 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Low-Rank Matrix Factorization: Global Optimality, Algorithms, and Applications
Aug 25, 2017
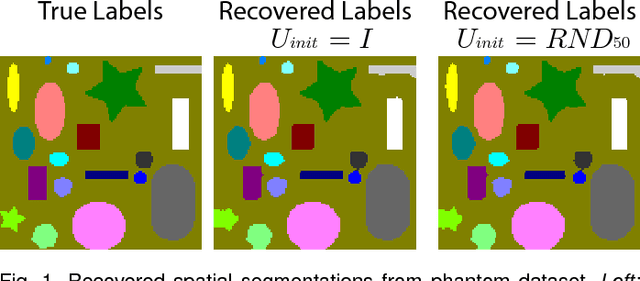
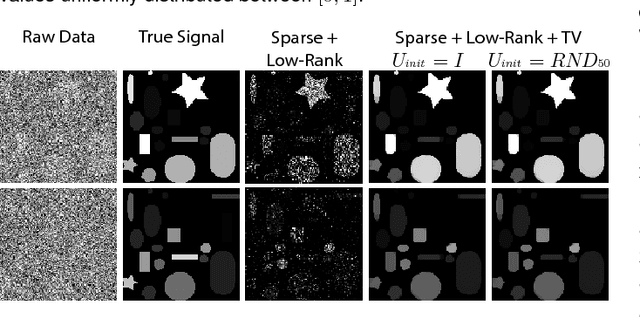
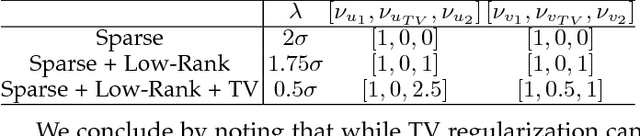
Recently, convex formulations of low-rank matrix factorization problems have received considerable attention in machine learning. However, such formulations often require solving for a matrix of the size of the data matrix, making it challenging to apply them to large scale datasets. Moreover, in many applications the data can display structures beyond simply being low-rank, e.g., images and videos present complex spatio-temporal structures that are largely ignored by standard low-rank methods. In this paper we study a matrix factorization technique that is suitable for large datasets and captures additional structure in the factors by using a particular form of regularization that includes well-known regularizers such as total variation and the nuclear norm as particular cases. Although the resulting optimization problem is non-convex, we show that if the size of the factors is large enough, under certain conditions, any local minimizer for the factors yields a global minimizer. A few practical algorithms are also provided to solve the matrix factorization problem, and bounds on the distance from a given approximate solution of the optimization problem to the global optimum are derived. Examples in neural calcium imaging video segmentation and hyperspectral compressed recovery show the advantages of our approach on high-dimensional datasets.
3D Pose Regression using Convolutional Neural Networks
Aug 18, 20173D pose estimation is a key component of many important computer vision tasks such as autonomous navigation and 3D scene understanding. Most state-of-the-art approaches to 3D pose estimation solve this problem as a pose-classification problem in which the pose space is discretized into bins and a CNN classifier is used to predict a pose bin. We argue that the 3D pose space is continuous and propose to solve the pose estimation problem in a CNN regression framework with a suitable representation, data augmentation and loss function that captures the geometry of the pose space. Experiments on PASCAL3D+ show that the proposed 3D pose regression approach achieves competitive performance compared to the state-of-the-art.
Curriculum Dropout
Aug 03, 2017
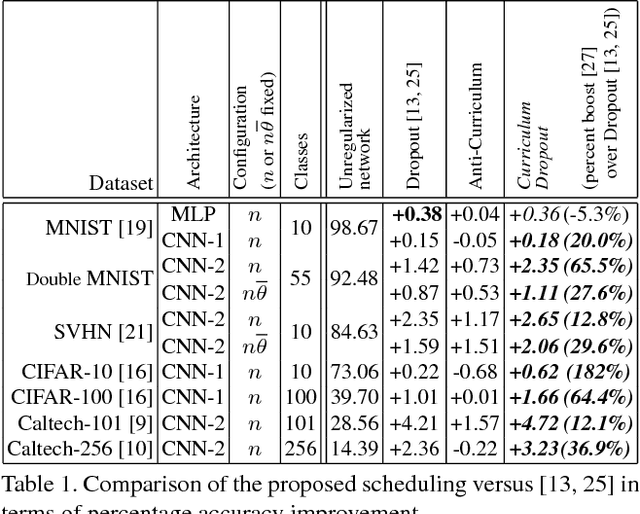
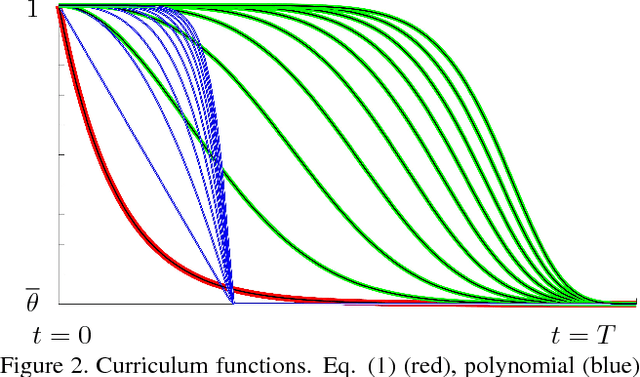
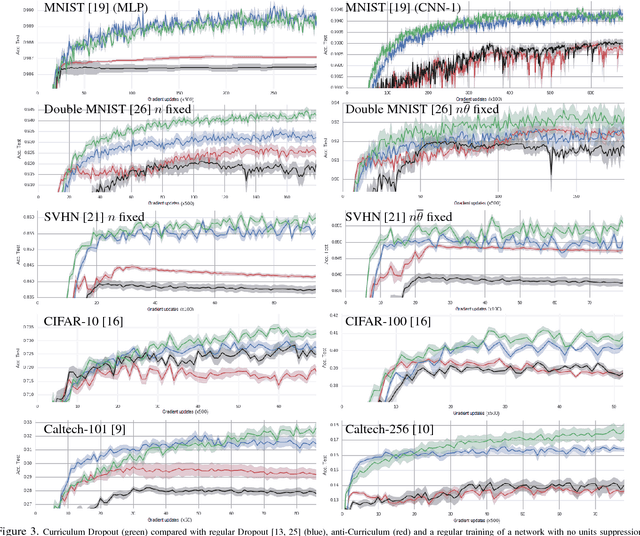
Dropout is a very effective way of regularizing neural networks. Stochastically "dropping out" units with a certain probability discourages over-specific co-adaptations of feature detectors, preventing overfitting and improving network generalization. Besides, Dropout can be interpreted as an approximate model aggregation technique, where an exponential number of smaller networks are averaged in order to get a more powerful ensemble. In this paper, we show that using a fixed dropout probability during training is a suboptimal choice. We thus propose a time scheduling for the probability of retaining neurons in the network. This induces an adaptive regularization scheme that smoothly increases the difficulty of the optimization problem. This idea of "starting easy" and adaptively increasing the difficulty of the learning problem has its roots in curriculum learning and allows one to train better models. Indeed, we prove that our optimization strategy implements a very general curriculum scheme, by gradually adding noise to both the input and intermediate feature representations within the network architecture. Experiments on seven image classification datasets and different network architectures show that our method, named Curriculum Dropout, frequently yields to better generalization and, at worst, performs just as well as the standard Dropout method.
Hyperplane Clustering Via Dual Principal Component Pursuit
Jun 19, 2017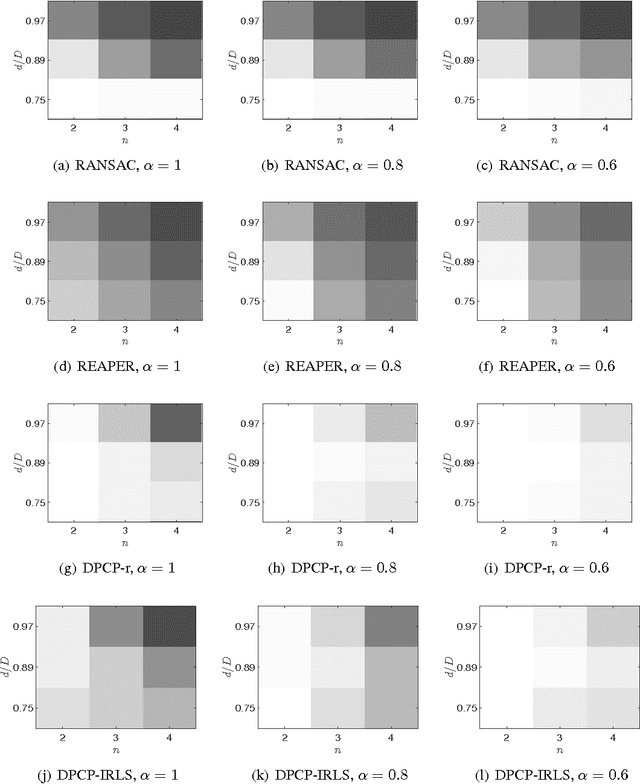

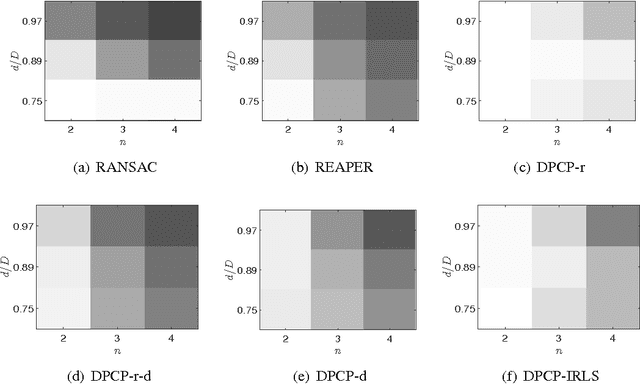
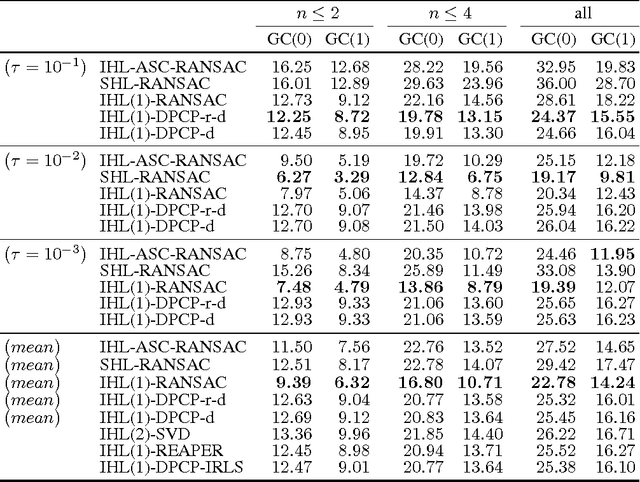
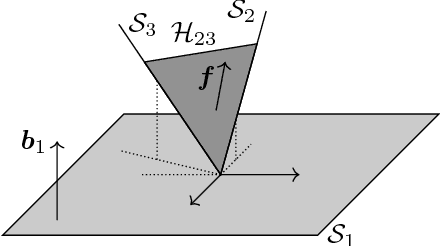
We extend the theoretical analysis of a recently proposed single subspace learning algorithm, called Dual Principal Component Pursuit (DPCP), to the case where the data are drawn from of a union of hyperplanes. To gain insight into the properties of the $\ell_1$ non-convex problem associated with DPCP, we develop a geometric analysis of a closely related continuous optimization problem. Then transferring this analysis to the discrete problem, our results state that as long as the hyperplanes are sufficiently separated, the dominant hyperplane is sufficiently dominant and the points are uniformly distributed inside the associated hyperplanes, then the non-convex DPCP problem has a unique global solution, equal to the normal vector of the dominant hyperplane. This suggests the correctness of a sequential hyperplane learning algorithm based on DPCP. A thorough experimental evaluation reveals that hyperplane learning schemes based on DPCP dramatically improve over the state-of-the-art methods for the case of synthetic data, while are competitive to the state-of-the-art in the case of 3D plane clustering for Kinect data.
Filtrated Algebraic Subspace Clustering
Mar 08, 2017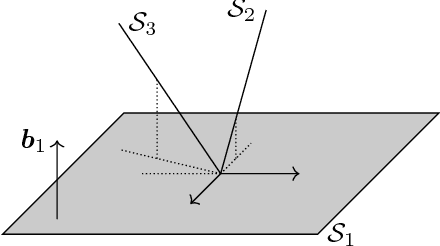
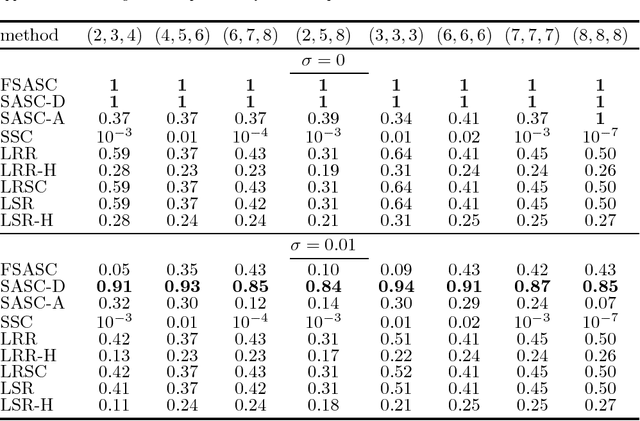
Subspace clustering is the problem of clustering data that lie close to a union of linear subspaces. In the abstract form of the problem, where no noise or other corruptions are present, the data are assumed to lie in general position inside the algebraic variety of a union of subspaces, and the objective is to decompose the variety into its constituent subspaces. Prior algebraic-geometric approaches to this problem require the subspaces to be of equal dimension, or the number of subspaces to be known. Subspaces of arbitrary dimensions can still be recovered in closed form, in terms of all homogeneous polynomials of degree $m$ that vanish on their union, when an upper bound m on the number of the subspaces is given. In this paper, we propose an alternative, provably correct, algorithm for addressing a union of at most $m$ arbitrary-dimensional subspaces, based on the idea of descending filtrations of subspace arrangements. Our algorithm uses the gradient of a vanishing polynomial at a point in the variety to find a hyperplane containing the subspace S passing through that point. By intersecting the variety with this hyperplane, we obtain a subvariety that contains S, and recursively applying the procedure until no non-trivial vanishing polynomial exists, our algorithm eventually identifies S. By repeating this procedure for other points, our algorithm eventually identifies all the subspaces by returning a basis for their orthogonal complement. Finally, we develop a variant of the abstract algorithm, suitable for computations with noisy data. We show by experiments on synthetic and real data that the proposed algorithm outperforms state-of-the-art methods on several occasions, thus demonstrating the merit of the idea of filtrations.
Algebraic Clustering of Affine Subspaces
Mar 08, 2017Subspace clustering is an important problem in machine learning with many applications in computer vision and pattern recognition. Prior work has studied this problem using algebraic, iterative, statistical, low-rank and sparse representation techniques. While these methods have been applied to both linear and affine subspaces, theoretical results have only been established in the case of linear subspaces. For example, algebraic subspace clustering (ASC) is guaranteed to provide the correct clustering when the data points are in general position and the union of subspaces is transversal. In this paper we study in a rigorous fashion the properties of ASC in the case of affine subspaces. Using notions from algebraic geometry, we prove that the homogenization trick, which embeds points in a union of affine subspaces into points in a union of linear subspaces, preserves the general position of the points and the transversality of the union of subspaces in the embedded space, thus establishing the correctness of ASC for affine subpaces.
Information Pursuit: A Bayesian Framework for Sequential Scene Parsing
Jan 09, 2017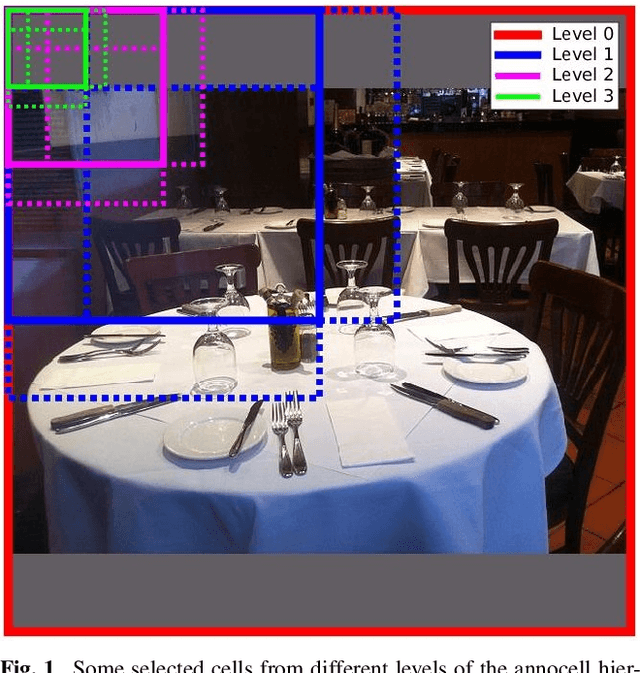
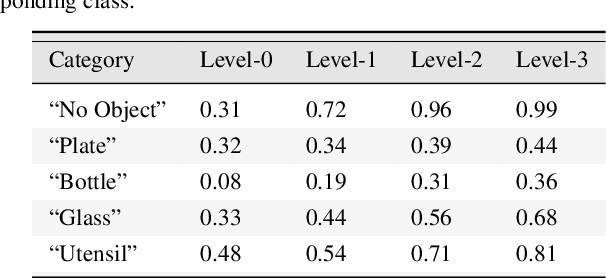

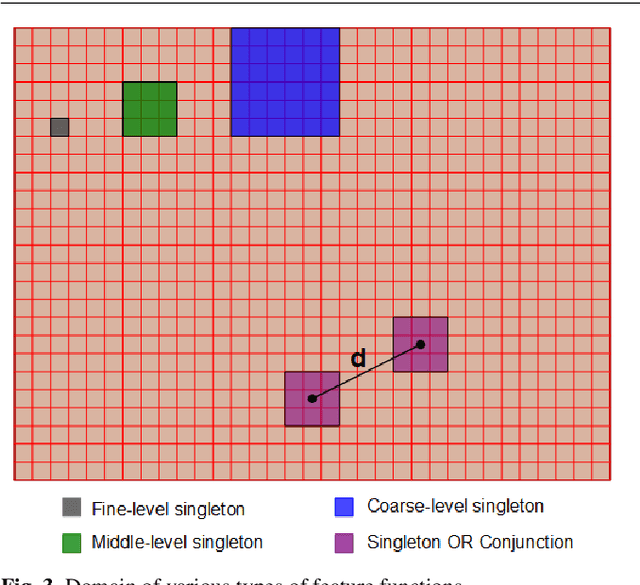
Despite enormous progress in object detection and classification, the problem of incorporating expected contextual relationships among object instances into modern recognition systems remains a key challenge. In this work we propose Information Pursuit, a Bayesian framework for scene parsing that combines prior models for the geometry of the scene and the spatial arrangement of objects instances with a data model for the output of high-level image classifiers trained to answer specific questions about the scene. In the proposed framework, the scene interpretation is progressively refined as evidence accumulates from the answers to a sequence of questions. At each step, we choose the question to maximize the mutual information between the new answer and the full interpretation given the current evidence obtained from previous inquiries. We also propose a method for learning the parameters of the model from synthesized, annotated scenes obtained by top-down sampling from an easy-to-learn generative scene model. Finally, we introduce a database of annotated indoor scenes of dining room tables, which we use to evaluate the proposed approach.
Temporal Convolutional Networks for Action Segmentation and Detection
Nov 16, 2016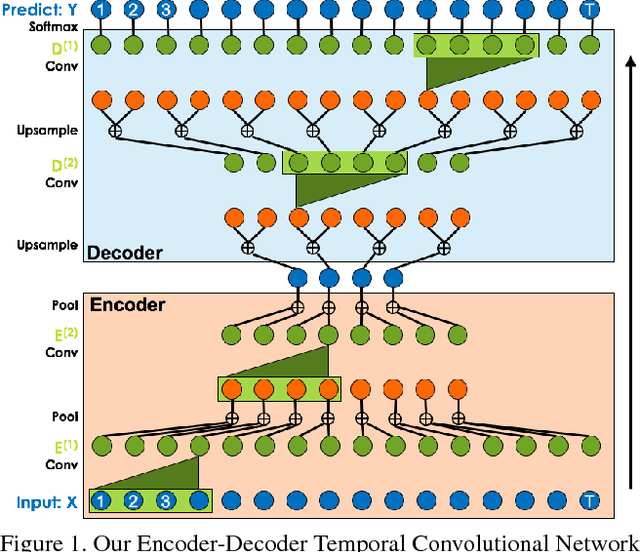
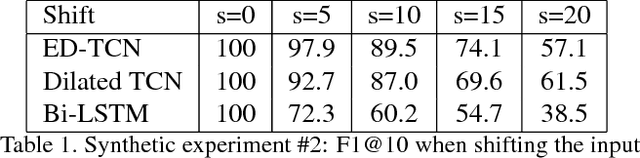
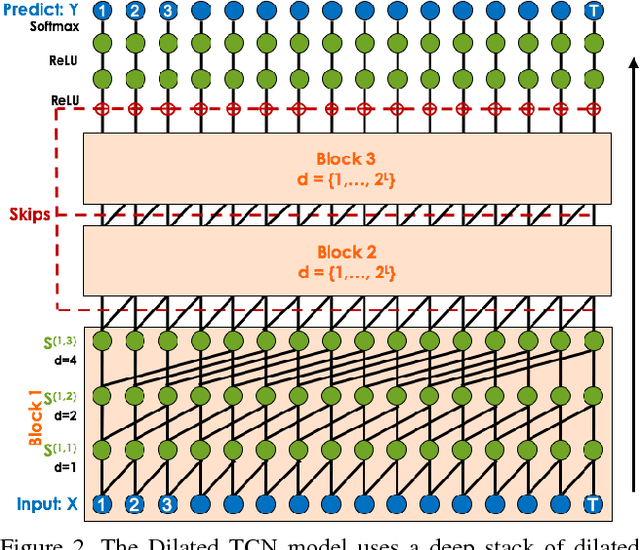
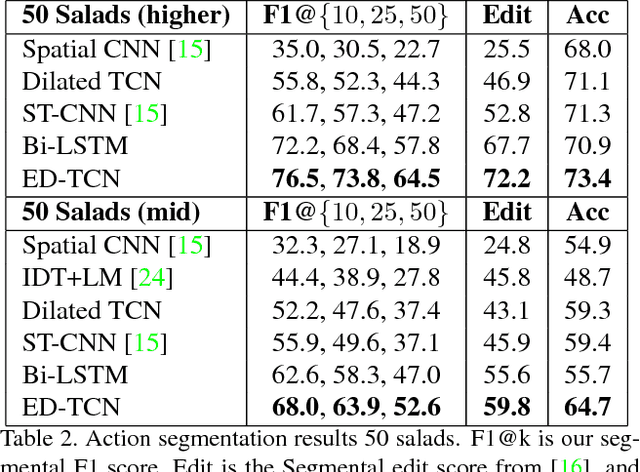
The ability to identify and temporally segment fine-grained human actions throughout a video is crucial for robotics, surveillance, education, and beyond. Typical approaches decouple this problem by first extracting local spatiotemporal features from video frames and then feeding them into a temporal classifier that captures high-level temporal patterns. We introduce a new class of temporal models, which we call Temporal Convolutional Networks (TCNs), that use a hierarchy of temporal convolutions to perform fine-grained action segmentation or detection. Our Encoder-Decoder TCN uses pooling and upsampling to efficiently capture long-range temporal patterns whereas our Dilated TCN uses dilated convolutions. We show that TCNs are capable of capturing action compositions, segment durations, and long-range dependencies, and are over a magnitude faster to train than competing LSTM-based Recurrent Neural Networks. We apply these models to three challenging fine-grained datasets and show large improvements over the state of the art.
Segmental Spatiotemporal CNNs for Fine-grained Action Segmentation
Sep 30, 2016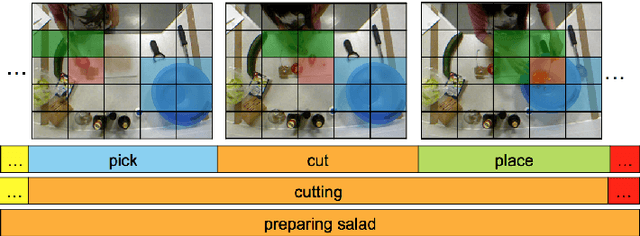
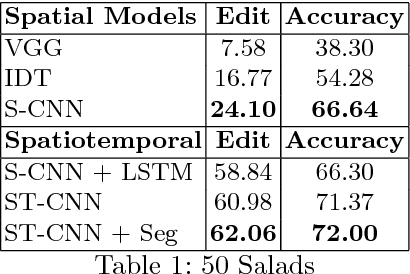
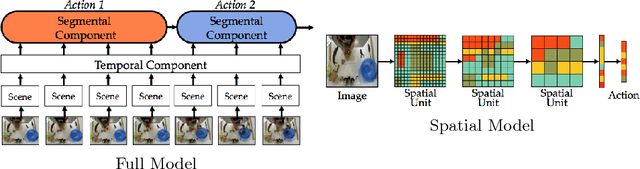
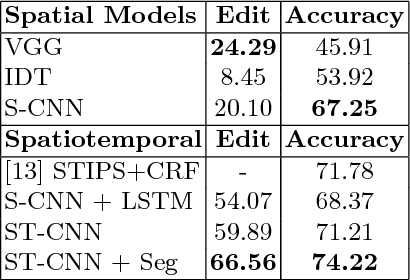
Joint segmentation and classification of fine-grained actions is important for applications of human-robot interaction, video surveillance, and human skill evaluation. However, despite substantial recent progress in large-scale action classification, the performance of state-of-the-art fine-grained action recognition approaches remains low. We propose a model for action segmentation which combines low-level spatiotemporal features with a high-level segmental classifier. Our spatiotemporal CNN is comprised of a spatial component that uses convolutional filters to capture information about objects and their relationships, and a temporal component that uses large 1D convolutional filters to capture information about how object relationships change across time. These features are used in tandem with a semi-Markov model that models transitions from one action to another. We introduce an efficient constrained segmental inference algorithm for this model that is orders of magnitude faster than the current approach. We highlight the effectiveness of our Segmental Spatiotemporal CNN on cooking and surgical action datasets for which we observe substantially improved performance relative to recent baseline methods.
Temporal Convolutional Networks: A Unified Approach to Action Segmentation
Aug 29, 2016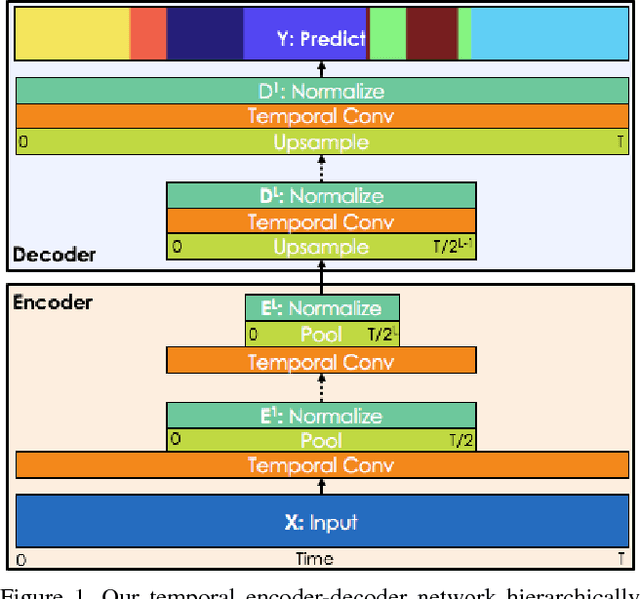
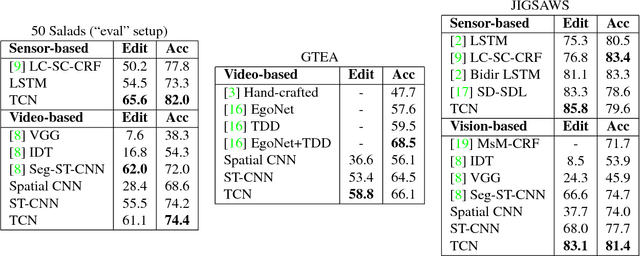
The dominant paradigm for video-based action segmentation is composed of two steps: first, for each frame, compute low-level features using Dense Trajectories or a Convolutional Neural Network that encode spatiotemporal information locally, and second, input these features into a classifier that captures high-level temporal relationships, such as a Recurrent Neural Network (RNN). While often effective, this decoupling requires specifying two separate models, each with their own complexities, and prevents capturing more nuanced long-range spatiotemporal relationships. We propose a unified approach, as demonstrated by our Temporal Convolutional Network (TCN), that hierarchically captures relationships at low-, intermediate-, and high-level time-scales. Our model achieves superior or competitive performance using video or sensor data on three public action segmentation datasets and can be trained in a fraction of the time it takes to train an RNN.