 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Search in Chemical Documents and Reactions
Feb 24, 2025We present a multimodal search tool that facilitates retrieval of chemical reactions, molecular structures, and associated text from scientific literature. Queries may combine molecular diagrams, textual descriptions, and reaction data, allowing users to connect different representations of chemical information. To support this, the indexing process includes chemical diagram extraction and parsing, extraction of reaction data from text in tabular form, and cross-modal linking of diagrams and their mentions in text. We describe the system's architecture, key functionalities, and retrieval process, along with expert assessments of the system. This demo highlights the workflow and technical components of the search system.
Local and Global Graph Modeling with Edge-weighted Graph Attention Network for Handwritten Mathematical Expression Recognition
Oct 24, 2024



In this paper, we present a novel approach to Handwritten Mathematical Expression Recognition (HMER) by leveraging graph-based modeling techniques. We introduce an End-to-end model with an Edge-weighted Graph Attention Mechanism (EGAT), designed to perform simultaneous node and edge classification. This model effectively integrates node and edge features, facilitating the prediction of symbol classes and their relationships within mathematical expressions. Additionally, we propose a stroke-level Graph Modeling method for both local (LGM) and global (GGM) information, which applies an end-to-end model to Online HMER tasks, transforming the recognition problem into node and edge classification tasks in graph structure. By capturing both local and global graph features, our method ensures comprehensive understanding of the expression structure. Through the combination of these components, our system demonstrates superior performance in symbol detection, relation classification, and expression-level recognition.
ColBERT's [MASK]-based Query Augmentation: Effects of Quadrupling the Query Input Length
Aug 24, 2024A unique aspect of ColBERT is its use of [MASK] tokens in queries to score documents (query augmentation). Prior work shows [MASK] tokens weighting non-[MASK] query terms, emphasizing certain tokens over others , rather than introducing whole new terms as initially proposed. We begin by demonstrating that a term weighting behavior previously reported for [MASK] tokens in ColBERTv1 holds for ColBERTv2. We then examine the effect of changing the number of [MASK] tokens from zero to up to four times past the query input length used in training, both for first stage retrieval, and for scoring candidates, observing an initial decrease in performance with few [MASK]s, a large increase when enough [MASK]s are added to pad queries to an average length of 32, then a plateau in performance afterwards. Additionally, we compare baseline performance to performance when the query length is extended to 128 tokens, and find that differences are small (e.g., within 1% on various metrics) and generally statistically insignificant, indicating performance does not collapse if ColBERT is presented with more [MASK] tokens than expected.
Mathematical Information Retrieval: Search and Question Answering
Aug 21, 2024



Mathematical information is essential for technical work, but its creation, interpretation, and search are challenging. To help address these challenges, researchers have developed multimodal search engines and mathematical question answering systems. This book begins with a simple framework characterizing the information tasks that people and systems perform as we work to answer math-related questions. The framework is used to organize and relate the other core topics of the book, including interactions between people and systems, representing math formulas in sources, and evaluation. We close with some key questions and concrete directions for future work. This book is intended for use by students, instructors, and researchers, and those who simply wish that it was easier to find and use mathematical information
A Study of PHOC Spatial Region Configurations for Math Formula Retrieval
Aug 17, 2024A Pyramidal Histogram Of Characters (PHOC) represents the spatial location of symbols as binary vectors. The vectors are composed of levels that split a formula into equal-sized regions of one or more types (e.g., rectangles or ellipses). For each region type, this produces a pyramid of overlapping regions, where the first level contains the entire formula, and the final level the finest-grained regions. In this work, we introduce concentric rectangles for regions, and analyze whether subsequent PHOC levels encode redundant information by omitting levels from PHOC configurations. As a baseline, we include a bag of words PHOC containing only the first whole-formula level. Finally, using the ARQMath-3 formula retrieval benchmark, we demonstrate that some levels encoded in the original PHOC configurations are redundant, that PHOC models with rectangular regions outperform earlier PHOC models, and that despite their simplicity, PHOC models are surprisingly competitive with the state-of-the-art. PHOC is not math-specific, and might be used for chemical diagrams, charts, or other graphics.
ChemScraper: Graphics Extraction, Molecular Diagram Parsing, and Annotated Data Generation for PDF Images
Nov 22, 2023Existing visual parsers for molecule diagrams translate pixel-based raster images such as PNGs to chemical structure representations (e.g., SMILES). However, PDFs created by word processors including LaTeX and Word provide explicit locations and shapes for characters, lines, and polygons. We extract symbols from born-digital PDF molecule images and then apply simple graph transformations to capture both visual and chemical structure in editable ChemDraw files (CDXML). Our fast ( PDF $\rightarrow$ visual graph $\rightarrow$ chemical graph ) pipeline does not require GPUs, Optical Character Recognition (OCR) or vectorization. We evaluate on standard benchmarks using SMILES strings, along with a novel evaluation that provides graph-based metrics and error compilation using LgEval. The geometric information in born-digital PDFs produces a highly accurate parser, motivating generating training data for visual parsers that recognize from raster images, with extracted graphics, visual structure, and chemical structure as annotations. To do this we render SMILES strings in Indigo, parse molecule structure, and then validate recognized structure to select correct files.
Effects of context, complexity, and clustering on evaluation for math formula retrieval
Nov 20, 2021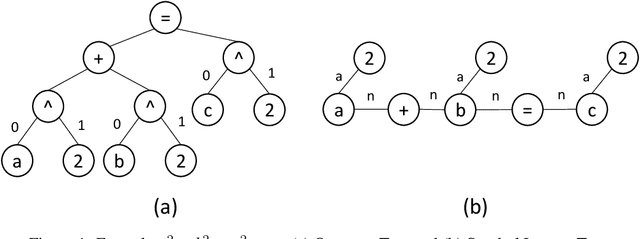
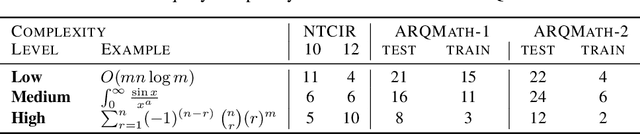

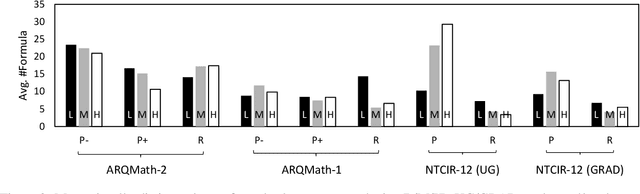
There are now several test collections for the formula retrieval task, in which a system's goal is to identify useful mathematical formulae to show in response to a query posed as a formula. These test collections differ in query format, query complexity, number of queries, content source, and relevance definition. Comparisons among six formula retrieval test collections illustrate that defining relevance based on query and/or document context can be consequential, that system results vary markedly with formula complexity, and that judging relevance after clustering formulas with identical symbol layouts (i.e., Symbol Layout Trees) can affect system preference ordering.
ScanSSD: Scanning Single Shot Detector for Mathematical Formulas in PDF Document Images
Mar 18, 2020
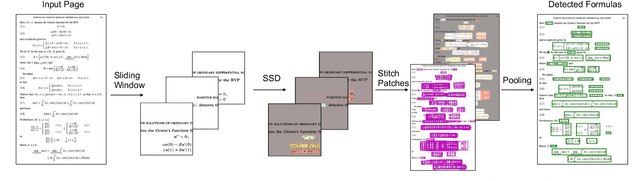

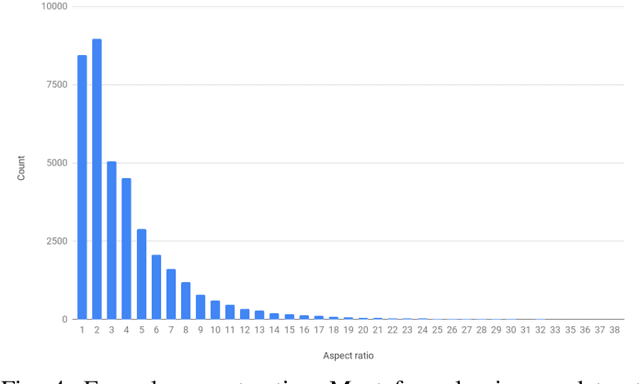
We introduce the Scanning Single Shot Detector (ScanSSD) for locating math formulas offset from text and embedded in textlines. ScanSSD uses only visual features for detection: no formatting or typesetting information such as layout, font, or character labels are employed. Given a 600 dpi document page image, a Single Shot Detector (SSD) locates formulas at multiple scales using sliding windows, after which candidate detections are pooled to obtain page-level results. For our experiments we use the TFD-ICDAR2019v2 dataset, a modification of the GTDB scanned math article collection. ScanSSD detects characters in formulas with high accuracy, obtaining a 0.926 f-score, and detects formulas with high recall overall. Detection errors are largely minor, such as splitting formulas at large whitespace gaps (e.g., for variable constraints) and merging formulas on adjacent textlines. Formula detection f-scores of 0.796 (IOU $\geq0.5$) and 0.733 (IOU $\ge 0.75$) are obtained. Our data, evaluation tools, and code are publicly available.
Detecting Figures and Part Labels in Patents: Competition-Based Development of Image Processing Algorithms
Nov 11, 2014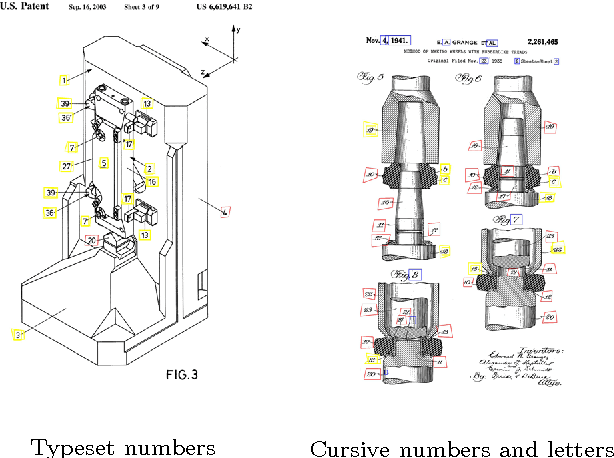


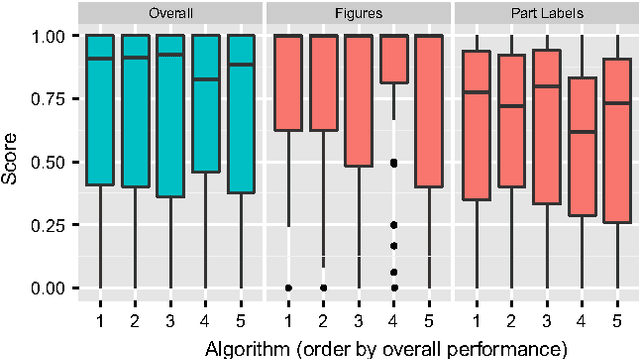
We report the findings of a month-long online competition in which participants developed algorithms for augmenting the digital version of patent documents published by the United States Patent and Trademark Office (USPTO). The goal was to detect figures and part labels in U.S. patent drawing pages. The challenge drew 232 teams of two, of which 70 teams (30%) submitted solutions. Collectively, teams submitted 1,797 solutions that were compiled on the competition servers. Participants reported spending an average of 63 hours developing their solutions, resulting in a total of 5,591 hours of development time. A manually labeled dataset of 306 patents was used for training, online system tests, and evaluation. The design and performance of the top-5 systems are presented, along with a system developed after the competition which illustrates that winning teams produced near state-of-the-art results under strict time and computation constraints. For the 1st place system, the harmonic mean of recall and precision (f-measure) was 88.57% for figure region detection, 78.81% for figure regions with correctly recognized figure titles, and 70.98% for part label detection and character recognition. Data and software from the competition are available through the online UCI Machine Learning repository to inspire follow-on work by the image processing community.