 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Online Crowdsourcing with Complex Annotations
Jan 25, 2024



Crowdsourcing platforms use various truth discovery algorithms to aggregate annotations from multiple labelers. In an online setting, however, the main challenge is to decide whether to ask for more annotations for each item to efficiently trade off cost (i.e., the number of annotations) for quality of the aggregated annotations. In this paper, we propose a novel approach for general complex annotation (such as bounding boxes and taxonomy paths), that works in an online crowdsourcing setting. We prove that the expected average similarity of a labeler is linear in their accuracy \emph{conditional on the reported label}. This enables us to infer reported label accuracy in a broad range of scenarios. We conduct extensive evaluations on real-world crowdsourcing data from Meta and show the effectiveness of our proposed online algorithms in improving the cost-quality trade-off.
Empirical Bayes approach to Truth Discovery problems
Jun 09, 2022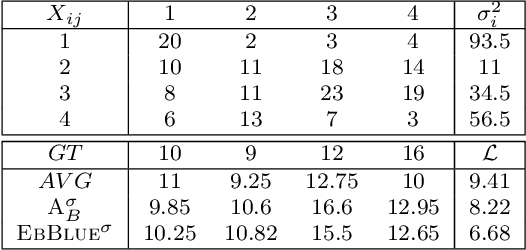
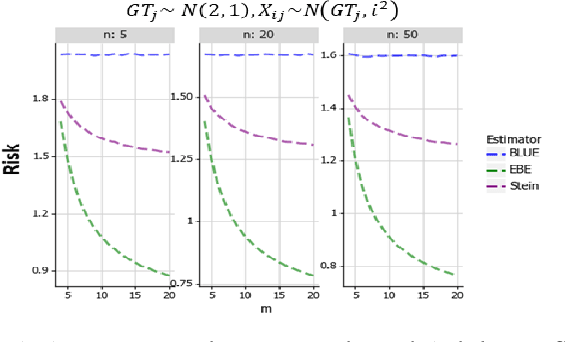
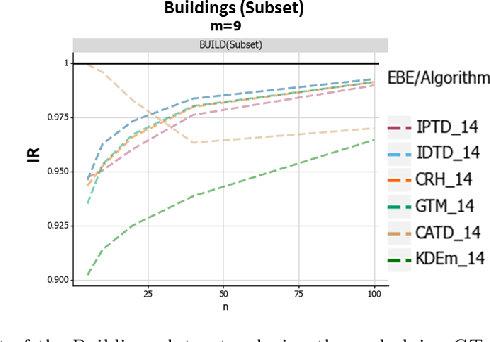
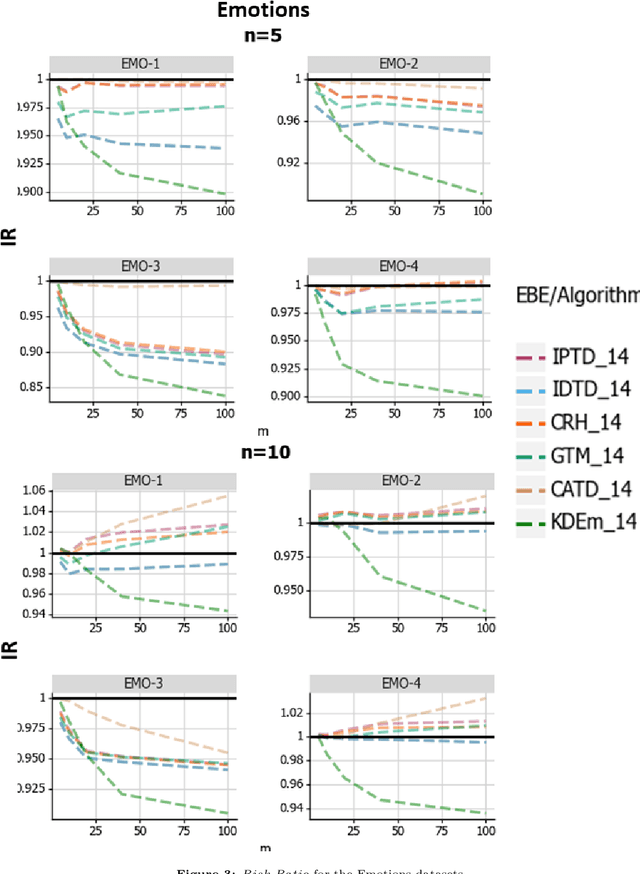
When aggregating information from conflicting sources, one's goal is to find the truth. Most real-value \emph{truth discovery} (TD) algorithms try to achieve this goal by estimating the competence of each source and then aggregating the conflicting information by weighing each source's answer proportionally to her competence. However, each of those algorithms requires more than a single source for such estimation and usually does not consider different estimation methods other than a weighted mean. Therefore, in this work we formulate, prove, and empirically test the conditions for an Empirical Bayes Estimator (EBE) to dominate the weighted mean aggregation. Our main result demonstrates that EBE, under mild conditions, can be used as a second step of any TD algorithm in order to reduce the expected error.
Representative Committees of Peers
Jun 14, 2020A population of voters must elect representatives among themselves to decide on a sequence of possibly unforeseen binary issues. Voters care only about the final decision, not the elected representatives. The disutility of a voter is proportional to the fraction of issues, where his preferences disagree with the decision. While an issue-by-issue vote by all voters would maximize social welfare, we are interested in how well the preferences of the population can be approximated by a small committee. We show that a k-sortition (a random committee of k voters with the majority vote within the committee) leads to an outcome within the factor 1+O(1/k) of the optimal social cost for any number of voters n, any number of issues $m$, and any preference profile. For a small number of issues m, the social cost can be made even closer to optimal by delegation procedures that weigh committee members according to their number of followers. However, for large m, we demonstrate that the k-sortition is the worst-case optimal rule within a broad family of committee-based rules that take into account metric information about the preference profile of the whole population.
Bidding in Spades
Feb 10, 2020
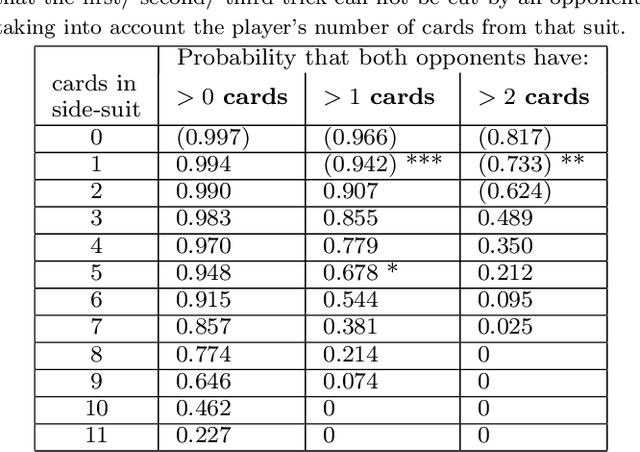
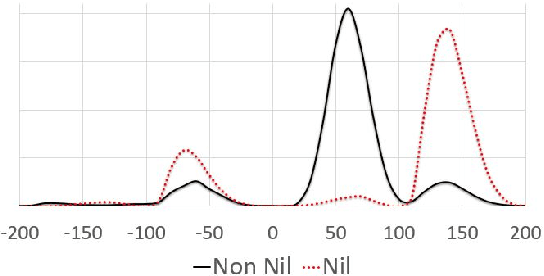
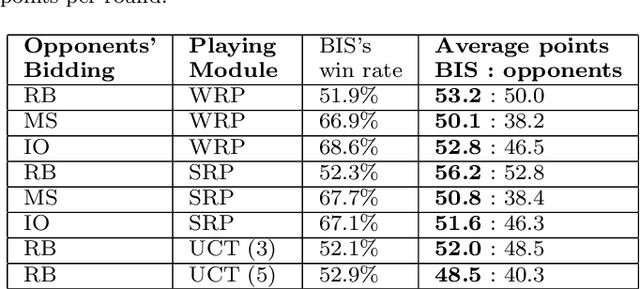
We present a Spades bidding algorithm that is superior to recreational human players and to publicly available bots. Like in Bridge, the game of Spades is composed of two independent phases, \textit{bidding} and \textit{playing}. This paper focuses on the bidding algorithm, since this phase holds a precise challenge: based on the input, choose the bid that maximizes the agent's winning probability. Our \emph{Bidding-in-Spades} (BIS) algorithm heuristically determines the bidding strategy by comparing the expected utility of each possible bid. A major challenge is how to estimate these expected utilities. To this end, we propose a set of domain-specific heuristics, and then correct them via machine learning using data from real-world players. The \BIS algorithm we present can be attached to any playing algorithm. It beats rule-based bidding bots when all use the same playing component. When combined with a rule-based playing algorithm, it is superior to the average recreational human.
Truth Discovery via Proxy Voting
May 02, 2019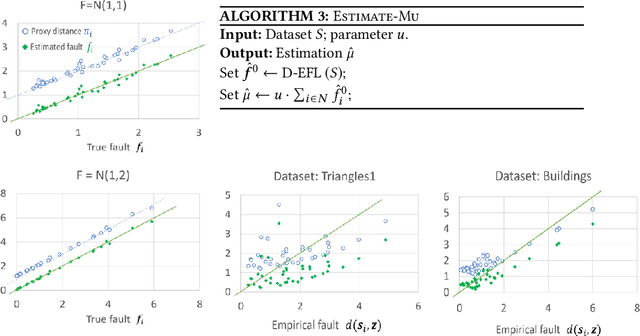
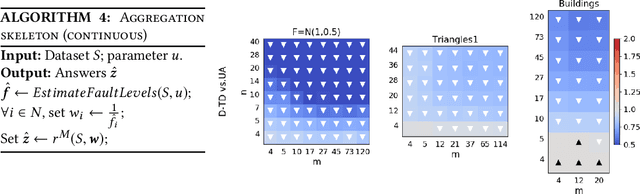
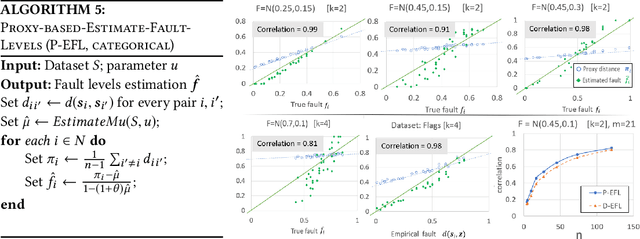
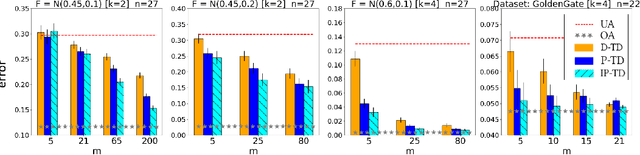
Truth discovery is a general name for a broad range of statistical methods aimed to extract the correct answers to questions, based on multiple answers coming from noisy sources. For example, workers in a crowdsourcing platform. In this paper, we design simple truth discovery methods inspired by \emph{proxy voting}, that give higher weight to workers whose answers are close to those of other workers. We prove that under standard statistical assumptions, proxy-based truth discovery (\PTD) allows us to estimate the true competence of each worker, whether workers face questions whose answers are real-valued, categorical, or rankings. We then demonstrate through extensive empirical study on synthetic and real data that \PTD is substantially better than unweighted aggregation, and competes well with other truth discovery methods, in all of the above domains.
On Sex, Evolution, and the Multiplicative Weights Update Algorithm
Feb 17, 2015
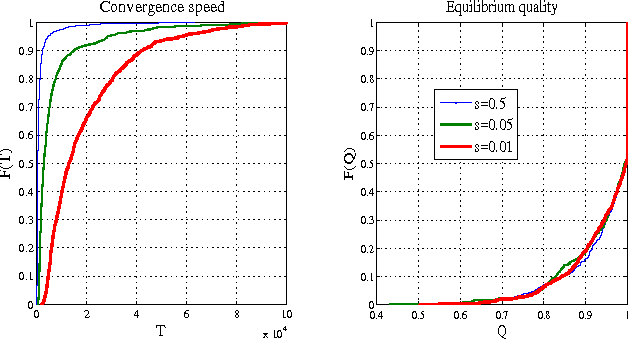

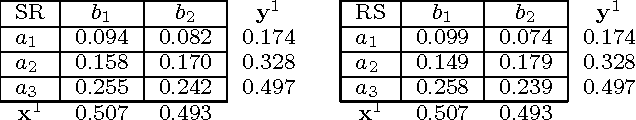
We consider a recent innovative theory by Chastain et al. on the role of sex in evolution [PNAS'14]. In short, the theory suggests that the evolutionary process of gene recombination implements the celebrated multiplicative weights updates algorithm (MWUA). They prove that the population dynamics induced by sexual reproduction can be precisely modeled by genes that use MWUA as their learning strategy in a particular coordination game. The result holds in the environments of \emph{weak selection}, under the assumption that the population frequencies remain a product distribution. We revisit the theory, eliminating both the requirement of weak selection and any assumption on the distribution of the population. Removing the assumption of product distributions is crucial, since as we show, this assumption is inconsistent with the population dynamics. We show that the marginal allele distributions induced by the population dynamics precisely match the marginals induced by a multiplicative weights update algorithm in this general setting, thereby affirming and substantially generalizing these earlier results. We further revise the implications for convergence and utility or fitness guarantees in coordination games. In contrast to the claim of Chastain et al.[PNAS'14], we conclude that the sexual evolutionary dynamics does not entail any property of the population distribution, beyond those already implied by convergence.
Solving Cooperative Reliability Games
Feb 14, 2012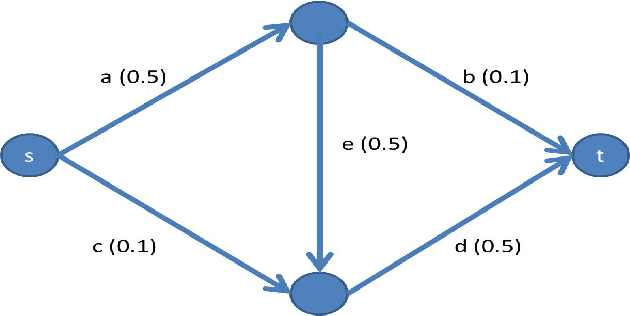
Cooperative games model the allocation of profit from joint actions, following considerations such as stability and fairness. We propose the reliability extension of such games, where agents may fail to participate in the game. In the reliability extension, each agent only "survives" with a certain probability, and a coalition's value is the probability that its surviving members would be a winning coalition in the base game. We study prominent solution concepts in such games, showing how to approximate the Shapley value and how to compute the core in games with few agent types. We also show that applying the reliability extension may stabilize the game, making the core non-empty even when the base game has an empty core.
The Cost of Stability in Coalitional Games
Jul 24, 2009A key question in cooperative game theory is that of coalitional stability, usually captured by the notion of the \emph{core}--the set of outcomes such that no subgroup of players has an incentive to deviate. However, some coalitional games have empty cores, and any outcome in such a game is unstable. In this paper, we investigate the possibility of stabilizing a coalitional game by using external payments. We consider a scenario where an external party, which is interested in having the players work together, offers a supplemental payment to the grand coalition (or, more generally, a particular coalition structure). This payment is conditional on players not deviating from their coalition(s). The sum of this payment plus the actual gains of the coalition(s) may then be divided among the agents so as to promote stability. We define the \emph{cost of stability (CoS)} as the minimal external payment that stabilizes the game. We provide general bounds on the cost of stability in several classes of games, and explore its algorithmic properties. To develop a better intuition for the concepts we introduce, we provide a detailed algorithmic study of the cost of stability in weighted voting games, a simple but expressive class of games which can model decision-making in political bodies, and cooperation in multiagent settings. Finally, we extend our model and results to games with coalition structures.
* 20 pages; will be presented at SAGT'09