 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvex Biclustering
Apr 15, 2016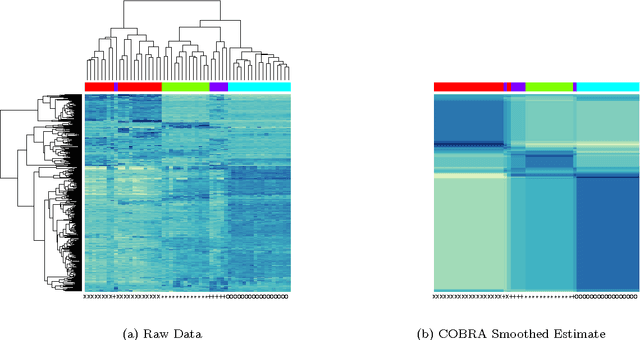
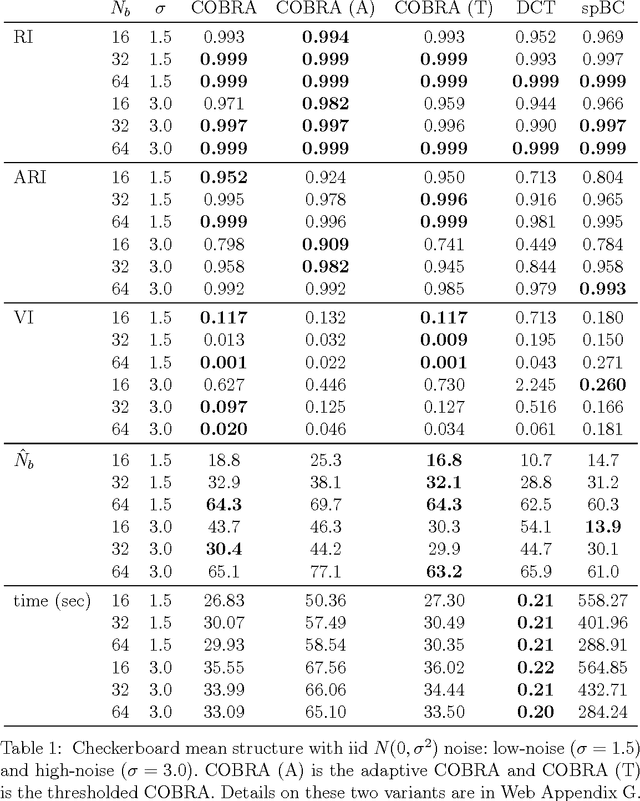
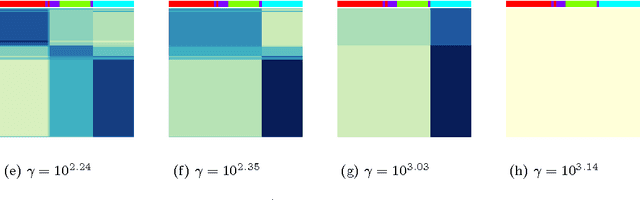
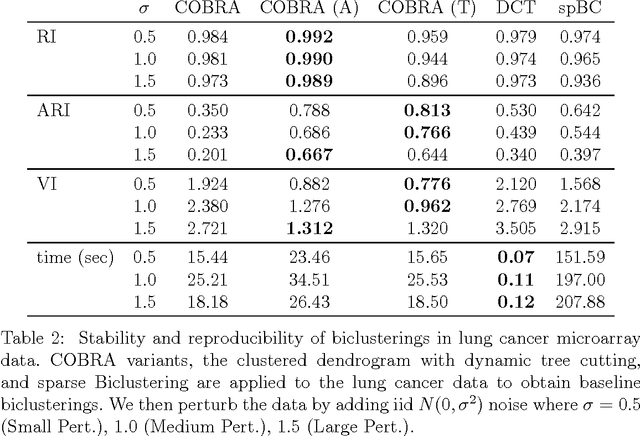
In the biclustering problem, we seek to simultaneously group observations and features. While biclustering has applications in a wide array of domains, ranging from text mining to collaborative filtering, the problem of identifying structure in high dimensional genomic data motivates this work. In this context, biclustering enables us to identify subsets of genes that are co-expressed only within a subset of experimental conditions. We present a convex formulation of the biclustering problem that possesses a unique global minimizer and an iterative algorithm, COBRA, that is guaranteed to identify it. Our approach generates an entire solution path of possible biclusters as a single tuning parameter is varied. We also show how to reduce the problem of selecting this tuning parameter to solving a trivial modification of the convex biclustering problem. The key contributions of our work are its simplicity, interpretability, and algorithmic guarantees - features that arguably are lacking in the current alternative algorithms. We demonstrate the advantages of our approach, which includes stably and reproducibly identifying biclusterings, on simulated and real microarray data.
* 29 pages, 3 figures
Consistent Parameter Estimation for LASSO and Approximate Message Passing
Nov 04, 2015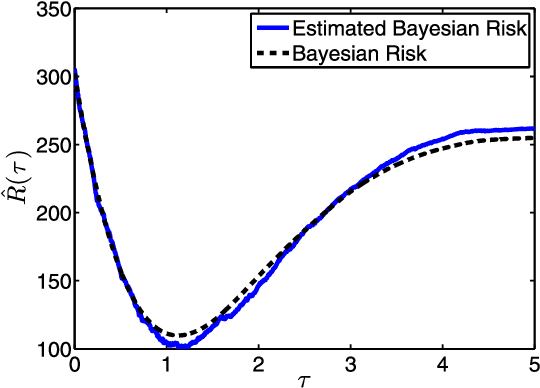
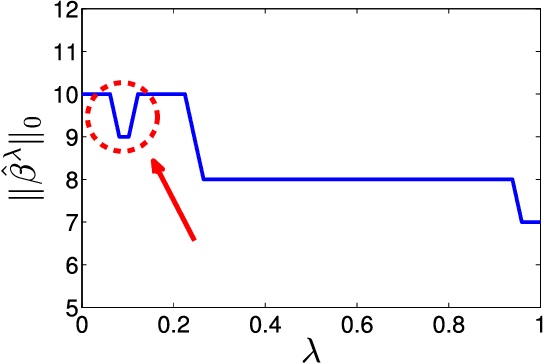
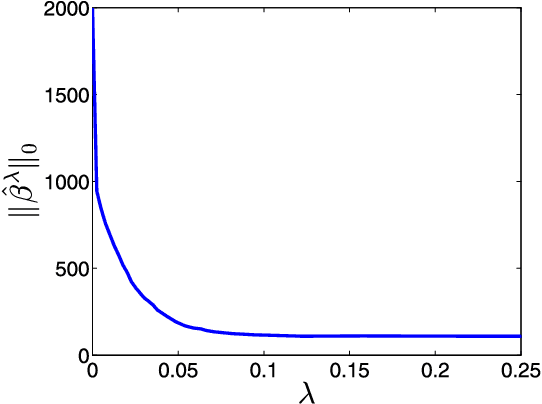
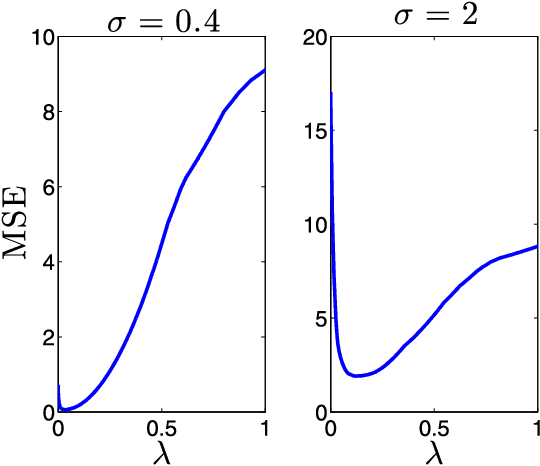
We consider the problem of recovering a vector $\beta_o \in \mathbb{R}^p$ from $n$ random and noisy linear observations $y= X\beta_o + w$, where $X$ is the measurement matrix and $w$ is noise. The LASSO estimate is given by the solution to the optimization problem $\hat{\beta}_{\lambda} = \arg \min_{\beta} \frac{1}{2} \|y-X\beta\|_2^2 + \lambda \| \beta \|_1$. Among the iterative algorithms that have been proposed for solving this optimization problem, approximate message passing (AMP) has attracted attention for its fast convergence. Despite significant progress in the theoretical analysis of the estimates of LASSO and AMP, little is known about their behavior as a function of the regularization parameter $\lambda$, or the thereshold parameters $\tau^t$. For instance the following basic questions have not yet been studied in the literature: (i) How does the size of the active set $\|\hat{\beta}^\lambda\|_0/p$ behave as a function of $\lambda$? (ii) How does the mean square error $\|\hat{\beta}_{\lambda} - \beta_o\|_2^2/p$ behave as a function of $\lambda$? (iii) How does $\|\beta^t - \beta_o \|_2^2/p$ behave as a function of $\tau^1, \ldots, \tau^{t-1}$? Answering these questions will help in addressing practical challenges regarding the optimal tuning of $\lambda$ or $\tau^1, \tau^2, \ldots$. This paper answers these questions in the asymptotic setting and shows how these results can be employed in deriving simple and theoretically optimal approaches for tuning the parameters $\tau^1, \ldots, \tau^t$ for AMP or $\lambda$ for LASSO. It also explores the connection between the optimal tuning of the parameters of AMP and the optimal tuning of LASSO.
A Deep Learning Approach to Structured Signal Recovery
Aug 17, 2015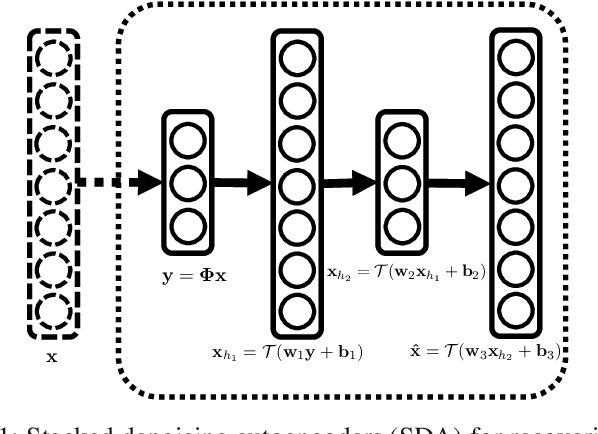
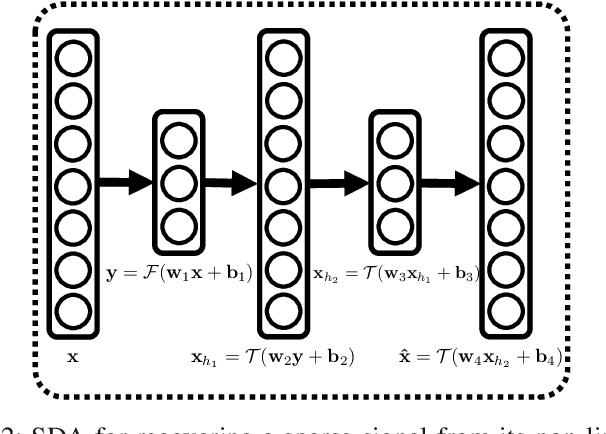

In this paper, we develop a new framework for sensing and recovering structured signals. In contrast to compressive sensing (CS) systems that employ linear measurements, sparse representations, and computationally complex convex/greedy algorithms, we introduce a deep learning framework that supports both linear and mildly nonlinear measurements, that learns a structured representation from training data, and that efficiently computes a signal estimate. In particular, we apply a stacked denoising autoencoder (SDA), as an unsupervised feature learner. SDA enables us to capture statistical dependencies between the different elements of certain signals and improve signal recovery performance as compared to the CS approach.
Video Compressive Sensing for Spatial Multiplexing Cameras using Motion-Flow Models
Aug 05, 2015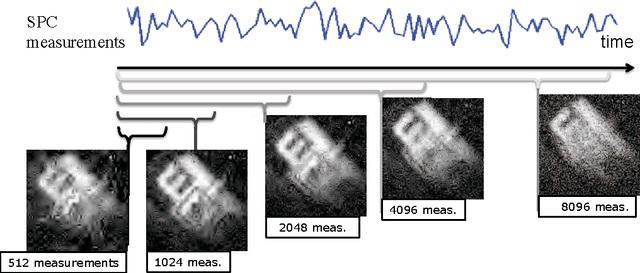
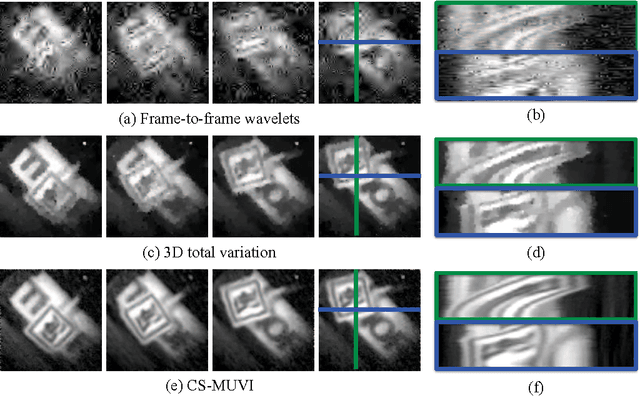
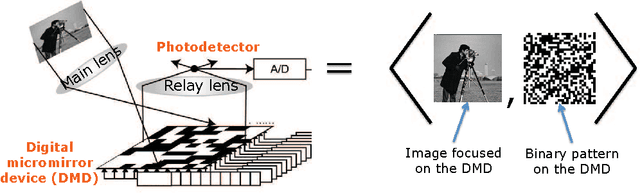
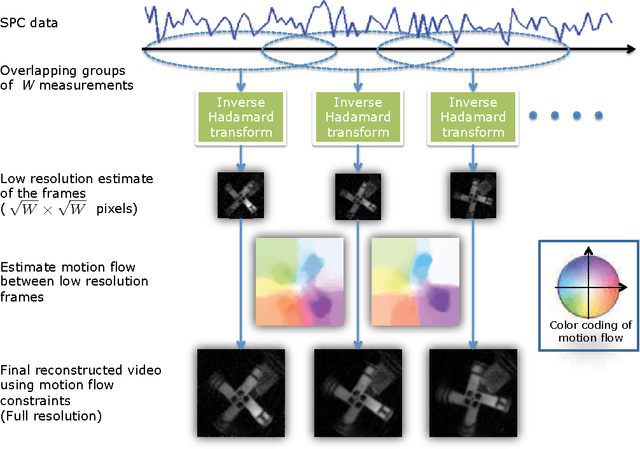
Spatial multiplexing cameras (SMCs) acquire a (typically static) scene through a series of coded projections using a spatial light modulator (e.g., a digital micro-mirror device) and a few optical sensors. This approach finds use in imaging applications where full-frame sensors are either too expensive (e.g., for short-wave infrared wavelengths) or unavailable. Existing SMC systems reconstruct static scenes using techniques from compressive sensing (CS). For videos, however, existing acquisition and recovery methods deliver poor quality. In this paper, we propose the CS multi-scale video (CS-MUVI) sensing and recovery framework for high-quality video acquisition and recovery using SMCs. Our framework features novel sensing matrices that enable the efficient computation of a low-resolution video preview, while enabling high-resolution video recovery using convex optimization. To further improve the quality of the reconstructed videos, we extract optical-flow estimates from the low-resolution previews and impose them as constraints in the recovery procedure. We demonstrate the efficacy of our CS-MUVI framework for a host of synthetic and real measured SMC video data, and we show that high-quality videos can be recovered at roughly $60\times$ compression.
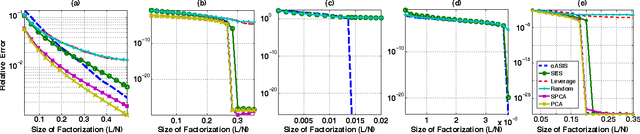
oASIS: Adaptive Column Sampling for Kernel Matrix Approximation
May 19, 2015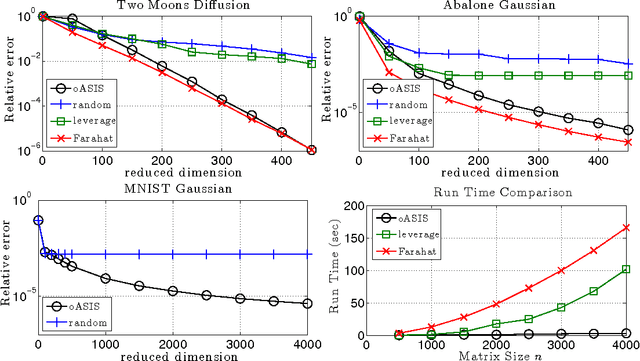

Kernel matrices (e.g. Gram or similarity matrices) are essential for many state-of-the-art approaches to classification, clustering, and dimensionality reduction. For large datasets, the cost of forming and factoring such kernel matrices becomes intractable. To address this challenge, we introduce a new adaptive sampling algorithm called Accelerated Sequential Incoherence Selection (oASIS) that samples columns without explicitly computing the entire kernel matrix. We provide conditions under which oASIS is guaranteed to exactly recover the kernel matrix with an optimal number of columns selected. Numerical experiments on both synthetic and real-world datasets demonstrate that oASIS achieves performance comparable to state-of-the-art adaptive sampling methods at a fraction of the computational cost. The low runtime complexity of oASIS and its low memory footprint enable the solution of large problems that are simply intractable using other adaptive methods.
Self-Expressive Decompositions for Matrix Approximation and Clustering
May 04, 2015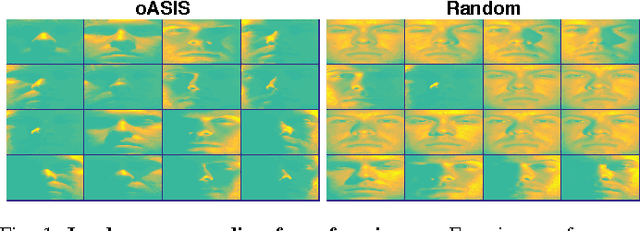
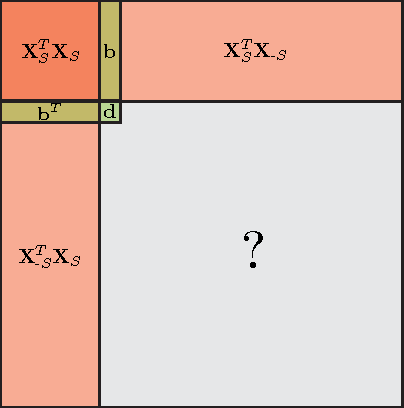
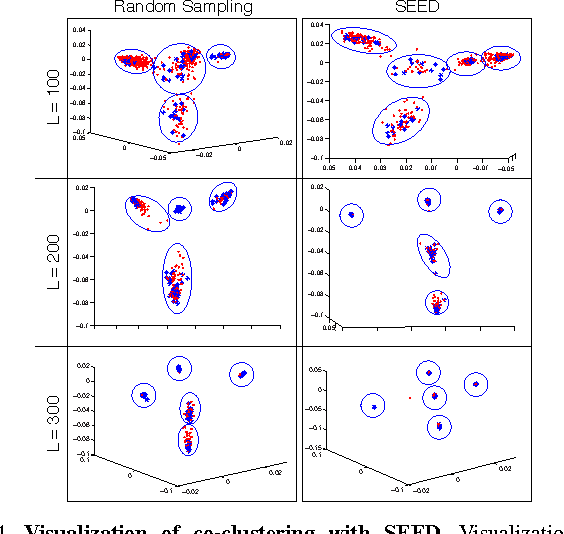
Data-aware methods for dimensionality reduction and matrix decomposition aim to find low-dimensional structure in a collection of data. Classical approaches discover such structure by learning a basis that can efficiently express the collection. Recently, "self expression", the idea of using a small subset of data vectors to represent the full collection, has been developed as an alternative to learning. Here, we introduce a scalable method for computing sparse SElf-Expressive Decompositions (SEED). SEED is a greedy method that constructs a basis by sequentially selecting incoherent vectors from the dataset. After forming a basis from a subset of vectors in the dataset, SEED then computes a sparse representation of the dataset with respect to this basis. We develop sufficient conditions under which SEED exactly represents low rank matrices and vectors sampled from a unions of independent subspaces. We show how SEED can be used in applications ranging from matrix approximation and denoising to clustering, and apply it to numerous real-world datasets. Our results demonstrate that SEED is an attractive low-complexity alternative to other sparse matrix factorization approaches such as sparse PCA and self-expressive methods for clustering.
A Probabilistic Theory of Deep Learning
Apr 02, 2015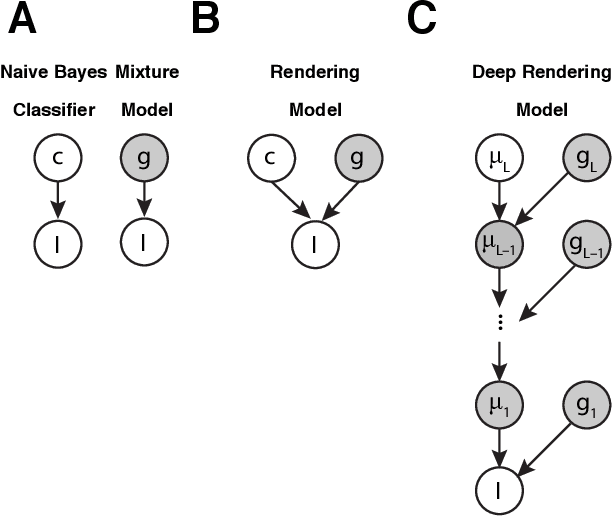
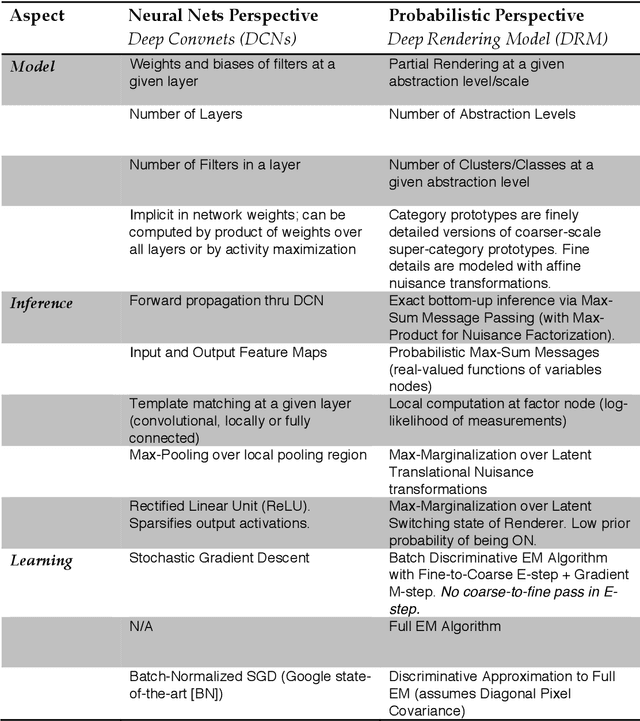
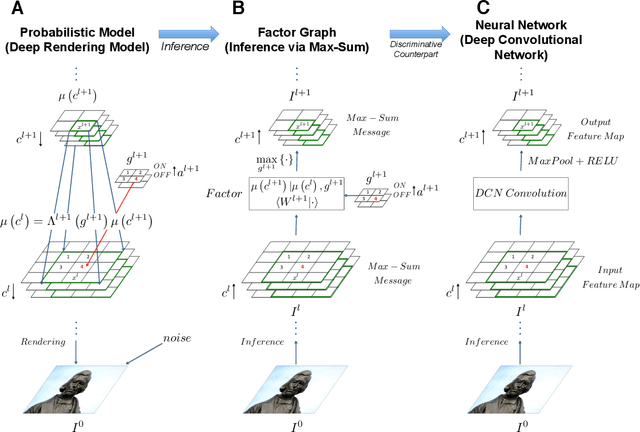
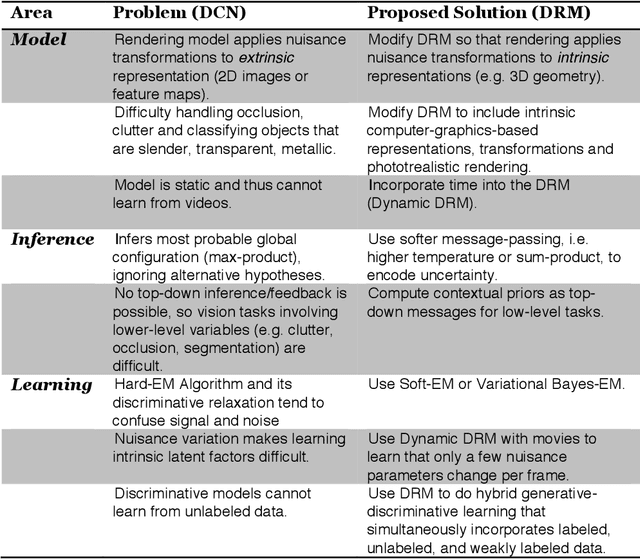
A grand challenge in machine learning is the development of computational algorithms that match or outperform humans in perceptual inference tasks that are complicated by nuisance variation. For instance, visual object recognition involves the unknown object position, orientation, and scale in object recognition while speech recognition involves the unknown voice pronunciation, pitch, and speed. Recently, a new breed of deep learning algorithms have emerged for high-nuisance inference tasks that routinely yield pattern recognition systems with near- or super-human capabilities. But a fundamental question remains: Why do they work? Intuitions abound, but a coherent framework for understanding, analyzing, and synthesizing deep learning architectures has remained elusive. We answer this question by developing a new probabilistic framework for deep learning based on the Deep Rendering Model: a generative probabilistic model that explicitly captures latent nuisance variation. By relaxing the generative model to a discriminative one, we can recover two of the current leading deep learning systems, deep convolutional neural networks and random decision forests, providing insights into their successes and shortcomings, as well as a principled route to their improvement.
Mathematical Language Processing: Automatic Grading and Feedback for Open Response Mathematical Questions
Jan 18, 2015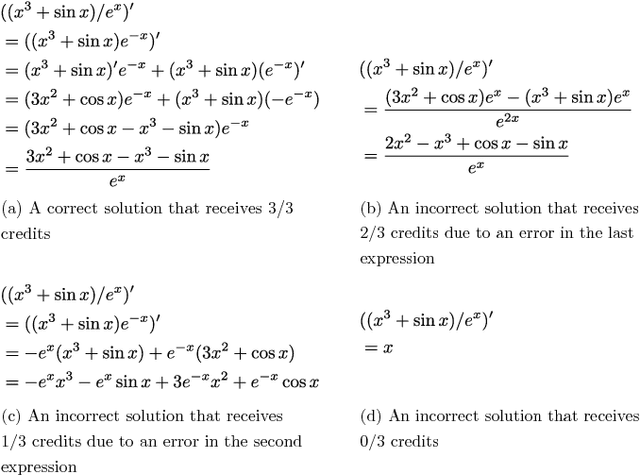

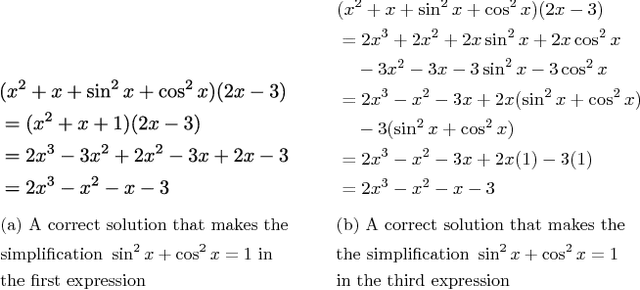
While computer and communication technologies have provided effective means to scale up many aspects of education, the submission and grading of assessments such as homework assignments and tests remains a weak link. In this paper, we study the problem of automatically grading the kinds of open response mathematical questions that figure prominently in STEM (science, technology, engineering, and mathematics) courses. Our data-driven framework for mathematical language processing (MLP) leverages solution data from a large number of learners to evaluate the correctness of their solutions, assign partial-credit scores, and provide feedback to each learner on the likely locations of any errors. MLP takes inspiration from the success of natural language processing for text data and comprises three main steps. First, we convert each solution to an open response mathematical question into a series of numerical features. Second, we cluster the features from several solutions to uncover the structures of correct, partially correct, and incorrect solutions. We develop two different clustering approaches, one that leverages generic clustering algorithms and one based on Bayesian nonparametrics. Third, we automatically grade the remaining (potentially large number of) solutions based on their assigned cluster and one instructor-provided grade per cluster. As a bonus, we can track the cluster assignment of each step of a multistep solution and determine when it departs from a cluster of correct solutions, which enables us to indicate the likely locations of errors to learners. We test and validate MLP on real-world MOOC data to demonstrate how it can substantially reduce the human effort required in large-scale educational platforms.
SPRITE: A Response Model For Multiple Choice Testing
Jan 12, 2015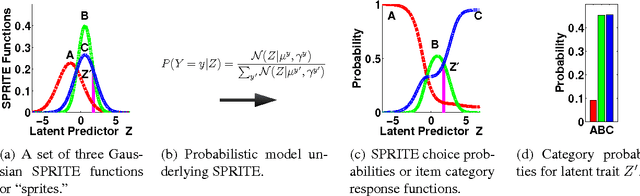
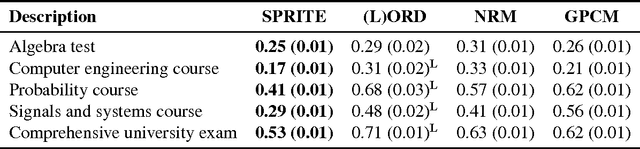
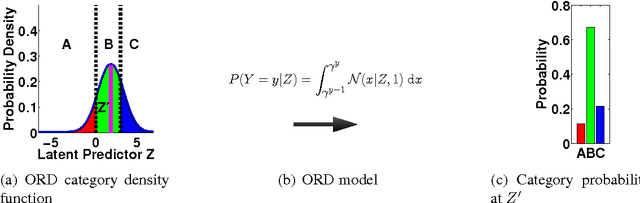
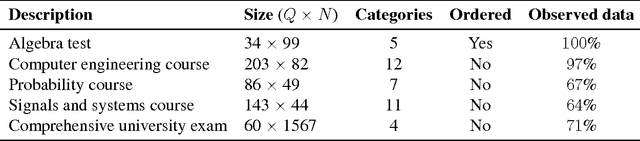
Item response theory (IRT) models for categorical response data are widely used in the analysis of educational data, computerized adaptive testing, and psychological surveys. However, most IRT models rely on both the assumption that categories are strictly ordered and the assumption that this ordering is known a priori. These assumptions are impractical in many real-world scenarios, such as multiple-choice exams where the levels of incorrectness for the distractor categories are often unknown. While a number of results exist on IRT models for unordered categorical data, they tend to have restrictive modeling assumptions that lead to poor data fitting performance in practice. Furthermore, existing unordered categorical models have parameters that are difficult to interpret. In this work, we propose a novel methodology for unordered categorical IRT that we call SPRITE (short for stochastic polytomous response item model) that: (i) analyzes both ordered and unordered categories, (ii) offers interpretable outputs, and (iii) provides improved data fitting compared to existing models. We compare SPRITE to existing item response models and demonstrate its efficacy on both synthetic and real-world educational datasets.
Quantized Matrix Completion for Personalized Learning
Dec 18, 2014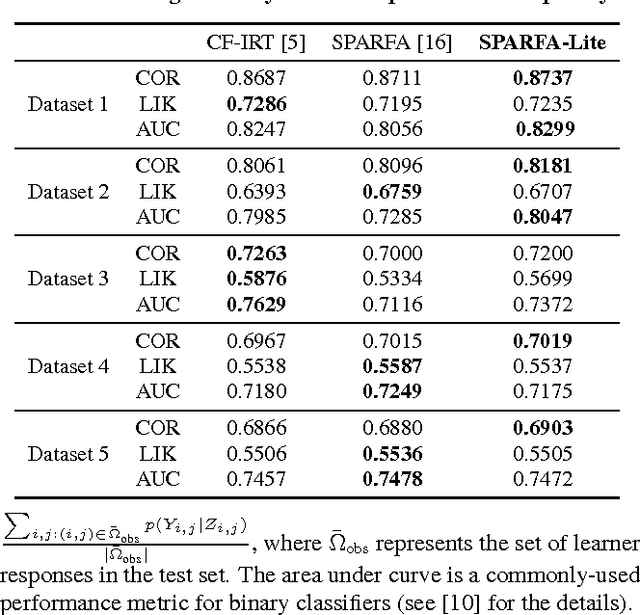

The recently proposed SPARse Factor Analysis (SPARFA) framework for personalized learning performs factor analysis on ordinal or binary-valued (e.g., correct/incorrect) graded learner responses to questions. The underlying factors are termed "concepts" (or knowledge components) and are used for learning analytics (LA), the estimation of learner concept-knowledge profiles, and for content analytics (CA), the estimation of question-concept associations and question difficulties. While SPARFA is a powerful tool for LA and CA, it requires a number of algorithm parameters (including the number of concepts), which are difficult to determine in practice. In this paper, we propose SPARFA-Lite, a convex optimization-based method for LA that builds on matrix completion, which only requires a single algorithm parameter and enables us to automatically identify the required number of concepts. Using a variety of educational datasets, we demonstrate that SPARFALite (i) achieves comparable performance in predicting unobserved learner responses to existing methods, including item response theory (IRT) and SPARFA, and (ii) is computationally more efficient.