 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplineCam: Exact Visualization and Characterization of Deep Network Geometry and Decision Boundaries
Feb 24, 2023Current Deep Network (DN) visualization and interpretability methods rely heavily on data space visualizations such as scoring which dimensions of the data are responsible for their associated prediction or generating new data features or samples that best match a given DN unit or representation. In this paper, we go one step further by developing the first provably exact method for computing the geometry of a DN's mapping - including its decision boundary - over a specified region of the data space. By leveraging the theory of Continuous Piece-Wise Linear (CPWL) spline DNs, SplineCam exactly computes a DNs geometry without resorting to approximations such as sampling or architecture simplification. SplineCam applies to any DN architecture based on CPWL nonlinearities, including (leaky-)ReLU, absolute value, maxout, and max-pooling and can also be applied to regression DNs such as implicit neural representations. Beyond decision boundary visualization and characterization, SplineCam enables one to compare architectures, measure generalizability and sample from the decision boundary on or off the manifold. Project Website: bit.ly/splinecam.
Unsupervised Learning on a DIET: Datum IndEx as Target Free of Self-Supervision, Reconstruction, Projector Head
Feb 20, 2023Costly, noisy, and over-specialized, labels are to be set aside in favor of unsupervised learning if we hope to learn cheap, reliable, and transferable models. To that end, spectral embedding, self-supervised learning, or generative modeling have offered competitive solutions. Those methods however come with numerous challenges \textit{e.g.} estimating geodesic distances, specifying projector architectures and anti-collapse losses, or specifying decoder architectures and reconstruction losses. In contrast, we introduce a simple explainable alternative -- coined \textbf{DIET} -- to learn representations from unlabeled data, free of those challenges. \textbf{DIET} is blatantly simple: take one's favorite classification setup and use the \textbf{D}atum \textbf{I}nd\textbf{E}x as its \textbf{T}arget class, \textit{i.e. each sample is its own class}, no further changes needed. \textbf{DIET} works without a decoder/projector network, is not based on positive pairs nor reconstruction, introduces no hyper-parameters, and works out-of-the-box across datasets and architectures. Despite \textbf{DIET}'s simplicity, the learned representations are of high-quality and often on-par with the state-of-the-art \textit{e.g.} using a linear classifier on top of DIET's learned representation reaches $71.4\%$ on CIFAR100 with a Resnet101, $52.5\%$ on TinyImagenet with a Resnext50.
The SSL Interplay: Augmentations, Inductive Bias, and Generalization
Feb 06, 2023



Self-supervised learning (SSL) has emerged as a powerful framework to learn representations from raw data without supervision. Yet in practice, engineers face issues such as instability in tuning optimizers and collapse of representations during training. Such challenges motivate the need for a theory to shed light on the complex interplay between the choice of data augmentation, network architecture, and training algorithm. We study such an interplay with a precise analysis of generalization performance on both pretraining and downstream tasks in a theory friendly setup, and highlight several insights for SSL practitioners that arise from our theory.
On minimal variations for unsupervised representation learning
Nov 07, 2022Unsupervised representation learning aims at describing raw data efficiently to solve various downstream tasks. It has been approached with many techniques, such as manifold learning, diffusion maps, or more recently self-supervised learning. Those techniques are arguably all based on the underlying assumption that target functions, associated with future downstream tasks, have low variations in densely populated regions of the input space. Unveiling minimal variations as a guiding principle behind unsupervised representation learning paves the way to better practical guidelines for self-supervised learning algorithms.
POLICE: Provably Optimal Linear Constraint Enforcement for Deep Neural Networks
Nov 07, 2022



Deep Neural Networks (DNNs) outshine alternative function approximators in many settings thanks to their modularity in composing any desired differentiable operator. The formed parametrized functional is then tuned to solve a task at hand from simple gradient descent. This modularity comes at the cost of making strict enforcement of constraints on DNNs, e.g. from a priori knowledge of the task, or from desired physical properties, an open challenge. In this paper we propose the first provable affine constraint enforcement method for DNNs that requires minimal changes into a given DNN's forward-pass, that is computationally friendly, and that leaves the optimization of the DNN's parameter to be unconstrained i.e. standard gradient-based method can be employed. Our method does not require any sampling and provably ensures that the DNN fulfills the affine constraint on a given input space's region at any point during training, and testing. We coin this method POLICE, standing for Provably Optimal LInear Constraint Enforcement.
ImageNet-X: Understanding Model Mistakes with Factor of Variation Annotations
Nov 03, 2022Deep learning vision systems are widely deployed across applications where reliability is critical. However, even today's best models can fail to recognize an object when its pose, lighting, or background varies. While existing benchmarks surface examples challenging for models, they do not explain why such mistakes arise. To address this need, we introduce ImageNet-X, a set of sixteen human annotations of factors such as pose, background, or lighting the entire ImageNet-1k validation set as well as a random subset of 12k training images. Equipped with ImageNet-X, we investigate 2,200 current recognition models and study the types of mistakes as a function of model's (1) architecture, e.g. transformer vs. convolutional, (2) learning paradigm, e.g. supervised vs. self-supervised, and (3) training procedures, e.g., data augmentation. Regardless of these choices, we find models have consistent failure modes across ImageNet-X categories. We also find that while data augmentation can improve robustness to certain factors, they induce spill-over effects to other factors. For example, strong random cropping hurts robustness on smaller objects. Together, these insights suggest to advance the robustness of modern vision models, future research should focus on collecting additional data and understanding data augmentation schemes. Along with these insights, we release a toolkit based on ImageNet-X to spur further study into the mistakes image recognition systems make.
The Hidden Uniform Cluster Prior in Self-Supervised Learning
Oct 13, 2022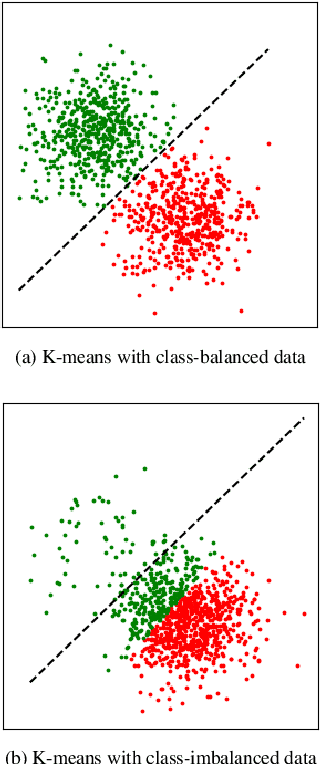


A successful paradigm in representation learning is to perform self-supervised pretraining using tasks based on mini-batch statistics (e.g., SimCLR, VICReg, SwAV, MSN). We show that in the formulation of all these methods is an overlooked prior to learn features that enable uniform clustering of the data. While this prior has led to remarkably semantic representations when pretraining on class-balanced data, such as ImageNet, we demonstrate that it can hamper performance when pretraining on class-imbalanced data. By moving away from conventional uniformity priors and instead preferring power-law distributed feature clusters, we show that one can improve the quality of the learned representations on real-world class-imbalanced datasets. To demonstrate this, we develop an extension of the Masked Siamese Networks (MSN) method to support the use of arbitrary features priors.
RankMe: Assessing the downstream performance of pretrained self-supervised representations by their rank
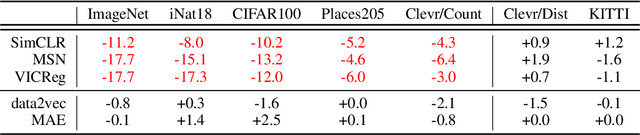
Oct 05, 2022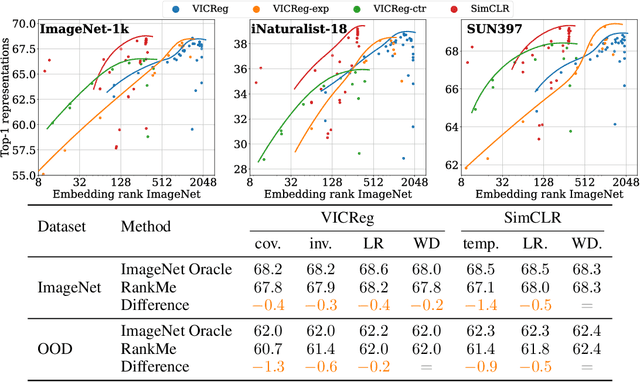
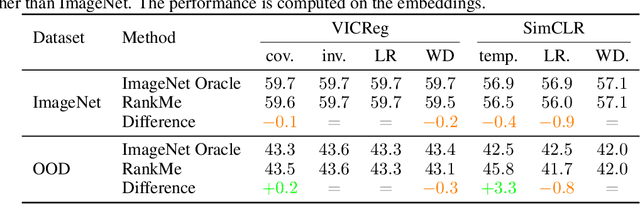
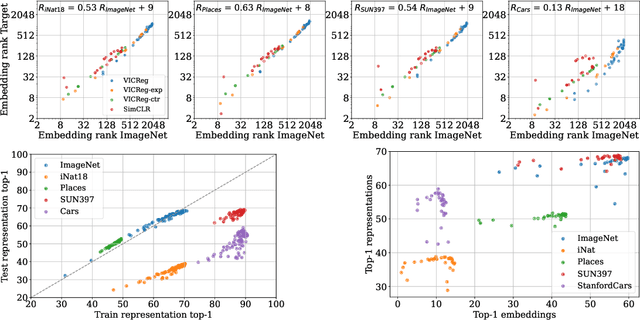
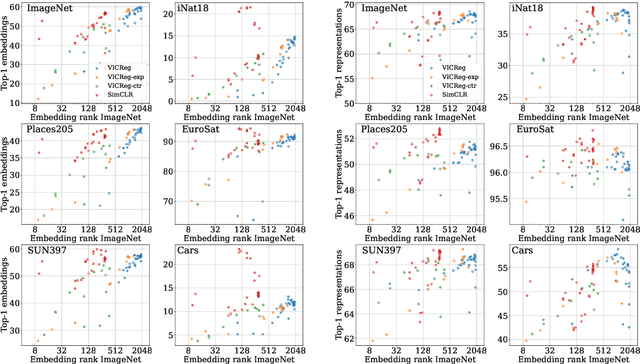
Joint-Embedding Self Supervised Learning (JE-SSL) has seen a rapid development, with the emergence of many method variations and few principled guidelines that would help practitioners to successfully deploy those methods. The main reason for that pitfall actually comes from JE-SSL's core principle of not employing any input reconstruction. Without any visual clue, it becomes extremely cryptic to judge the quality of a learned representation without having access to a labelled dataset. We hope to correct those limitations by providing a single -- theoretically motivated -- criterion that reflects the quality of learned JE-SSL representations: their effective rank. Albeit simple and computationally friendly, this method -- coined RankMe -- allows one to assess the performance of JE-SSL representations, even on different downstream datasets, without requiring any labels, training or parameters to tune. Through thorough empirical experiments involving hundreds of repeated training episodes, we demonstrate how RankMe can be used for hyperparameter selection with nearly no loss in final performance compared to the current selection method that involve dataset labels. We hope that RankMe will facilitate the use of JE-SSL in domains with little or no labeled data.
Variance Covariance Regularization Enforces Pairwise Independence in Self-Supervised Representations
Sep 29, 2022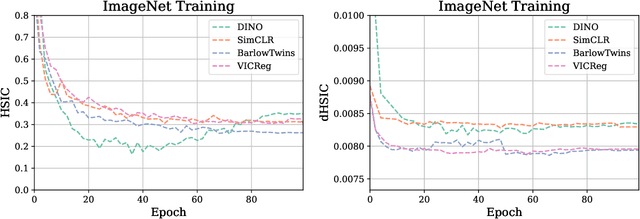
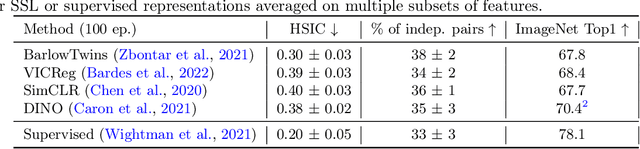
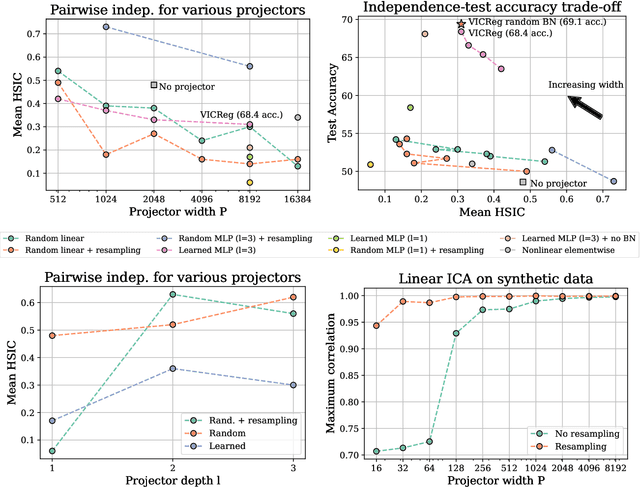

Self-Supervised Learning (SSL) methods such as VICReg, Barlow Twins or W-MSE avoid collapse of their joint embedding architectures by constraining or regularizing the covariance matrix of their projector's output. This study highlights important properties of such strategy, which we coin Variance-Covariance regularization (VCReg). More precisely, we show that VCReg enforces pairwise independence between the features of the learned representation. This result emerges by bridging VCReg applied on the projector's output to kernel independence criteria applied on the projector's input. This provides the first theoretical motivations and explanations of VCReg. We empirically validate our findings where (i) we observe that SSL methods employing VCReg learn visual representations with greater pairwise independence than other methods, (i) we put in evidence which projector's characteristics favor pairwise independence, and show it to emerge independently from learning the projector, (ii) we use these findings to obtain nontrivial performance gains for VICReg, (iii) we demonstrate that the scope of VCReg goes beyond SSL by using it to solve Independent Component Analysis. We hope that our findings will support the adoption of VCReg in SSL and beyond.
Joint Embedding Self-Supervised Learning in the Kernel Regime
Sep 29, 2022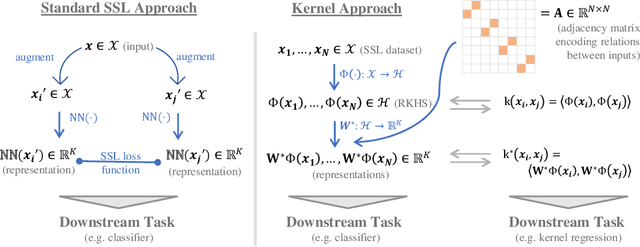
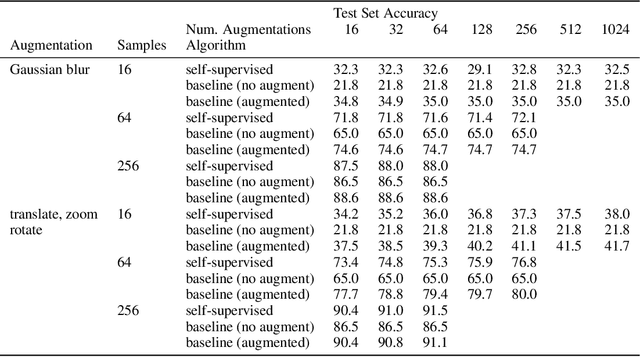
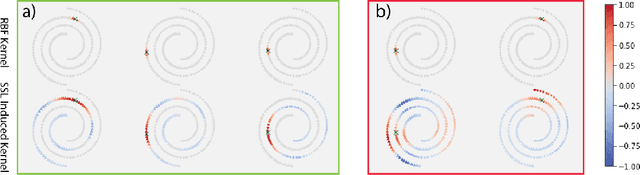
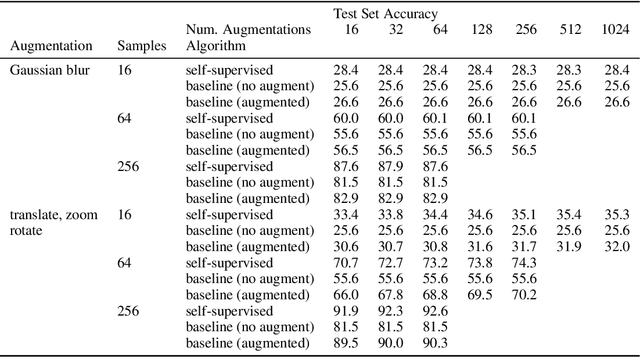
The fundamental goal of self-supervised learning (SSL) is to produce useful representations of data without access to any labels for classifying the data. Modern methods in SSL, which form representations based on known or constructed relationships between samples, have been particularly effective at this task. Here, we aim to extend this framework to incorporate algorithms based on kernel methods where embeddings are constructed by linear maps acting on the feature space of a kernel. In this kernel regime, we derive methods to find the optimal form of the output representations for contrastive and non-contrastive loss functions. This procedure produces a new representation space with an inner product denoted as the induced kernel which generally correlates points which are related by an augmentation in kernel space and de-correlates points otherwise. We analyze our kernel model on small datasets to identify common features of self-supervised learning algorithms and gain theoretical insights into their performance on downstream tasks.