currently considered best practice in the field. We show that the professional human translations contained significantly fewer errors, and that perceived quality in human evaluation depends on the choice of raters, the availability of linguistic context, and the creation of reference translations. Our results call for revisiting current best practices to assess strong machine translation systems in general and human-machine parity in particular, for which we offer a set of recommendations based on our empirical findings.