 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoiser-based projections for 2-D super-resolution multi-reference alignment
Apr 10, 2022


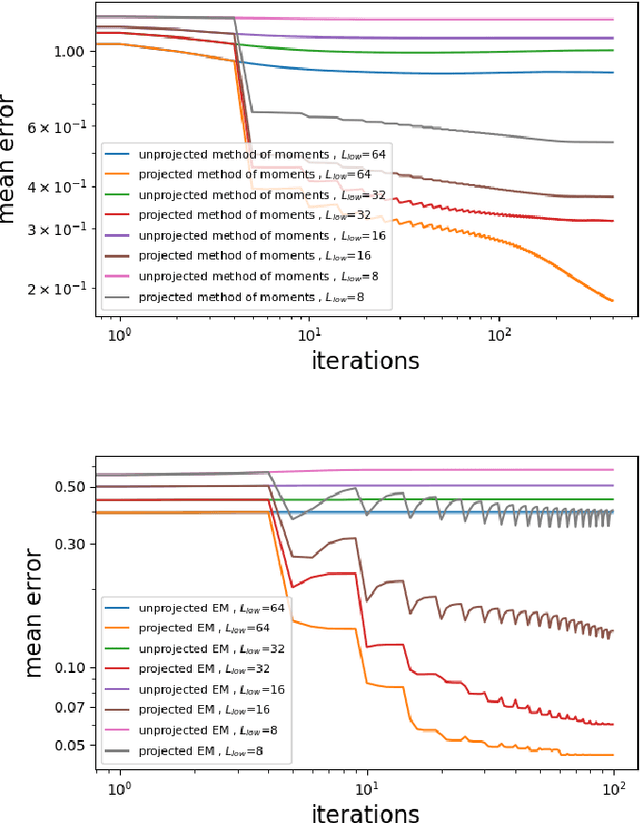
We study the 2-D super-resolution multi-reference alignment (SR-MRA) problem: estimating an image from its down-sampled, circularly-translated, and noisy copies. The SR-MRA problem serves as a mathematical abstraction of the structure determination problem for biological molecules. Since the SR-MRA problem is ill-posed without prior knowledge, accurate image estimation relies on designing priors that well-describe the statistics of the images of interest. In this work, we build on recent advances in image processing, and harness the power of denoisers as priors of images. In particular, we suggest to use denoisers as projections, and design two computational frameworks to estimate the image: projected expectation-maximization and projected method of moments. We provide an efficient GPU implementation, and demonstrate the effectiveness of these algorithms by extensive numerical experiments on a wide range of parameters and images.
Shallow Transits -- Deep Learning II: Identify Individual Exoplanetary Transits in Red Noise using Deep Learning
Mar 15, 2022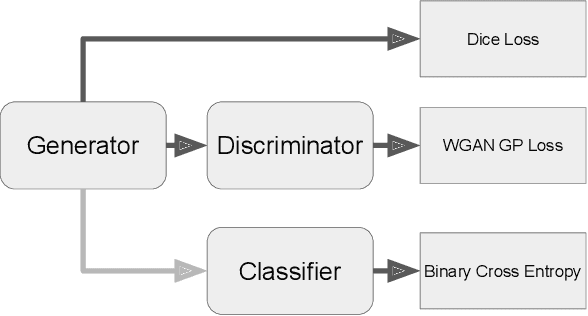

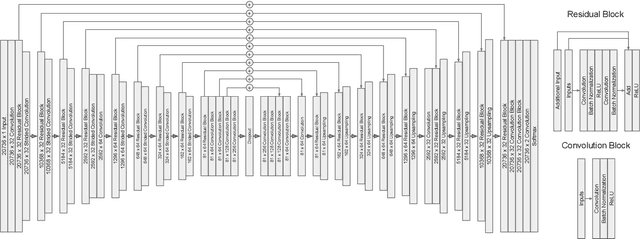
In a previous paper, we have introduced a deep learning neural network that should be able to detect the existence of very shallow periodic planetary transits in the presence of red noise. The network in that feasibility study would not provide any further details about the detected transits. The current paper completes this missing part. We present a neural network that tags samples that were obtained during transits. This is essentially similar to the task of identifying the semantic context of each pixel in an image -- an important task in computer vision, called `semantic segmentation', which is often performed by deep neural networks. The neural network we present makes use of novel deep learning concepts such as U-Nets, Generative Adversarial Networks (GAN), and adversarial loss. The resulting segmentation should allow further studies of the light curves which are tagged as containing transits. This approach towards the detection and study of very shallow transits is bound to play a significant role in future space-based transit surveys such as PLATO, which are specifically aimed to detect those extremely difficult cases of long-period shallow transits. Our segmentation network also adds to the growing toolbox of deep learning approaches which are being increasingly used in the study of exoplanets, but so far mainly for vetting transits, rather than their initial detection.
Generative Adversarial Networks
Mar 01, 2022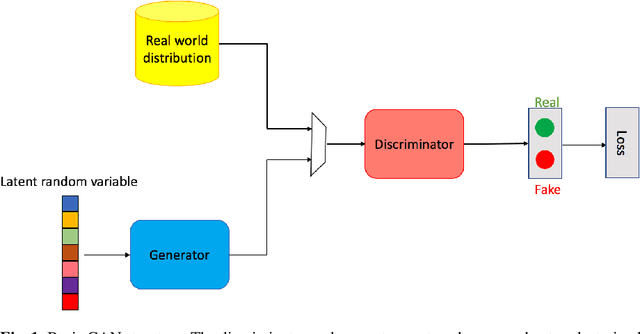

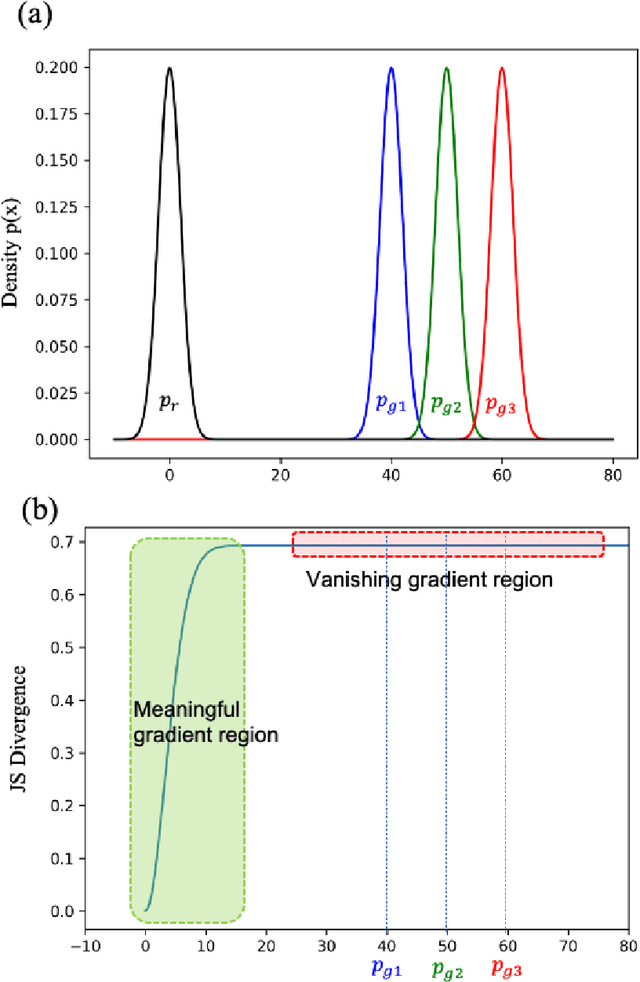
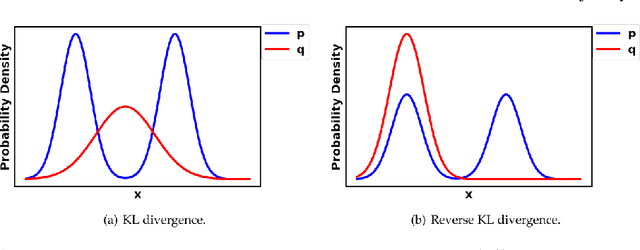
Generative Adversarial Networks (GANs) are very popular frameworks for generating high-quality data, and are immensely used in both the academia and industry in many domains. Arguably, their most substantial impact has been in the area of computer vision, where they achieve state-of-the-art image generation. This chapter gives an introduction to GANs, by discussing their principle mechanism and presenting some of their inherent problems during training and evaluation. We focus on these three issues: (1) mode collapse, (2) vanishing gradients, and (3) generation of low-quality images. We then list some architecture-variant and loss-variant GANs that remedy the above challenges. Lastly, we present two utilization examples of GANs for real-world applications: Data augmentation and face images generation.
SPAGHETTI: Editing Implicit Shapes Through Part Aware Generation
Jan 31, 2022
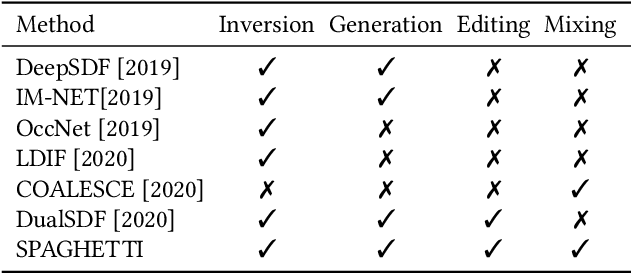
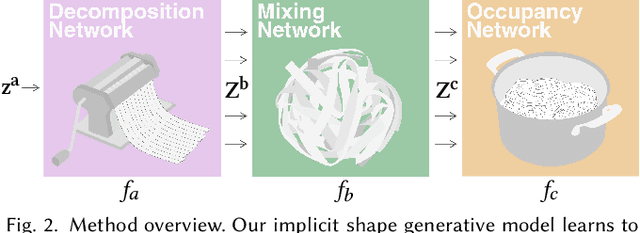
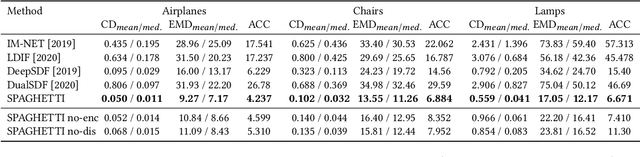
Neural implicit fields are quickly emerging as an attractive representation for learning based techniques. However, adopting them for 3D shape modeling and editing is challenging. We introduce a method for $\mathbf{E}$diting $\mathbf{I}$mplicit $\mathbf{S}$hapes $\mathbf{T}$hrough $\mathbf{P}$art $\mathbf{A}$ware $\mathbf{G}$enera$\mathbf{T}$ion, permuted in short as SPAGHETTI. Our architecture allows for manipulation of implicit shapes by means of transforming, interpolating and combining shape segments together, without requiring explicit part supervision. SPAGHETTI disentangles shape part representation into extrinsic and intrinsic geometric information. This characteristic enables a generative framework with part-level control. The modeling capabilities of SPAGHETTI are demonstrated using an interactive graphical interface, where users can directly edit neural implicit shapes.
Extending the Vocabulary of Fictional Languages using Neural Networks
Jan 18, 2022Fictional languages have become increasingly popular over the recent years appearing in novels, movies, TV shows, comics, and video games. While some of these fictional languages have a complete vocabulary, most do not. We propose a deep learning solution to the problem. Using style transfer and machine translation tools, we generate new words for a given target fictional language, while maintaining the style of its creator, hence extending this language vocabulary.
DeepMLS: Geometry-Aware Control Point Deformation
Jan 05, 2022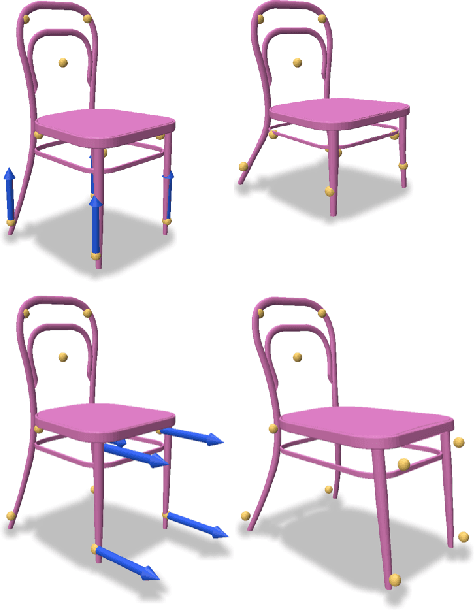
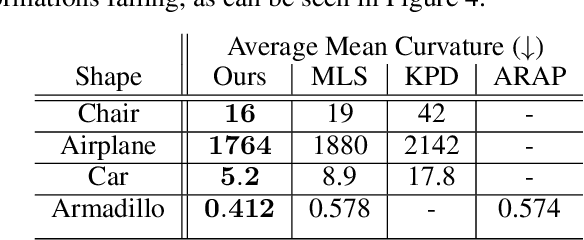
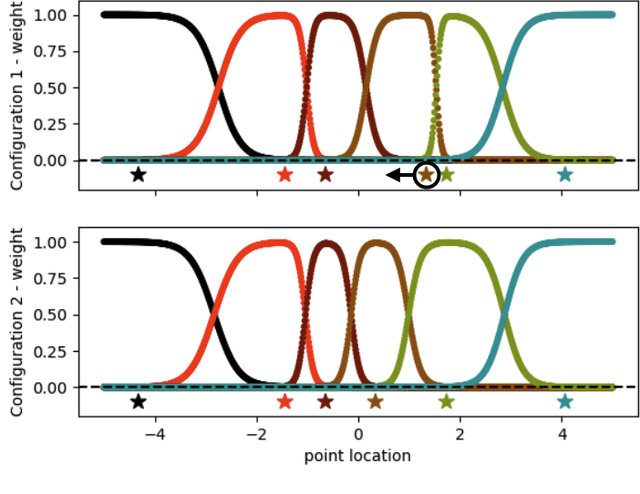
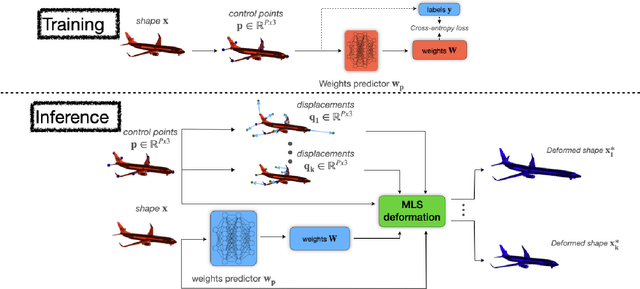
We introduce DeepMLS, a space-based deformation technique, guided by a set of displaced control points. We leverage the power of neural networks to inject the underlying shape geometry into the deformation parameters. The goal of our technique is to enable a realistic and intuitive shape deformation. Our method is built upon moving least-squares (MLS), since it minimizes a weighted sum of the given control point displacements. Traditionally, the influence of each control point on every point in space (i.e., the weighting function) is defined using inverse distance heuristics. In this work, we opt to learn the weighting function, by training a neural network on the control points from a single input shape, and exploit the innate smoothness of neural networks. Our geometry-aware control point deformation is agnostic to the surface representation and quality; it can be applied to point clouds or meshes, including non-manifold and disconnected surface soups. We show that our technique facilitates intuitive piecewise smooth deformations, which are well suited for manufactured objects. We show the advantages of our approach compared to existing surface and space-based deformation techniques, both quantitatively and qualitatively.
Video Reconstruction from a Single Motion Blurred Image using Learned Dynamic Phase Coding
Dec 28, 2021

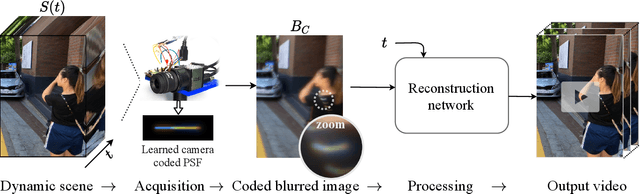
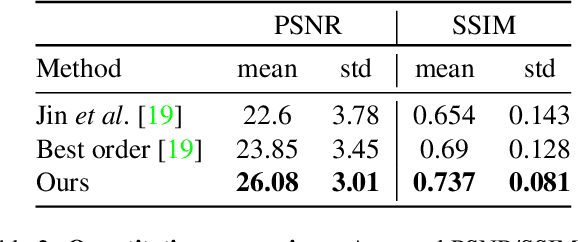
Video reconstruction from a single motion-blurred image is a challenging problem, which can enhance existing cameras' capabilities. Recently, several works addressed this task using conventional imaging and deep learning. Yet, such purely-digital methods are inherently limited, due to direction ambiguity and noise sensitivity. Some works proposed to address these limitations using non-conventional image sensors, however, such sensors are extremely rare and expensive. To circumvent these limitations with simpler means, we propose a hybrid optical-digital method for video reconstruction that requires only simple modifications to existing optical systems. We use a learned dynamic phase-coding in the lens aperture during the image acquisition to encode the motion trajectories, which serve as prior information for the video reconstruction process. The proposed computational camera generates a sharp frame burst of the scene at various frame rates from a single coded motion-blurred image, using an image-to-video convolutional neural network. We present advantages and improved performance compared to existing methods, using both simulations and a real-world camera prototype.
Unsupervised Domain Generalization by Learning a Bridge Across Domains
Dec 04, 2021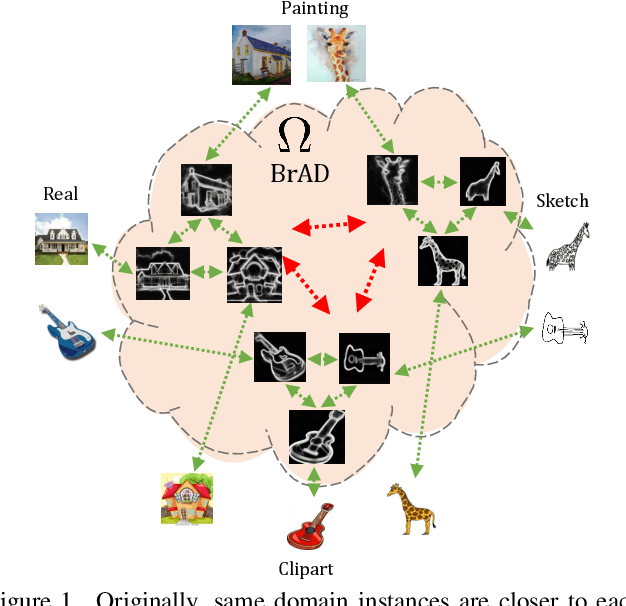
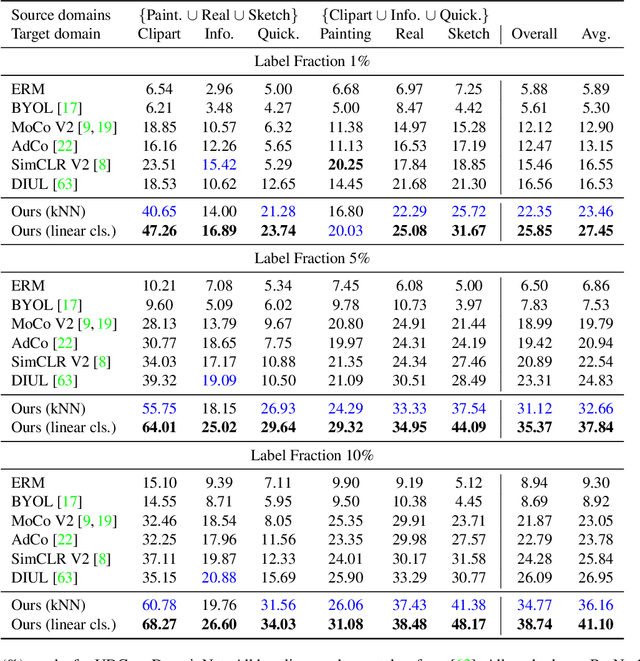
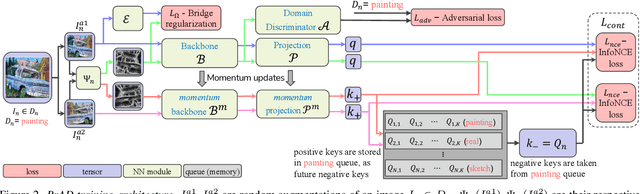
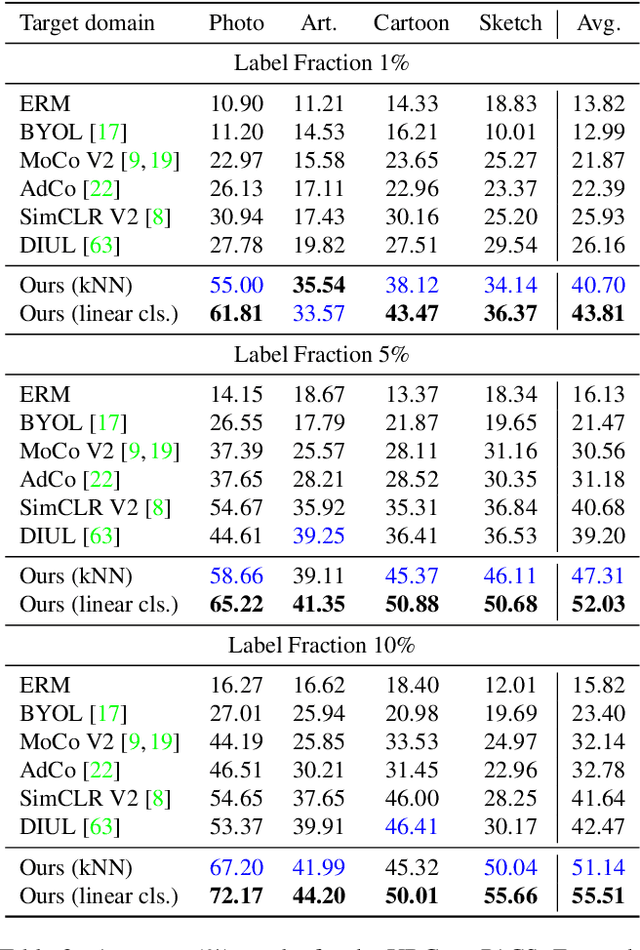
The ability to generalize learned representations across significantly different visual domains, such as between real photos, clipart, paintings, and sketches, is a fundamental capacity of the human visual system. In this paper, different from most cross-domain works that utilize some (or full) source domain supervision, we approach a relatively new and very practical Unsupervised Domain Generalization (UDG) setup of having no training supervision in neither source nor target domains. Our approach is based on self-supervised learning of a Bridge Across Domains (BrAD) - an auxiliary bridge domain accompanied by a set of semantics preserving visual (image-to-image) mappings to BrAD from each of the training domains. The BrAD and mappings to it are learned jointly (end-to-end) with a contrastive self-supervised representation model that semantically aligns each of the domains to its BrAD-projection, and hence implicitly drives all the domains (seen or unseen) to semantically align to each other. In this work, we show how using an edge-regularized BrAD our approach achieves significant gains across multiple benchmarks and a range of tasks, including UDG, Few-shot UDA, and unsupervised generalization across multi-domain datasets (including generalization to unseen domains and classes).
DeepBBS: Deep Best Buddies for Point Cloud Registration
Oct 16, 2021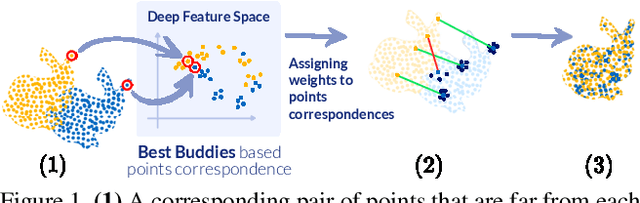
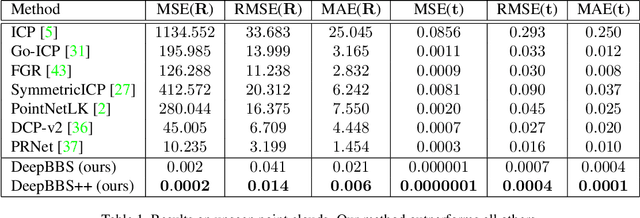
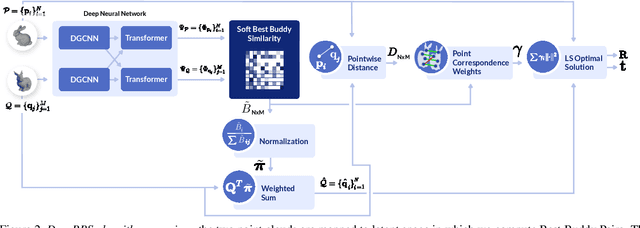
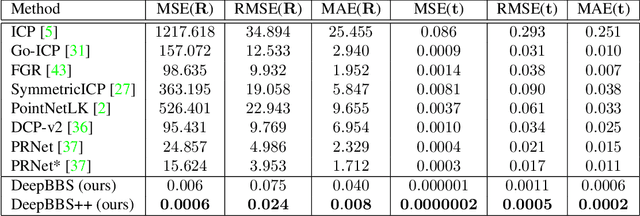
Recently, several deep learning approaches have been proposed for point cloud registration. These methods train a network to generate a representation that helps finding matching points in two 3D point clouds. Finding good matches allows them to calculate the transformation between the point clouds accurately. Two challenges of these techniques are dealing with occlusions and generalizing to objects of classes unseen during training. This work proposes DeepBBS, a novel method for learning a representation that takes into account the best buddy distance between points during training. Best Buddies (i.e., mutual nearest neighbors) are pairs of points nearest to each other. The Best Buddies criterion is a strong indication for correct matches that, in turn, leads to accurate registration. Our experiments show improved performance compared to previous methods. In particular, our learned representation leads to an accurate registration for partial shapes and in unseen categories.
Mesh Draping: Parametrization-Free Neural Mesh Transfer
Oct 11, 2021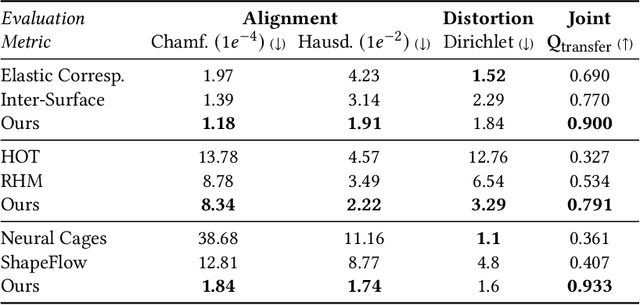
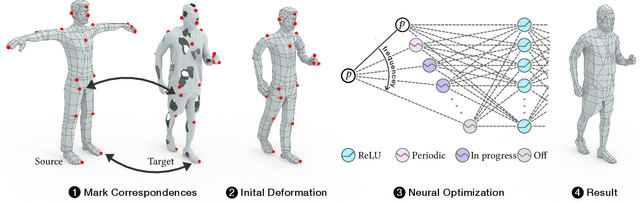

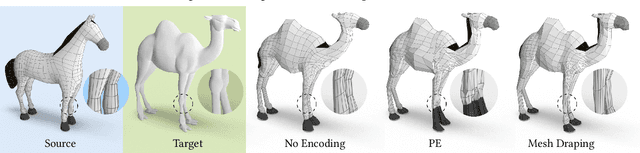
Despite recent advances in geometric modeling, 3D mesh modeling still involves a considerable amount of manual labor by experts. In this paper, we introduce Mesh Draping: a neural method for transferring existing mesh structure from one shape to another. The method drapes the source mesh over the target geometry and at the same time seeks to preserve the carefully designed characteristics of the source mesh. At its core, our method deforms the source mesh using progressive positional encoding. We show that by leveraging gradually increasing frequencies to guide the neural optimization, we are able to achieve stable and high quality mesh transfer. Our approach is simple and requires little user guidance, compared to contemporary surface mapping techniques which rely on parametrization or careful manual tuning. Most importantly, Mesh Draping is a parameterization-free method, and thus applicable to a variety of target shape representations, including point clouds, polygon soups, and non-manifold meshes. We demonstrate that the transferred meshing remains faithful to the source mesh design characteristics, and at the same time fits the target geometry well.