 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Spectral Body Recognition with Side Information Embedding: Benchmarks on LLCM and Analyzing Range-Induced Occlusions on IJB-MDF
Jun 10, 2025Vision Transformers (ViTs) have demonstrated impressive performance across a wide range of biometric tasks, including face and body recognition. In this work, we adapt a ViT model pretrained on visible (VIS) imagery to the challenging problem of cross-spectral body recognition, which involves matching images captured in the visible and infrared (IR) domains. Recent ViT architectures have explored incorporating additional embeddings beyond traditional positional embeddings. Building on this idea, we integrate Side Information Embedding (SIE) and examine the impact of encoding domain and camera information to enhance cross-spectral matching. Surprisingly, our results show that encoding only camera information - without explicitly incorporating domain information - achieves state-of-the-art performance on the LLCM dataset. While occlusion handling has been extensively studied in visible-spectrum person re-identification (Re-ID), occlusions in visible-infrared (VI) Re-ID remain largely underexplored - primarily because existing VI-ReID datasets, such as LLCM, SYSU-MM01, and RegDB, predominantly feature full-body, unoccluded images. To address this gap, we analyze the impact of range-induced occlusions using the IARPA Janus Benchmark Multi-Domain Face (IJB-MDF) dataset, which provides a diverse set of visible and infrared images captured at various distances, enabling cross-range, cross-spectral evaluations.
Multi-Domain Biometric Recognition using Body Embeddings
Mar 13, 2025



Biometric recognition becomes increasingly challenging as we move away from the visible spectrum to infrared imagery, where domain discrepancies significantly impact identification performance. In this paper, we show that body embeddings perform better than face embeddings for cross-spectral person identification in medium-wave infrared (MWIR) and long-wave infrared (LWIR) domains. Due to the lack of multi-domain datasets, previous research on cross-spectral body identification - also known as Visible-Infrared Person Re-Identification (VI-ReID) - has primarily focused on individual infrared bands, such as near-infrared (NIR) or LWIR, separately. We address the multi-domain body recognition problem using the IARPA Janus Benchmark Multi-Domain Face (IJB-MDF) dataset, which enables matching of short-wave infrared (SWIR), MWIR, and LWIR images against RGB (VIS) images. We leverage a vision transformer architecture to establish benchmark results on the IJB-MDF dataset and, through extensive experiments, provide valuable insights into the interrelation of infrared domains, the adaptability of VIS-pretrained models, the role of local semantic features in body-embeddings, and effective training strategies for small datasets. Additionally, we show that finetuning a body model, pretrained exclusively on VIS data, with a simple combination of cross-entropy and triplet losses achieves state-of-the-art mAP scores on the LLCM dataset.
Template-based Multi-Domain Face Recognition
Sep 15, 2024



Despite the remarkable performance of deep neural networks for face detection and recognition tasks in the visible spectrum, their performance on more challenging non-visible domains is comparatively still lacking. While significant research has been done in the fields of domain adaptation and domain generalization, in this paper we tackle scenarios in which these methods have limited applicability owing to the lack of training data from target domains. We focus on the problem of single-source (visible) and multi-target (SWIR, long-range/remote, surveillance, and body-worn) face recognition task. We show through experiments that a good template generation algorithm becomes crucial as the complexity of the target domain increases. In this context, we introduce a template generation algorithm called Norm Pooling (and a variant known as Sparse Pooling) and show that it outperforms average pooling across different domains and networks, on the IARPA JANUS Benchmark Multi-domain Face (IJB-MDF) dataset.
A Fast and Accurate System for Face Detection, Identification, and Verification
Sep 20, 2018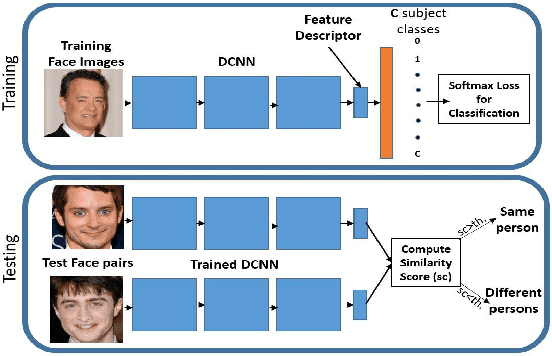
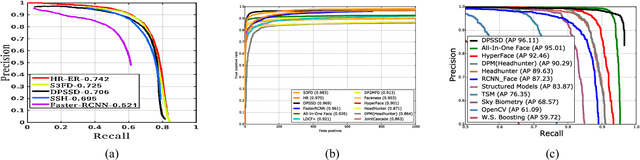
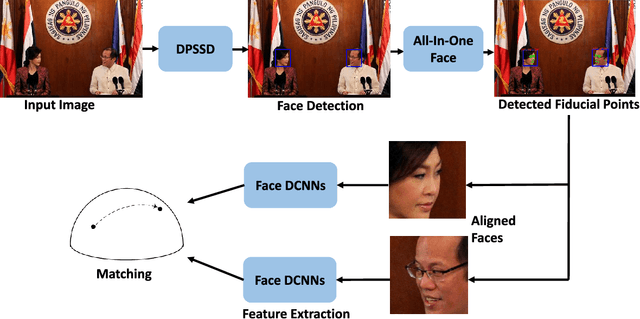
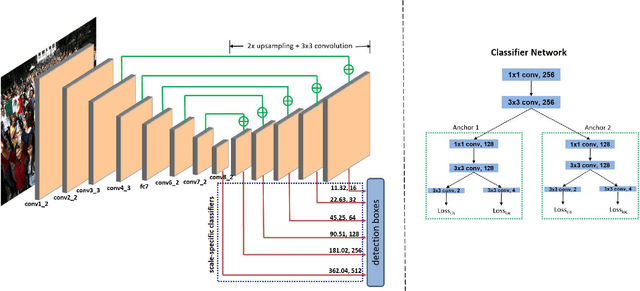
The availability of large annotated datasets and affordable computation power have led to impressive improvements in the performance of CNNs on various object detection and recognition benchmarks. These, along with a better understanding of deep learning methods, have also led to improved capabilities of machine understanding of faces. CNNs are able to detect faces, locate facial landmarks, estimate pose, and recognize faces in unconstrained images and videos. In this paper, we describe the details of a deep learning pipeline for unconstrained face identification and verification which achieves state-of-the-art performance on several benchmark datasets. We propose a novel face detector, Deep Pyramid Single Shot Face Detector (DPSSD), which is fast and capable of detecting faces with large scale variations (especially tiny faces). We give design details of the various modules involved in automatic face recognition: face detection, landmark localization and alignment, and face identification/verification. We provide evaluation results of the proposed face detector on challenging unconstrained face detection datasets. Then, we present experimental results for IARPA Janus Benchmarks A, B and C (IJB-A, IJB-B, IJB-C), and the Janus Challenge Set 5 (CS5).
UMDFaces: An Annotated Face Dataset for Training Deep Networks
May 21, 2017
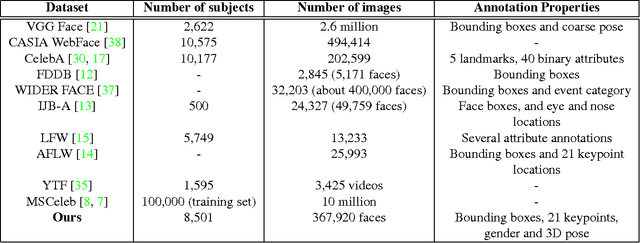

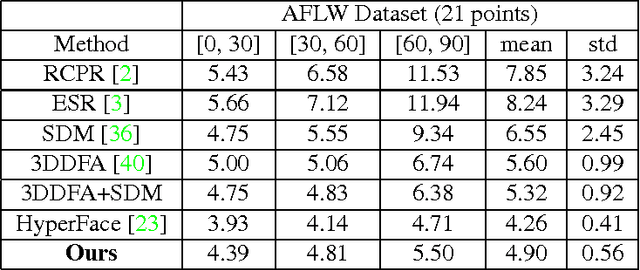
Recent progress in face detection (including keypoint detection), and recognition is mainly being driven by (i) deeper convolutional neural network architectures, and (ii) larger datasets. However, most of the large datasets are maintained by private companies and are not publicly available. The academic computer vision community needs larger and more varied datasets to make further progress. In this paper we introduce a new face dataset, called UMDFaces, which has 367,888 annotated faces of 8,277 subjects. We also introduce a new face recognition evaluation protocol which will help advance the state-of-the-art in this area. We discuss how a large dataset can be collected and annotated using human annotators and deep networks. We provide human curated bounding boxes for faces. We also provide estimated pose (roll, pitch and yaw), locations of twenty-one key-points and gender information generated by a pre-trained neural network. In addition, the quality of keypoint annotations has been verified by humans for about 115,000 images. Finally, we compare the quality of the dataset with other publicly available face datasets at similar scales.