 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning with Stein's Unbiased Risk Estimator
May 26, 2018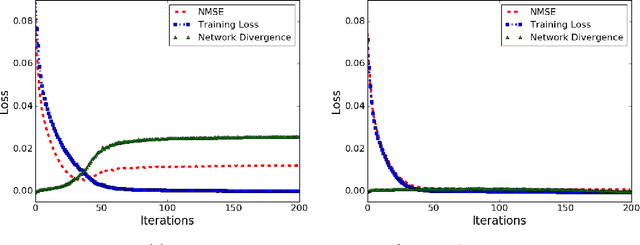
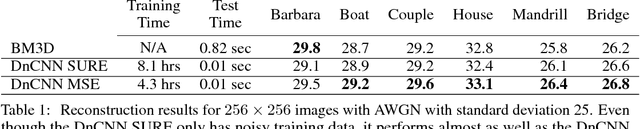

Learning from unlabeled and noisy data is one of the grand challenges of machine learning. As such, it has seen a flurry of research with new ideas proposed continuously. In this work, we revisit a classical idea: Stein's Unbiased Risk Estimator (SURE). We show that, in the context of image recovery, SURE and its generalizations can be used to train convolutional neural networks (CNNs) for a range of image denoising and recovery problems {\em without any ground truth data.} Specifically, our goal is to reconstruct an image $x$ from a {\em noisy} linear transformation (measurement) of the image. We consider two scenarios: one where no additional data is available and one where we have measurements of other images that are drawn from the same noisy distribution as $x$, but have no access to the clean images. Such is the case, for instance, in the context of medical imaging, microscopy, and astronomy, where noise-less ground truth data is rarely available. We show that in this situation, SURE can be used to estimate the mean-squared-error loss associated with an estimate of $x$. Using this estimate of the loss, we train networks to perform denoising and compressed sensing recovery. In addition, we also use the SURE framework to partially explain and improve upon an intriguing results presented by Ulyanov et al. in "Deep Image Prior": that a network initialized with random weights and fit to a single noisy image can effectively denoise that image.
Semi-Supervised Learning via New Deep Network Inversion
Nov 12, 2017

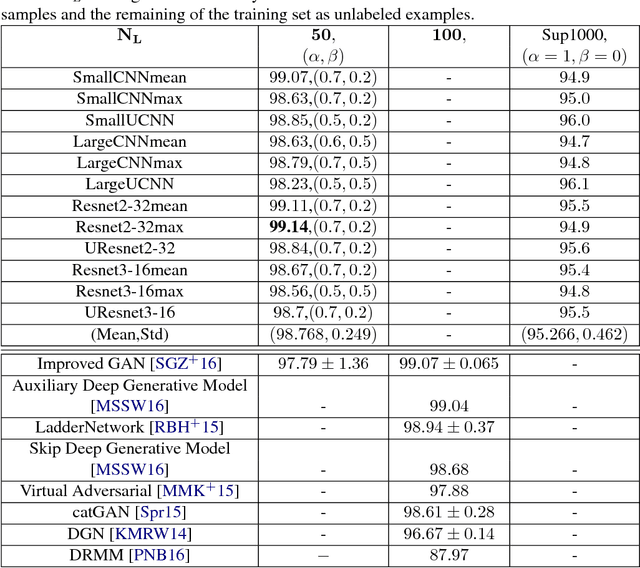
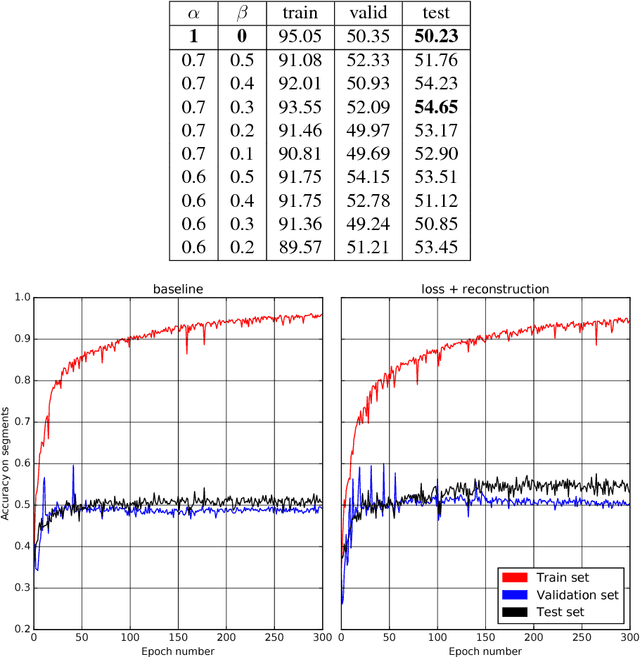
We exploit a recently derived inversion scheme for arbitrary deep neural networks to develop a new semi-supervised learning framework that applies to a wide range of systems and problems. The approach outperforms current state-of-the-art methods on MNIST reaching $99.14\%$ of test set accuracy while using $5$ labeled examples per class. Experiments with one-dimensional signals highlight the generality of the method. Importantly, our approach is simple, efficient, and requires no change in the deep network architecture.
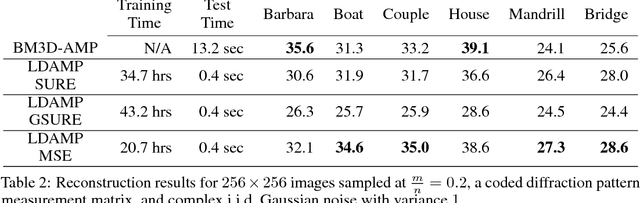
Learned D-AMP: Principled Neural Network based Compressive Image Recovery
Nov 06, 2017
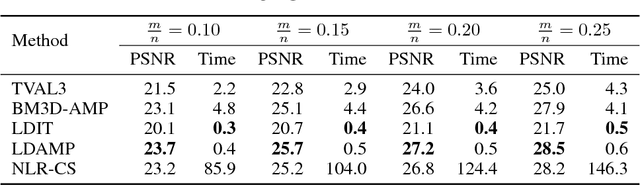
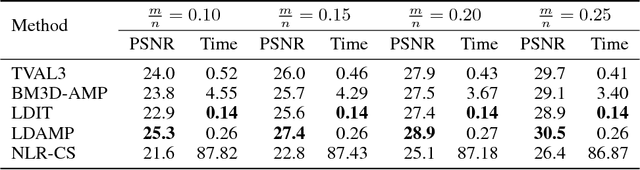
Compressive image recovery is a challenging problem that requires fast and accurate algorithms. Recently, neural networks have been applied to this problem with promising results. By exploiting massively parallel GPU processing architectures and oodles of training data, they can run orders of magnitude faster than existing techniques. However, these methods are largely unprincipled black boxes that are difficult to train and often-times specific to a single measurement matrix. It was recently demonstrated that iterative sparse-signal-recovery algorithms can be "unrolled" to form interpretable deep networks. Taking inspiration from this work, we develop a novel neural network architecture that mimics the behavior of the denoising-based approximate message passing (D-AMP) algorithm. We call this new network Learned D-AMP (LDAMP). The LDAMP network is easy to train, can be applied to a variety of different measurement matrices, and comes with a state-evolution heuristic that accurately predicts its performance. Most importantly, it outperforms the state-of-the-art BM3D-AMP and NLR-CS algorithms in terms of both accuracy and run time. At high resolutions, and when used with sensing matrices that have fast implementations, LDAMP runs over $50\times$ faster than BM3D-AMP and hundreds of times faster than NLR-CS.
DeepCodec: Adaptive Sensing and Recovery via Deep Convolutional Neural Networks
Jul 11, 2017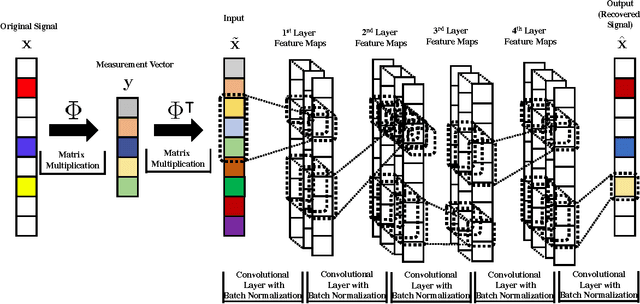
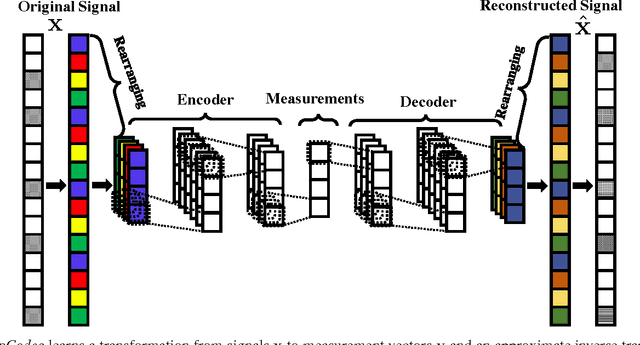
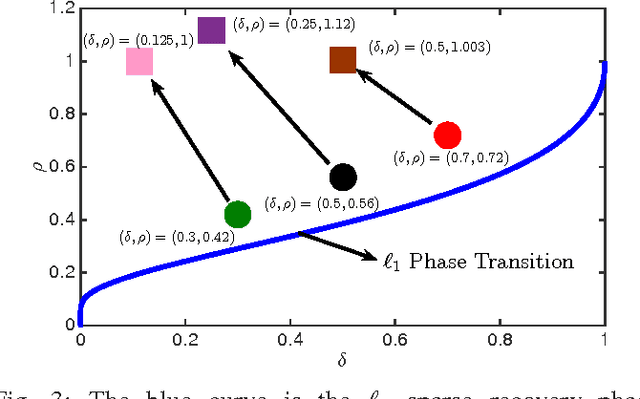
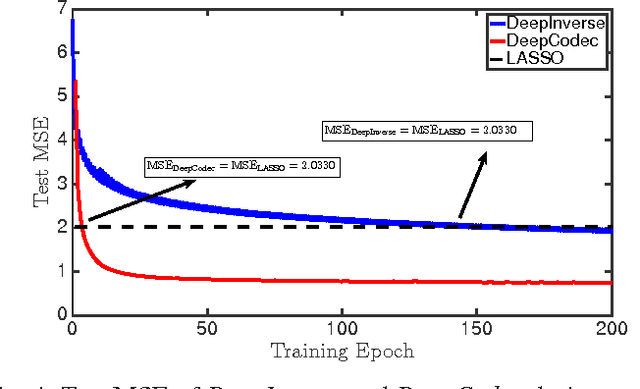
In this paper we develop a novel computational sensing framework for sensing and recovering structured signals. When trained on a set of representative signals, our framework learns to take undersampled measurements and recover signals from them using a deep convolutional neural network. In other words, it learns a transformation from the original signals to a near-optimal number of undersampled measurements and the inverse transformation from measurements to signals. This is in contrast to traditional compressive sensing (CS) systems that use random linear measurements and convex optimization or iterative algorithms for signal recovery. We compare our new framework with $\ell_1$-minimization from the phase transition point of view and demonstrate that it outperforms $\ell_1$-minimization in the regions of phase transition plot where $\ell_1$-minimization cannot recover the exact solution. In addition, we experimentally demonstrate how learning measurements enhances the overall recovery performance, speeds up training of recovery framework, and leads to having fewer parameters to learn.
Data-Mining Textual Responses to Uncover Misconception Patterns
Mar 30, 2017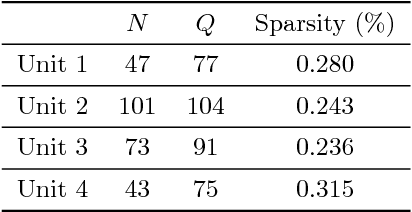


An important, yet largely unstudied, problem in student data analysis is to detect misconceptions from students' responses to open-response questions. Misconception detection enables instructors to deliver more targeted feedback on the misconceptions exhibited by many students in their class, thus improving the quality of instruction. In this paper, we propose a new natural language processing-based framework to detect the common misconceptions among students' textual responses to short-answer questions. We propose a probabilistic model for students' textual responses involving misconceptions and experimentally validate it on a real-world student-response dataset. Experimental results show that our proposed framework excels at classifying whether a response exhibits one or more misconceptions. More importantly, it can also automatically detect the common misconceptions exhibited across responses from multiple students to multiple questions; this property is especially important at large scale, since instructors will no longer need to manually specify all possible misconceptions that students might exhibit.
Learning to Invert: Signal Recovery via Deep Convolutional Networks
Jan 14, 2017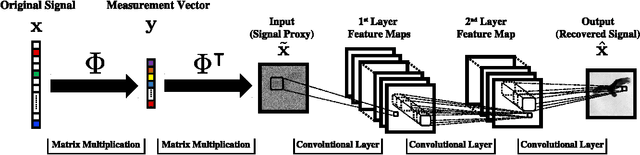
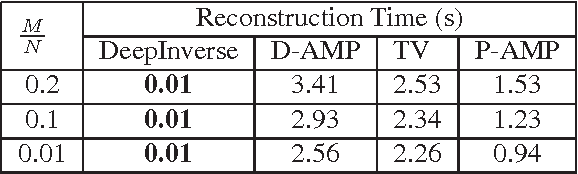
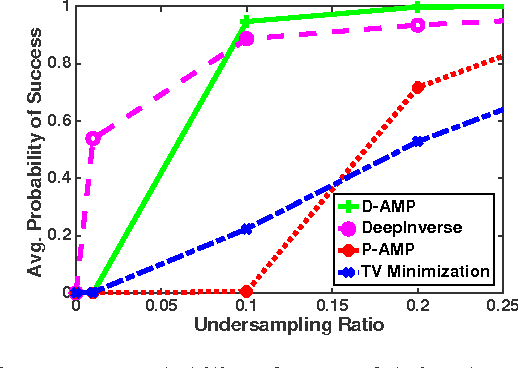

The promise of compressive sensing (CS) has been offset by two significant challenges. First, real-world data is not exactly sparse in a fixed basis. Second, current high-performance recovery algorithms are slow to converge, which limits CS to either non-real-time applications or scenarios where massive back-end computing is available. In this paper, we attack both of these challenges head-on by developing a new signal recovery framework we call {\em DeepInverse} that learns the inverse transformation from measurement vectors to signals using a {\em deep convolutional network}. When trained on a set of representative images, the network learns both a representation for the signals (addressing challenge one) and an inverse map approximating a greedy or convex recovery algorithm (addressing challenge two). Our experiments indicate that the DeepInverse network closely approximates the solution produced by state-of-the-art CS recovery algorithms yet is hundreds of times faster in run time. The tradeoff for the ultrafast run time is a computationally intensive, off-line training procedure typical to deep networks. However, the training needs to be completed only once, which makes the approach attractive for a host of sparse recovery problems.
Semi-Supervised Learning with the Deep Rendering Mixture Model
Dec 06, 2016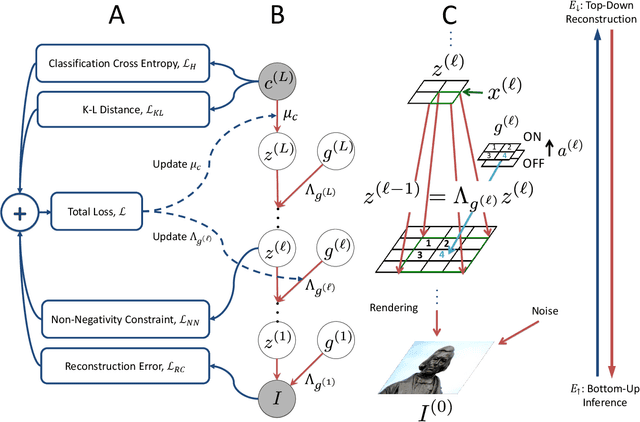
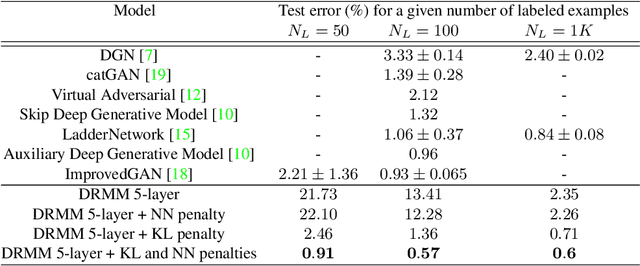
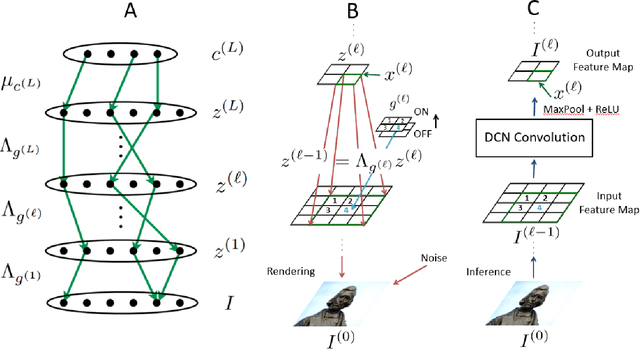

Semi-supervised learning algorithms reduce the high cost of acquiring labeled training data by using both labeled and unlabeled data during learning. Deep Convolutional Networks (DCNs) have achieved great success in supervised tasks and as such have been widely employed in the semi-supervised learning. In this paper we leverage the recently developed Deep Rendering Mixture Model (DRMM), a probabilistic generative model that models latent nuisance variation, and whose inference algorithm yields DCNs. We develop an EM algorithm for the DRMM to learn from both labeled and unlabeled data. Guided by the theory of the DRMM, we introduce a novel non-negativity constraint and a variational inference term. We report state-of-the-art performance on MNIST and SVHN and competitive results on CIFAR10. We also probe deeper into how a DRMM trained in a semi-supervised setting represents latent nuisance variation using synthetically rendered images. Taken together, our work provides a unified framework for supervised, unsupervised, and semi-supervised learning.
A Probabilistic Framework for Deep Learning
Dec 06, 2016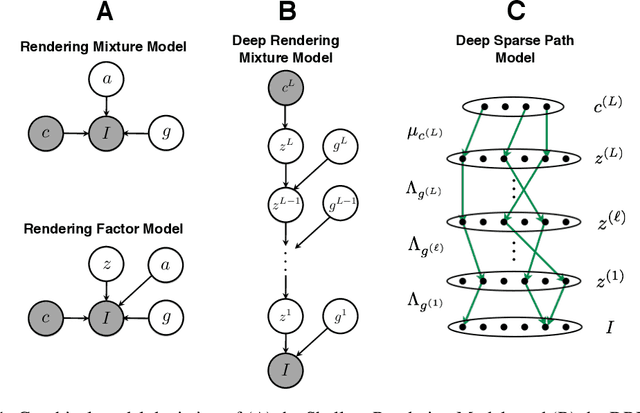
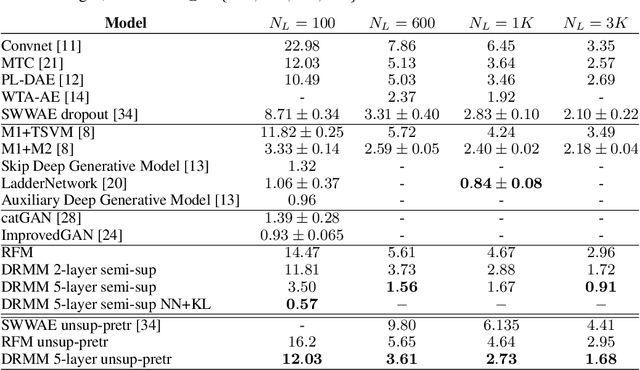
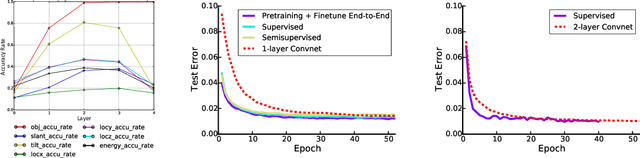
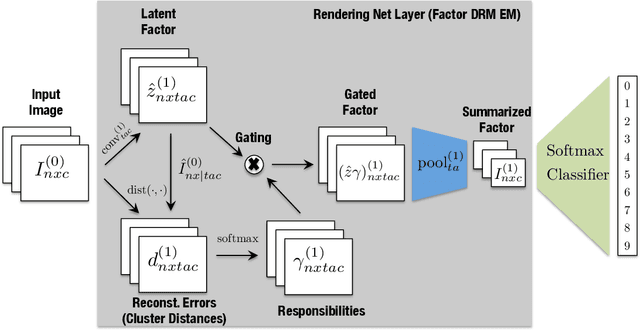
We develop a probabilistic framework for deep learning based on the Deep Rendering Mixture Model (DRMM), a new generative probabilistic model that explicitly capture variations in data due to latent task nuisance variables. We demonstrate that max-sum inference in the DRMM yields an algorithm that exactly reproduces the operations in deep convolutional neural networks (DCNs), providing a first principles derivation. Our framework provides new insights into the successes and shortcomings of DCNs as well as a principled route to their improvement. DRMM training via the Expectation-Maximization (EM) algorithm is a powerful alternative to DCN back-propagation, and initial training results are promising. Classification based on the DRMM and other variants outperforms DCNs in supervised digit classification, training 2-3x faster while achieving similar accuracy. Moreover, the DRMM is applicable to semi-supervised and unsupervised learning tasks, achieving results that are state-of-the-art in several categories on the MNIST benchmark and comparable to state of the art on the CIFAR10 benchmark.
RankMap: A Platform-Aware Framework for Distributed Learning from Dense Datasets
Oct 27, 2016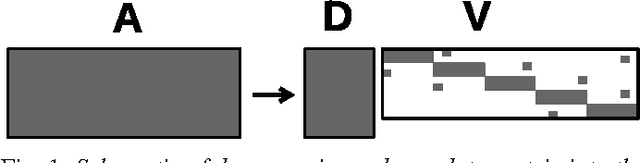
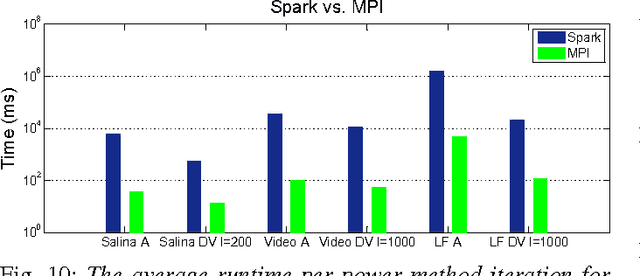
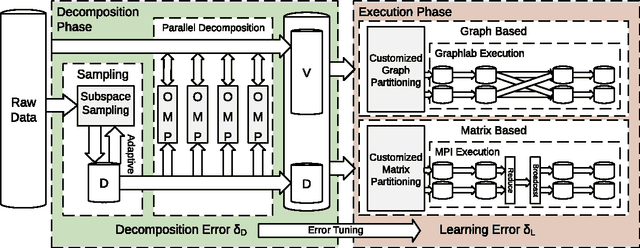
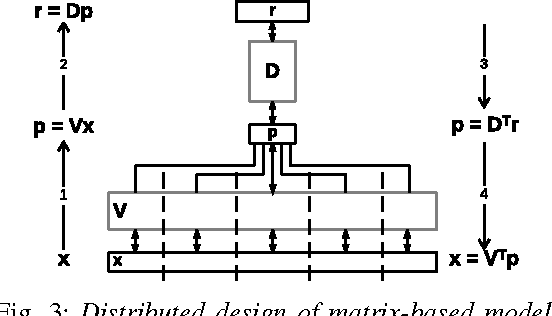
This paper introduces RankMap, a platform-aware end-to-end framework for efficient execution of a broad class of iterative learning algorithms for massive and dense datasets. Our framework exploits data structure to factorize it into an ensemble of lower rank subspaces. The factorization creates sparse low-dimensional representations of the data, a property which is leveraged to devise effective mapping and scheduling of iterative learning algorithms on the distributed computing machines. We provide two APIs, one matrix-based and one graph-based, which facilitate automated adoption of the framework for performing several contemporary learning applications. To demonstrate the utility of RankMap, we solve sparse recovery and power iteration problems on various real-world datasets with up to 1.8 billion non-zeros. Our evaluations are performed on Amazon EC2 and IBM iDataPlex servers using up to 244 cores. The results demonstrate up to two orders of magnitude improvements in memory usage, execution speed, and bandwidth compared with the best reported prior work, while achieving the same level of learning accuracy.
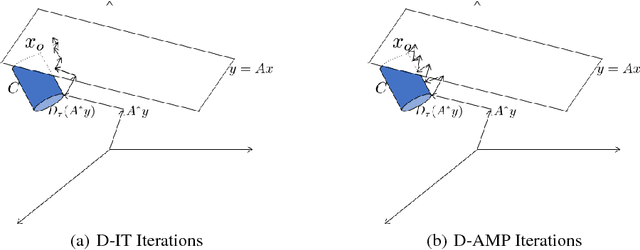
From Denoising to Compressed Sensing
Apr 17, 2016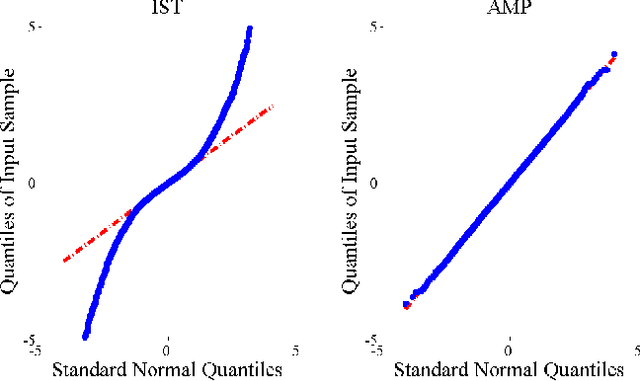
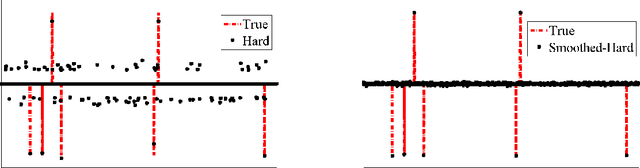
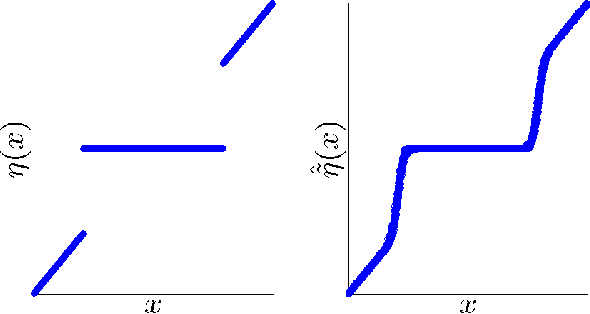
A denoising algorithm seeks to remove noise, errors, or perturbations from a signal. Extensive research has been devoted to this arena over the last several decades, and as a result, today's denoisers can effectively remove large amounts of additive white Gaussian noise. A compressed sensing (CS) reconstruction algorithm seeks to recover a structured signal acquired using a small number of randomized measurements. Typical CS reconstruction algorithms can be cast as iteratively estimating a signal from a perturbed observation. This paper answers a natural question: How can one effectively employ a generic denoiser in a CS reconstruction algorithm? In response, we develop an extension of the approximate message passing (AMP) framework, called Denoising-based AMP (D-AMP), that can integrate a wide class of denoisers within its iterations. We demonstrate that, when used with a high performance denoiser for natural images, D-AMP offers state-of-the-art CS recovery performance while operating tens of times faster than competing methods. We explain the exceptional performance of D-AMP by analyzing some of its theoretical features. A key element in D-AMP is the use of an appropriate Onsager correction term in its iterations, which coerces the signal perturbation at each iteration to be very close to the white Gaussian noise that denoisers are typically designed to remove.