 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLOLA -- An Open-Source Massively Multilingual Large Language Model
Sep 19, 2024



This paper presents LOLA, a massively multilingual large language model trained on more than 160 languages using a sparse Mixture-of-Experts Transformer architecture. Our architectural and implementation choices address the challenge of harnessing linguistic diversity while maintaining efficiency and avoiding the common pitfalls of multilinguality. Our analysis of the evaluation results shows competitive performance in natural language generation and understanding tasks. Additionally, we demonstrate how the learned expert-routing mechanism exploits implicit phylogenetic linguistic patterns to potentially alleviate the curse of multilinguality. We provide an in-depth look at the training process, an analysis of the datasets, and a balanced exploration of the model's strengths and limitations. As an open-source model, LOLA promotes reproducibility and serves as a robust foundation for future research. Our findings enable the development of compute-efficient multilingual models with strong, scalable performance across languages.
MST5 -- Multilingual Question Answering over Knowledge Graphs
Jul 08, 2024



Knowledge Graph Question Answering (KGQA) simplifies querying vast amounts of knowledge stored in a graph-based model using natural language. However, the research has largely concentrated on English, putting non-English speakers at a disadvantage. Meanwhile, existing multilingual KGQA systems face challenges in achieving performance comparable to English systems, highlighting the difficulty of generating SPARQL queries from diverse languages. In this research, we propose a simplified approach to enhance multilingual KGQA systems by incorporating linguistic context and entity information directly into the processing pipeline of a language model. Unlike existing methods that rely on separate encoders for integrating auxiliary information, our strategy leverages a single, pretrained multilingual transformer-based language model to manage both the primary input and the auxiliary data. Our methodology significantly improves the language model's ability to accurately convert a natural language query into a relevant SPARQL query. It demonstrates promising results on the most recent QALD datasets, namely QALD-9-Plus and QALD-10. Furthermore, we introduce and evaluate our approach on Chinese and Japanese, thereby expanding the language diversity of the existing datasets.
Convolutional Hypercomplex Embeddings for Link Prediction
Jun 29, 2021
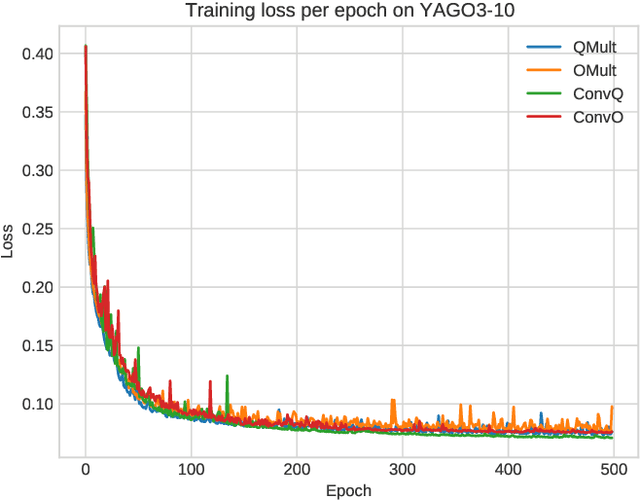
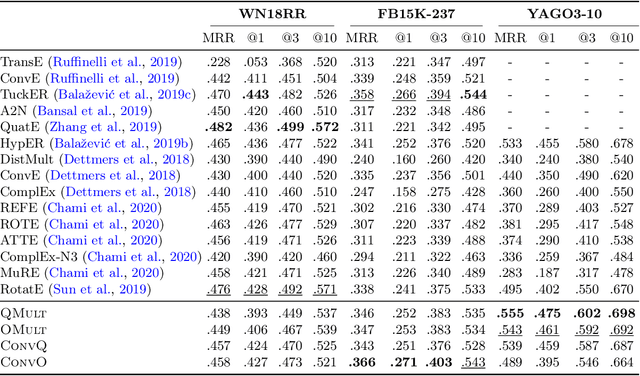
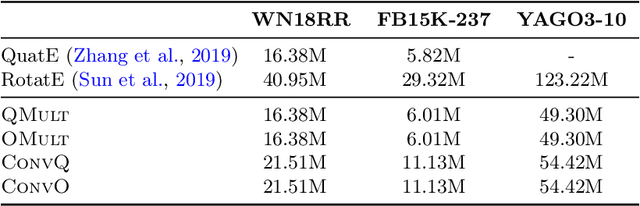
Knowledge graph embedding research has mainly focused on the two smallest normed division algebras, $\mathbb{R}$ and $\mathbb{C}$. Recent results suggest that trilinear products of quaternion-valued embeddings can be a more effective means to tackle link prediction. In addition, models based on convolutions on real-valued embeddings often yield state-of-the-art results for link prediction. In this paper, we investigate a composition of convolution operations with hypercomplex multiplications. We propose the four approaches QMult, OMult, ConvQ and ConvO to tackle the link prediction problem. QMult and OMult can be considered as quaternion and octonion extensions of previous state-of-the-art approaches, including DistMult and ComplEx. ConvQ and ConvO build upon QMult and OMult by including convolution operations in a way inspired by the residual learning framework. We evaluated our approaches on seven link prediction datasets including WN18RR, FB15K-237 and YAGO3-10. Experimental results suggest that the benefits of learning hypercomplex-valued vector representations become more apparent as the size and complexity of the knowledge graph grows. ConvO outperforms state-of-the-art approaches on FB15K-237 in MRR, Hit@1 and Hit@3, while QMult, OMult, ConvQ and ConvO outperform state-of-the-approaches on YAGO3-10 in all metrics. Results also suggest that link prediction performances can be further improved via prediction averaging. To foster reproducible research, we provide an open-source implementation of approaches, including training and evaluation scripts as well as pretrained models.
Knowledge Graph Question Answering using Graph-Pattern Isomorphism
Mar 11, 2021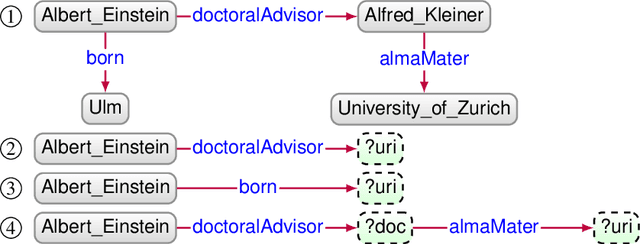

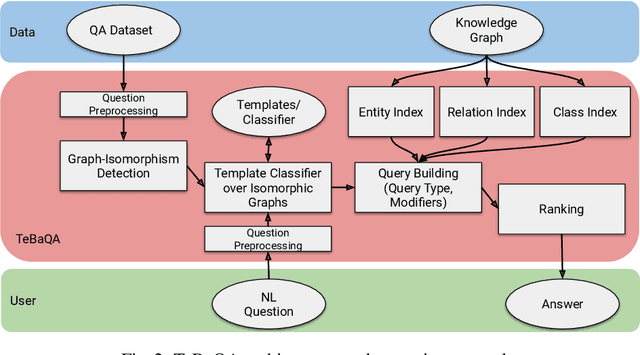

Knowledge Graph Question Answering (KGQA) systems are based on machine learning algorithms, requiring thousands of question-answer pairs as training examples or natural language processing pipelines that need module fine-tuning. In this paper, we present a novel QA approach, dubbed TeBaQA. Our approach learns to answer questions based on graph isomorphisms from basic graph patterns of SPARQL queries. Learning basic graph patterns is efficient due to the small number of possible patterns. This novel paradigm reduces the amount of training data necessary to achieve state-of-the-art performance. TeBaQA also speeds up the domain adaption process by transforming the QA system development task into a much smaller and easier data compilation task. In our evaluation, TeBaQA achieves state-of-the-art performance on QALD-8 and delivers comparable results on QALD-9 and LC-QuAD v1. Additionally, we performed a fine-grained evaluation on complex queries that deal with aggregation and superlative questions as well as an ablation study, highlighting future research challenges.
A shallow neural model for relation prediction
Jan 22, 2021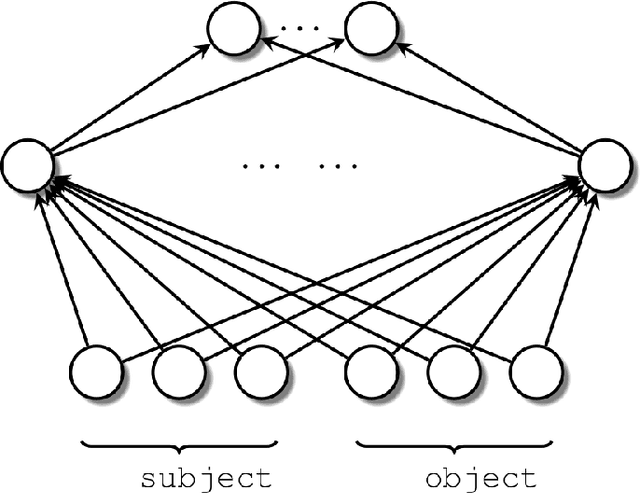
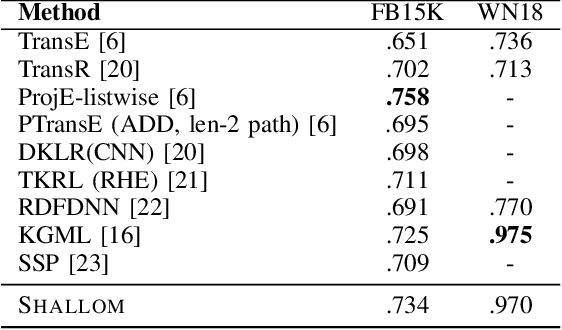
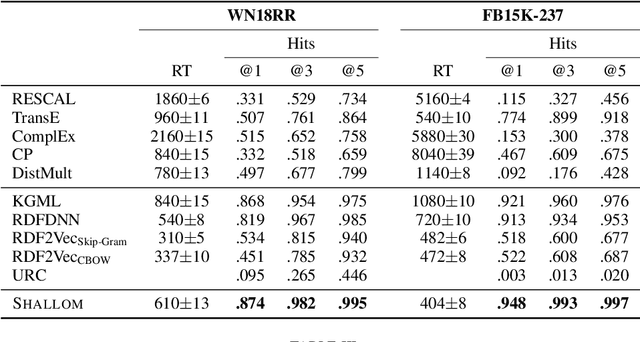

Knowledge graph completion refers to predicting missing triples. Most approaches achieve this goal by predicting entities, given an entity and a relation. We predict missing triples via the relation prediction. To this end, we frame the relation prediction problem as a multi-label classification problem and propose a shallow neural model (SHALLOM) that accurately infers missing relations from entities. SHALLOM is analogous to C-BOW as both approaches predict a central token (p) given surrounding tokens ((s,o)). Our experiments indicate that SHALLOM outperforms state-of-the-art approaches on the FB15K-237 and WN18RR with margins of up to $3\%$ and $8\%$ (absolute), respectively, while requiring a maximum training time of 8 minutes on these datasets. We ensure the reproducibility of our results by providing an open-source implementation including training and evaluation scripts at {\url{https://github.com/dice-group/Shallom}.}
NABU $\mathrm{-}$ Multilingual Graph-based Neural RDF Verbalizer
Sep 21, 2020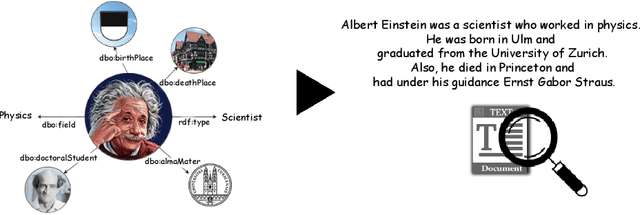
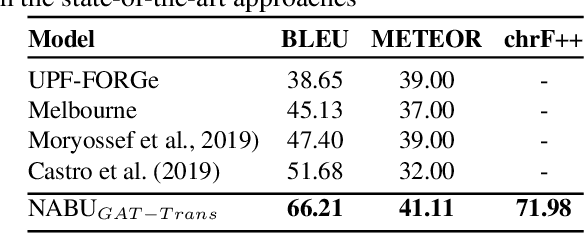
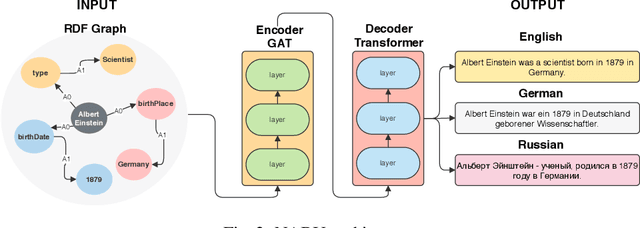
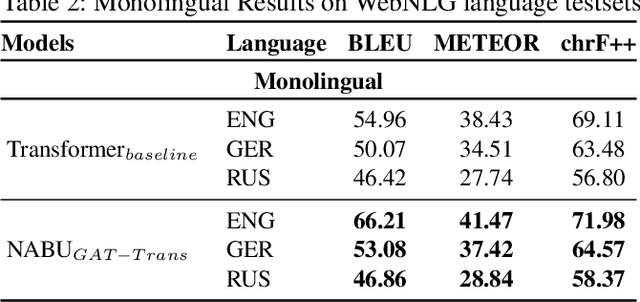
The RDF-to-text task has recently gained substantial attention due to continuous growth of Linked Data. In contrast to traditional pipeline models, recent studies have focused on neural models, which are now able to convert a set of RDF triples into text in an end-to-end style with promising results. However, English is the only language widely targeted. We address this research gap by presenting NABU, a multilingual graph-based neural model that verbalizes RDF data to German, Russian, and English. NABU is based on an encoder-decoder architecture, uses an encoder inspired by Graph Attention Networks and a Transformer as decoder. Our approach relies on the fact that knowledge graphs are language-agnostic and they hence can be used to generate multilingual text. We evaluate NABU in monolingual and multilingual settings on standard benchmarking WebNLG datasets. Our results show that NABU outperforms state-of-the-art approaches on English with 66.21 BLEU, and achieves consistent results across all languages on the multilingual scenario with 56.04 BLEU.
Knowledge Graphs for Multilingual Language Translation and Generation
Sep 16, 2020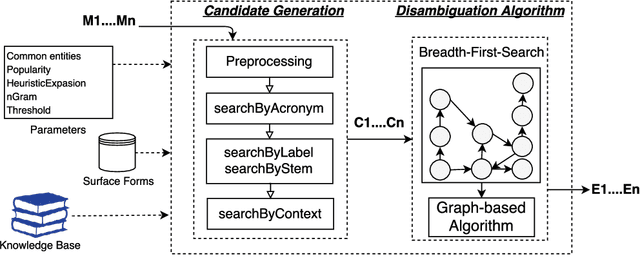
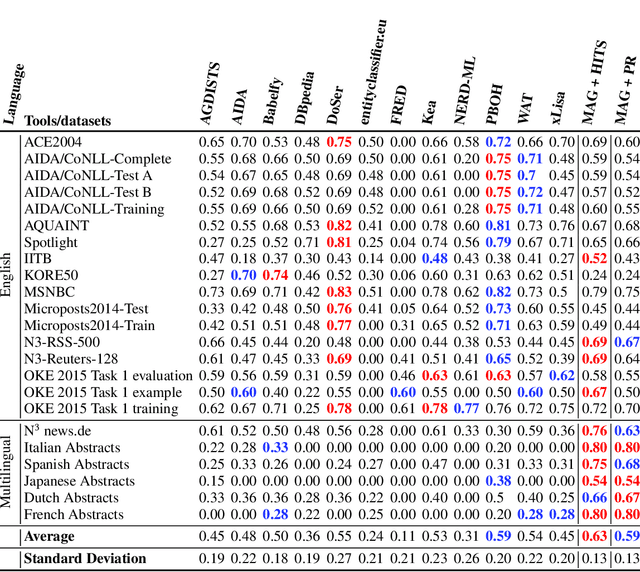
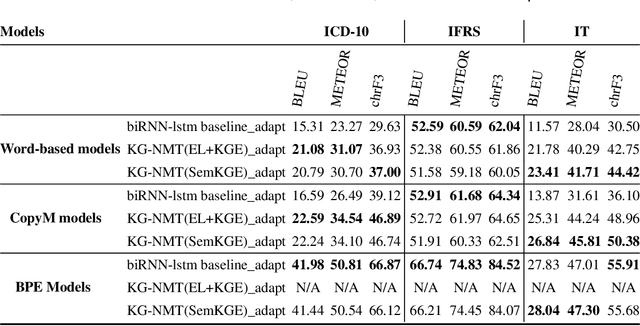
The Natural Language Processing (NLP) community has recently seen outstanding progress, catalysed by the release of different Neural Network (NN) architectures. Neural-based approaches have proven effective by significantly increasing the output quality of a large number of automated solutions for NLP tasks (Belinkov and Glass, 2019). Despite these notable advancements, dealing with entities still poses a difficult challenge as they are rarely seen in training data. Entities can be classified into two groups, i.e., proper nouns and common nouns. Proper nouns are also known as Named Entities (NE) and correspond to the name of people, organizations, or locations, e.g., John, WHO, or Canada. Common nouns describe classes of objects, e.g., spoon or cancer. Both types of entities can be found in a Knowledge Graph (KG). Recent work has successfully exploited the contribution of KGs in NLP tasks, such as Natural Language Inference (NLI) (KM et al.,2018) and Question Answering (QA) (Sorokin and Gurevych, 2018). Only a few works had exploited the benefits of KGs in Neural Machine Translation (NMT) when the work presented herein began. Additionally, few works had studied the contribution of KGs to Natural Language Generation (NLG) tasks. Moreover, the multilinguality also remained an open research area in these respective tasks (Young et al., 2018). In this thesis, we focus on the use of KGs for machine translation and the generation of texts to deal with the problems caused by entities and consequently enhance the quality of automatically generated texts.
Where is Linked Data in Question Answering over Linked Data?
May 07, 2020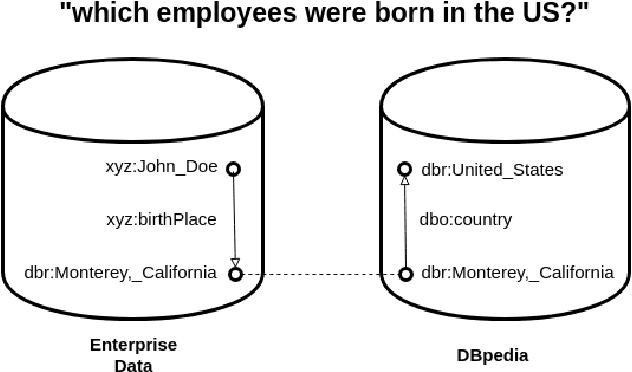
We argue that "Question Answering with Knowledge Base" and "Question Answering over Linked Data" are currently two instances of the same problem, despite one explicitly declares to deal with Linked Data. We point out the lack of existing methods to evaluate question answering on datasets which exploit external links to the rest of the cloud or share common schema. To this end, we propose the creation of new evaluation settings to leverage the advantages of the Semantic Web to achieve AI-complete question answering.
A Holistic Natural Language Generation Framework for the Semantic Web
Nov 04, 2019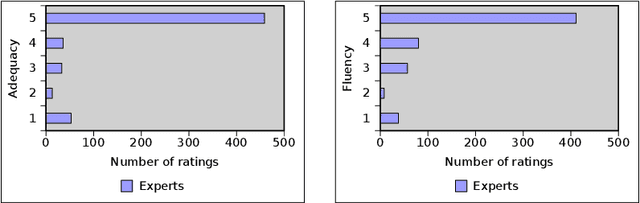
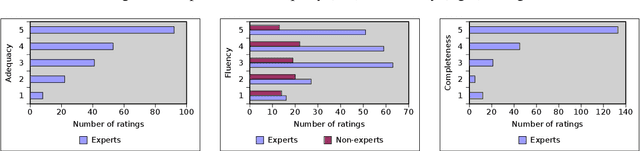
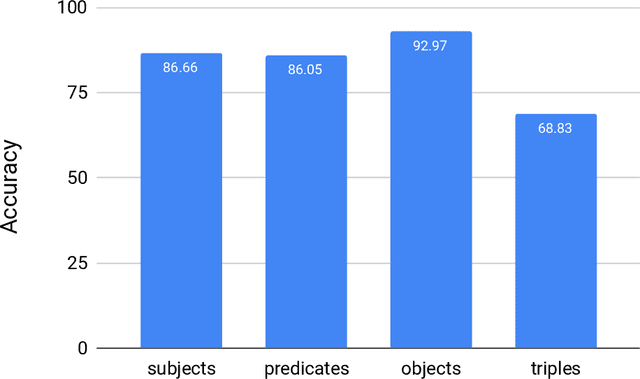
With the ever-growing generation of data for the Semantic Web comes an increasing demand for this data to be made available to non-semantic Web experts. One way of achieving this goal is to translate the languages of the Semantic Web into natural language. We present LD2NL, a framework for verbalizing the three key languages of the Semantic Web, i.e., RDF, OWL, and SPARQL. Our framework is based on a bottom-up approach to verbalization. We evaluated LD2NL in an open survey with 86 persons. Our results suggest that our framework can generate verbalizations that are close to natural languages and that can be easily understood by non-experts. Therewith, it enables non-domain experts to interpret Semantic Web data with more than 91\% of the accuracy of domain experts.
Semantic Web for Machine Translation: Challenges and Directions
Jul 23, 2019A large number of machine translation approaches have recently been developed to facilitate the fluid migration of content across languages. However, the literature suggests that many obstacles must still be dealt with to achieve better automatic translations. One of these obstacles is lexical and syntactic ambiguity. A promising way of overcoming this problem is using Semantic Web technologies. This article is an extended abstract of our systematic review on machine translation approaches that rely on Semantic Web technologies for improving the translation of texts. Overall, we present the challenges and opportunities in the use of Semantic Web technologies in Machine Translation. Moreover, our research suggests that while Semantic Web technologies can enhance the quality of machine translation outputs for various problems, the combination of both is still in its infancy.