 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Interpretable Information Retrieval for Product Question Answering with Heterogeneous Data
May 21, 2024



Expansion-enhanced sparse lexical representation improves information retrieval (IR) by minimizing vocabulary mismatch problems during lexical matching. In this paper, we explore the potential of jointly learning dense semantic representation and combining it with the lexical one for ranking candidate information. We present a hybrid information retrieval mechanism that maximizes lexical and semantic matching while minimizing their shortcomings. Our architecture consists of dual hybrid encoders that independently encode queries and information elements. Each encoder jointly learns a dense semantic representation and a sparse lexical representation augmented by a learnable term expansion of the corresponding text through contrastive learning. We demonstrate the efficacy of our model in single-stage ranking of a benchmark product question-answering dataset containing the typical heterogeneous information available on online product pages. Our evaluation demonstrates that our hybrid approach outperforms independently trained retrievers by 10.95% (sparse) and 2.7% (dense) in MRR@5 score. Moreover, our model offers better interpretability and performs comparably to state-of-the-art cross encoders while reducing response time by 30% (latency) and cutting computational load by approximately 38% (FLOPs).
Masked LoGoNet: Fast and Accurate 3D Image Analysis for Medical Domain
Feb 09, 2024



Standard modern machine-learning-based imaging methods have faced challenges in medical applications due to the high cost of dataset construction and, thereby, the limited labeled training data available. Additionally, upon deployment, these methods are usually used to process a large volume of data on a daily basis, imposing a high maintenance cost on medical facilities. In this paper, we introduce a new neural network architecture, termed LoGoNet, with a tailored self-supervised learning (SSL) method to mitigate such challenges. LoGoNet integrates a novel feature extractor within a U-shaped architecture, leveraging Large Kernel Attention (LKA) and a dual encoding strategy to capture both long-range and short-range feature dependencies adeptly. This is in contrast to existing methods that rely on increasing network capacity to enhance feature extraction. This combination of novel techniques in our model is especially beneficial in medical image segmentation, given the difficulty of learning intricate and often irregular body organ shapes, such as the spleen. Complementary, we propose a novel SSL method tailored for 3D images to compensate for the lack of large labeled datasets. The method combines masking and contrastive learning techniques within a multi-task learning framework and is compatible with both Vision Transformer (ViT) and CNN-based models. We demonstrate the efficacy of our methods in numerous tasks across two standard datasets (i.e., BTCV and MSD). Benchmark comparisons with eight state-of-the-art models highlight LoGoNet's superior performance in both inference time and accuracy.
CrashFormer: A Multimodal Architecture to Predict the Risk of Crash
Feb 07, 2024



Reducing traffic accidents is a crucial global public safety concern. Accident prediction is key to improving traffic safety, enabling proactive measures to be taken before a crash occurs, and informing safety policies, regulations, and targeted interventions. Despite numerous studies on accident prediction over the past decades, many have limitations in terms of generalizability, reproducibility, or feasibility for practical use due to input data or problem formulation. To address existing shortcomings, we propose CrashFormer, a multi-modal architecture that utilizes comprehensive (but relatively easy to obtain) inputs such as the history of accidents, weather information, map images, and demographic information. The model predicts the future risk of accidents on a reasonably acceptable cadence (i.e., every six hours) for a geographical location of 5.161 square kilometers. CrashFormer is composed of five components: a sequential encoder to utilize historical accidents and weather data, an image encoder to use map imagery data, a raw data encoder to utilize demographic information, a feature fusion module for aggregating the encoded features, and a classifier that accepts the aggregated data and makes predictions accordingly. Results from extensive real-world experiments in 10 major US cities show that CrashFormer outperforms state-of-the-art sequential and non-sequential models by 1.8% in F1-score on average when using ``sparse'' input data.
Novel Physics-Based Machine-Learning Models for Indoor Air Quality Approximations
Aug 02, 2023



Cost-effective sensors are capable of real-time capturing a variety of air quality-related modalities from different pollutant concentrations to indoor/outdoor humidity and temperature. Machine learning (ML) models are capable of performing air-quality "ahead-of-time" approximations. Undoubtedly, accurate indoor air quality approximation significantly helps provide a healthy indoor environment, optimize associated energy consumption, and offer human comfort. However, it is crucial to design an ML architecture to capture the domain knowledge, so-called problem physics. In this study, we propose six novel physics-based ML models for accurate indoor pollutant concentration approximations. The proposed models include an adroit combination of state-space concepts in physics, Gated Recurrent Units, and Decomposition techniques. The proposed models were illustrated using data collected from five offices in a commercial building in California. The proposed models are shown to be less complex, computationally more efficient, and more accurate than similar state-of-the-art transformer-based models. The superiority of the proposed models is due to their relatively light architecture (computational efficiency) and, more importantly, their ability to capture the underlying highly nonlinear patterns embedded in the often contaminated sensor-collected indoor air quality temporal data.
Judge Me in Context: A Telematics-Based Driving Risk Prediction Framework in Presence of Weak Risk Labels
May 05, 2023



Driving risk prediction has been a topic of much research over the past few decades to minimize driving risk and increase safety. The use of demographic information in risk prediction is a traditional solution with applications in insurance planning, however, it is difficult to capture true driving behavior via such coarse-grained factors. Therefor, the use of telematics data has gained a widespread popularity over the past decade. While most of the existing studies leverage demographic information in addition to telematics data, our objective is to maximize the use of telematics as well as contextual information (e.g., road-type) to build a risk prediction framework with real-world applications. We contextualize telematics data in a variety of forms, and then use it to develop a risk classifier, assuming that there are some weak risk labels available (e.g., past traffic citation records). Before building a risk classifier though, we employ a novel data-driven process to augment weak risk labels. Extensive analysis and results based on real-world data from multiple major cities in the United States demonstrate usefulness of the proposed framework.
Will there be a construction? Predicting road constructions based on heterogeneous spatiotemporal data
Sep 14, 2022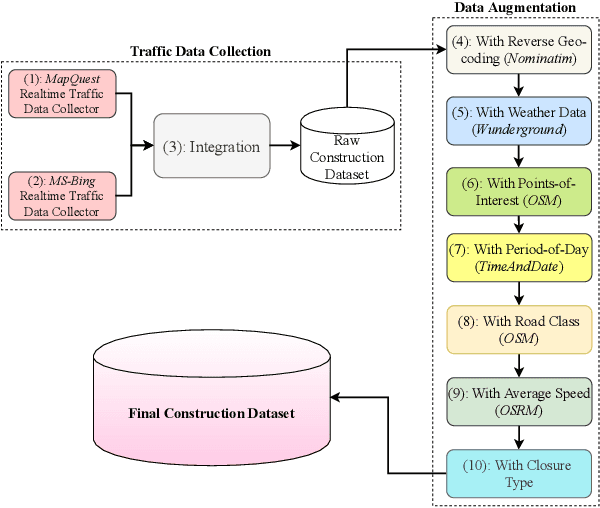
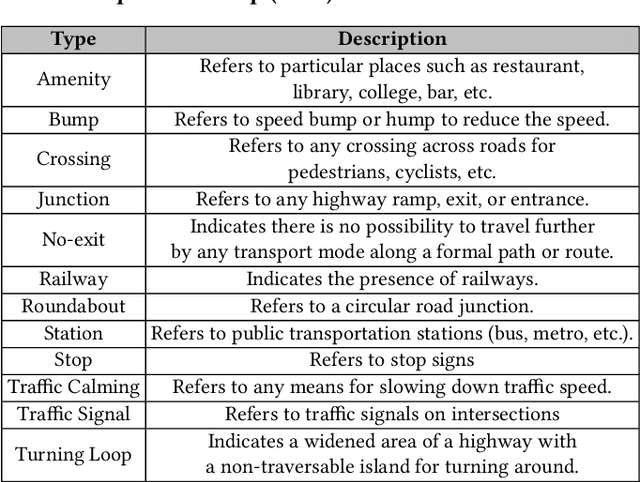
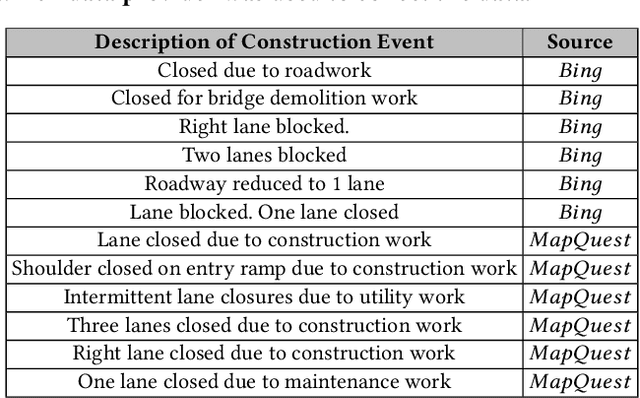
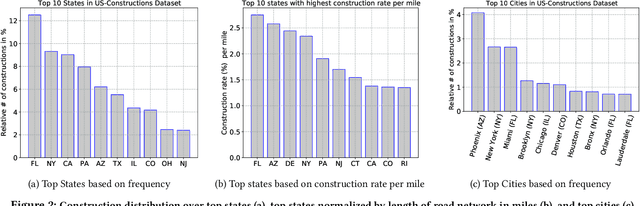
Road construction projects maintain transportation infrastructures. These projects range from the short-term (e.g., resurfacing or fixing potholes) to the long-term (e.g., adding a shoulder or building a bridge). Deciding what the next construction project is and when it is to be scheduled is traditionally done through inspection by humans using special equipment. This approach is costly and difficult to scale. An alternative is the use of computational approaches that integrate and analyze multiple types of past and present spatiotemporal data to predict location and time of future road constructions. This paper reports on such an approach, one that uses a deep-neural-network-based model to predict future constructions. Our model applies both convolutional and recurrent components on a heterogeneous dataset consisting of construction, weather, map and road-network data. We also report on how we addressed the lack of adequate publicly available data - by building a large scale dataset named "US-Constructions", that includes 6.2 million cases of road constructions augmented by a variety of spatiotemporal attributes and road-network features, collected in the contiguous United States (US) between 2016 and 2021. Using extensive experiments on several major cities in the US, we show the applicability of our work in accurately predicting future constructions - an average f1-score of 0.85 and accuracy 82.2% - that outperform baselines. Additionally, we show how our training pipeline addresses spatial sparsity of data.
Scalable Deep Graph Clustering with Random-walk based Self-supervised Learning
Dec 31, 2021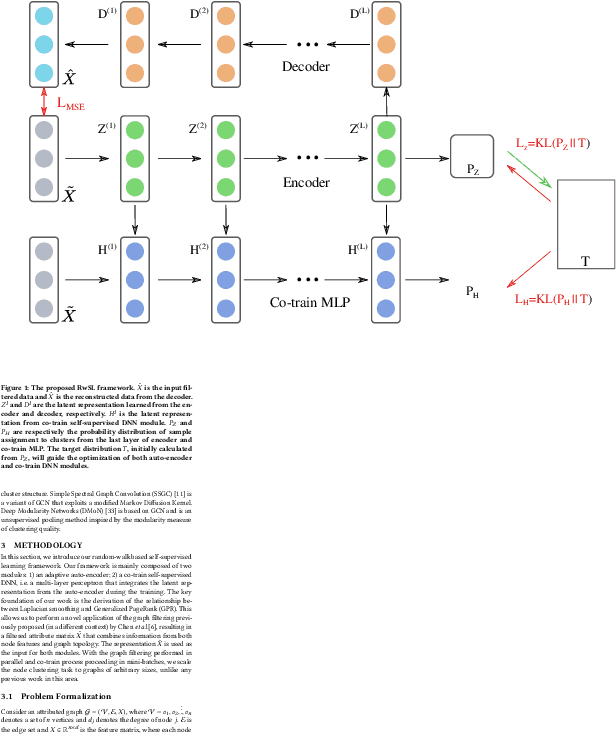

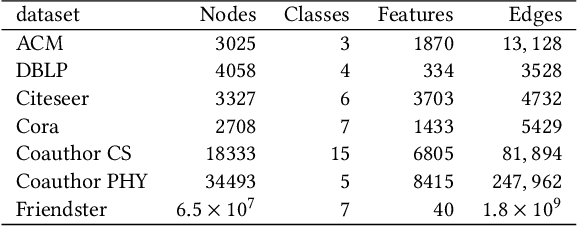
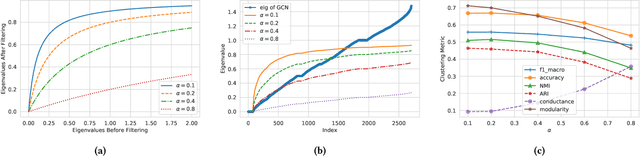
Web-based interactions can be frequently represented by an attributed graph, and node clustering in such graphs has received much attention lately. Multiple efforts have successfully applied Graph Convolutional Networks (GCN), though with some limits on accuracy as GCNs have been shown to suffer from over-smoothing issues. Though other methods (particularly those based on Laplacian Smoothing) have reported better accuracy, a fundamental limitation of all the work is a lack of scalability. This paper addresses this open problem by relating the Laplacian smoothing to the Generalized PageRank and applying a random-walk based algorithm as a scalable graph filter. This forms the basis for our scalable deep clustering algorithm, RwSL, where through a self-supervised mini-batch training mechanism, we simultaneously optimize a deep neural network for sample-cluster assignment distribution and an autoencoder for a clustering-oriented embedding. Using 6 real-world datasets and 6 clustering metrics, we show that RwSL achieved improved results over several recent baselines. Most notably, we show that RwSL, unlike all other deep clustering frameworks, can continue to scale beyond graphs with more than one million nodes, i.e., handle web-scale. We also demonstrate how RwSL could perform node clustering on a graph with 1.8 billion edges using only a single GPU.
Driving Style Representation in Convolutional Recurrent Neural Network Model of Driver Identification
Feb 11, 2021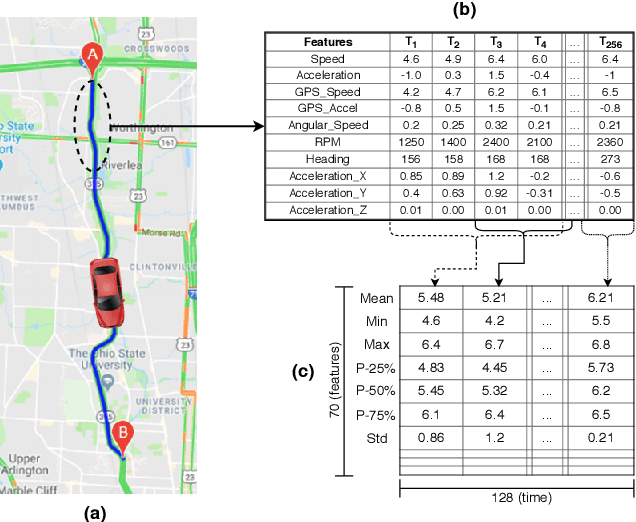
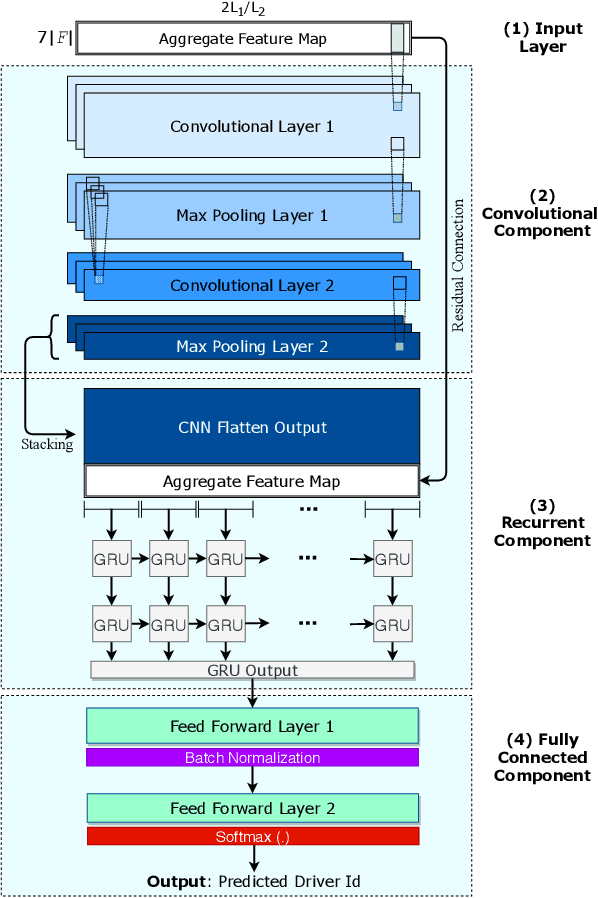
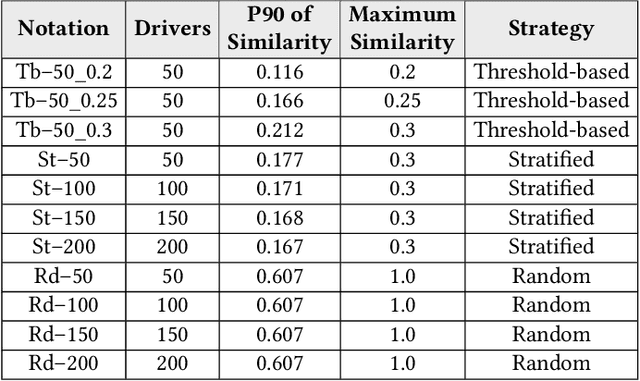
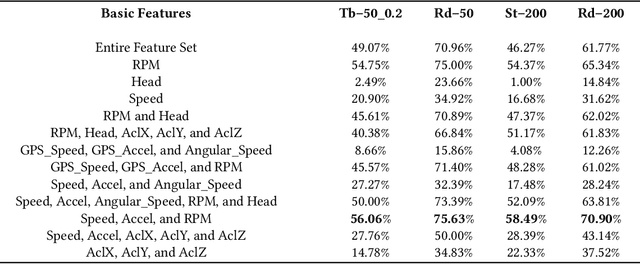
Identifying driving styles is the task of analyzing the behavior of drivers in order to capture variations that will serve to discriminate different drivers from each other. This task has become a prerequisite for a variety of applications, including usage-based insurance, driver coaching, driver action prediction, and even in designing autonomous vehicles; because driving style encodes essential information needed by these applications. In this paper, we present a deep-neural-network architecture, we term D-CRNN, for building high-fidelity representations for driving style, that combine the power of convolutional neural networks (CNN) and recurrent neural networks (RNN). Using CNN, we capture semantic patterns of driver behavior from trajectories (such as a turn or a braking event). We then find temporal dependencies between these semantic patterns using RNN to encode driving style. We demonstrate the effectiveness of these techniques for driver identification by learning driving style through extensive experiments conducted on several large, real-world datasets, and comparing the results with the state-of-the-art deep-learning and non-deep-learning solutions. These experiments also demonstrate a useful example of bias removal, by presenting how we preprocess the input data by sampling dissimilar trajectories for each driver to prevent spatial memorization. Finally, this paper presents an analysis of the contribution of different attributes for driver identification; we find that engine RPM, Speed, and Acceleration are the best combination of features.
Sequence-to-Set Semantic Tagging: End-to-End Multi-label Prediction using Neural Attention for Complex Query Reformulation and Automated Text Categorization
Nov 11, 2019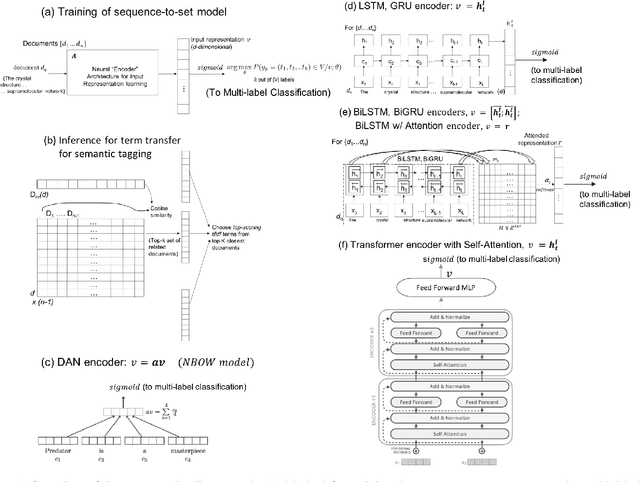

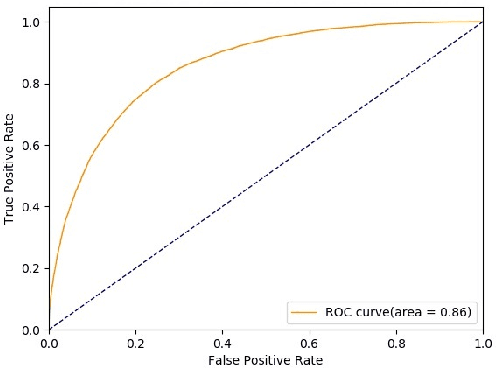
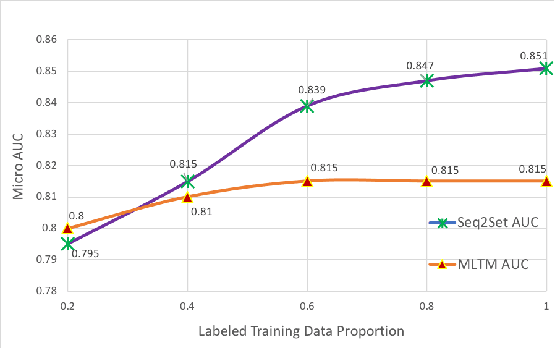
Novel contexts may often arise in complex querying scenarios such as in evidence-based medicine (EBM) involving biomedical literature, that may not explicitly refer to entities or canonical concept forms occurring in any fact- or rule-based knowledge source such as an ontology like the UMLS. Moreover, hidden associations between candidate concepts meaningful in the current context, may not exist within a single document, but within the collection, via alternate lexical forms. Therefore, inspired by the recent success of sequence-to-sequence neural models in delivering the state-of-the-art in a wide range of NLP tasks, we develop a novel sequence-to-set framework with neural attention for learning document representations that can effect term transfer within the corpus, for semantically tagging a large collection of documents. We demonstrate that our proposed method can be effective in both a supervised multi-label classification setup for text categorization, as well as in a unique unsupervised setting with no human-annotated document labels that uses no external knowledge resources and only corpus-derived term statistics to drive the training. Further, we show that semi-supervised training using our architecture on large amounts of unlabeled data can augment performance on the text categorization task when limited labeled data is available. Our approach to generate document encodings employing our sequence-to-set models for inference of semantic tags, gives to the best of our knowledge, the state-of-the-art for both, the unsupervised query expansion task for the TREC CDS 2016 challenge dataset when evaluated on an Okapi BM25--based document retrieval system; and also over the MLTM baseline (Soleimani et al, 2016), for both supervised and semi-supervised multi-label prediction tasks on the del.icio.us and Ohsumed datasets. We will make our code and data publicly available.
Towards Successful Social Media Advertising: Predicting the Influence of Commercial Tweets
Oct 28, 2019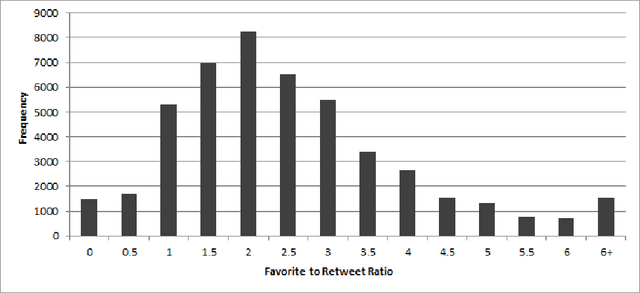
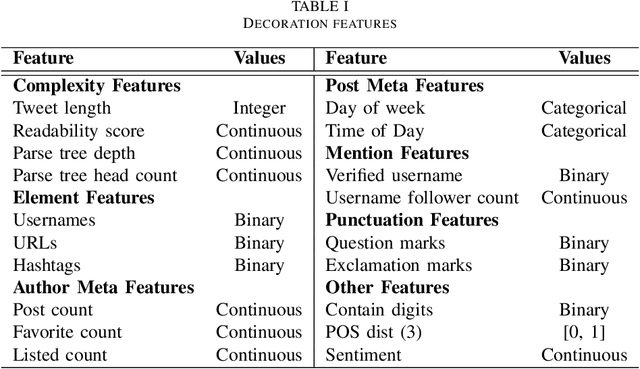
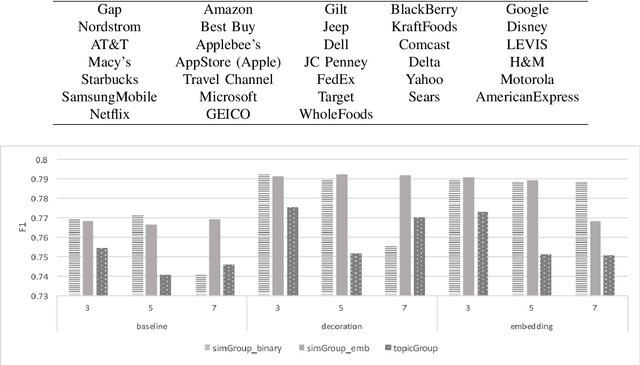
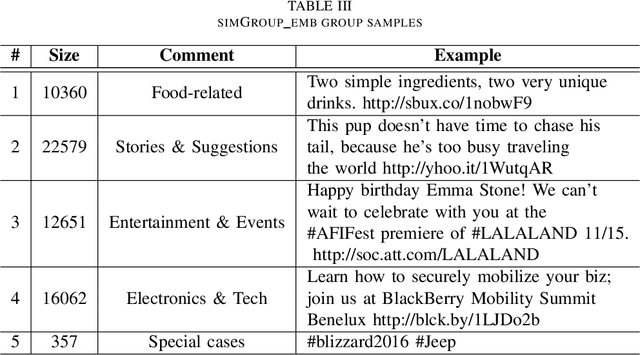
Businesses communicate using Twitter for a variety of reasons -- to raise awareness of their brands, to market new products, to respond to community comments, and to connect with their customers and potential customers in a targeted manner. For businesses to do this effectively, they need to understand which content and structural elements about a tweet make it influential, that is, widely liked, followed, and retweeted. This paper presents a systematic methodology for analyzing commercial tweets, and predicting the influence on their readers. Our model, which use a combination of decoration and meta features, outperforms the prediction ability of the baseline model as well as the tweet embedding model. Further, in order to demonstrate a practical use of this work, we show how an unsuccessful tweet may be engineered (for example, reworded) to increase its potential for success.