 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizing Jensen and Bregman divergences with comparative convexity and the statistical Bhattacharyya distances with comparable means
May 03, 2017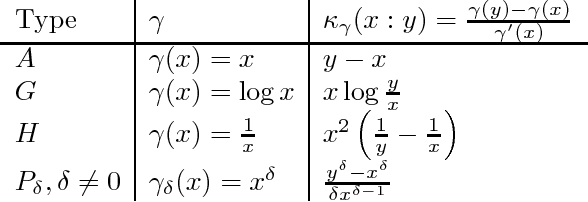
Comparative convexity is a generalization of convexity relying on abstract notions of means. We define the Jensen divergence and the Jensen diversity from the viewpoint of comparative convexity, and show how to obtain the generalized Bregman divergences as limit cases of skewed Jensen divergences. In particular, we report explicit formula of these generalized Bregman divergences when considering quasi-arithmetic means. Finally, we introduce a generalization of the Bhattacharyya statistical distances based on comparative means using relative convexity.
Making Deep Neural Networks Robust to Label Noise: a Loss Correction Approach
Mar 22, 2017
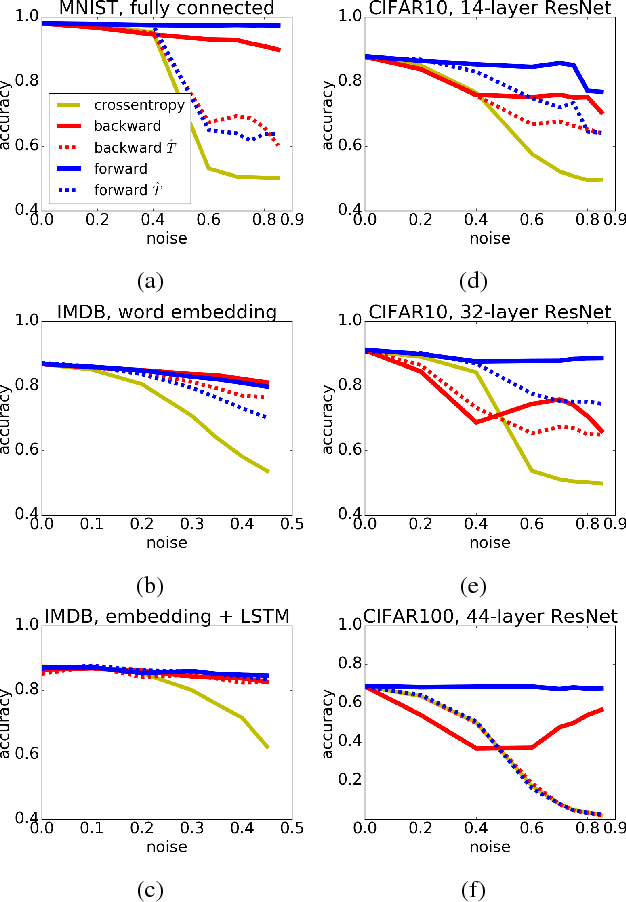
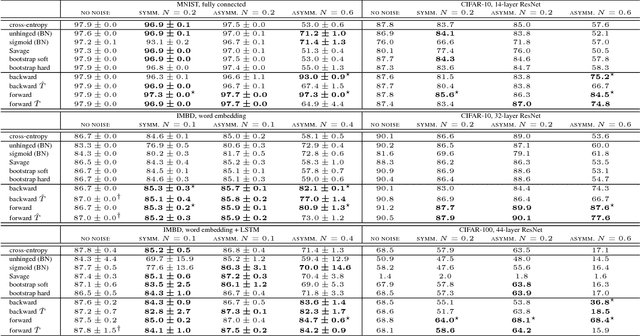
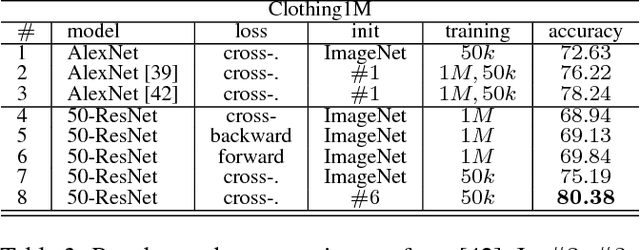
We present a theoretically grounded approach to train deep neural networks, including recurrent networks, subject to class-dependent label noise. We propose two procedures for loss correction that are agnostic to both application domain and network architecture. They simply amount to at most a matrix inversion and multiplication, provided that we know the probability of each class being corrupted into another. We further show how one can estimate these probabilities, adapting a recent technique for noise estimation to the multi-class setting, and thus providing an end-to-end framework. Extensive experiments on MNIST, IMDB, CIFAR-10, CIFAR-100 and a large scale dataset of clothing images employing a diversity of architectures --- stacking dense, convolutional, pooling, dropout, batch normalization, word embedding, LSTM and residual layers --- demonstrate the noise robustness of our proposals. Incidentally, we also prove that, when ReLU is the only non-linearity, the loss curvature is immune to class-dependent label noise.
The Crossover Process: Learnability and Data Protection from Inference Attacks
Mar 07, 2017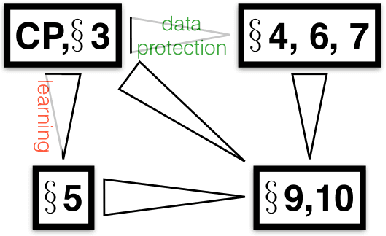
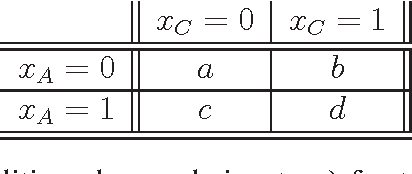
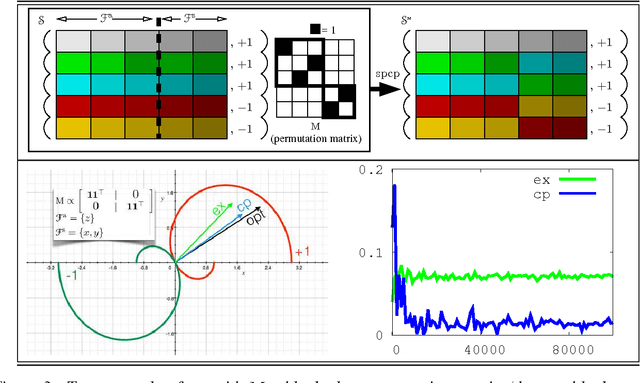
It is usual to consider data protection and learnability as conflicting objectives. This is not always the case: we show how to jointly control inference --- seen as the attack --- and learnability by a noise-free process that mixes training examples, the Crossover Process (cp). One key point is that the cp~is typically able to alter joint distributions without touching on marginals, nor altering the sufficient statistic for the class. In other words, it saves (and sometimes improves) generalization for supervised learning, but can alter the relationship between covariates --- and therefore fool measures of nonlinear independence and causal inference into misleading ad-hoc conclusions. For example, a cp~can increase / decrease odds ratios, bring fairness or break fairness, tamper with disparate impact, strengthen, weaken or reverse causal directions, change observed statistical measures of dependence. For each of these, we quantify changes brought by a cp, as well as its statistical impact on generalization abilities via a new complexity measure that we call the Rademacher cp~complexity. Experiments on a dozen readily available domains validate the theory.
Semi-parametric Network Structure Discovery Models
Feb 27, 2017
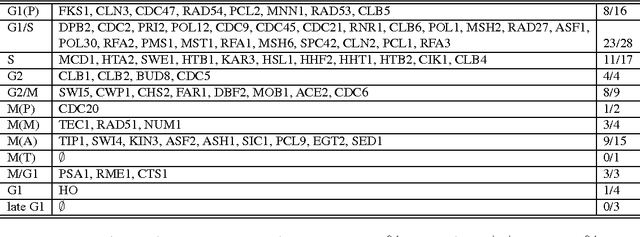
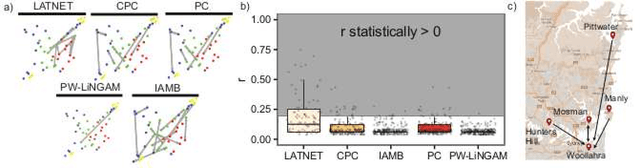
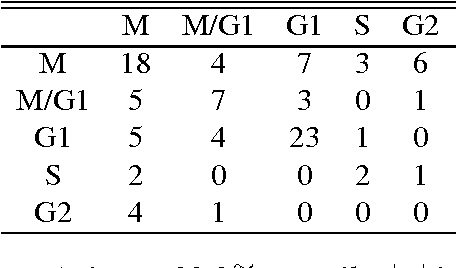
We propose a network structure discovery model for continuous observations that generalizes linear causal models by incorporating a Gaussian process (GP) prior on a network-independent component, and random sparsity and weight matrices as the network-dependent parameters. This approach provides flexible modeling of network-independent trends in the observations as well as uncertainty quantification around the discovered network structure. We establish a connection between our model and multi-task GPs and develop an efficient stochastic variational inference algorithm for it. Furthermore, we formally show that our approach is numerically stable and in fact numerically easy to carry out almost everywhere on the support of the random variables involved. Finally, we evaluate our model on three applications, showing that it outperforms previous approaches. We provide a qualitative and quantitative analysis of the structures discovered for domains such as the study of the full genome regulation of the yeast Saccharomyces cerevisiae.
A series of maximum entropy upper bounds of the differential entropy
Dec 09, 2016We present a series of closed-form maximum entropy upper bounds for the differential entropy of a continuous univariate random variable and study the properties of that series. We then show how to use those generic bounds for upper bounding the differential entropy of Gaussian mixture models. This requires to calculate the raw moments and raw absolute moments of Gaussian mixtures in closed-form that may also be handy in statistical machine learning and information theory. We report on our experiments and discuss on the tightness of those bounds.
Large Margin Nearest Neighbor Classification using Curved Mahalanobis Distances
Sep 26, 2016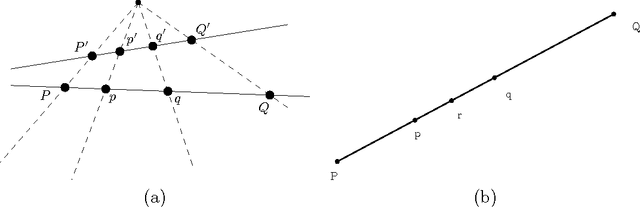
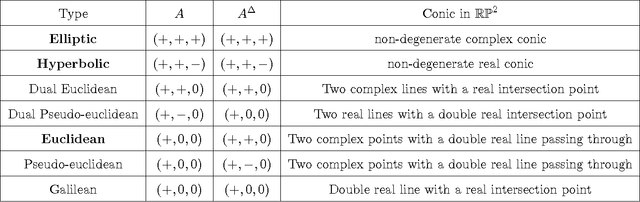
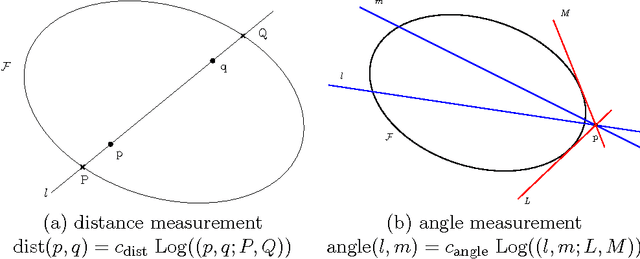
We consider the supervised classification problem of machine learning in Cayley-Klein projective geometries: We show how to learn a curved Mahalanobis metric distance corresponding to either the hyperbolic geometry or the elliptic geometry using the Large Margin Nearest Neighbor (LMNN) framework. We report on our experimental results, and further consider the case of learning a mixed curved Mahalanobis distance. Besides, we show that the Cayley-Klein Voronoi diagrams are affine, and can be built from an equivalent (clipped) power diagrams, and that Cayley-Klein balls have Mahalanobis shapes with displaced centers.
Tsallis Regularized Optimal Transport and Ecological Inference
Sep 15, 2016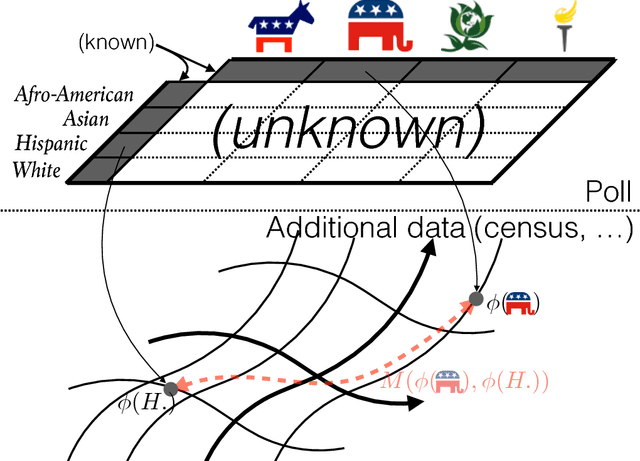

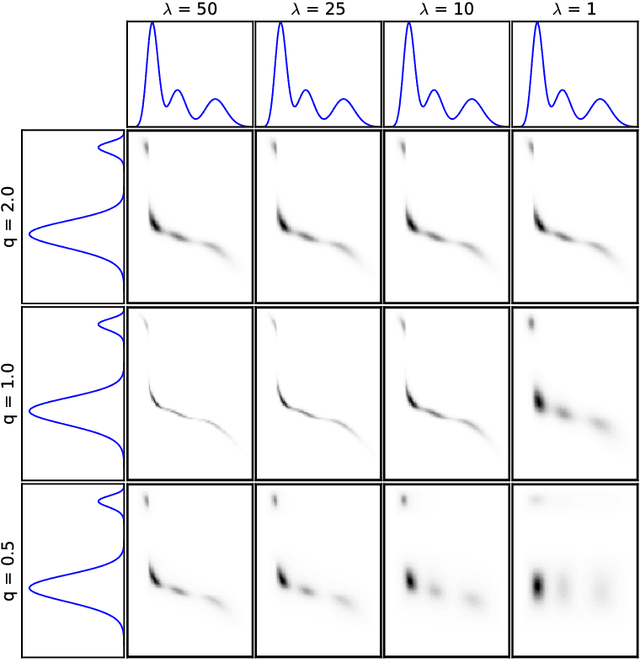
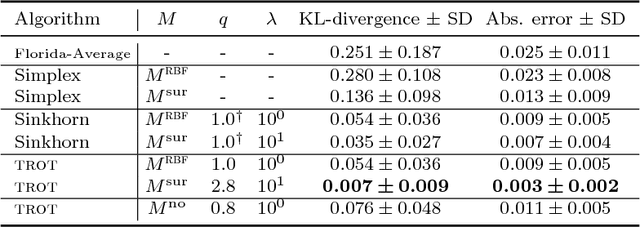
Optimal transport is a powerful framework for computing distances between probability distributions. We unify the two main approaches to optimal transport, namely Monge-Kantorovitch and Sinkhorn-Cuturi, into what we define as Tsallis regularized optimal transport (\trot). \trot~interpolates a rich family of distortions from Wasserstein to Kullback-Leibler, encompassing as well Pearson, Neyman and Hellinger divergences, to name a few. We show that metric properties known for Sinkhorn-Cuturi generalize to \trot, and provide efficient algorithms for finding the optimal transportation plan with formal convergence proofs. We also present the first application of optimal transport to the problem of ecological inference, that is, the reconstruction of joint distributions from their marginals, a problem of large interest in the social sciences. \trot~provides a convenient framework for ecological inference by allowing to compute the joint distribution --- that is, the optimal transportation plan itself --- when side information is available, which is \textit{e.g.} typically what census represents in political science. Experiments on data from the 2012 US presidential elections display the potential of \trot~in delivering a faithful reconstruction of the joint distribution of ethnic groups and voter preferences.
A scaled Bregman theorem with applications
Jul 01, 2016
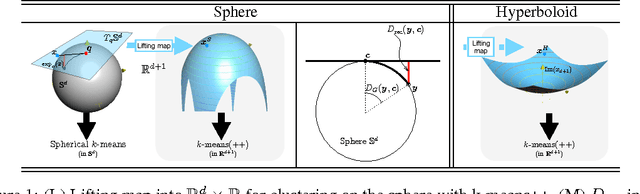

Bregman divergences play a central role in the design and analysis of a range of machine learning algorithms. This paper explores the use of Bregman divergences to establish reductions between such algorithms and their analyses. We present a new scaled isodistortion theorem involving Bregman divergences (scaled Bregman theorem for short) which shows that certain "Bregman distortions'" (employing a potentially non-convex generator) may be exactly re-written as a scaled Bregman divergence computed over transformed data. Admissible distortions include geodesic distances on curved manifolds and projections or gauge-normalisation, while admissible data include scalars, vectors and matrices. Our theorem allows one to leverage to the wealth and convenience of Bregman divergences when analysing algorithms relying on the aforementioned Bregman distortions. We illustrate this with three novel applications of our theorem: a reduction from multi-class density ratio to class-probability estimation, a new adaptive projection free yet norm-enforcing dual norm mirror descent algorithm, and a reduction from clustering on flat manifolds to clustering on curved manifolds. Experiments on each of these domains validate the analyses and suggest that the scaled Bregman theorem might be a worthy addition to the popular handful of Bregman divergence properties that have been pervasive in machine learning.
Fast $(1+ε)$-approximation of the Löwner extremal matrices of high-dimensional symmetric matrices
Apr 06, 2016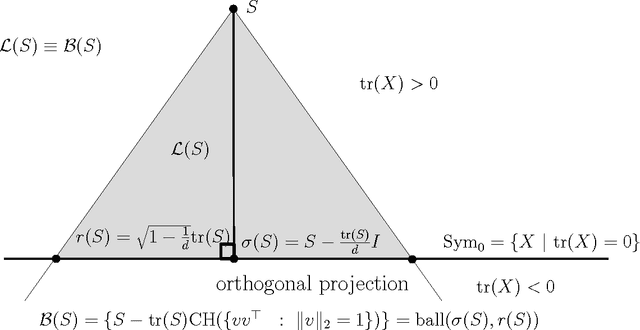
Matrix data sets are common nowadays like in biomedical imaging where the Diffusion Tensor Magnetic Resonance Imaging (DT-MRI) modality produces data sets of 3D symmetric positive definite matrices anchored at voxel positions capturing the anisotropic diffusion properties of water molecules in biological tissues. The space of symmetric matrices can be partially ordered using the L\"owner ordering, and computing extremal matrices dominating a given set of matrices is a basic primitive used in matrix-valued signal processing. In this letter, we design a fast and easy-to-implement iterative algorithm to approximate arbitrarily finely these extremal matrices. Finally, we discuss on extensions to matrix clustering.
Fast Learning from Distributed Datasets without Entity Matching
Mar 13, 2016
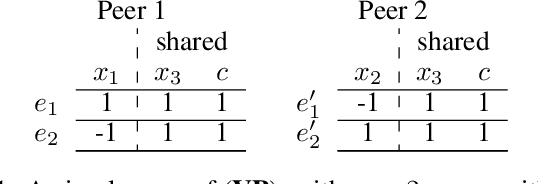
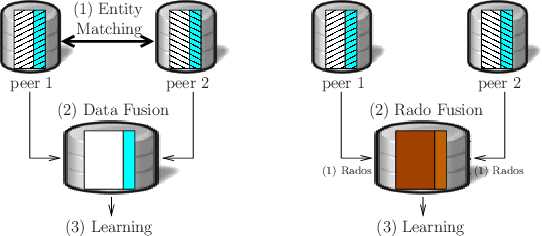
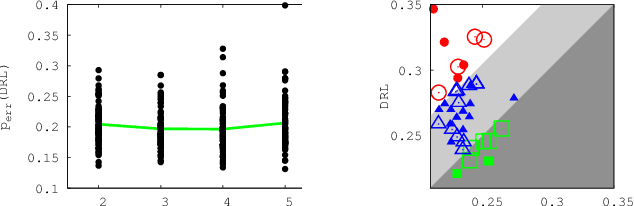
Consider the following data fusion scenario: two datasets/peers contain the same real-world entities described using partially shared features, e.g. banking and insurance company records of the same customer base. Our goal is to learn a classifier in the cross product space of the two domains, in the hard case in which no shared ID is available -- e.g. due to anonymization. Traditionally, the problem is approached by first addressing entity matching and subsequently learning the classifier in a standard manner. We present an end-to-end solution which bypasses matching entities, based on the recently introduced concept of Rademacher observations (rados). Informally, we replace the minimisation of a loss over examples, which requires to solve entity resolution, by the equivalent minimisation of a (different) loss over rados. Among others, key properties we show are (i) a potentially huge subset of these rados does not require to perform entity matching, and (ii) the algorithm that provably minimizes the rado loss over these rados has time and space complexities smaller than the algorithm minimizing the equivalent example loss. Last, we relax a key assumption of the model, that the data is vertically partitioned among peers --- in this case, we would not even know the existence of a solution to entity resolution. In this more general setting, experiments validate the possibility of significantly beating even the optimal peer in hindsight.