 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkip-Thought Vectors
Jun 22, 2015
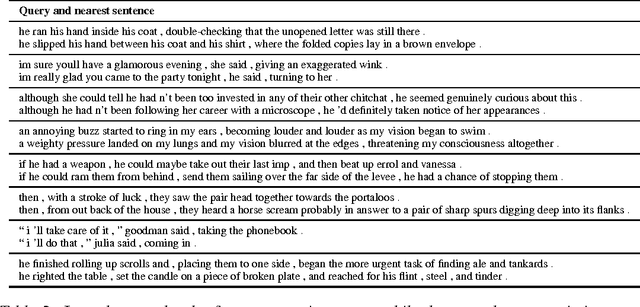
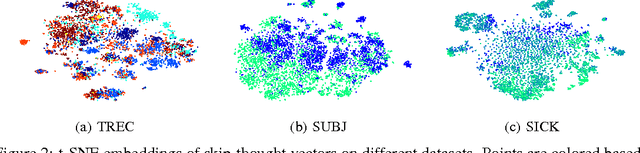

We describe an approach for unsupervised learning of a generic, distributed sentence encoder. Using the continuity of text from books, we train an encoder-decoder model that tries to reconstruct the surrounding sentences of an encoded passage. Sentences that share semantic and syntactic properties are thus mapped to similar vector representations. We next introduce a simple vocabulary expansion method to encode words that were not seen as part of training, allowing us to expand our vocabulary to a million words. After training our model, we extract and evaluate our vectors with linear models on 8 tasks: semantic relatedness, paraphrase detection, image-sentence ranking, question-type classification and 4 benchmark sentiment and subjectivity datasets. The end result is an off-the-shelf encoder that can produce highly generic sentence representations that are robust and perform well in practice. We will make our encoder publicly available.
Unifying Visual-Semantic Embeddings with Multimodal Neural Language Models
Nov 10, 2014
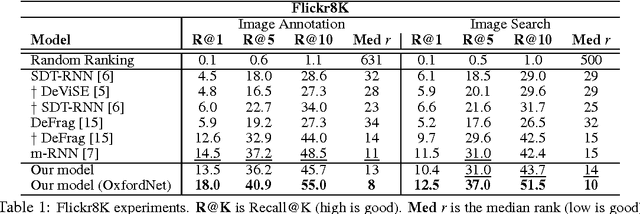
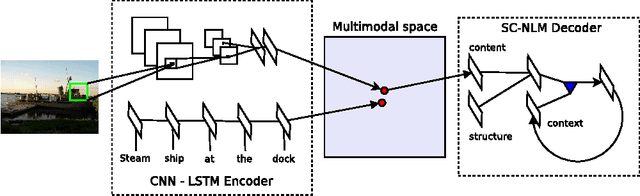
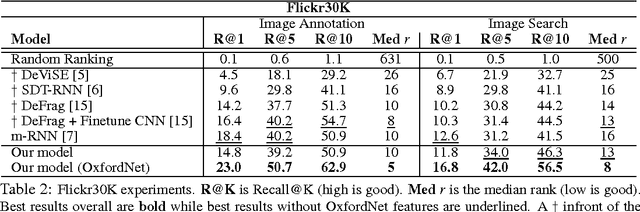
Inspired by recent advances in multimodal learning and machine translation, we introduce an encoder-decoder pipeline that learns (a): a multimodal joint embedding space with images and text and (b): a novel language model for decoding distributed representations from our space. Our pipeline effectively unifies joint image-text embedding models with multimodal neural language models. We introduce the structure-content neural language model that disentangles the structure of a sentence to its content, conditioned on representations produced by the encoder. The encoder allows one to rank images and sentences while the decoder can generate novel descriptions from scratch. Using LSTM to encode sentences, we match the state-of-the-art performance on Flickr8K and Flickr30K without using object detections. We also set new best results when using the 19-layer Oxford convolutional network. Furthermore we show that with linear encoders, the learned embedding space captures multimodal regularities in terms of vector space arithmetic e.g. *image of a blue car* - "blue" + "red" is near images of red cars. Sample captions generated for 800 images are made available for comparison.
Input Warping for Bayesian Optimization of Non-stationary Functions
Jun 11, 2014


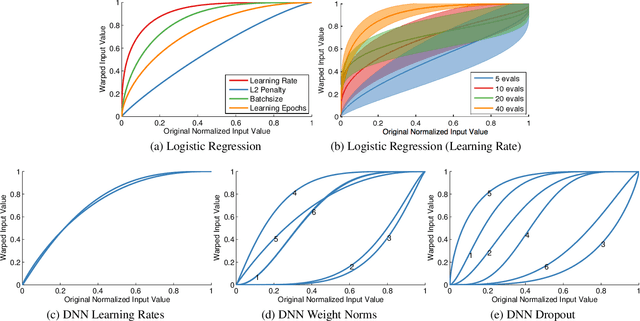
Bayesian optimization has proven to be a highly effective methodology for the global optimization of unknown, expensive and multimodal functions. The ability to accurately model distributions over functions is critical to the effectiveness of Bayesian optimization. Although Gaussian processes provide a flexible prior over functions which can be queried efficiently, there are various classes of functions that remain difficult to model. One of the most frequently occurring of these is the class of non-stationary functions. The optimization of the hyperparameters of machine learning algorithms is a problem domain in which parameters are often manually transformed a priori, for example by optimizing in "log-space," to mitigate the effects of spatially-varying length scale. We develop a methodology for automatically learning a wide family of bijective transformations or warpings of the input space using the Beta cumulative distribution function. We further extend the warping framework to multi-task Bayesian optimization so that multiple tasks can be warped into a jointly stationary space. On a set of challenging benchmark optimization tasks, we observe that the inclusion of warping greatly improves on the state-of-the-art, producing better results faster and more reliably.
A Multiplicative Model for Learning Distributed Text-Based Attribute Representations
Jun 10, 2014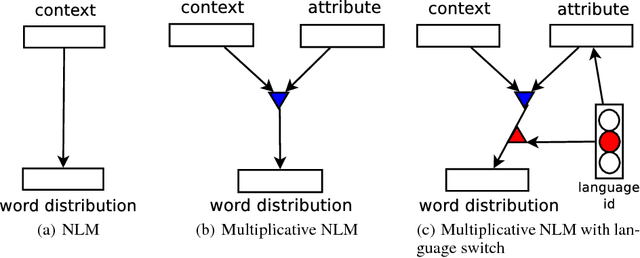

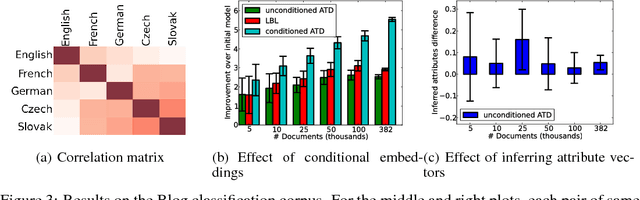
In this paper we propose a general framework for learning distributed representations of attributes: characteristics of text whose representations can be jointly learned with word embeddings. Attributes can correspond to document indicators (to learn sentence vectors), language indicators (to learn distributed language representations), meta-data and side information (such as the age, gender and industry of a blogger) or representations of authors. We describe a third-order model where word context and attribute vectors interact multiplicatively to predict the next word in a sequence. This leads to the notion of conditional word similarity: how meanings of words change when conditioned on different attributes. We perform several experimental tasks including sentiment classification, cross-lingual document classification, and blog authorship attribution. We also qualitatively evaluate conditional word neighbours and attribute-conditioned text generation.
Efficient Parametric Projection Pursuit Density Estimation
Oct 19, 2012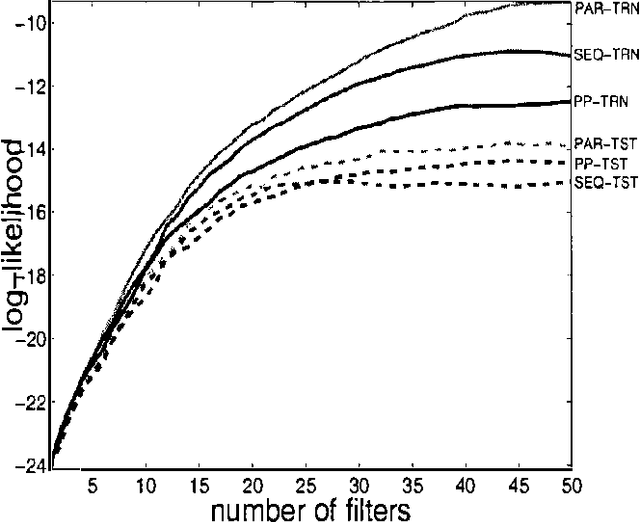
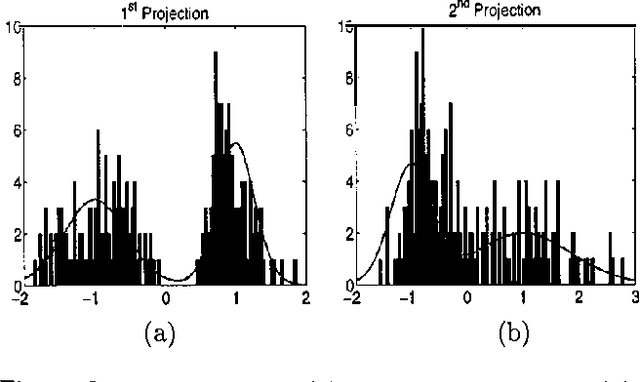
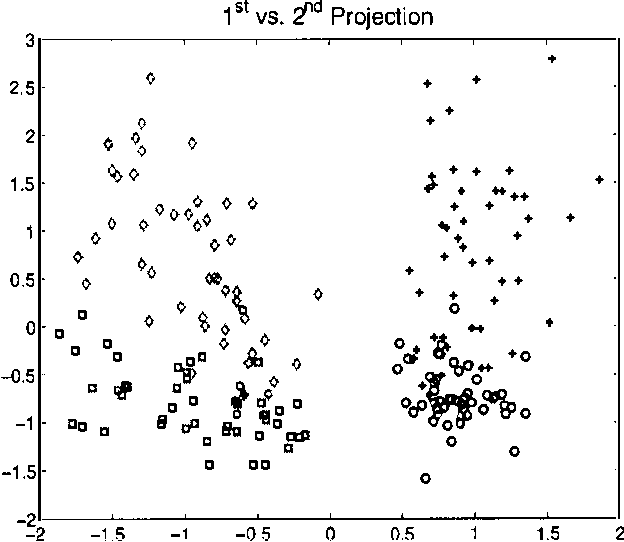

Product models of low dimensional experts are a powerful way to avoid the curse of dimensionality. We present the ``under-complete product of experts' (UPoE), where each expert models a one dimensional projection of the data. The UPoE is fully tractable and may be interpreted as a parametric probabilistic model for projection pursuit. Its ML learning rules are identical to the approximate learning rules proposed before for under-complete ICA. We also derive an efficient sequential learning algorithm and discuss its relationship to projection pursuit density estimation and feature induction algorithms for additive random field models.
Active Collaborative Filtering
Oct 19, 2012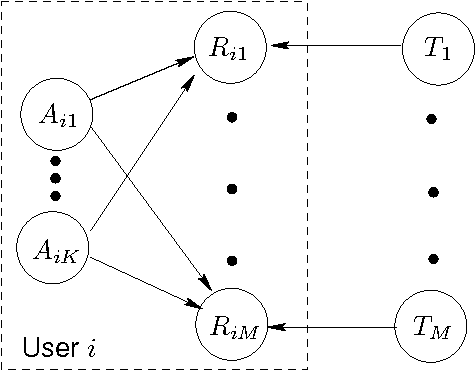

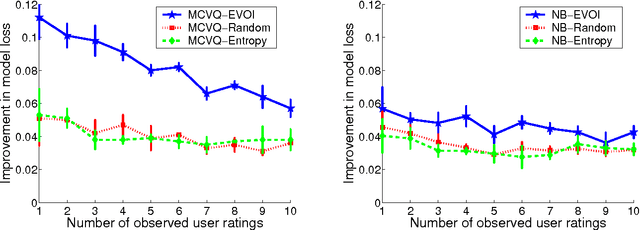
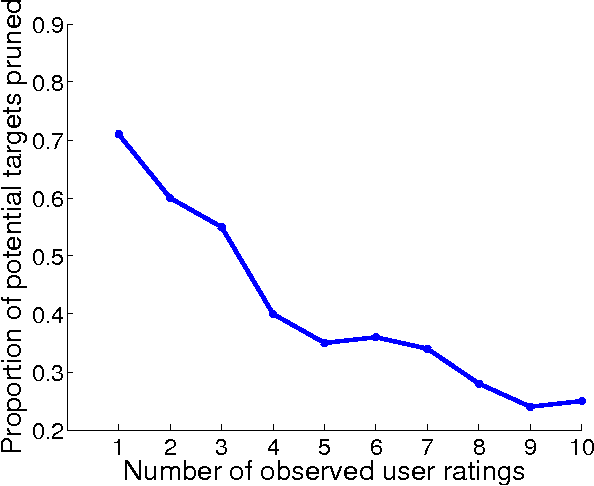
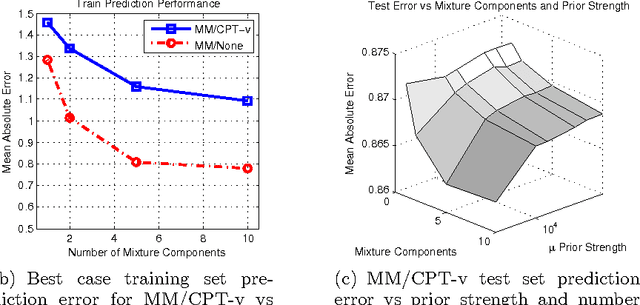
Collaborative filtering (CF) allows the preferences of multiple users to be pooled to make recommendations regarding unseen products. We consider in this paper the problem of online and interactive CF: given the current ratings associated with a user, what queries (new ratings) would most improve the quality of the recommendations made? We cast this terms of expected value of information (EVOI); but the online computational cost of computing optimal queries is prohibitive. We show how offline prototyping and computation of bounds on EVOI can be used to dramatically reduce the required online computation. The framework we develop is general, but we focus on derivations and empirical study in the specific case of the multiple-cause vector quantization model.
Fast Exact Inference for Recursive Cardinality Models
Oct 16, 2012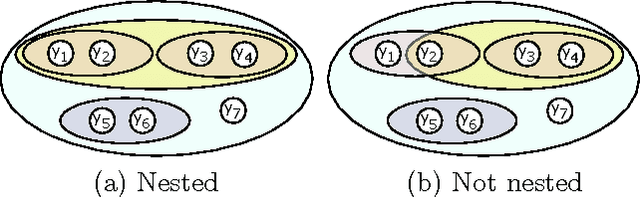
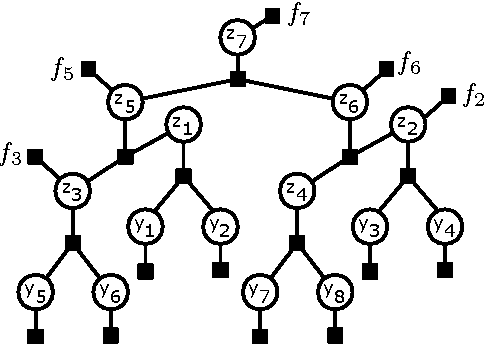
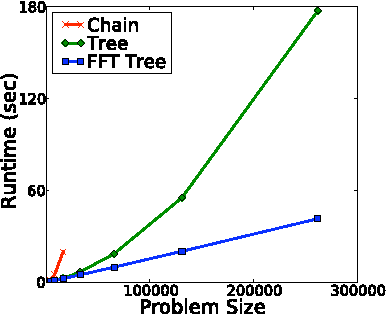
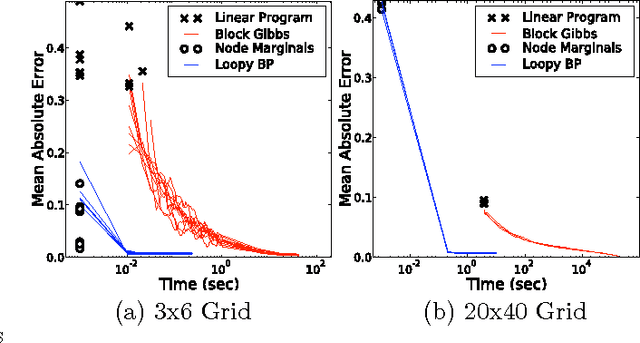
Cardinality potentials are a generally useful class of high order potential that affect probabilities based on how many of D binary variables are active. Maximum a posteriori (MAP) inference for cardinality potential models is well-understood, with efficient computations taking O(DlogD) time. Yet efficient marginalization and sampling have not been addressed as thoroughly in the machine learning community. We show that there exists a simple algorithm for computing marginal probabilities and drawing exact joint samples that runs in O(Dlog2 D) time, and we show how to frame the algorithm as efficient belief propagation in a low order tree-structured model that includes additional auxiliary variables. We then develop a new, more general class of models, termed Recursive Cardinality models, which take advantage of this efficiency. Finally, we show how to do efficient exact inference in models composed of a tree structure and a cardinality potential. We explore the expressive power of Recursive Cardinality models and empirically demonstrate their utility.
Collaborative Filtering and the Missing at Random Assumption
Jun 20, 2012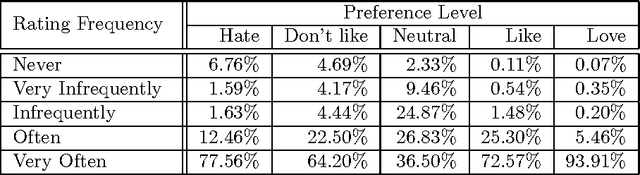
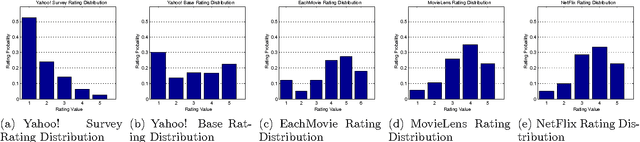
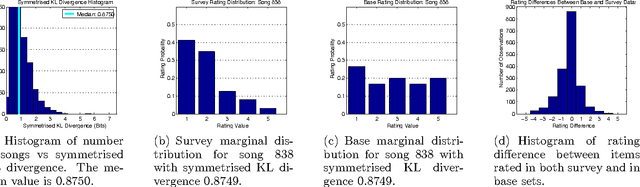
Rating prediction is an important application, and a popular research topic in collaborative filtering. However, both the validity of learning algorithms, and the validity of standard testing procedures rest on the assumption that missing ratings are missing at random (MAR). In this paper we present the results of a user study in which we collect a random sample of ratings from current users of an online radio service. An analysis of the rating data collected in the study shows that the sample of random ratings has markedly different properties than ratings of user-selected songs. When asked to report on their own rating behaviour, a large number of users indicate they believe their opinion of a song does affect whether they choose to rate that song, a violation of the MAR condition. Finally, we present experimental results showing that incorporating an explicit model of the missing data mechanism can lead to significant improvements in prediction performance on the random sample of ratings.
Flexible Priors for Exemplar-based Clustering
Jun 13, 2012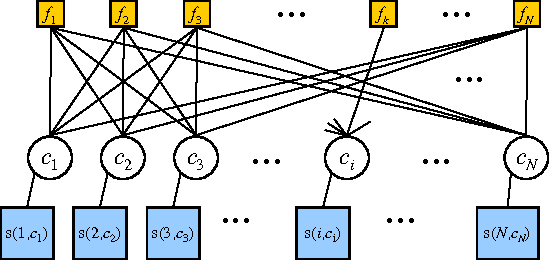
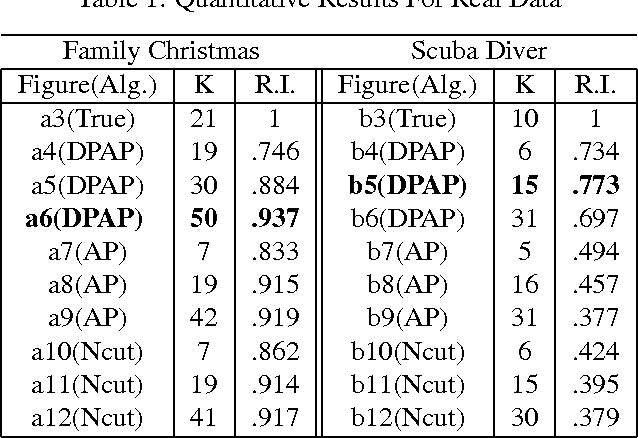
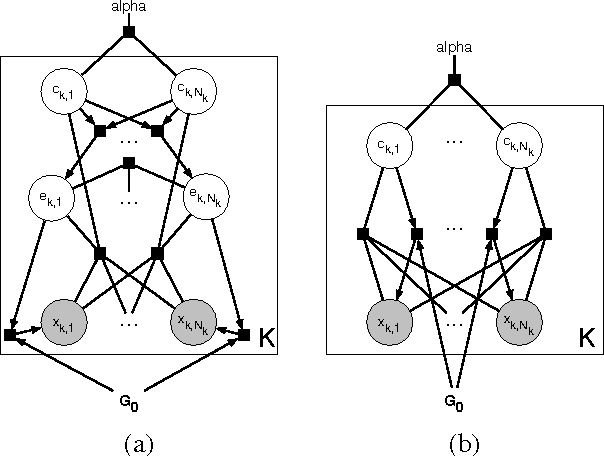
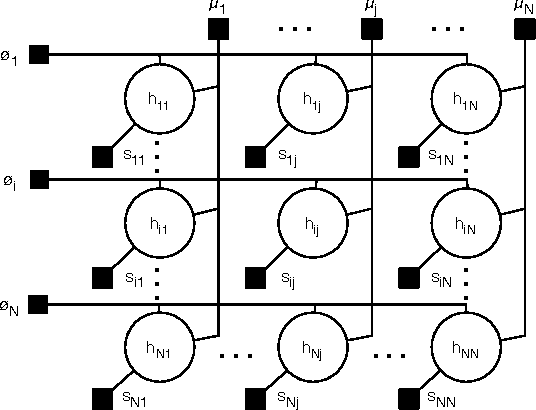
Exemplar-based clustering methods have been shown to produce state-of-the-art results on a number of synthetic and real-world clustering problems. They are appealing because they offer computational benefits over latent-mean models and can handle arbitrary pairwise similarity measures between data points. However, when trying to recover underlying structure in clustering problems, tailored similarity measures are often not enough; we also desire control over the distribution of cluster sizes. Priors such as Dirichlet process priors allow the number of clusters to be unspecified while expressing priors over data partitions. To our knowledge, they have not been applied to exemplar-based models. We show how to incorporate priors, including Dirichlet process priors, into the recently introduced affinity propagation algorithm. We develop an efficient maxproduct belief propagation algorithm for our new model and demonstrate experimentally how the expanded range of clustering priors allows us to better recover true clusterings in situations where we have some information about the generating process.
A Framework for Optimizing Paper Matching
Feb 14, 2012
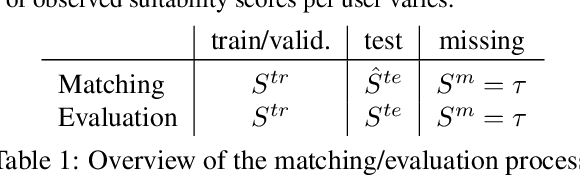
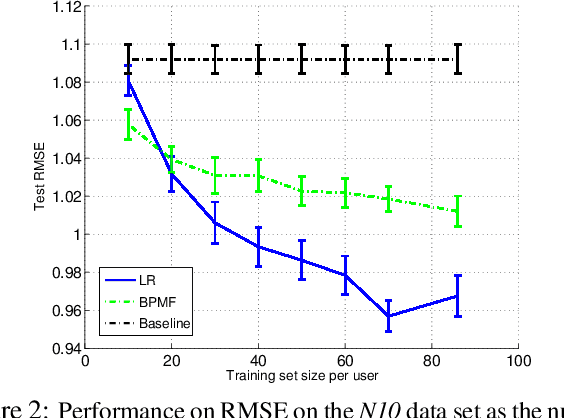
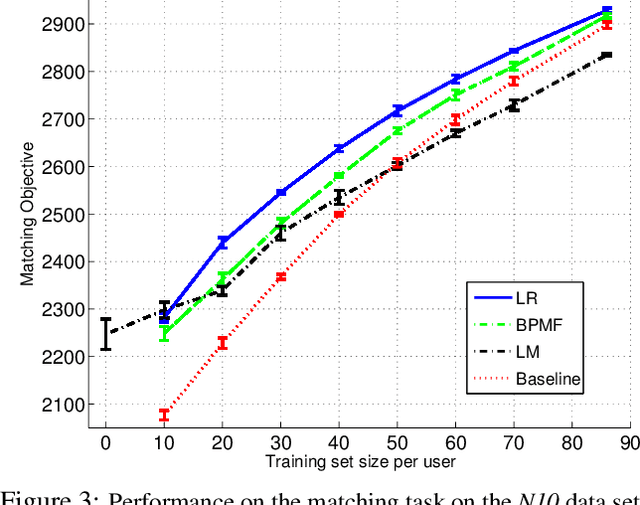
At the heart of many scientific conferences is the problem of matching submitted papers to suitable reviewers. Arriving at a good assignment is a major and important challenge for any conference organizer. In this paper we propose a framework to optimize paper-to-reviewer assignments. Our framework uses suitability scores to measure pairwise affinity between papers and reviewers. We show how learning can be used to infer suitability scores from a small set of provided scores, thereby reducing the burden on reviewers and organizers. We frame the assignment problem as an integer program and propose several variations for the paper-to-reviewer matching domain. We also explore how learning and matching interact. Experiments on two conference data sets examine the performance of several learning methods as well as the effectiveness of the matching formulations.