 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Differentially Private Ad Prediction Models with Semi-Sensitive Features
Jan 26, 2024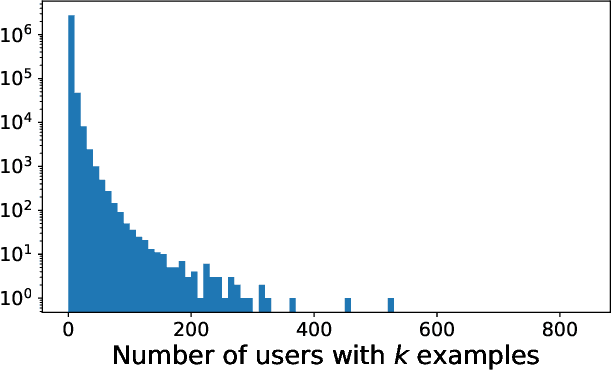
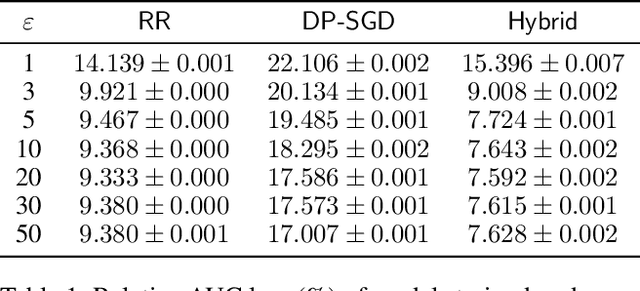
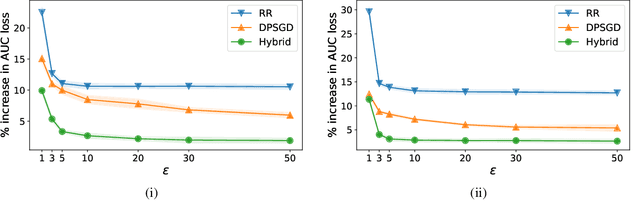
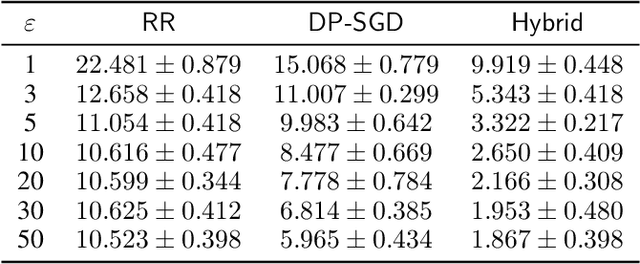
Motivated by problems arising in digital advertising, we introduce the task of training differentially private (DP) machine learning models with semi-sensitive features. In this setting, a subset of the features is known to the attacker (and thus need not be protected) while the remaining features as well as the label are unknown to the attacker and should be protected by the DP guarantee. This task interpolates between training the model with full DP (where the label and all features should be protected) or with label DP (where all the features are considered known, and only the label should be protected). We present a new algorithm for training DP models with semi-sensitive features. Through an empirical evaluation on real ads datasets, we demonstrate that our algorithm surpasses in utility the baselines of (i) DP stochastic gradient descent (DP-SGD) run on all features (known and unknown), and (ii) a label DP algorithm run only on the known features (while discarding the unknown ones).
Optimal Unbiased Randomizers for Regression with Label Differential Privacy
Dec 09, 2023We propose a new family of label randomizers for training regression models under the constraint of label differential privacy (DP). In particular, we leverage the trade-offs between bias and variance to construct better label randomizers depending on a privately estimated prior distribution over the labels. We demonstrate that these randomizers achieve state-of-the-art privacy-utility trade-offs on several datasets, highlighting the importance of reducing bias when training neural networks with label DP. We also provide theoretical results shedding light on the structural properties of the optimal unbiased randomizers.
Sparsity-Preserving Differentially Private Training of Large Embedding Models
Nov 14, 2023



As the use of large embedding models in recommendation systems and language applications increases, concerns over user data privacy have also risen. DP-SGD, a training algorithm that combines differential privacy with stochastic gradient descent, has been the workhorse in protecting user privacy without compromising model accuracy by much. However, applying DP-SGD naively to embedding models can destroy gradient sparsity, leading to reduced training efficiency. To address this issue, we present two new algorithms, DP-FEST and DP-AdaFEST, that preserve gradient sparsity during private training of large embedding models. Our algorithms achieve substantial reductions ($10^6 \times$) in gradient size, while maintaining comparable levels of accuracy, on benchmark real-world datasets.
User-Level Differential Privacy With Few Examples Per User
Sep 21, 2023Previous work on user-level differential privacy (DP) [Ghazi et al. NeurIPS 2021, Bun et al. STOC 2023] obtained generic algorithms that work for various learning tasks. However, their focus was on the example-rich regime, where the users have so many examples that each user could themselves solve the problem. In this work we consider the example-scarce regime, where each user has only a few examples, and obtain the following results: 1. For approximate-DP, we give a generic transformation of any item-level DP algorithm to a user-level DP algorithm. Roughly speaking, the latter gives a (multiplicative) savings of $O_{\varepsilon,\delta}(\sqrt{m})$ in terms of the number of users required for achieving the same utility, where $m$ is the number of examples per user. This algorithm, while recovering most known bounds for specific problems, also gives new bounds, e.g., for PAC learning. 2. For pure-DP, we present a simple technique for adapting the exponential mechanism [McSherry, Talwar FOCS 2007] to the user-level setting. This gives new bounds for a variety of tasks, such as private PAC learning, hypothesis selection, and distribution learning. For some of these problems, we show that our bounds are near-optimal.
Ticketed Learning-Unlearning Schemes
Jun 27, 2023



We consider the learning--unlearning paradigm defined as follows. First given a dataset, the goal is to learn a good predictor, such as one minimizing a certain loss. Subsequently, given any subset of examples that wish to be unlearnt, the goal is to learn, without the knowledge of the original training dataset, a good predictor that is identical to the predictor that would have been produced when learning from scratch on the surviving examples. We propose a new ticketed model for learning--unlearning wherein the learning algorithm can send back additional information in the form of a small-sized (encrypted) ``ticket'' to each participating training example, in addition to retaining a small amount of ``central'' information for later. Subsequently, the examples that wish to be unlearnt present their tickets to the unlearning algorithm, which additionally uses the central information to return a new predictor. We provide space-efficient ticketed learning--unlearning schemes for a broad family of concept classes, including thresholds, parities, intersection-closed classes, among others. En route, we introduce the count-to-zero problem, where during unlearning, the goal is to simply know if there are any examples that survived. We give a ticketed learning--unlearning scheme for this problem that relies on the construction of Sperner families with certain properties, which might be of independent interest.
Approximating a RUM from Distributions on k-Slates
May 22, 2023In this work we consider the problem of fitting Random Utility Models (RUMs) to user choices. Given the winner distributions of the subsets of size $k$ of a universe, we obtain a polynomial-time algorithm that finds the RUM that best approximates the given distribution on average. Our algorithm is based on a linear program that we solve using the ellipsoid method. Given that its corresponding separation oracle problem is NP-hard, we devise an approximate separation oracle that can be viewed as a generalization of the weighted feedback arc set problem to hypergraphs. Our theoretical result can also be made practical: we obtain a heuristic that is effective and scales to real-world datasets.
On User-Level Private Convex Optimization
May 08, 2023
We introduce a new mechanism for stochastic convex optimization (SCO) with user-level differential privacy guarantees. The convergence rates of this mechanism are similar to those in the prior work of Levy et al. (2021); Narayanan et al. (2022), but with two important improvements. Our mechanism does not require any smoothness assumptions on the loss. Furthermore, our bounds are also the first where the minimum number of users needed for user-level privacy has no dependence on the dimension and only a logarithmic dependence on the desired excess error. The main idea underlying the new mechanism is to show that the optimizers of strongly convex losses have low local deletion sensitivity, along with an output perturbation method for functions with low local deletion sensitivity, which could be of independent interest.
Revenue Management without Demand Forecasting: A Data-Driven Approach for Bid Price Generation
Apr 14, 2023Traditional revenue management relies on long and stable historical data and predictable demand patterns. However, meeting those requirements is not always possible. Many industries face demand volatility on an ongoing basis, an example would be air cargo which has much shorter booking horizon with highly variable batch arrivals. Even for passenger airlines where revenue management (RM) is well-established, reacting to external shocks is a well-known challenge that requires user monitoring and manual intervention. Moreover, traditional RM comes with strict data requirements including historical bookings and pricing even in the absence of any bookings, spanning multiple years. For companies that have not established a practice in RM, that type of extensive data is usually not available. We present a data-driven approach to RM which eliminates the need for demand forecasting and optimization techniques. We develop a methodology to generate bid prices using historical booking data only. Our approach is an ex-post greedy heuristic to estimate proxies for marginal opportunity costs as a function of remaining capacity and time-to-departure solely based on historical booking data. We utilize a neural network algorithm to project bid price estimations into the future. We conduct an extensive simulation study where we measure performance of our methodology compared to that of an optimally generated bid price using dynamic programming (DP). We also extend our simulations to measure performance of both data-driven and DP generated bid prices under the presence of demand misspecification. Our results show that our data-driven methodology stays near a theoretical optimum (<1% revenue gap) for a wide-range of settings, whereas DP deviates more significantly from the optimal as the magnitude of misspecification is increased. This highlights the robustness of our data-driven approach.
Regression with Label Differential Privacy
Dec 12, 2022



We study the task of training regression models with the guarantee of label differential privacy (DP). Based on a global prior distribution on label values, which could be obtained privately, we derive a label DP randomization mechanism that is optimal under a given regression loss function. We prove that the optimal mechanism takes the form of a ``randomized response on bins'', and propose an efficient algorithm for finding the optimal bin values. We carry out a thorough experimental evaluation on several datasets demonstrating the efficacy of our algorithm.
Private Ad Modeling with DP-SGD
Nov 21, 2022



A well-known algorithm in privacy-preserving ML is differentially private stochastic gradient descent (DP-SGD). While this algorithm has been evaluated on text and image data, it has not been previously applied to ads data, which are notorious for their high class imbalance and sparse gradient updates. In this work we apply DP-SGD to several ad modeling tasks including predicting click-through rates, conversion rates, and number of conversion events, and evaluate their privacy-utility trade-off on real-world datasets. Our work is the first to empirically demonstrate that DP-SGD can provide both privacy and utility for ad modeling tasks.