 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialoKG: Knowledge-Structure Aware Task-Oriented Dialogue Generation
Apr 19, 2022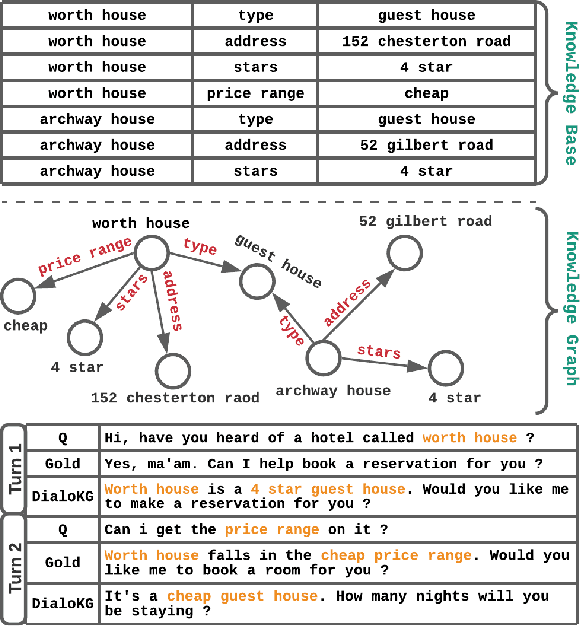

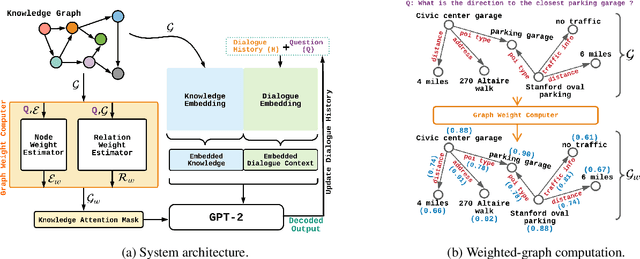
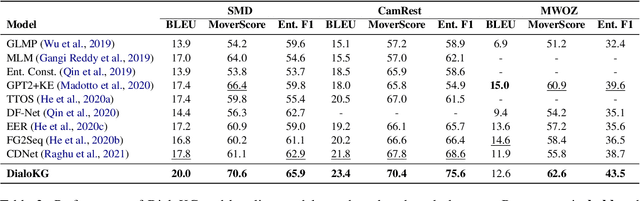
Task-oriented dialogue generation is challenging since the underlying knowledge is often dynamic and effectively incorporating knowledge into the learning process is hard. It is particularly challenging to generate both human-like and informative responses in this setting. Recent research primarily focused on various knowledge distillation methods where the underlying relationship between the facts in a knowledge base is not effectively captured. In this paper, we go one step further and demonstrate how the structural information of a knowledge graph can improve the system's inference capabilities. Specifically, we propose DialoKG, a novel task-oriented dialogue system that effectively incorporates knowledge into a language model. Our proposed system views relational knowledge as a knowledge graph and introduces (1) a structure-aware knowledge embedding technique, and (2) a knowledge graph-weighted attention masking strategy to facilitate the system selecting relevant information during the dialogue generation. An empirical evaluation demonstrates the effectiveness of DialoKG over state-of-the-art methods on several standard benchmark datasets.
RoMe: A Robust Metric for Evaluating Natural Language Generation
Mar 17, 2022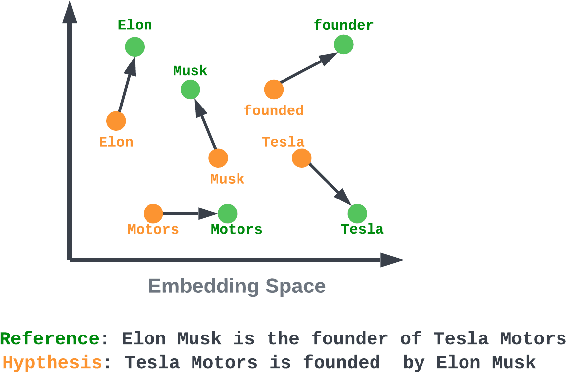
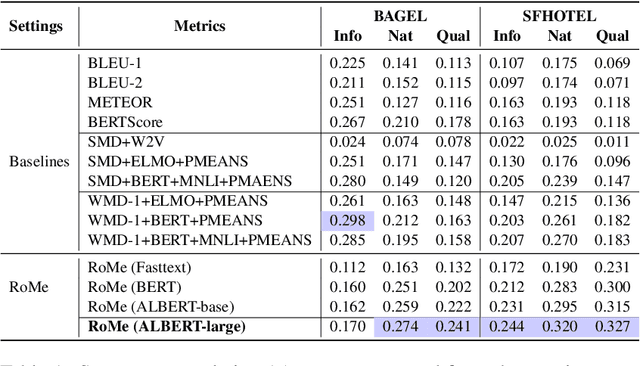
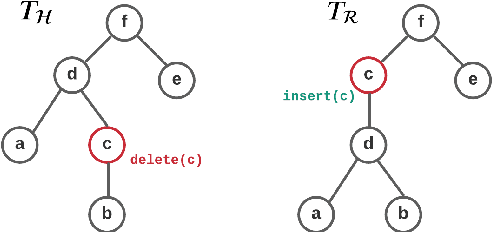

Evaluating Natural Language Generation (NLG) systems is a challenging task. Firstly, the metric should ensure that the generated hypothesis reflects the reference's semantics. Secondly, it should consider the grammatical quality of the generated sentence. Thirdly, it should be robust enough to handle various surface forms of the generated sentence. Thus, an effective evaluation metric has to be multifaceted. In this paper, we propose an automatic evaluation metric incorporating several core aspects of natural language understanding (language competence, syntactic and semantic variation). Our proposed metric, RoMe, is trained on language features such as semantic similarity combined with tree edit distance and grammatical acceptability, using a self-supervised neural network to assess the overall quality of the generated sentence. Moreover, we perform an extensive robustness analysis of the state-of-the-art methods and RoMe. Empirical results suggest that RoMe has a stronger correlation to human judgment over state-of-the-art metrics in evaluating system-generated sentences across several NLG tasks.
QALD-9-plus: A Multilingual Dataset for Question Answering over DBpedia and Wikidata Translated by Native Speakers
Feb 07, 2022
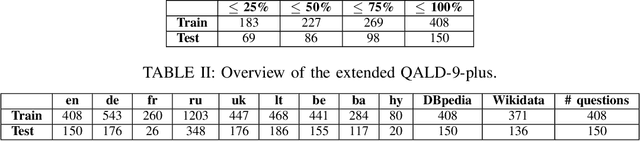

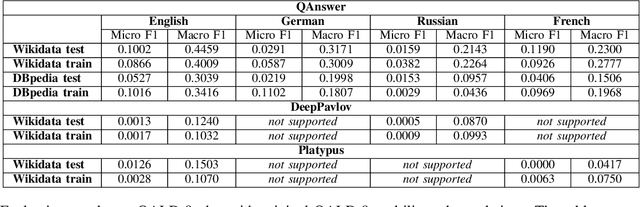
The ability to have the same experience for different user groups (i.e., accessibility) is one of the most important characteristics of Web-based systems. The same is true for Knowledge Graph Question Answering (KGQA) systems that provide the access to Semantic Web data via natural language interface. While following our research agenda on the multilingual aspect of accessibility of KGQA systems, we identified several ongoing challenges. One of them is the lack of multilingual KGQA benchmarks. In this work, we extend one of the most popular KGQA benchmarks - QALD-9 by introducing high-quality questions' translations to 8 languages provided by native speakers, and transferring the SPARQL queries of QALD-9 from DBpedia to Wikidata, s.t., the usability and relevance of the dataset is strongly increased. Five of the languages - Armenian, Ukrainian, Lithuanian, Bashkir and Belarusian - to our best knowledge were never considered in KGQA research community before. The latter two of the languages are considered as "endangered" by UNESCO. We call the extended dataset QALD-9-plus and made it available online https://github.com/Perevalov/qald_9_plus.
Knowledge Graph Question Answering Leaderboard: A Community Resource to Prevent a Replication Crisis
Jan 20, 2022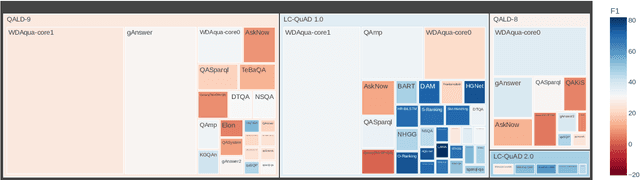
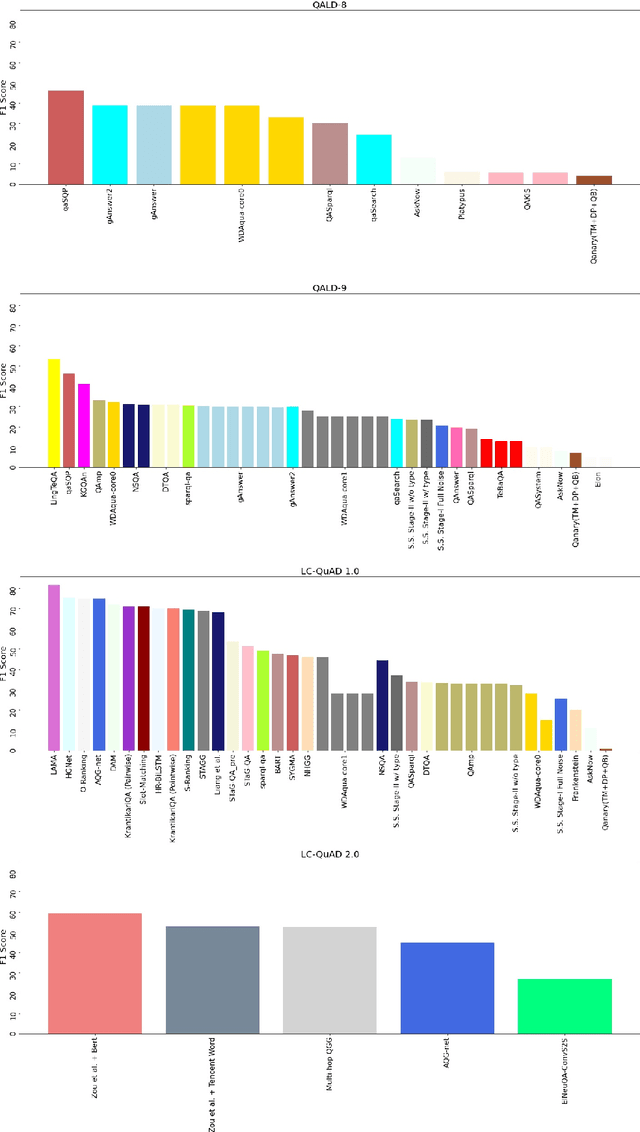
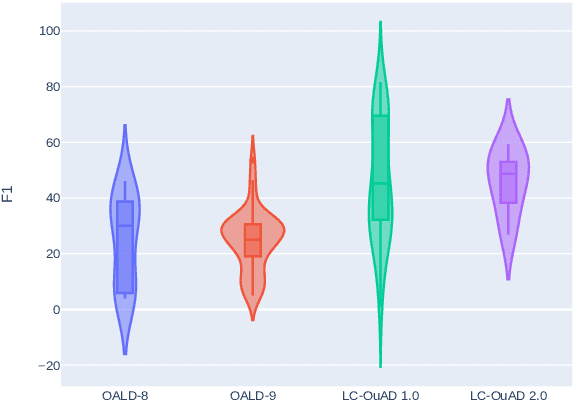
Data-driven systems need to be evaluated to establish trust in the scientific approach and its applicability. In particular, this is true for Knowledge Graph (KG) Question Answering (QA), where complex data structures are made accessible via natural-language interfaces. Evaluating the capabilities of these systems has been a driver for the community for more than ten years while establishing different KGQA benchmark datasets. However, comparing different approaches is cumbersome. The lack of existing and curated leaderboards leads to a missing global view over the research field and could inject mistrust into the results. In particular, the latest and most-used datasets in the KGQA community, LC-QuAD and QALD, miss providing central and up-to-date points of trust. In this paper, we survey and analyze a wide range of evaluation results with significant coverage of 100 publications and 98 systems from the last decade. We provide a new central and open leaderboard for any KGQA benchmark dataset as a focal point for the community - https://kgqa.github.io/leaderboard. Our analysis highlights existing problems during the evaluation of KGQA systems. Thus, we will point to possible improvements for future evaluations.
Semantic Answer Type and Relation Prediction Task (SMART 2021)
Jan 10, 2022
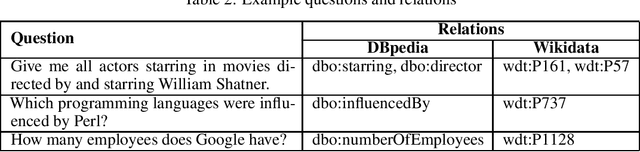
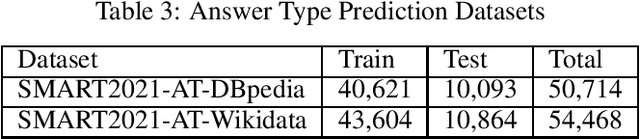
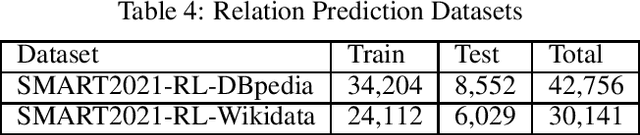
Each year the International Semantic Web Conference organizes a set of Semantic Web Challenges to establish competitions that will advance state-of-the-art solutions in some problem domains. The Semantic Answer Type and Relation Prediction Task (SMART) task is one of the ISWC 2021 Semantic Web challenges. This is the second year of the challenge after a successful SMART 2020 at ISWC 2020. This year's version focuses on two sub-tasks that are very important to Knowledge Base Question Answering (KBQA): Answer Type Prediction and Relation Prediction. Question type and answer type prediction can play a key role in knowledge base question answering systems providing insights about the expected answer that are helpful to generate correct queries or rank the answer candidates. More concretely, given a question in natural language, the first task is, to predict the answer type using a target ontology (e.g., DBpedia or Wikidata. Similarly, the second task is to identify relations in the natural language query and link them to the relations in a target ontology. This paper discusses the task descriptions, benchmark datasets, and evaluation metrics. For more information, please visit https://smart-task.github.io/2021/.
Survey on English Entity Linking on Wikidata
Dec 03, 2021

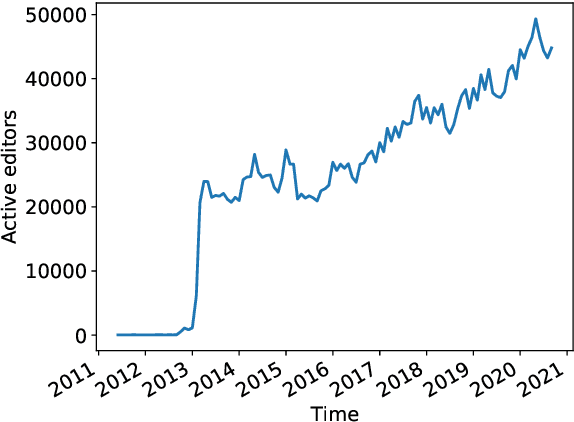
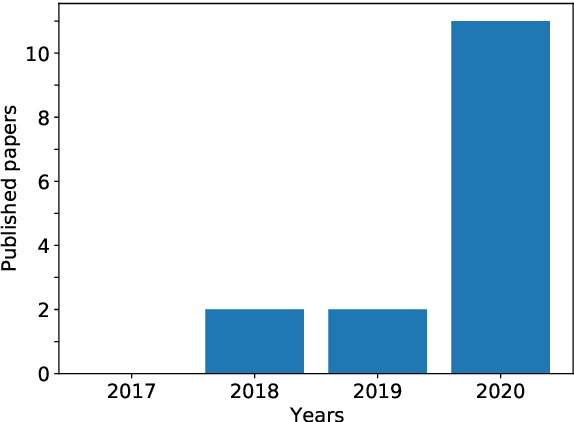
Wikidata is a frequently updated, community-driven, and multilingual knowledge graph. Hence, Wikidata is an attractive basis for Entity Linking, which is evident by the recent increase in published papers. This survey focuses on four subjects: (1) Which Wikidata Entity Linking datasets exist, how widely used are they and how are they constructed? (2) Do the characteristics of Wikidata matter for the design of Entity Linking datasets and if so, how? (3) How do current Entity Linking approaches exploit the specific characteristics of Wikidata? (4) Which Wikidata characteristics are unexploited by existing Entity Linking approaches? This survey reveals that current Wikidata-specific Entity Linking datasets do not differ in their annotation scheme from schemes for other knowledge graphs like DBpedia. Thus, the potential for multilingual and time-dependent datasets, naturally suited for Wikidata, is not lifted. Furthermore, we show that most Entity Linking approaches use Wikidata in the same way as any other knowledge graph missing the chance to leverage Wikidata-specific characteristics to increase quality. Almost all approaches employ specific properties like labels and sometimes descriptions but ignore characteristics such as the hyper-relational structure. Hence, there is still room for improvement, for example, by including hyper-relational graph embeddings or type information. Many approaches also include information from Wikipedia, which is easily combinable with Wikidata and provides valuable textual information, which Wikidata lacks.
Knowledge Graph Question Answering using Graph-Pattern Isomorphism
Mar 11, 2021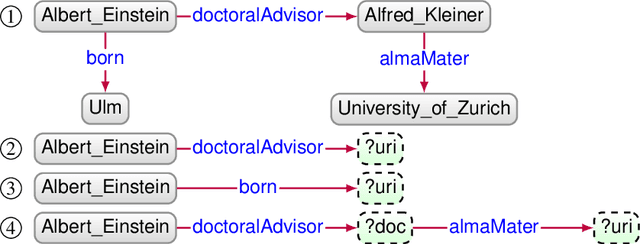

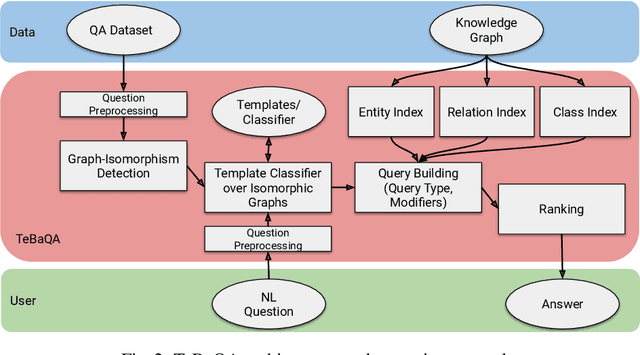

Knowledge Graph Question Answering (KGQA) systems are based on machine learning algorithms, requiring thousands of question-answer pairs as training examples or natural language processing pipelines that need module fine-tuning. In this paper, we present a novel QA approach, dubbed TeBaQA. Our approach learns to answer questions based on graph isomorphisms from basic graph patterns of SPARQL queries. Learning basic graph patterns is efficient due to the small number of possible patterns. This novel paradigm reduces the amount of training data necessary to achieve state-of-the-art performance. TeBaQA also speeds up the domain adaption process by transforming the QA system development task into a much smaller and easier data compilation task. In our evaluation, TeBaQA achieves state-of-the-art performance on QALD-8 and delivers comparable results on QALD-9 and LC-QuAD v1. Additionally, we performed a fine-grained evaluation on complex queries that deal with aggregation and superlative questions as well as an ablation study, highlighting future research challenges.
SeMantic AnsweR Type prediction task at ISWC 2020 Semantic Web Challenge
Dec 01, 2020

Each year the International Semantic Web Conference accepts a set of Semantic Web Challenges to establish competitions that will advance the state of the art solutions in any given problem domain. The SeMantic AnsweR Type prediction task (SMART) was part of ISWC 2020 challenges. Question type and answer type prediction can play a key role in knowledge base question answering systems providing insights that are helpful to generate correct queries or rank the answer candidates. More concretely, given a question in natural language, the task of SMART challenge is, to predict the answer type using a target ontology (e.g., DBpedia or Wikidata).
Message Passing for Hyper-Relational Knowledge Graphs
Sep 22, 2020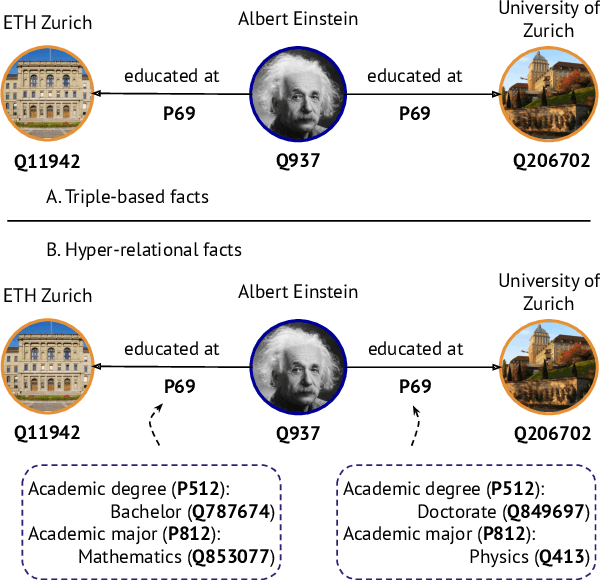
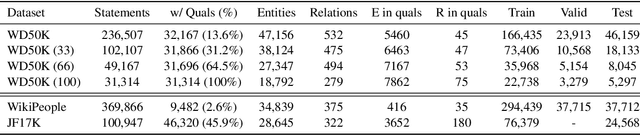
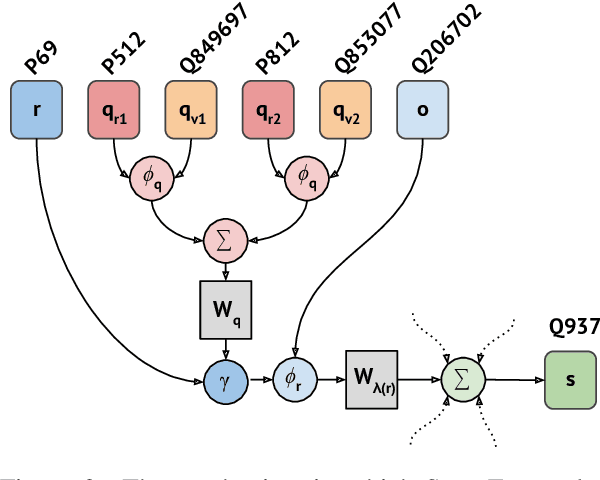
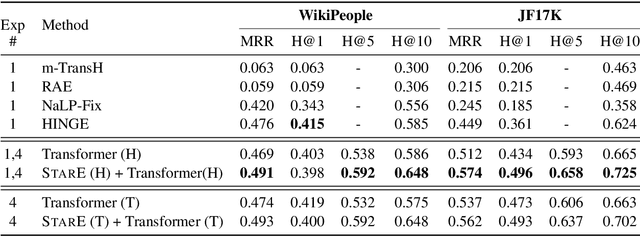
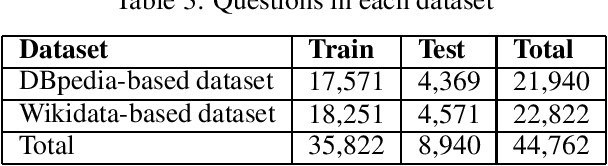
Hyper-relational knowledge graphs (KGs) (e.g., Wikidata) enable associating additional key-value pairs along with the main triple to disambiguate, or restrict the validity of a fact. In this work, we propose a message passing based graph encoder - StarE capable of modeling such hyper-relational KGs. Unlike existing approaches, StarE can encode an arbitrary number of additional information (qualifiers) along with the main triple while keeping the semantic roles of qualifiers and triples intact. We also demonstrate that existing benchmarks for evaluating link prediction (LP) performance on hyper-relational KGs suffer from fundamental flaws and thus develop a new Wikidata-based dataset - WD50K. Our experiments demonstrate that StarE based LP model outperforms existing approaches across multiple benchmarks. We also confirm that leveraging qualifiers is vital for link prediction with gains up to 25 MRR points compared to triple-based representations.
Towards an Interoperable Ecosystem of AI and LT Platforms: A Roadmap for the Implementation of Different Levels of Interoperability
Apr 17, 2020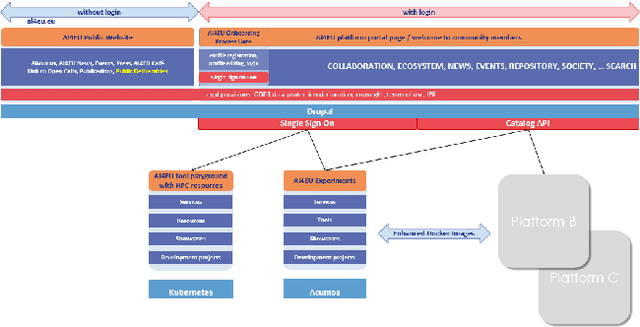
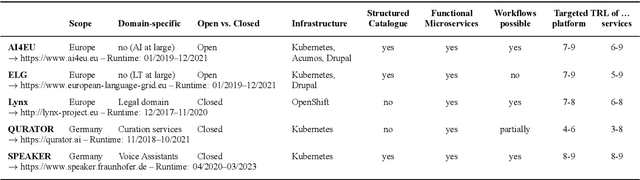
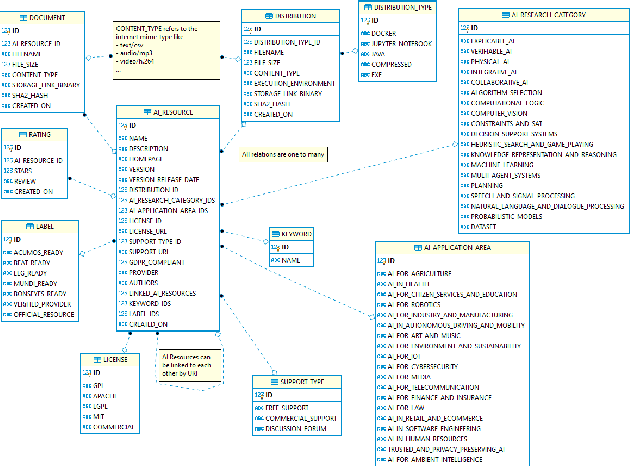

With regard to the wider area of AI/LT platform interoperability, we concentrate on two core aspects: (1) cross-platform search and discovery of resources and services; (2) composition of cross-platform service workflows. We devise five different levels (of increasing complexity) of platform interoperability that we suggest to implement in a wider federation of AI/LT platforms. We illustrate the approach using the five emerging AI/LT platforms AI4EU, ELG, Lynx, QURATOR and SPEAKER.