 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree Lunch for Pass@$k$? Low Cost Diverse Sampling for Diffusion Language Models
Mar 05, 2026Diverse outputs in text generation are necessary for effective exploration in complex reasoning tasks, such as code generation and mathematical problem solving. Such Pass@$k$ problems benefit from distinct candidates covering the solution space. However, traditional sampling approaches often waste computational resources on repetitive failure modes. While Diffusion Language Models have emerged as a competitive alternative to the prevailing Autoregressive paradigm, they remain susceptible to this redundancy, with independent samples frequently collapsing into similar modes. To address this, we propose a training free, low cost intervention to enhance generative diversity in Diffusion Language Models. Our approach modifies intermediate samples in a batch sequentially, where each sample is repelled from the feature space of previous samples, actively penalising redundancy. Unlike prior methods that require retraining or beam search, our strategy incurs negligible computational overhead, while ensuring that each sample contributes a unique perspective to the batch. We evaluate our method on the HumanEval and GSM8K benchmarks using the LLaDA-8B-Instruct model. Our results demonstrate significantly improved diversity and Pass@$k$ performance across various temperature settings. As a simple modification to the sampling process, our method offers an immediate, low-cost improvement for current and future Diffusion Language Models in tasks that benefit from diverse solution search. We make our code available at https://github.com/sean-lamont/odd.
3D-Prover: Diversity Driven Theorem Proving With Determinantal Point Processes
Oct 14, 2024



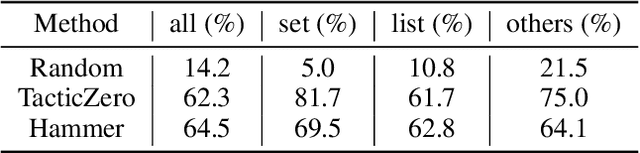
A key challenge in automated formal reasoning is the intractable search space, which grows exponentially with the depth of the proof. This branching is caused by the large number of candidate proof tactics which can be applied to a given goal. Nonetheless, many of these tactics are semantically similar or lead to an execution error, wasting valuable resources in both cases. We address the problem of effectively pruning this search, using only synthetic data generated from previous proof attempts. We first demonstrate that it is possible to generate semantically aware tactic representations which capture the effect on the proving environment, likelihood of success and execution time. We then propose a novel filtering mechanism which leverages these representations to select semantically diverse and high quality tactics, using Determinantal Point Processes. Our approach, 3D-Prover, is designed to be general, and to augment any underlying tactic generator. We demonstrate the effectiveness of 3D-Prover on the miniF2F-valid and miniF2F-test benchmarks by augmenting the ReProver LLM. We show that our approach leads to an increase in the overall proof rate, as well as a significant improvement in the tactic success rate, execution time and diversity.
Approximate Nearest Neighbour Search on Dynamic Datasets: An Investigation
Apr 30, 2024Approximate k-Nearest Neighbour (ANN) methods are often used for mining information and aiding machine learning on large scale high-dimensional datasets. ANN methods typically differ in the index structure used for accelerating searches, resulting in various recall/runtime trade-off points. For applications with static datasets, runtime constraints and dataset properties can be used to empirically select an ANN method with suitable operating characteristics. However, for applications with dynamic datasets, which are subject to frequent online changes (like addition of new samples), there is currently no consensus as to which ANN methods are most suitable. Traditional evaluation approaches do not consider the computational costs of updating the index structure, as well as the frequency and size of index updates. To address this, we empirically evaluate 5 popular ANN methods on two main applications (online data collection and online feature learning) while taking into account these considerations. Two dynamic datasets are used, derived from the SIFT1M dataset with 1 million samples and the DEEP1B dataset with 1 billion samples. The results indicate that the often used k-d trees method is not suitable on dynamic datasets as it is slower than a straightforward baseline exhaustive search method. For online data collection, the Hierarchical Navigable Small World Graphs method achieves a consistent speedup over baseline across a wide range of recall rates. For online feature learning, the Scalable Nearest Neighbours method is faster than baseline for recall rates below 75%.
BAIT: Benchmarking (Embedding) Architectures for Interactive Theorem-Proving
Mar 06, 2024Artificial Intelligence for Theorem Proving has given rise to a plethora of benchmarks and methodologies, particularly in Interactive Theorem Proving (ITP). Research in the area is fragmented, with a diverse set of approaches being spread across several ITP systems. This presents a significant challenge to the comparison of methods, which are often complex and difficult to replicate. Addressing this, we present BAIT, a framework for fair and streamlined comparison of learning approaches in ITP. We demonstrate BAIT's capabilities with an in-depth comparison, across several ITP benchmarks, of state-of-the-art architectures applied to the problem of formula embedding. We find that Structure Aware Transformers perform particularly well, improving on techniques associated with the original problem sets. BAIT also allows us to assess the end-to-end proving performance of systems built on interactive environments. This unified perspective reveals a novel end-to-end system that improves on prior work. We also provide a qualitative analysis, illustrating that improved performance is associated with more semantically-aware embeddings. By streamlining the implementation and comparison of Machine Learning algorithms in the ITP context, we anticipate BAIT will be a springboard for future research.
Cross-Entropy Estimators for Sequential Experiment Design with Reinforcement Learning
May 29, 2023



Reinforcement learning can effectively learn amortised design policies for designing sequences of experiments. However, current methods rely on contrastive estimators of expected information gain, which require an exponential number of contrastive samples to achieve an unbiased estimation. We propose an alternative lower bound estimator, based on the cross-entropy of the joint model distribution and a flexible proposal distribution. This proposal distribution approximates the true posterior of the model parameters given the experimental history and the design policy. Our estimator requires no contrastive samples, can achieve more accurate estimates of high information gains, allows learning of superior design policies, and is compatible with implicit probabilistic models. We assess our algorithm's performance in various tasks, including continuous and discrete designs and explicit and implicit likelihoods.
Transformed Distribution Matching for Missing Value Imputation
Feb 20, 2023



We study the problem of imputing missing values in a dataset, which has important applications in many domains. The key to missing value imputation is to capture the data distribution with incomplete samples and impute the missing values accordingly. In this paper, by leveraging the fact that any two batches of data with missing values come from the same data distribution, we propose to impute the missing values of two batches of samples by transforming them into a latent space through deep invertible functions and matching them distributionally. To learn the transformations and impute the missing values simultaneously, a simple and well-motivated algorithm is proposed. Extensive experiments over a large number of datasets and competing benchmark algorithms show that our method achieves state-of-the-art performance.
The Contextual Lasso: Sparse Linear Models via Deep Neural Networks
Feb 02, 2023



Sparse linear models are a gold standard tool for interpretable machine learning, a field of emerging importance as predictive models permeate decision-making in many domains. Unfortunately, sparse linear models are far less flexible as functions of their input features than black-box models like deep neural networks. With this capability gap in mind, we study a not-uncommon situation where the input features dichotomize into two groups: explanatory features, which we wish to explain the model's predictions, and contextual features, which we wish to determine the model's explanations. This dichotomy leads us to propose the contextual lasso, a new statistical estimator that fits a sparse linear model whose sparsity pattern and coefficients can vary with the contextual features. The fitting process involves learning a nonparametric map, realized via a deep neural network, from contextual feature vector to sparse coefficient vector. To attain sparse coefficients, we train the network with a novel lasso regularizer in the form of a projection layer that maps the network's output onto the space of $\ell_1$-constrained linear models. Extensive experiments on real and synthetic data suggest that the learned models, which remain highly transparent, can be sparser than the regular lasso without sacrificing the predictive power of a standard deep neural network.
Bayesian Optimisation for Mixed-Variable Inputs using Value Proposals
Feb 17, 2022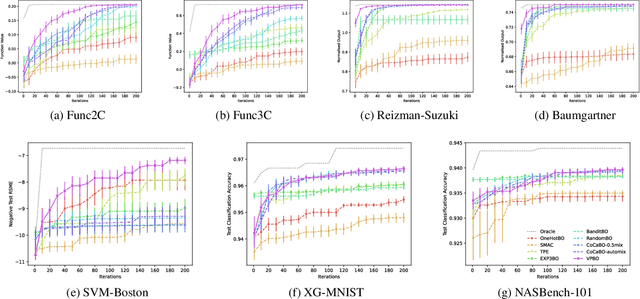
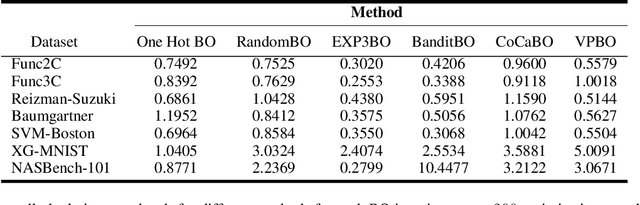

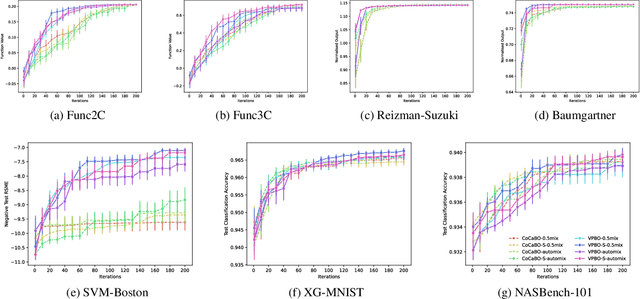
Many real-world optimisation problems are defined over both categorical and continuous variables, yet efficient optimisation methods such asBayesian Optimisation (BO) are not designed tohandle such mixed-variable search spaces. Recent approaches to this problem cast the selection of the categorical variables as a bandit problem, operating independently alongside a BO component which optimises the continuous variables. In this paper, we adopt a holistic view and aim to consolidate optimisation of the categorical and continuous sub-spaces under a single acquisition metric. We derive candidates from the ExpectedImprovement criterion, which we call value proposals, and use these proposals to make selections on both the categorical and continuous components of the input. We show that this unified approach significantly outperforms existing mixed-variable optimisation approaches across several mixed-variable black-box optimisation tasks.
Optimizing Sequential Experimental Design with Deep Reinforcement Learning
Feb 02, 2022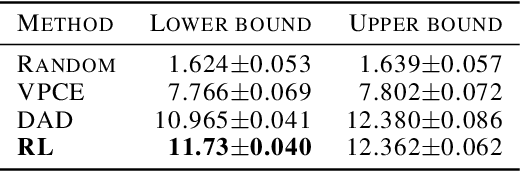
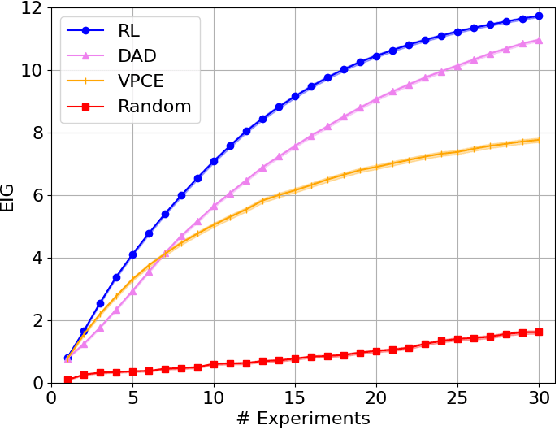
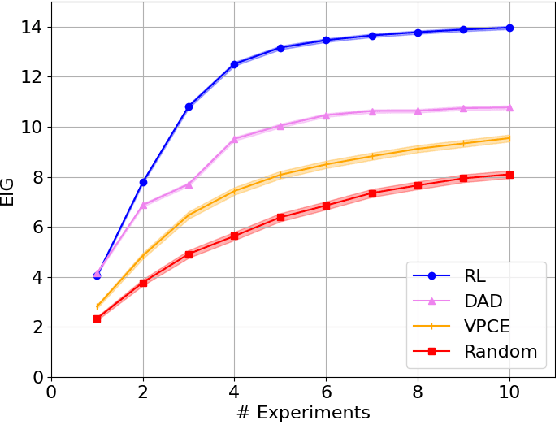

Bayesian approaches developed to solve the optimal design of sequential experiments are mathematically elegant but computationally challenging. Recently, techniques using amortization have been proposed to make these Bayesian approaches practical, by training a parameterized policy that proposes designs efficiently at deployment time. However, these methods may not sufficiently explore the design space, require access to a differentiable probabilistic model and can only optimize over continuous design spaces. Here, we address these limitations by showing that the problem of optimizing policies can be reduced to solving a Markov decision process (MDP). We solve the equivalent MDP with modern deep reinforcement learning techniques. Our experiments show that our approach is also computationally efficient at deployment time and exhibits state-of-the-art performance on both continuous and discrete design spaces, even when the probabilistic model is a black box.
TacticZero: Learning to Prove Theorems from Scratch with Deep Reinforcement Learning
Feb 19, 2021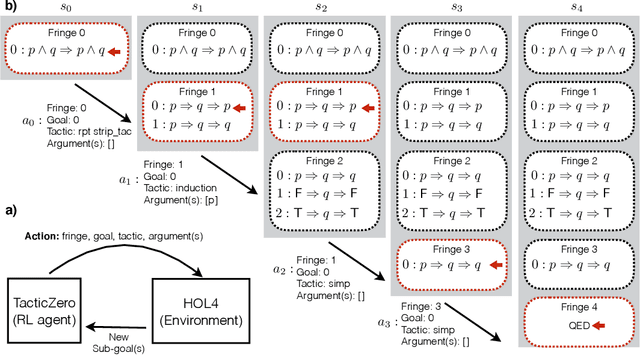
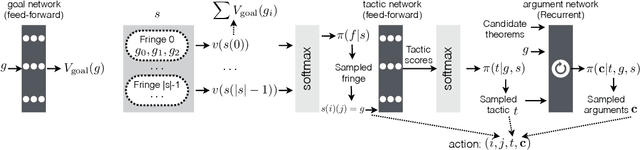
We propose a novel approach to interactive theorem-proving (ITP) using deep reinforcement learning. Unlike previous work, our framework is able to prove theorems both end-to-end and from scratch (i.e., without relying on example proofs from human experts). We formulate the process of ITP as a Markov decision process (MDP) in which each state represents a set of potential derivation paths. The agent learns to select promising derivations as well as appropriate tactics within each derivation using deep policy gradients. This structure allows us to introduce a novel backtracking mechanism which enables the agent to efficiently discard (predicted) dead-end derivations and restart the derivation from promising alternatives. Experimental results show that the framework provides comparable performance to that of the approaches that use human experts, and that it is also capable of proving theorems that it has never seen during training. We further elaborate the role of each component of the framework using ablation studies.