 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Resource Text-to-Speech Synthesis Using Noise-Augmented Training of ForwardTacotron
Jan 10, 2025



In recent years, several text-to-speech systems have been proposed to synthesize natural speech in zero-shot, few-shot, and low-resource scenarios. However, these methods typically require training with data from many different speakers. The speech quality across the speaker set typically is diverse and imposes an upper limit on the quality achievable for the low-resource speaker. In the current work, we achieve high-quality speech synthesis using as little as five minutes of speech from the desired speaker by augmenting the low-resource speaker data with noise and employing multiple sampling techniques during training. Our method requires only four high-quality, high-resource speakers, which are easy to obtain and use in practice. Our low-complexity method achieves improved speaker similarity compared to the state-of-the-art zero-shot method HierSpeech++ and the recent low-resource method AdapterMix while maintaining comparable naturalness. Our proposed approach can also reduce the data requirements for speech synthesis for new speakers and languages.
Low-Resource Text-to-Speech Using Specific Data and Noise Augmentation
Jun 16, 2023



Many neural text-to-speech architectures can synthesize nearly natural speech from text inputs. These architectures must be trained with tens of hours of annotated and high-quality speech data. Compiling such large databases for every new voice requires a lot of time and effort. In this paper, we describe a method to extend the popular Tacotron-2 architecture and its training with data augmentation to enable single-speaker synthesis using a limited amount of specific training data. In contrast to elaborate augmentation methods proposed in the literature, we use simple stationary noises for data augmentation. Our extension is easy to implement and adds almost no computational overhead during training and inference. Using only two hours of training data, our approach was rated by human listeners to be on par with the baseline Tacotron-2 trained with 23.5 hours of LJSpeech data. In addition, we tested our model with a semantically unpredictable sentences test, which showed that both models exhibit similar intelligibility levels.
Towards an Interoperable Ecosystem of AI and LT Platforms: A Roadmap for the Implementation of Different Levels of Interoperability
Apr 17, 2020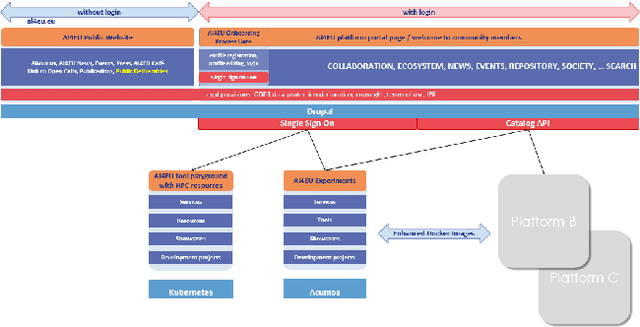
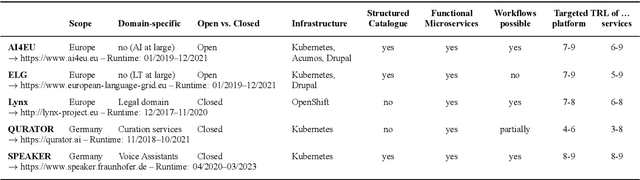
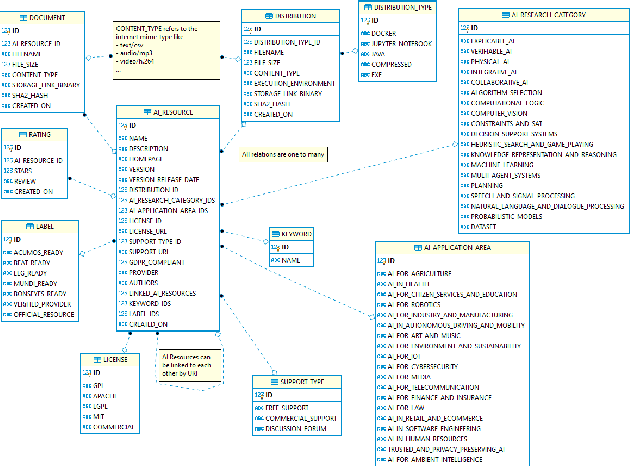

With regard to the wider area of AI/LT platform interoperability, we concentrate on two core aspects: (1) cross-platform search and discovery of resources and services; (2) composition of cross-platform service workflows. We devise five different levels (of increasing complexity) of platform interoperability that we suggest to implement in a wider federation of AI/LT platforms. We illustrate the approach using the five emerging AI/LT platforms AI4EU, ELG, Lynx, QURATOR and SPEAKER.