 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLBGP: Learning Based Goal Planning for Autonomous Following in Front
Nov 05, 2020
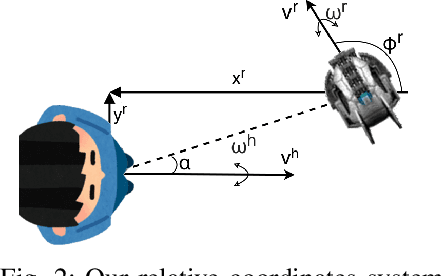


This paper investigates a hybrid solution which combines deep reinforcement learning (RL) and classical trajectory planning for the following in front application. Here, an autonomous robot aims to stay ahead of a person as the person freely walks around. Following in front is a challenging problem as the user's intended trajectory is unknown and needs to be estimated, explicitly or implicitly, by the robot. In addition, the robot needs to find a feasible way to safely navigate ahead of human trajectory. Our deep RL module implicitly estimates human trajectory and produces short-term navigational goals to guide the robot. These goals are used by a trajectory planner to smoothly navigate the robot to the short-term goals, and eventually in front of the user. We employ curriculum learning in the deep RL module to efficiently achieve a high return. Our system outperforms the state-of-the-art in following ahead and is more reliable compared to end-to-end alternatives in both the simulation and real world experiments. In contrast to a pure deep RL approach, we demonstrate zero-shot transfer of the trained policy from simulation to the real world.
Recognizing and Tracking High-Level, Human-Meaningful Navigation Features of Occupancy Grid Maps
Mar 08, 2019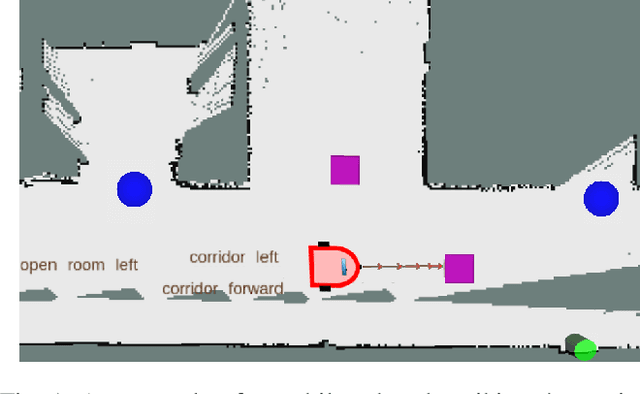
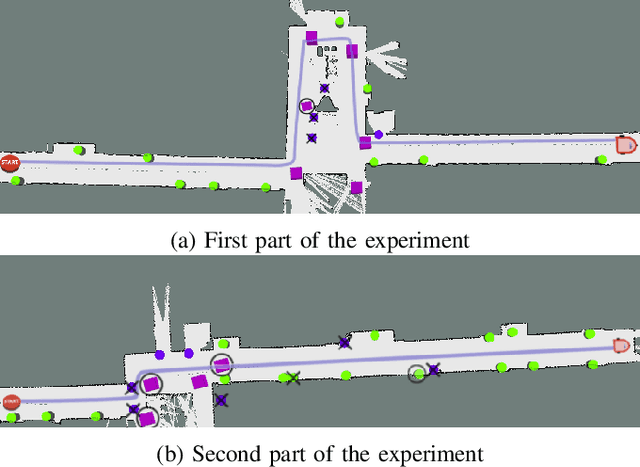
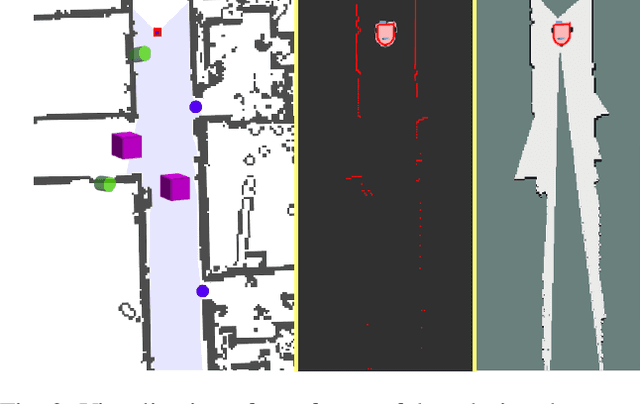
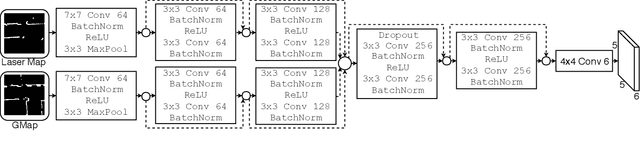
This paper describes a system whereby a robot detects and track human-meaningful navigational cues as it navigates in an indoor environment. It is intended as the sensor front-end for a mobile robot system that can communicate its navigational context with human users. From simulated LiDAR scan data we construct a set of 2D occupancy grid bitmaps, then hand-label these with human-scale navigational features such as closed doors, open corridors and intersections. We train a Convolutional Neural Network (CNN) to recognize these features on input bitmaps. In our demonstration system, these features are detected at every time step then passed to a tracking module that does frame-to-frame data association to improve detection accuracy and identify stable unique features. We evaluate the system in both simulation and the real world. We compare the performance of using input occupancy grids obtained directly from LiDAR data, or incrementally constructed with SLAM, and their combination.
Active Image-based Modeling with a Toy Drone
Mar 07, 2018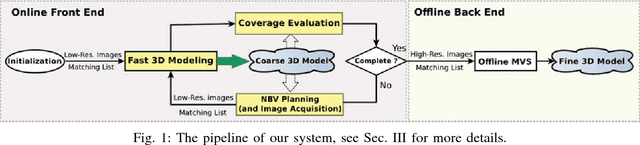
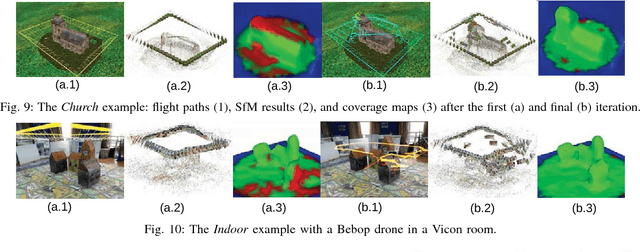


Image-based modeling techniques can now generate photo-realistic 3D models from images. But it is up to users to provide high quality images with good coverage and view overlap, which makes the data capturing process tedious and time consuming. We seek to automate data capturing for image-based modeling. The core of our system is an iterative linear method to solve the multi-view stereo (MVS) problem quickly and plan the Next-Best-View (NBV) effectively. Our fast MVS algorithm enables online model reconstruction and quality assessment to determine the NBVs on the fly. We test our system with a toy unmanned aerial vehicle (UAV) in simulated, indoor and outdoor experiments. Results show that our system improves the efficiency of data acquisition and ensures the completeness of the final model.
UAV Visual Teach and Repeat Using Only Semantic Object Features
Jan 24, 2018
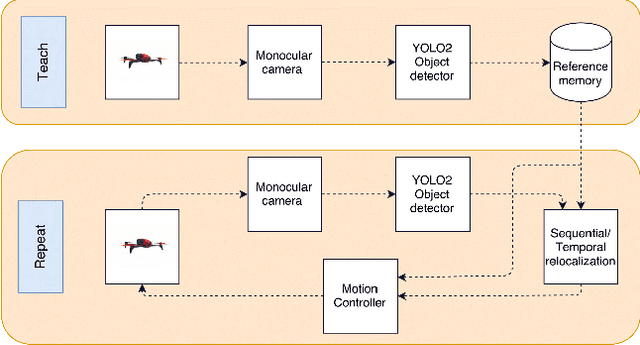
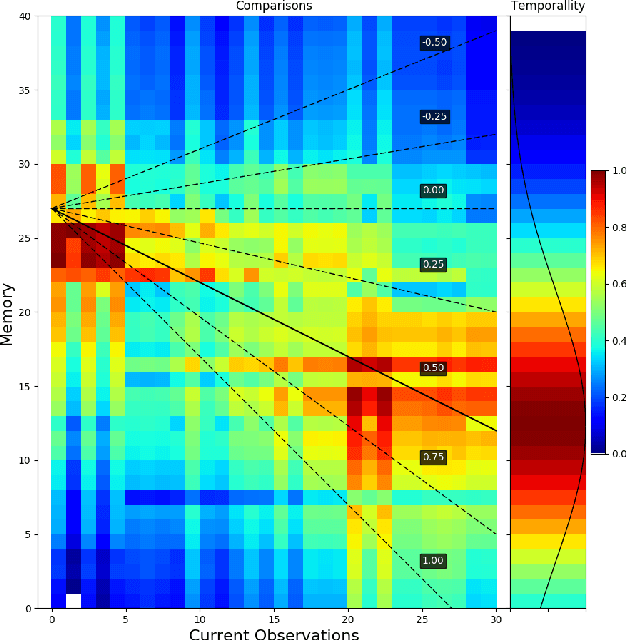
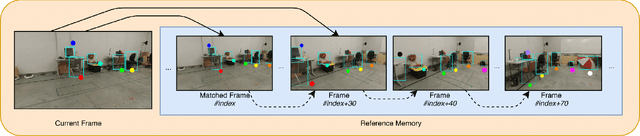
We demonstrate the use of semantic object detections as robust features for Visual Teach and Repeat (VTR). Recent CNN-based object detectors are able to reliably detect objects of tens or hundreds of categories in a video at frame rates. We show that such detections are repeatable enough to use as landmarks for VTR, without any low-level image features. Since object detections are highly invariant to lighting and surface appearance changes, our VTR can cope with global lighting changes and local movements of the landmark objects. In the teaching phase, we build a series of compact scene descriptors: a list of detected object labels and their image-plane locations. In the repeating phase, we use Seq-SLAM-like relocalization to identify the most similar learned scene, then use a motion control algorithm based on the funnel lane theory to navigate the robot along the previously piloted trajectory. We evaluate the method on a commodity UAV, examining the robustness of the algorithm to new viewpoints, lighting conditions, and movements of landmark objects. The results suggest that semantic object features could be useful due to their invariance to superficial appearance changes compared to low-level image features.
Publishing Identifiable Experiment Code And Configuration Is Important, Good and Easy
Apr 10, 2012We argue for the value of publishing the exact code, configuration and data processing scripts used to produce empirical work in robotics. In particular, we recommend publishing a unique identifier for the code package in the paper itself, as a promise to the reader that this is the relavant code. We review some recent discussion of best practice for reproducibility in various professional organisations and journals, and discuss the current reward structure for publishing code in robotics, along with some ideas for improvement.