 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated identification of Ichneumonoidea wasps via YOLO-based deep learning: Integrating HiresCam for Explainable AI
Mar 17, 2026Accurate taxonomic identification of parasitoid wasps within the superfamily Ichneumonoidea is essential for biodiversity assessment, ecological monitoring, and biological control programs. However, morphological similarity, small body size, and fine-grained interspecific variation make manual identification labor-intensive and expertise-dependent. This study proposes a deep learning-based framework for the automated identification of Ichneumonoidea wasps using a YOLO-based architecture integrated with High-Resolution Class Activation Mapping (HiResCAM) to enhance interpretability. The proposed system simultaneously identifies wasp families from high-resolution images. The dataset comprises 3556 high-resolution images of Hymenoptera specimens. The taxonomic distribution is primarily concentrated among the families Ichneumonidae (n = 786), Braconidae (n = 648), Apidae (n = 466), and Vespidae (n = 460). Extensive experiments were conducted using a curated dataset, with model performance evaluated through precision, recall, F1 score, and accuracy. The results demonstrate high accuracy of over 96 % and robust generalization across morphological variations. HiResCAM visualizations confirm that the model focuses on taxonomically relevant anatomical regions, such as wing venation, antennae segmentation, and metasomal structures, thereby validating the biological plausibility of the learned features. The integration of explainable AI techniques improves transparency and trustworthiness, making the system suitable for entomological research to accelerate biodiversity characterization in an under-described parasitoid superfamily.
Viewpoint-Agnostic Grasp Pipeline using VLM and Partial Observations
Mar 09, 2026Robust grasping in cluttered, unstructured environments remains challenging for mobile legged manipulators due to occlusions that lead to partial observations, unreliable depth estimates, and the need for collision-free, execution-feasible approaches. In this paper we present an end-to-end pipeline for language-guided grasping that bridges open-vocabulary target selection to safe grasp execution on a real robot. Given a natural-language command, the system grounds the target in RGB using open-vocabulary detection and promptable instance segmentation, extracts an object-centric point cloud from RGB-D, and improves geometric reliability under occlusion via back-projected depth compensation and two-stage point cloud completion. We then generate and collision-filter 6-DoF grasp candidates and select an executable grasp using safety-oriented heuristics that account for reachability, approach feasibility, and clearance. We evaluate the method on a quadruped robot with an arm in two cluttered tabletop scenarios, using paired trials against a view-dependent baseline. The proposed approach achieves a 90% overall success rate (9/10) against 30% (3/10) for the baseline, demonstrating substantially improved robustness to occlusions and partial observations in clutter.
Evaluating Zero-Shot and One-Shot Adaptation of Small Language Models in Leader-Follower Interaction
Feb 26, 2026Leader-follower interaction is an important paradigm in human-robot interaction (HRI). Yet, assigning roles in real time remains challenging for resource-constrained mobile and assistive robots. While large language models (LLMs) have shown promise for natural communication, their size and latency limit on-device deployment. Small language models (SLMs) offer a potential alternative, but their effectiveness for role classification in HRI has not been systematically evaluated. In this paper, we present a benchmark of SLMs for leader-follower communication, introducing a novel dataset derived from a published database and augmented with synthetic samples to capture interaction-specific dynamics. We investigate two adaptation strategies: prompt engineering and fine-tuning, studied under zero-shot and one-shot interaction modes, compared with an untrained baseline. Experiments with Qwen2.5-0.5B reveal that zero-shot fine-tuning achieves robust classification performance (86.66% accuracy) while maintaining low latency (22.2 ms per sample), significantly outperforming baseline and prompt-engineered approaches. However, results also indicate a performance degradation in one-shot modes, where increased context length challenges the model's architectural capacity. These findings demonstrate that fine-tuned SLMs provide an effective solution for direct role assignment, while highlighting critical trade-offs between dialogue complexity and classification reliability on the edge.
Optimizing Grasping in Legged Robots: A Deep Learning Approach to Loco-Manipulation
Aug 24, 2025



Quadruped robots have emerged as highly efficient and versatile platforms, excelling in navigating complex and unstructured terrains where traditional wheeled robots might fail. Equipping these robots with manipulator arms unlocks the advanced capability of loco-manipulation to perform complex physical interaction tasks in areas ranging from industrial automation to search-and-rescue missions. However, achieving precise and adaptable grasping in such dynamic scenarios remains a significant challenge, often hindered by the need for extensive real-world calibration and pre-programmed grasp configurations. This paper introduces a deep learning framework designed to enhance the grasping capabilities of quadrupeds equipped with arms, focusing on improved precision and adaptability. Our approach centers on a sim-to-real methodology that minimizes reliance on physical data collection. We developed a pipeline within the Genesis simulation environment to generate a synthetic dataset of grasp attempts on common objects. By simulating thousands of interactions from various perspectives, we created pixel-wise annotated grasp-quality maps to serve as the ground truth for our model. This dataset was used to train a custom CNN with a U-Net-like architecture that processes multi-modal input from an onboard RGB and depth cameras, including RGB images, depth maps, segmentation masks, and surface normal maps. The trained model outputs a grasp-quality heatmap to identify the optimal grasp point. We validated the complete framework on a four-legged robot. The system successfully executed a full loco-manipulation task: autonomously navigating to a target object, perceiving it with its sensors, predicting the optimal grasp pose using our model, and performing a precise grasp. This work proves that leveraging simulated training with advanced sensing offers a scalable and effective solution for object handling.
A Synthetic Dataset for Manometry Recognition in Robotic Applications
Aug 24, 2025This work addresses the challenges of data scarcity and high acquisition costs for training robust object detection models in complex industrial environments, such as offshore oil platforms. The practical and economic barriers to collecting real-world data in these hazardous settings often hamper the development of autonomous inspection systems. To overcome this, in this work we propose and validate a hybrid data synthesis pipeline that combines procedural rendering with AI-driven video generation. Our methodology leverages BlenderProc to create photorealistic images with precise annotations and controlled domain randomization, and integrates NVIDIA's Cosmos-Predict2 world-foundation model to synthesize physically plausible video sequences with temporal diversity, capturing rare viewpoints and adverse conditions. We demonstrate that a YOLO-based detection network trained on a composite dataset, blending real images with our synthetic data, achieves superior performance compared to models trained exclusively on real-world data. Notably, a 1:1 mixture of real and synthetic data yielded the highest accuracy, surpassing the real-only baseline. These findings highlight the viability of a synthetic-first approach as an efficient, cost-effective, and safe alternative for developing reliable perception systems in safety-critical and resource-constrained industrial applications.
A Vision-Based Shared-Control Teleoperation Scheme for Controlling the Robotic Arm of a Four-Legged Robot
Aug 20, 2025In hazardous and remote environments, robotic systems perform critical tasks demanding improved safety and efficiency. Among these, quadruped robots with manipulator arms offer mobility and versatility for complex operations. However, teleoperating quadruped robots is challenging due to the lack of integrated obstacle detection and intuitive control methods for the robotic arm, increasing collision risks in confined or dynamically changing workspaces. Teleoperation via joysticks or pads can be non-intuitive and demands a high level of expertise due to its complexity, culminating in a high cognitive load on the operator. To address this challenge, a teleoperation approach that directly maps human arm movements to the robotic manipulator offers a simpler and more accessible solution. This work proposes an intuitive remote control by leveraging a vision-based pose estimation pipeline that utilizes an external camera with a machine learning-based model to detect the operator's wrist position. The system maps these wrist movements into robotic arm commands to control the robot's arm in real-time. A trajectory planner ensures safe teleoperation by detecting and preventing collisions with both obstacles and the robotic arm itself. The system was validated on the real robot, demonstrating robust performance in real-time control. This teleoperation approach provides a cost-effective solution for industrial applications where safety, precision, and ease of use are paramount, ensuring reliable and intuitive robotic control in high-risk environments.
Improving Failure Prediction in Aircraft Fastener Assembly Using Synthetic Data in Imbalanced Datasets
May 06, 2025



Automating aircraft manufacturing still relies heavily on human labor due to the complexity of the assembly processes and customization requirements. One key challenge is achieving precise positioning, especially for large aircraft structures, where errors can lead to substantial maintenance costs or part rejection. Existing solutions often require costly hardware or lack flexibility. Used in aircraft by the thousands, threaded fasteners, e.g., screws, bolts, and collars, are traditionally executed by fixed-base robots and usually have problems in being deployed in the mentioned manufacturing sites. This paper emphasizes the importance of error detection and classification for efficient and safe assembly of threaded fasteners, especially aeronautical collars. Safe assembly of threaded fasteners is paramount since acquiring sufficient data for training deep learning models poses challenges due to the rarity of failure cases and imbalanced datasets. The paper addresses this by proposing techniques like class weighting and data augmentation, specifically tailored for temporal series data, to improve classification performance. Furthermore, the paper introduces a novel problem-modeling approach, emphasizing metrics relevant to collar assembly rather than solely focusing on accuracy. This tailored approach enhances the models' capability to handle the challenges of threaded fastener assembly effectively.
MIHRaGe: A Mixed-Reality Interface for Human-Robot Interaction via Gaze-Oriented Control
May 06, 2025



Individuals with upper limb mobility impairments often require assistive technologies to perform activities of daily living. While gaze-tracking has emerged as a promising method for robotic assistance, existing solutions lack sufficient feedback mechanisms, leading to uncertainty in user intent recognition and reduced adaptability. This paper presents the MIHRAGe interface, an integrated system that combines gaze-tracking, robotic assistance, and a mixed-reality to create an immersive environment for controlling the robot using only eye movements. The system was evaluated through an experimental protocol involving four participants, assessing gaze accuracy, robotic positioning precision, and the overall success of a pick and place task. Results showed an average gaze fixation error of 1.46 cm, with individual variations ranging from 1.28 cm to 2.14 cm. The robotic arm demonstrated an average positioning error of +-1.53 cm, with discrepancies attributed to interface resolution and calibration constraints. In a pick and place task, the system achieved a success rate of 80%, highlighting its potential for improving accessibility in human-robot interaction with visual feedback to the user.
EEG-Based Epileptic Seizure Prediction Using Temporal Multi-Channel Transformers
Sep 18, 2022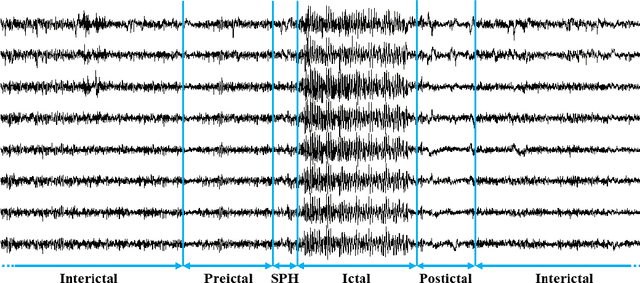

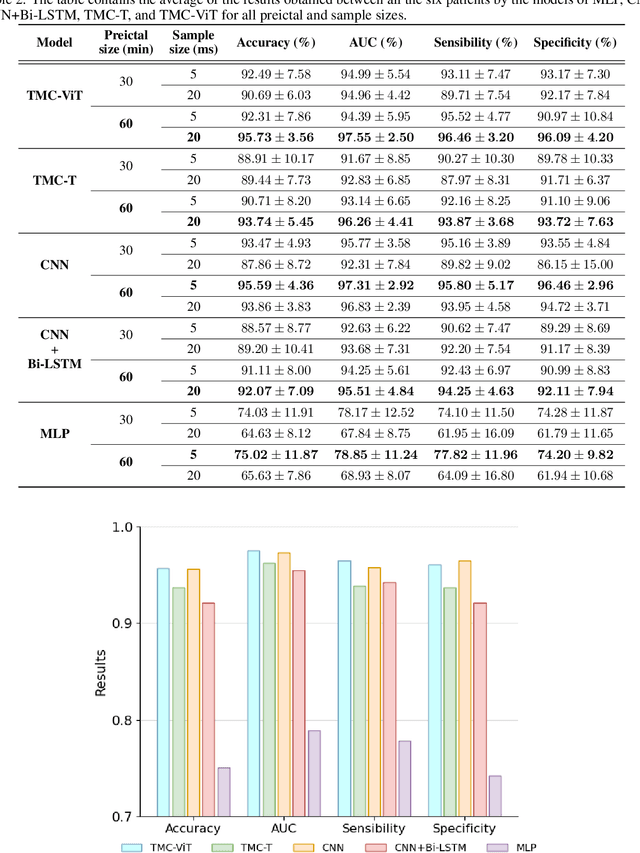

Epilepsy is one of the most common neurological diseases, characterized by transient and unprovoked events called epileptic seizures. Electroencephalogram (EEG) is an auxiliary method used to perform both the diagnosis and the monitoring of epilepsy. Given the unexpected nature of an epileptic seizure, its prediction would improve patient care, optimizing the quality of life and the treatment of epilepsy. Predicting an epileptic seizure implies the identification of two distinct states of EEG in a patient with epilepsy: the preictal and the interictal. In this paper, we developed two deep learning models called Temporal Multi-Channel Transformer (TMC-T) and Vision Transformer (TMC-ViT), adaptations of Transformer-based architectures for multi-channel temporal signals. Moreover, we accessed the impact of choosing different preictal duration, since its length is not a consensus among experts, and also evaluated how the sample size benefits each model. Our models are compared with fully connected, convolutional, and recurrent networks. The algorithms were patient-specific trained and evaluated on raw EEG signals from the CHB-MIT database. Experimental results and statistical validation demonstrated that our TMC-ViT model surpassed the CNN architecture, state-of-the-art in seizure prediction.