 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-Locate-News: Multimodal Focus Location Estimation in News
Nov 15, 2022



The consumption of news has changed significantly as the Web has become the most influential medium for information. To analyze and contextualize the large amount of news published every day, the geographic focus of an article is an important aspect in order to enable content-based news retrieval. There are methods and datasets for geolocation estimation from text or photos, but they are typically considered as separate tasks. However, the photo might lack geographical cues and text can include multiple locations, making it challenging to recognize the focus location using a single modality. In this paper, a novel dataset called Multimodal Focus Location of News (MM-Locate-News) is introduced. We evaluate state-of-the-art methods on the new benchmark dataset and suggest novel models to predict the focus location of news using both textual and image content. The experimental results show that the multimodal model outperforms unimodal models.
SoccerNet 2022 Challenges Results
Oct 05, 2022
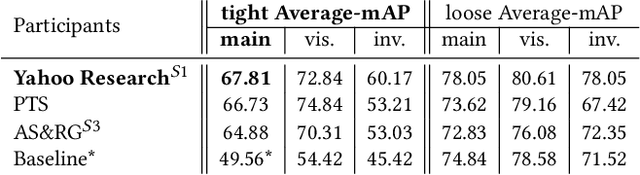
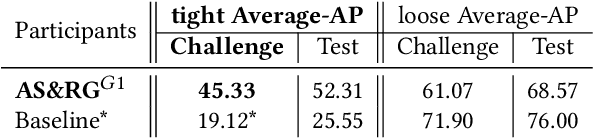
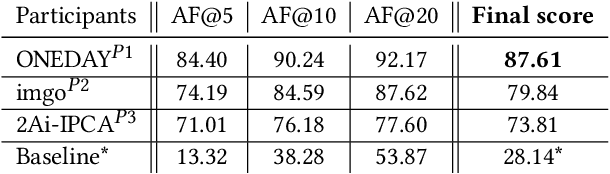
The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.
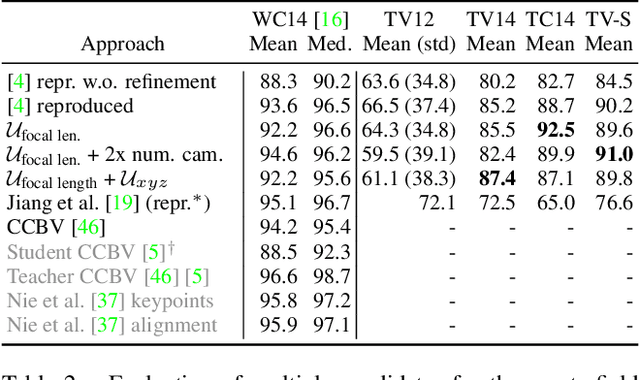
Keypoint-less Camera Calibration for Sports Field Registration in Soccer
Jul 24, 2022
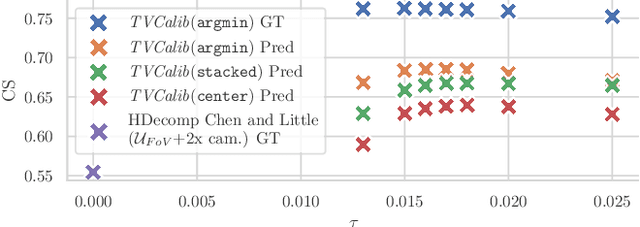
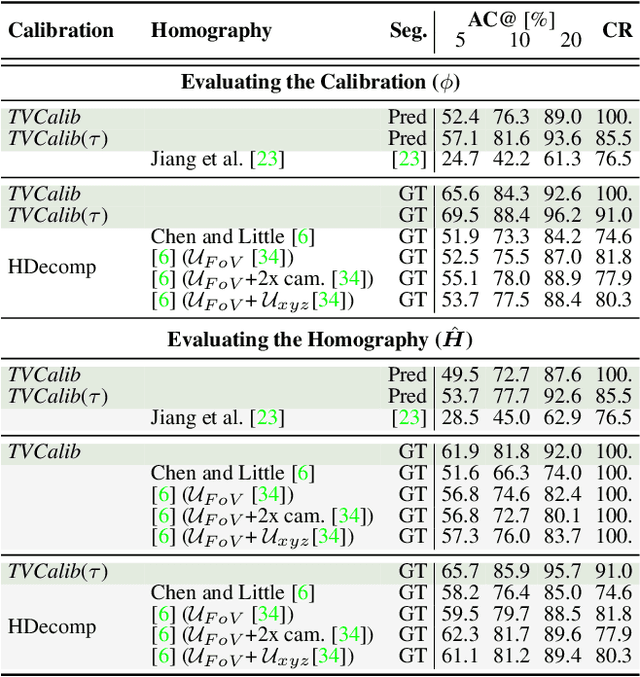
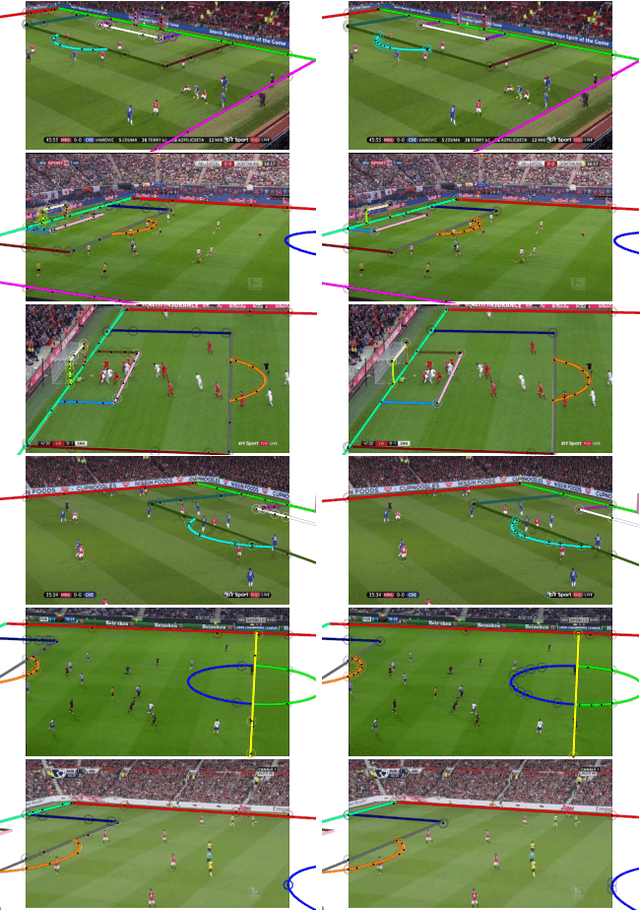
Sports field registration in broadcast videos is typically interpreted as the task of homography estimation, which provides a mapping between a planar field and the corresponding visible area of the image. In contrast to previous approaches, we consider the task as a camera calibration problem. First, we introduce a differentiable objective function that is able to learn the camera pose and focal length from segment correspondences (e.g., lines, point clouds), based on pixel-level annotations for segments of a known calibration object, i.e., the sports field. The calibration module iteratively minimizes the segment reprojection error induced by the estimated camera parameters. Second, we propose a novel approach for 3D sports field registration from broadcast soccer images. The calibration module does not require any training data and compared to the typical solution, which subsequently refines an initial estimation, our solution does it in one step. The proposed method is evaluated for sports field registration on two datasets and achieves superior results compared to two state-of-the-art approaches.
Semi-supervised Human Pose Estimation in Art-historical Images
Jul 11, 2022
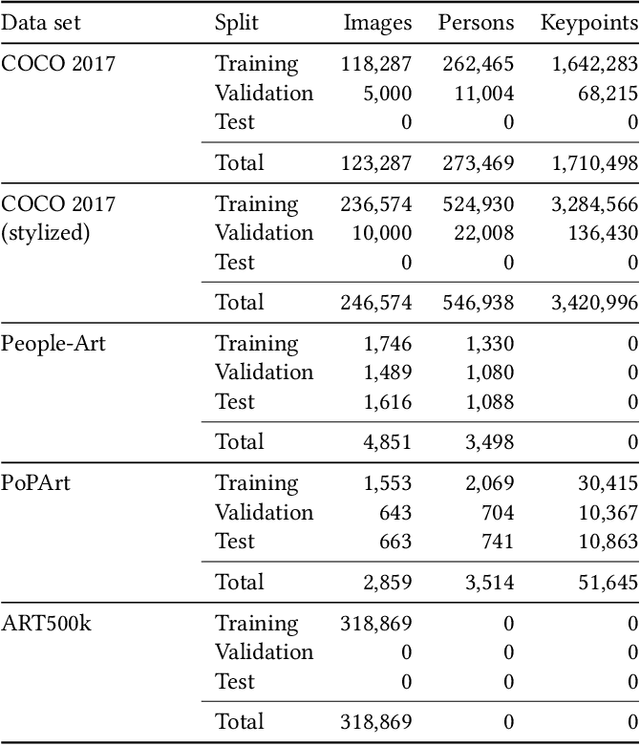
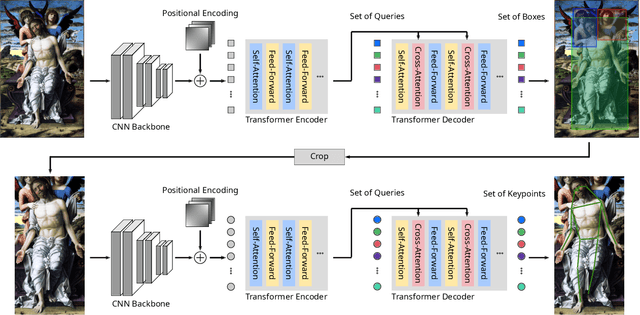
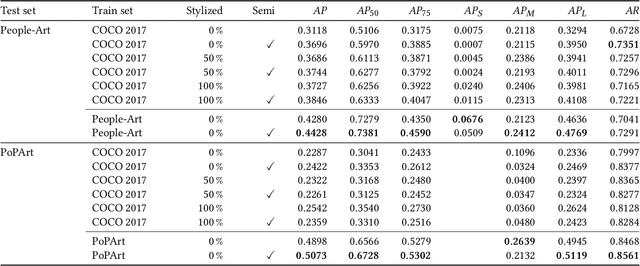
Gesture as language of non-verbal communication has been theoretically established since the 17th century. However, its relevance for the visual arts has been expressed only sporadically. This may be primarily due to the sheer overwhelming amount of data that traditionally had to be processed by hand. With the steady progress of digitization, though, a growing number of historical artifacts have been indexed and made available to the public, creating a need for automatic retrieval of art-historical motifs with similar body constellations or poses. Since the domain of art differs significantly from existing real-world data sets for human pose estimation due to its style variance, this presents new challenges. In this paper, we propose a novel approach to estimate human poses in art-historical images. In contrast to previous work that attempts to bridge the domain gap with pre-trained models or through style transfer, we suggest semi-supervised learning for both object and keypoint detection. Furthermore, we introduce a novel domain-specific art data set that includes both bounding box and keypoint annotations of human figures. Our approach achieves significantly better results than methods that use pre-trained models or style transfer.
MM-Claims: A Dataset for Multimodal Claim Detection in Social Media
May 04, 2022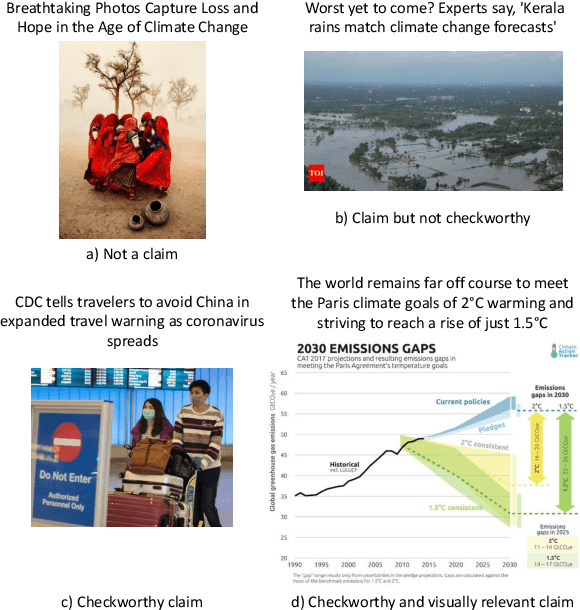
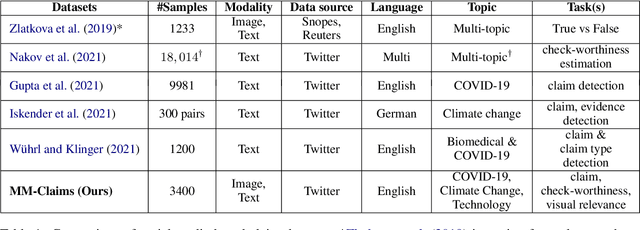
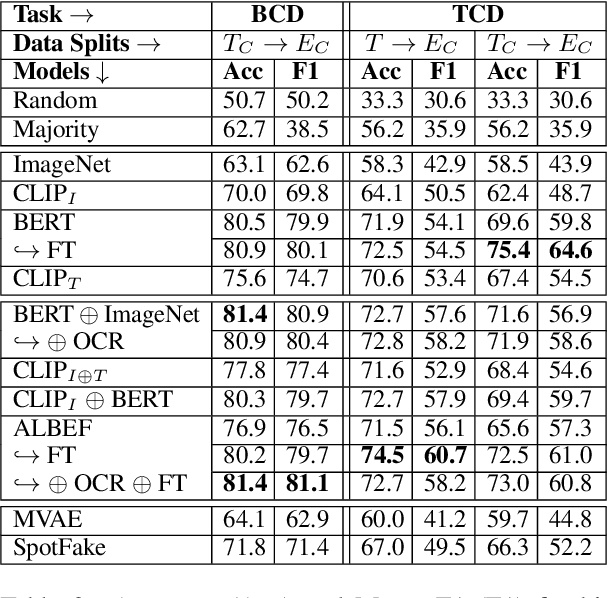
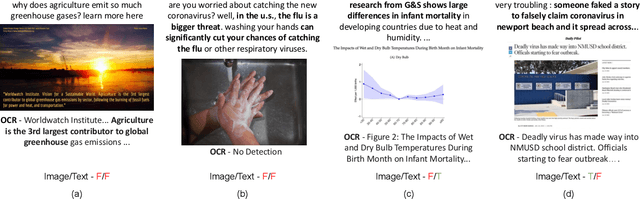
In recent years, the problem of misinformation on the web has become widespread across languages, countries, and various social media platforms. Although there has been much work on automated fake news detection, the role of images and their variety are not well explored. In this paper, we investigate the roles of image and text at an earlier stage of the fake news detection pipeline, called claim detection. For this purpose, we introduce a novel dataset, MM-Claims, which consists of tweets and corresponding images over three topics: COVID-19, Climate Change and broadly Technology. The dataset contains roughly 86000 tweets, out of which 3400 are labeled manually by multiple annotators for the training and evaluation of multimodal models. We describe the dataset in detail, evaluate strong unimodal and multimodal baselines, and analyze the potential and drawbacks of current models.
TIB-VA at SemEval-2022 Task 5: A Multimodal Architecture for the Detection and Classification of Misogynous Memes
Apr 13, 2022

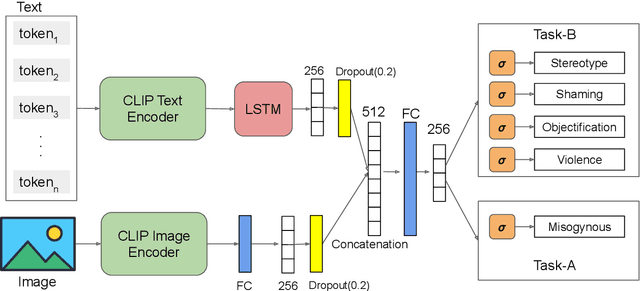
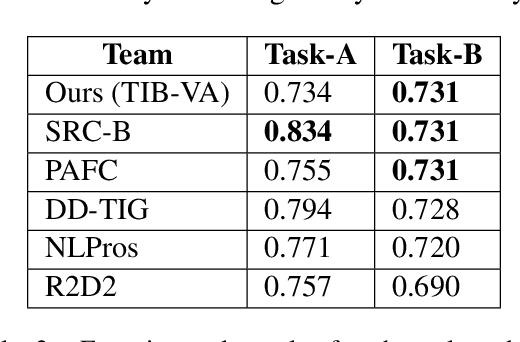
The detection of offensive, hateful content on social media is a challenging problem that affects many online users on a daily basis. Hateful content is often used to target a group of people based on ethnicity, gender, religion and other factors. The hate or contempt toward women has been increasing on social platforms. Misogynous content detection is especially challenging when textual and visual modalities are combined to form a single context, e.g., an overlay text embedded on top of an image, also known as meme. In this paper, we present a multimodal architecture that combines textual and visual features in order to detect misogynous meme content. The proposed architecture is evaluated in the SemEval-2022 Task 5: MAMI - Multimedia Automatic Misogyny Identification challenge under the team name TIB-VA. Our solution obtained the best result in the Task-B where the challenge is to classify whether a given document is misogynous and further identify the main sub-classes of shaming, stereotype, objectification, and violence.
SaL-Lightning Dataset: Search and Eye Gaze Behavior, Resource Interactions and Knowledge Gain during Web Search
Jan 07, 2022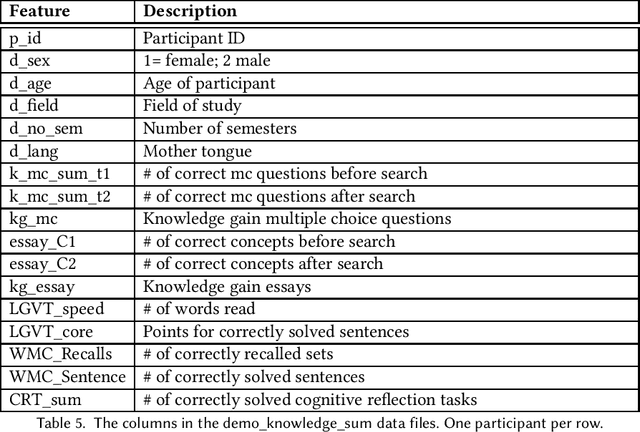
The emerging research field Search as Learning investigates how the Web facilitates learning through modern information retrieval systems. SAL research requires significant amounts of data that capture both search behavior of users and their acquired knowledge in order to obtain conclusive insights or train supervised machine learning models. However, the creation of such datasets is costly and requires interdisciplinary efforts in order to design studies and capture a wide range of features. In this paper, we address this issue and introduce an extensive dataset based on a user study, in which $114$ participants were asked to learn about the formation of lightning and thunder. Participants' knowledge states were measured before and after Web search through multiple-choice questionnaires and essay-based free recall tasks. To enable future research in SAL-related tasks we recorded a plethora of features and person-related attributes. Besides the screen recordings, visited Web pages, and detailed browsing histories, a large number of behavioral features and resource features were monitored. We underline the usefulness of the dataset by describing three, already published, use cases.
Combining Textual Features for the Detection of Hateful and Offensive Language
Dec 09, 2021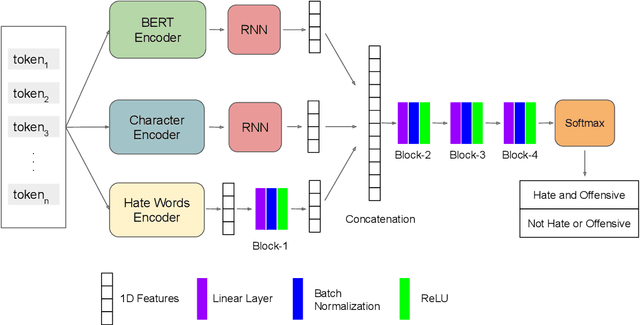
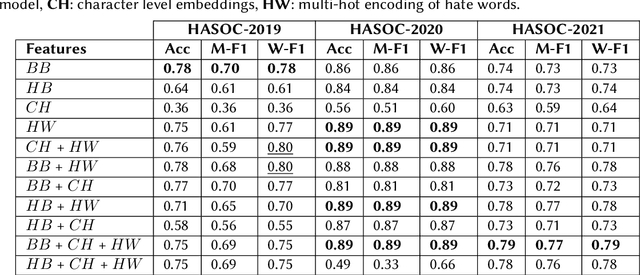
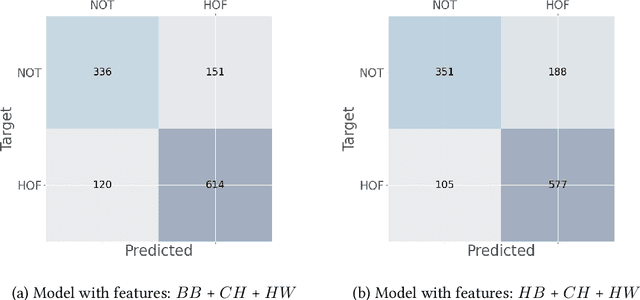
The detection of offensive, hateful and profane language has become a critical challenge since many users in social networks are exposed to cyberbullying activities on a daily basis. In this paper, we present an analysis of combining different textual features for the detection of hateful or offensive posts on Twitter. We provide a detailed experimental evaluation to understand the impact of each building block in a neural network architecture. The proposed architecture is evaluated on the English Subtask 1A: Identifying Hate, offensive and profane content from the post datasets of HASOC-2021 dataset under the team name TIB-VA. We compared different variants of the contextual word embeddings combined with the character level embeddings and the encoding of collected hate terms.
Extraction of Positional Player Data from Broadcast Soccer Videos
Oct 21, 2021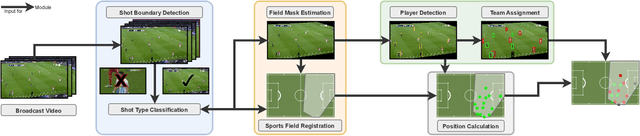

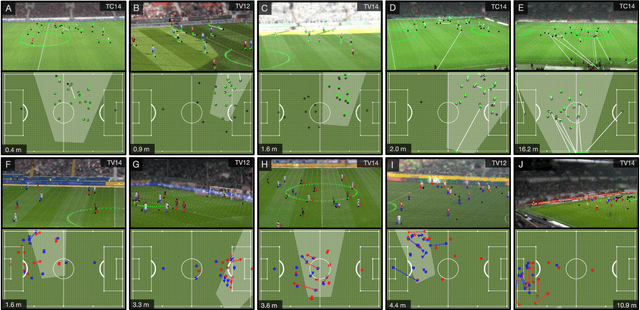
Computer-aided support and analysis are becoming increasingly important in the modern world of sports. The scouting of potential prospective players, performance as well as match analysis, and the monitoring of training programs rely more and more on data-driven technologies to ensure success. Therefore, many approaches require large amounts of data, which are, however, not easy to obtain in general. In this paper, we propose a pipeline for the fully-automated extraction of positional data from broadcast video recordings of soccer matches. In contrast to previous work, the system integrates all necessary sub-tasks like sports field registration, player detection, or team assignment that are crucial for player position estimation. The quality of the modules and the entire system is interdependent. A comprehensive experimental evaluation is presented for the individual modules as well as the entire pipeline to identify the influence of errors to subsequent modules and the overall result. In this context, we propose novel evaluation metrics to compare the output with ground-truth positional data.
A Unified Taxonomy and Multimodal Dataset for Events in Invasion Games
Aug 26, 2021
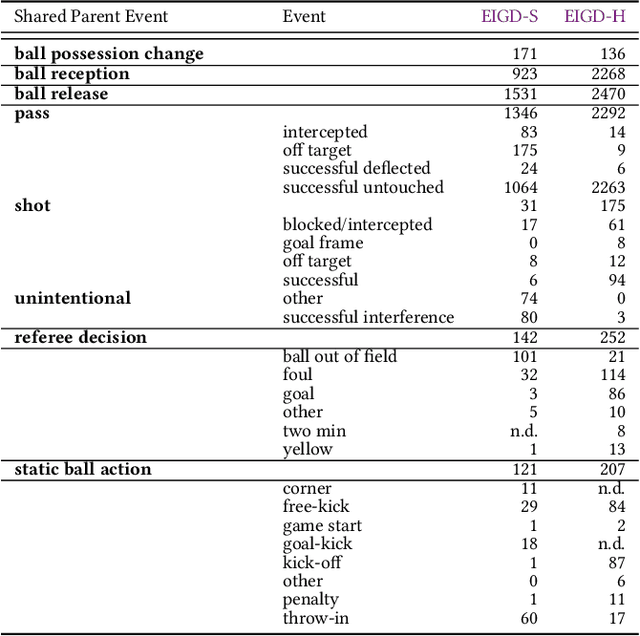
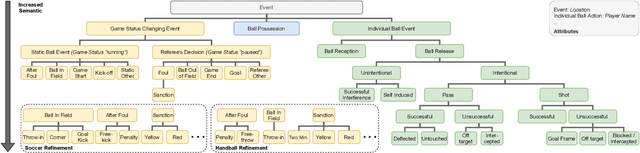

The automatic detection of events in complex sports games like soccer and handball using positional or video data is of large interest in research and industry. One requirement is a fundamental understanding of underlying concepts, i.e., events that occur on the pitch. Previous work often deals only with so-called low-level events based on well-defined rules such as free kicks, free throws, or goals. High-level events, such as passes, are less frequently approached due to a lack of consistent definitions. This introduces a level of ambiguity that necessities careful validation when regarding event annotations. Yet, this validation step is usually neglected as the majority of studies adopt annotations from commercial providers on private datasets of unknown quality and focuses on soccer only. To address these issues, we present (1) a universal taxonomy that covers a wide range of low and high-level events for invasion games and is exemplarily refined to soccer and handball, and (2) release two multi-modal datasets comprising video and positional data with gold-standard annotations to foster research in fine-grained and ball-centered event spotting. Experiments on human performance demonstrate the robustness of the proposed taxonomy, and that disagreements and ambiguities in the annotation increase with the complexity of the event. An I3D model for video classification is adopted for event spotting and reveals the potential for benchmarking. Datasets are available at: https://github.com/mm4spa/eigd