 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoT-Guard: Small Models for Strong Monitoring
May 12, 2026Monitoring the chain-of-thought (CoT) of reasoning models is a promising approach for detecting covert misbehavior (i.e., hidden objectives) in code generation tasks. While large models (GPT-5, Gemini-3-Flash) can serve as effective CoT monitors, they are expensive to deploy due to the lengthy reasoning traces and high API cost, emphasizing the need for smaller, cheaper alternatives. Nevertheless, we find that current small models (4B--8B) struggle to detect hidden objectives despite access to the CoT, frequently misattributing them as part of the user query. To address this, we propose a post-training pipeline combining supervised fine-tuning (SFT) and reinforcement learning (RL), where SFT narrows the gap for in-domain tasks by distilling detection behavior from stronger monitors, and RL on hard and subtly crafted hidden objectives helps the model generalize to out-of-domain monitoring tasks. To validate this generalization, we evaluate under a realistic threat model motivated by practical supply-chain attacks, where the adversary is a third-party LLM router injecting hidden objectives into code-generation requests through either prompt manipulation or code manipulation attacks. To push beyond objectives that large monitors already saturate, we also introduce four new challenging tasks even for strong monitors. Finally, we introduce CoT-Guard, a 4B-parameter monitor that demonstrates superior generalization performance under both prompt and code manipulation attacks, achieving a G-mean^2 (i.e., TNR x TPR) of 75% and outperforming GPT-5.4 (56%), GPT-5-mini (41%), and Qwen3-32B (54%), while closing the gap to Gemini-3-Flash (83%). These results demonstrate that CoT-Guard provides a practical and cost-effective user-side defense, substantially improving hidden-objective detection while avoiding the deployment cost of large monitors.
On the application of transfer learning in prognostics and health management
Jul 03, 2020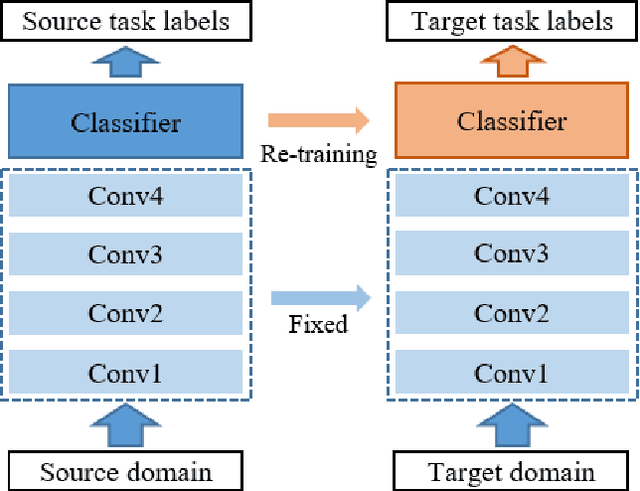
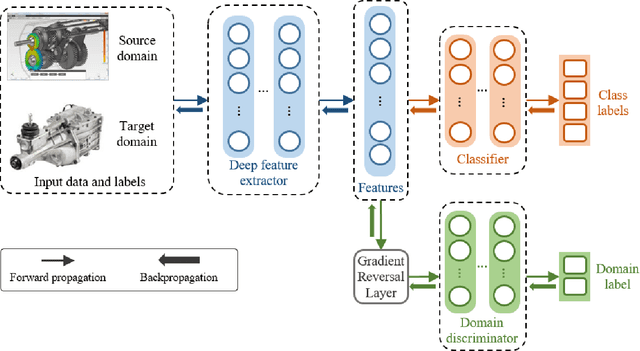
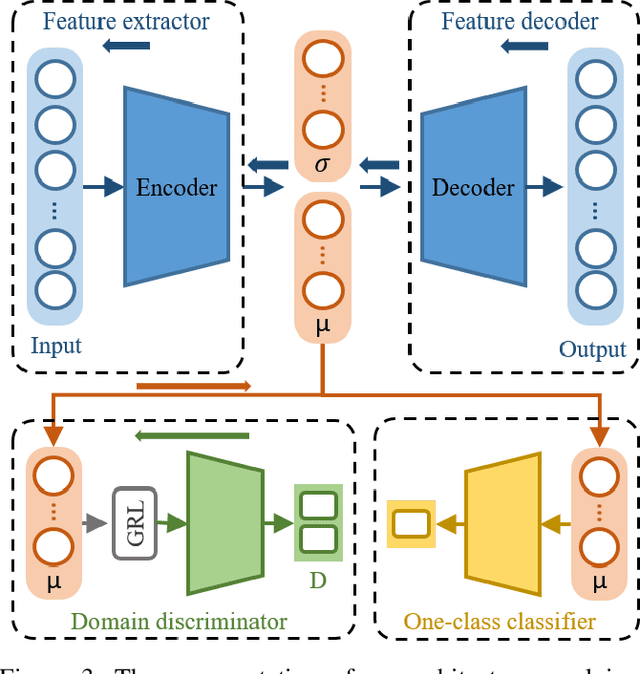
Advancements in sensing and computing technologies, the development of human and computer interaction frameworks, big data storage capabilities, and the emergence of cloud storage and could computing have resulted in an abundance of data in the modern industry. This data availability has encouraged researchers and industry practitioners to rely on data-based machine learning, especially deep learning, models for fault diagnostics and prognostics more than ever. These models provide unique advantages, however, their performance is heavily dependent on the training data and how well that data represents the test data. This issue mandates fine-tuning and even training the models from scratch when there is a slight change in operating conditions or equipment. Transfer learning is an approach that can remedy this issue by keeping portions of what is learned from previous training and transferring them to the new application. In this paper, a unified definition for transfer learning and its different types is provided, Prognostics and Health Management (PHM) studies that have used transfer learning are reviewed in detail, and finally, a discussion on transfer learning application considerations and gaps is provided for improving the applicability of transfer learning in PHM.