 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Constructing Sparse Navigable Graphs
Jul 17, 2025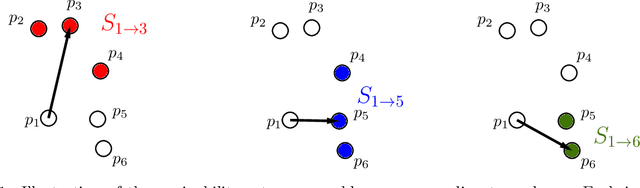



Graph-based nearest neighbor search methods have seen a surge of popularity in recent years, offering state-of-the-art performance across a wide variety of applications. Central to these methods is the task of constructing a sparse navigable search graph for a given dataset endowed with a distance function. Unfortunately, doing so is computationally expensive, so heuristics are universally used in practice. In this work, we initiate the study of fast algorithms with provable guarantees for search graph construction. For a dataset with $n$ data points, the problem of constructing an optimally sparse navigable graph can be framed as $n$ separate but highly correlated minimum set cover instances. This yields a naive $O(n^3)$ time greedy algorithm that returns a navigable graph whose sparsity is at most $O(\log n)$ higher than optimal. We improve significantly on this baseline, taking advantage of correlation between the set cover instances to leverage techniques from streaming and sublinear-time set cover algorithms. Combined with problem-specific pre-processing techniques, we present an $\tilde{O}(n^2)$ time algorithm for constructing an $O(\log n)$-approximate sparsest navigable graph under any distance function. The runtime of our method is optimal up to logarithmic factors under the Strong Exponential Time Hypothesis via a reduction from Monochromatic Closest Pair. Moreover, we prove that, as with general set cover, obtaining better than an $O(\log n)$-approximation is NP-hard, despite the significant additional structure present in the navigable graph problem. Finally, we show that our techniques can also beat cubic time for the closely related and practically important problems of constructing $\alpha$-shortcut reachable and $\tau$-monotonic graphs, which are also used for nearest neighbor search. For such graphs, we obtain $\tilde{O}(n^{2.5})$ time or better algorithms.
In-Place Updates of a Graph Index for Streaming Approximate Nearest Neighbor Search
Feb 19, 2025Indices for approximate nearest neighbor search (ANNS) are a basic component for information retrieval and widely used in database, search, recommendation and RAG systems. In these scenarios, documents or other objects are inserted into and deleted from the working set at a high rate, requiring a stream of updates to the vector index. Algorithms based on proximity graph indices are the most efficient indices for ANNS, winning many benchmark competitions. However, it is challenging to update such graph index at a high rate, while supporting stable recall after many updates. Since the graph is singly-linked, deletions are hard because there is no fast way to find in-neighbors of a deleted vertex. Therefore, to update the graph, state-of-the-art algorithms such as FreshDiskANN accumulate deletions in a batch and periodically consolidate, removing edges to deleted vertices and modifying the graph to ensure recall stability. In this paper, we present IP-DiskANN (InPlaceUpdate-DiskANN), the first algorithm to avoid batch consolidation by efficiently processing each insertion and deletion in-place. Our experiments using standard benchmarks show that IP-DiskANN has stable recall over various lengthy update patterns in both high-recall and low-recall regimes. Further, its query throughput and update speed are better than using the batch consolidation algorithm and HNSW.