 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperFace: A Deep Multi-task Learning Framework for Face Detection, Landmark Localization, Pose Estimation, and Gender Recognition
Dec 06, 2017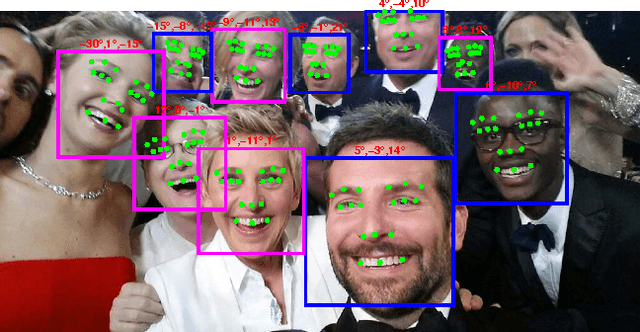
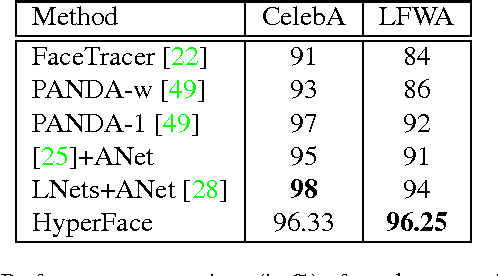
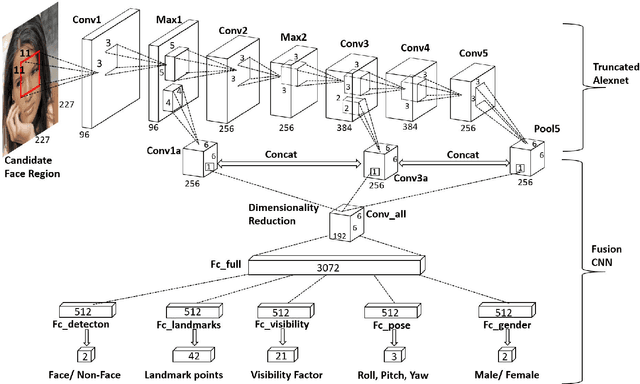

We present an algorithm for simultaneous face detection, landmarks localization, pose estimation and gender recognition using deep convolutional neural networks (CNN). The proposed method called, HyperFace, fuses the intermediate layers of a deep CNN using a separate CNN followed by a multi-task learning algorithm that operates on the fused features. It exploits the synergy among the tasks which boosts up their individual performances. Additionally, we propose two variants of HyperFace: (1) HyperFace-ResNet that builds on the ResNet-101 model and achieves significant improvement in performance, and (2) Fast-HyperFace that uses a high recall fast face detector for generating region proposals to improve the speed of the algorithm. Extensive experiments show that the proposed models are able to capture both global and local information in faces and performs significantly better than many competitive algorithms for each of these four tasks.
The Do's and Don'ts for CNN-based Face Verification
Sep 06, 2017
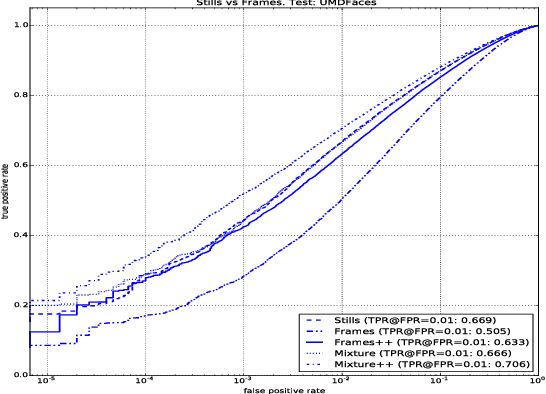
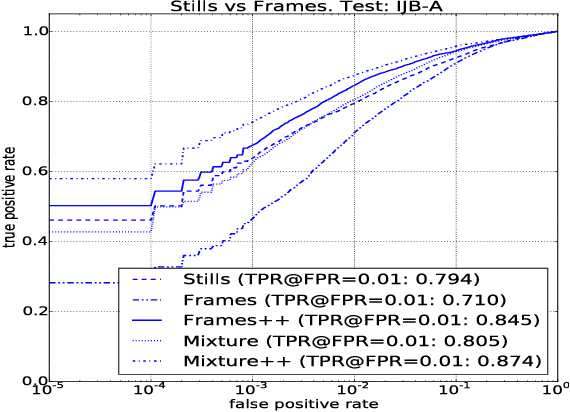
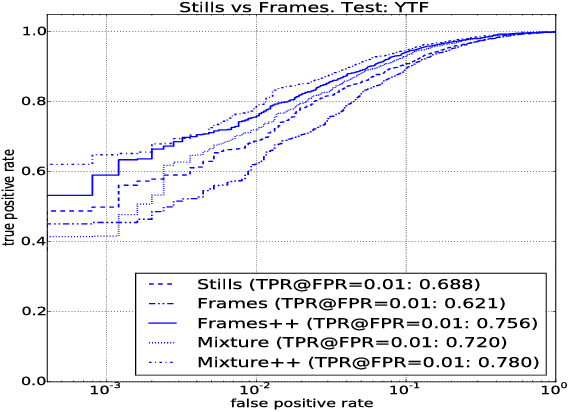
While the research community appears to have developed a consensus on the methods of acquiring annotated data, design and training of CNNs, many questions still remain to be answered. In this paper, we explore the following questions that are critical to face recognition research: (i) Can we train on still images and expect the systems to work on videos? (ii) Are deeper datasets better than wider datasets? (iii) Does adding label noise lead to improvement in performance of deep networks? (iv) Is alignment needed for face recognition? We address these questions by training CNNs using CASIA-WebFace, UMDFaces, and a new video dataset and testing on YouTube- Faces, IJB-A and a disjoint portion of UMDFaces datasets. Our new data set, which will be made publicly available, has 22,075 videos and 3,735,476 human annotated frames extracted from them.
Unconstrained Still/Video-Based Face Verification with Deep Convolutional Neural Networks
Jul 18, 2017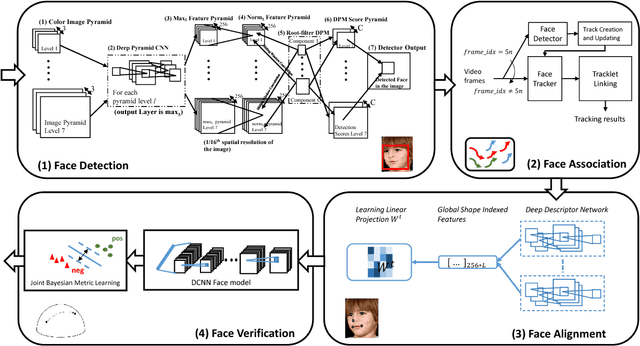
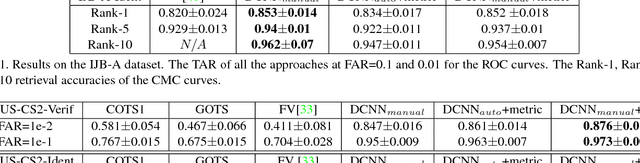


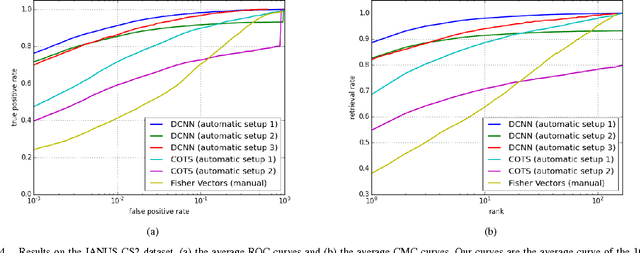
Over the last five years, methods based on Deep Convolutional Neural Networks (DCNNs) have shown impressive performance improvements for object detection and recognition problems. This has been made possible due to the availability of large annotated datasets, a better understanding of the non-linear mapping between input images and class labels as well as the affordability of GPUs. In this paper, we present the design details of a deep learning system for unconstrained face recognition, including modules for face detection, association, alignment and face verification. The quantitative performance evaluation is conducted using the IARPA Janus Benchmark A (IJB-A), the JANUS Challenge Set 2 (JANUS CS2), and the LFW dataset. The IJB-A dataset includes real-world unconstrained faces of 500 subjects with significant pose and illumination variations which are much harder than the Labeled Faces in the Wild (LFW) and Youtube Face (YTF) datasets. JANUS CS2 is the extended version of IJB-A which contains not only all the images/frames of IJB-A but also includes the original videos for evaluating the video-based face verification system. Some open issues regarding DCNNs for face verification problems are then discussed.
L2-constrained Softmax Loss for Discriminative Face Verification
Jun 07, 2017
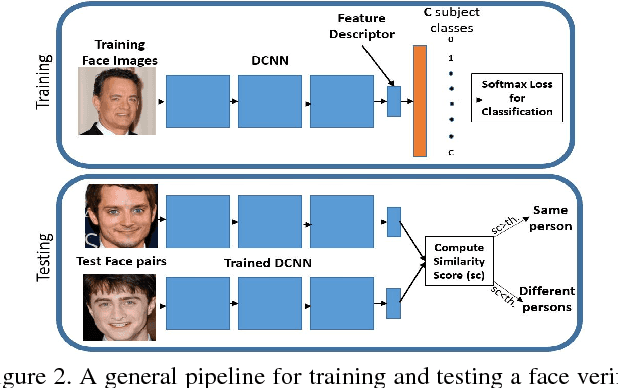
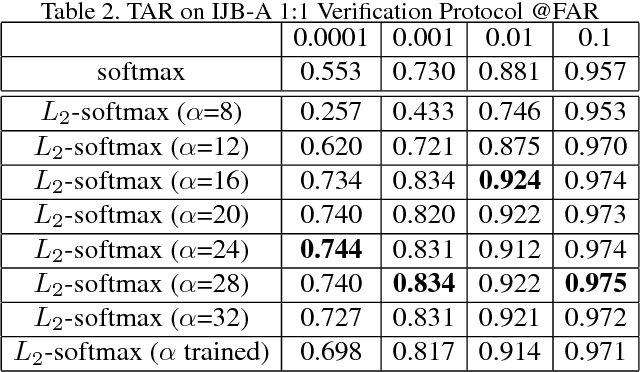
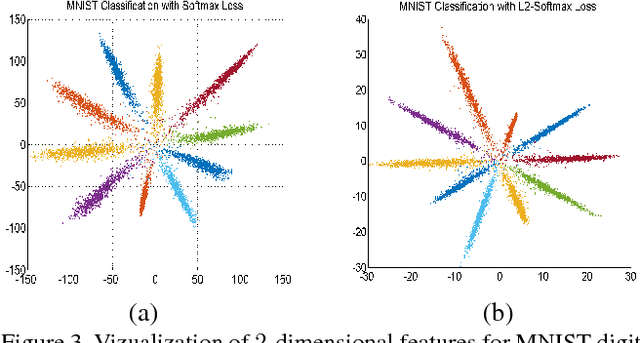
In recent years, the performance of face verification systems has significantly improved using deep convolutional neural networks (DCNNs). A typical pipeline for face verification includes training a deep network for subject classification with softmax loss, using the penultimate layer output as the feature descriptor, and generating a cosine similarity score given a pair of face images. The softmax loss function does not optimize the features to have higher similarity score for positive pairs and lower similarity score for negative pairs, which leads to a performance gap. In this paper, we add an L2-constraint to the feature descriptors which restricts them to lie on a hypersphere of a fixed radius. This module can be easily implemented using existing deep learning frameworks. We show that integrating this simple step in the training pipeline significantly boosts the performance of face verification. Specifically, we achieve state-of-the-art results on the challenging IJB-A dataset, achieving True Accept Rate of 0.909 at False Accept Rate 0.0001 on the face verification protocol. Additionally, we achieve state-of-the-art performance on LFW dataset with an accuracy of 99.78%, and competing performance on YTF dataset with accuracy of 96.08%.
UMDFaces: An Annotated Face Dataset for Training Deep Networks
May 21, 2017
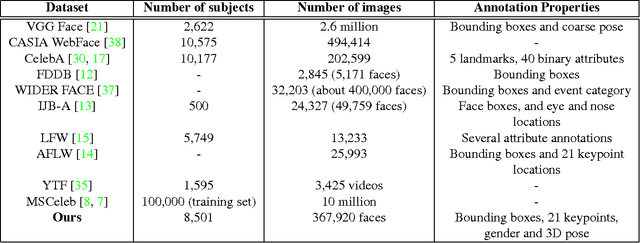

Recent progress in face detection (including keypoint detection), and recognition is mainly being driven by (i) deeper convolutional neural network architectures, and (ii) larger datasets. However, most of the large datasets are maintained by private companies and are not publicly available. The academic computer vision community needs larger and more varied datasets to make further progress. In this paper we introduce a new face dataset, called UMDFaces, which has 367,888 annotated faces of 8,277 subjects. We also introduce a new face recognition evaluation protocol which will help advance the state-of-the-art in this area. We discuss how a large dataset can be collected and annotated using human annotators and deep networks. We provide human curated bounding boxes for faces. We also provide estimated pose (roll, pitch and yaw), locations of twenty-one key-points and gender information generated by a pre-trained neural network. In addition, the quality of keypoint annotations has been verified by humans for about 115,000 images. Finally, we compare the quality of the dataset with other publicly available face datasets at similar scales.
An All-In-One Convolutional Neural Network for Face Analysis
Nov 03, 2016
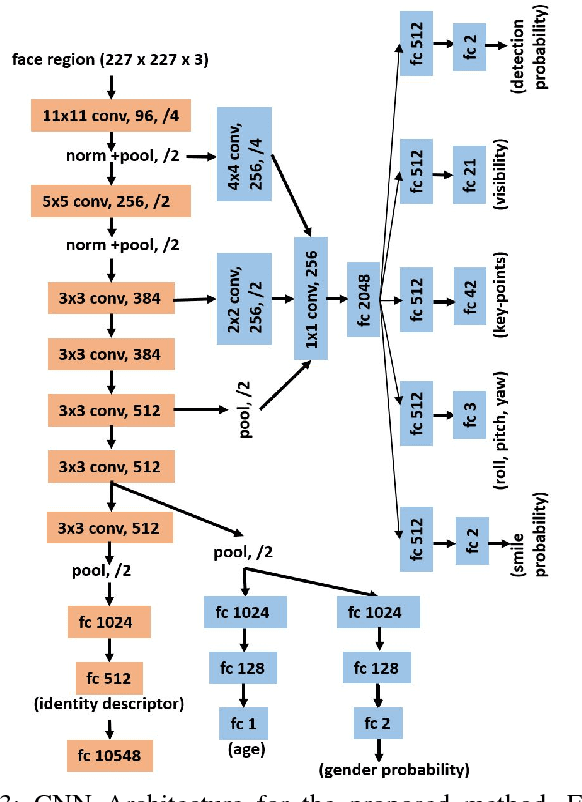

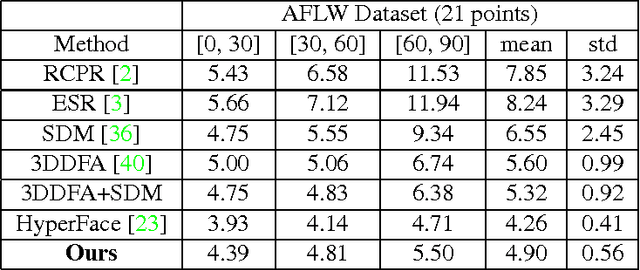
We present a multi-purpose algorithm for simultaneous face detection, face alignment, pose estimation, gender recognition, smile detection, age estimation and face recognition using a single deep convolutional neural network (CNN). The proposed method employs a multi-task learning framework that regularizes the shared parameters of CNN and builds a synergy among different domains and tasks. Extensive experiments show that the network has a better understanding of face and achieves state-of-the-art result for most of these tasks.
Face Alignment by Local Deep Descriptor Regression
Jan 29, 2016
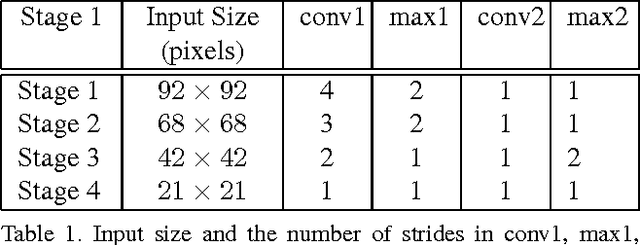
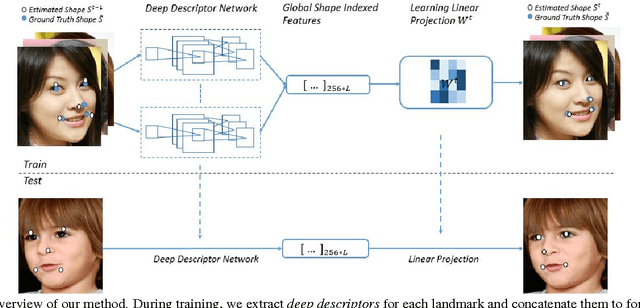
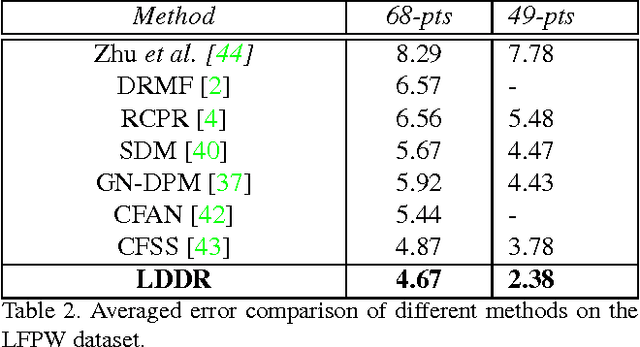
We present an algorithm for extracting key-point descriptors using deep convolutional neural networks (CNN). Unlike many existing deep CNNs, our model computes local features around a given point in an image. We also present a face alignment algorithm based on regression using these local descriptors. The proposed method called Local Deep Descriptor Regression (LDDR) is able to localize face landmarks of varying sizes, poses and occlusions with high accuracy. Deep Descriptors presented in this paper are able to uniquely and efficiently describe every pixel in the image and therefore can potentially replace traditional descriptors such as SIFT and HOG. Extensive evaluations on five publicly available unconstrained face alignment datasets show that our deep descriptor network is able to capture strong local features around a given landmark and performs significantly better than many competitive and state-of-the-art face alignment algorithms.
Towards the Design of an End-to-End Automated System for Image and Video-based Recognition
Jan 28, 2016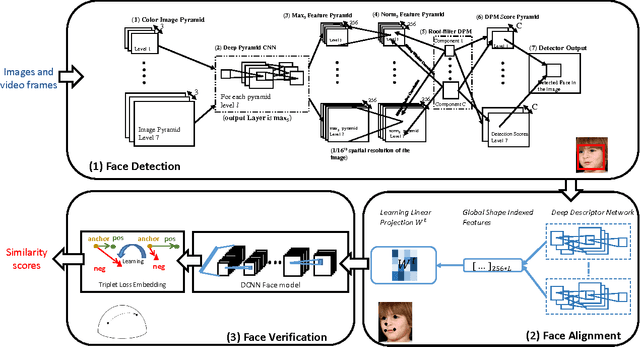


Over many decades, researchers working in object recognition have longed for an end-to-end automated system that will simply accept 2D or 3D image or videos as inputs and output the labels of objects in the input data. Computer vision methods that use representations derived based on geometric, radiometric and neural considerations and statistical and structural matchers and artificial neural network-based methods where a multi-layer network learns the mapping from inputs to class labels have provided competing approaches for image recognition problems. Over the last four years, methods based on Deep Convolutional Neural Networks (DCNNs) have shown impressive performance improvements on object detection/recognition challenge problems. This has been made possible due to the availability of large annotated data, a better understanding of the non-linear mapping between image and class labels as well as the affordability of GPUs. In this paper, we present a brief history of developments in computer vision and artificial neural networks over the last forty years for the problem of image-based recognition. We then present the design details of a deep learning system for end-to-end unconstrained face verification/recognition. Some open issues regarding DCNNs for object recognition problems are then discussed. We caution the readers that the views expressed in this paper are from the authors and authors only!
A Deep Pyramid Deformable Part Model for Face Detection
Aug 18, 2015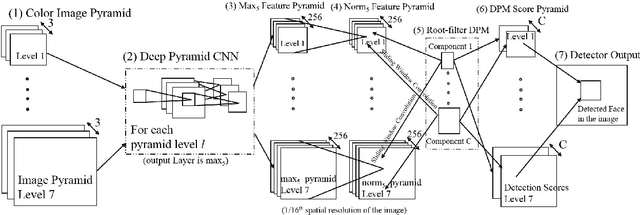

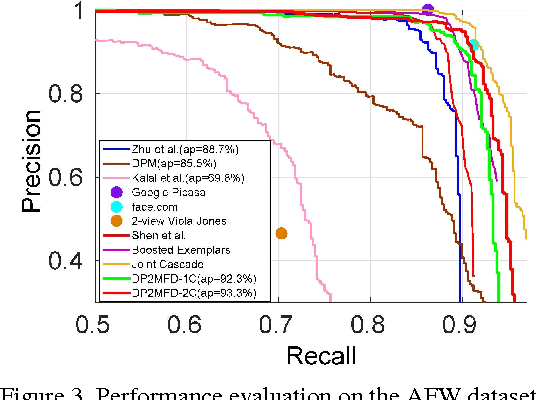
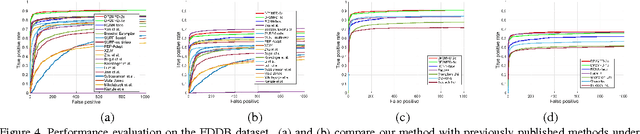
We present a face detection algorithm based on Deformable Part Models and deep pyramidal features. The proposed method called DP2MFD is able to detect faces of various sizes and poses in unconstrained conditions. It reduces the gap in training and testing of DPM on deep features by adding a normalization layer to the deep convolutional neural network (CNN). Extensive experiments on four publicly available unconstrained face detection datasets show that our method is able to capture the meaningful structure of faces and performs significantly better than many competitive face detection algorithms.