 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Masked Autoencoders with Application to Anomaly Detection in Non-Contrast Enhanced Breast MRI
Mar 10, 2023Self-supervised models allow (pre-)training on unlabeled data and therefore have the potential to overcome the need for large annotated cohorts. One leading self-supervised model is the masked autoencoder (MAE) which was developed on natural imaging data. The MAE is masking out a high fraction of visual transformer (ViT) input patches, to then recover the uncorrupted images as a pretraining task. In this work, we extend MAE to perform anomaly detection on breast magnetic resonance imaging (MRI). This new model, coined masked autoencoder for medical imaging (MAEMI) is trained on two non-contrast enhanced MRI sequences, aiming at lesion detection without the need for intravenous injection of contrast media and temporal image acquisition. During training, only non-cancerous images are presented to the model, with the purpose of localizing anomalous tumor regions during test time. We use a public dataset for model development. Performance of the architecture is evaluated in reference to subtraction images created from dynamic contrast enhanced (DCE)-MRI.
TEXTure: Text-Guided Texturing of 3D Shapes
Feb 03, 2023



In this paper, we present TEXTure, a novel method for text-guided generation, editing, and transfer of textures for 3D shapes. Leveraging a pretrained depth-to-image diffusion model, TEXTure applies an iterative scheme that paints a 3D model from different viewpoints. Yet, while depth-to-image models can create plausible textures from a single viewpoint, the stochastic nature of the generation process can cause many inconsistencies when texturing an entire 3D object. To tackle these problems, we dynamically define a trimap partitioning of the rendered image into three progression states, and present a novel elaborated diffusion sampling process that uses this trimap representation to generate seamless textures from different views. We then show that one can transfer the generated texture maps to new 3D geometries without requiring explicit surface-to-surface mapping, as well as extract semantic textures from a set of images without requiring any explicit reconstruction. Finally, we show that TEXTure can be used to not only generate new textures but also edit and refine existing textures using either a text prompt or user-provided scribbles. We demonstrate that our TEXTuring method excels at generating, transferring, and editing textures through extensive evaluation, and further close the gap between 2D image generation and 3D texturing.
ADIR: Adaptive Diffusion for Image Reconstruction
Dec 06, 2022



In recent years, denoising diffusion models have demonstrated outstanding image generation performance. The information on natural images captured by these models is useful for many image reconstruction applications, where the task is to restore a clean image from its degraded observations. In this work, we propose a conditional sampling scheme that exploits the prior learned by diffusion models while retaining agreement with the observations. We then combine it with a novel approach for adapting pretrained diffusion denoising networks to their input. We examine two adaption strategies: the first uses only the degraded image, while the second, which we advocate, is performed using images that are ``nearest neighbors'' of the degraded image, retrieved from a diverse dataset using an off-the-shelf visual-language model. To evaluate our method, we test it on two state-of-the-art publicly available diffusion models, Stable Diffusion and Guided Diffusion. We show that our proposed `adaptive diffusion for image reconstruction' (ADIR) approach achieves a significant improvement in the super-resolution, deblurring, and text-based editing tasks.
PIP: Positional-encoding Image Prior
Nov 25, 2022



In Deep Image Prior (DIP), a Convolutional Neural Network (CNN) is fitted to map a latent space to a degraded (e.g. noisy) image but in the process learns to reconstruct the clean image. This phenomenon is attributed to CNN's internal image-prior. We revisit the DIP framework, examining it from the perspective of a neural implicit representation. Motivated by this perspective, we replace the random or learned latent with Fourier-Features (Positional Encoding). We show that thanks to the Fourier features properties, we can replace the convolution layers with simple pixel-level MLPs. We name this scheme ``Positional Encoding Image Prior" (PIP) and exhibit that it performs very similarly to DIP on various image-reconstruction tasks with much less parameters required. Additionally, we demonstrate that PIP can be easily extended to videos, where 3D-DIP struggles and suffers from instability. Code and additional examples for all tasks, including videos, are available on the project page https://nimrodshabtay.github.io/PIP/
MAEDAY: MAE for few and zero shot AnomalY-Detection
Nov 25, 2022



The goal of Anomaly-Detection (AD) is to identify outliers, or outlying regions, from some unknown distribution given only a set of positive (good) examples. Few-Shot AD (FSAD) aims to solve the same task with a minimal amount of normal examples. Recent embedding-based methods, that compare the embedding vectors of queries to a set of reference embeddings, have demonstrated impressive results for FSAD, where as little as one good example is provided. A different approach, image-reconstruction-based, has been historically used for AD. The idea is to train a model to recover normal images from corrupted observations, assuming that the model will fail to recover regions when encountered with an out-of-distribution image. However, image-reconstruction-based methods were not yet used in the low-shot regime as they need to be trained on a diverse set of normal images in order to properly perform. We suggest using Masked Auto-Encoder (MAE), a self-supervised transformer model trained for recovering missing image regions based on their surroundings for FSAD. We show that MAE performs well by pre-training on an arbitrary set of natural images (ImageNet) and only fine-tuning on a small set of normal images. We name this method MAEDAY. We further find that MAEDAY provides an orthogonal signal to the embedding-based methods and the ensemble of the two approaches achieves very strong SOTA results. We also present a novel task of Zero-Shot AD (ZSAD) where no normal samples are available at training time. We show that MAEDAY performs surprisingly well at this task. Finally, we provide a new dataset for detecting foreign objects on the ground and demonstrate superior results for this task as well. Code is available at https://github.com/EliSchwartz/MAEDAY .
Teaching Structured Vision&Language Concepts to Vision&Language Models
Nov 21, 2022



Vision and Language (VL) models have demonstrated remarkable zero-shot performance in a variety of tasks. However, some aspects of complex language understanding still remain a challenge. We introduce the collective notion of Structured Vision&Language Concepts (SVLC) which includes object attributes, relations, and states which are present in the text and visible in the image. Recent studies have shown that even the best VL models struggle with SVLC. A possible way of fixing this issue is by collecting dedicated datasets for teaching each SVLC type, yet this might be expensive and time-consuming. Instead, we propose a more elegant data-driven approach for enhancing VL models' understanding of SVLCs that makes more effective use of existing VL pre-training datasets and does not require any additional data. While automatic understanding of image structure still remains largely unsolved, language structure is much better modeled and understood, allowing for its effective utilization in teaching VL models. In this paper, we propose various techniques based on language structure understanding that can be used to manipulate the textual part of off-the-shelf paired VL datasets. VL models trained with the updated data exhibit a significant improvement of up to 15% in their SVLC understanding with only a mild degradation in their zero-shot capabilities both when training from scratch or fine-tuning a pre-trained model.
Latent-NeRF for Shape-Guided Generation of 3D Shapes and Textures
Nov 14, 2022Text-guided image generation has progressed rapidly in recent years, inspiring major breakthroughs in text-guided shape generation. Recently, it has been shown that using score distillation, one can successfully text-guide a NeRF model to generate a 3D object. We adapt the score distillation to the publicly available, and computationally efficient, Latent Diffusion Models, which apply the entire diffusion process in a compact latent space of a pretrained autoencoder. As NeRFs operate in image space, a naive solution for guiding them with latent score distillation would require encoding to the latent space at each guidance step. Instead, we propose to bring the NeRF to the latent space, resulting in a Latent-NeRF. Analyzing our Latent-NeRF, we show that while Text-to-3D models can generate impressive results, they are inherently unconstrained and may lack the ability to guide or enforce a specific 3D structure. To assist and direct the 3D generation, we propose to guide our Latent-NeRF using a Sketch-Shape: an abstract geometry that defines the coarse structure of the desired object. Then, we present means to integrate such a constraint directly into a Latent-NeRF. This unique combination of text and shape guidance allows for increased control over the generation process. We also show that latent score distillation can be successfully applied directly on 3D meshes. This allows for generating high-quality textures on a given geometry. Our experiments validate the power of our different forms of guidance and the efficiency of using latent rendering. Implementation is available at https://github.com/eladrich/latent-nerf
Learning Low Dimensional State Spaces with Overparameterized Recurrent Neural Network
Oct 25, 2022Overparameterization in deep learning typically refers to settings where a trained Neural Network (NN) has representational capacity to fit the training data in many ways, some of which generalize well, while others do not. In the case of Recurrent Neural Networks (RNNs), there exists an additional layer of overparameterization, in the sense that a model may exhibit many solutions that generalize well for sequence lengths seen in training, some of which extrapolate to longer sequences, while others do not. Numerous works studied the tendency of Gradient Descent (GD) to fit overparameterized NNs with solutions that generalize well. On the other hand, its tendency to fit overparameterized RNNs with solutions that extrapolate has been discovered only lately, and is far less understood. In this paper, we analyze the extrapolation properties of GD when applied to overparameterized linear RNNs. In contrast to recent arguments suggesting an implicit bias towards short-term memory, we provide theoretical evidence for learning low dimensional state spaces, which can also model long-term memory. Our result relies on a dynamical characterization which shows that GD (with small step size and near-zero initialization) strives to maintain a certain form of balancedness, as well as on tools developed in the context of the moment problem from statistics (recovery of a probability distribution from its moments). Experiments corroborate our theory, demonstrating extrapolation via learning low dimensional state spaces with both linear and non-linear RNNs
A Diffusion Model Predicts 3D Shapes from 2D Microscopy Images
Aug 31, 2022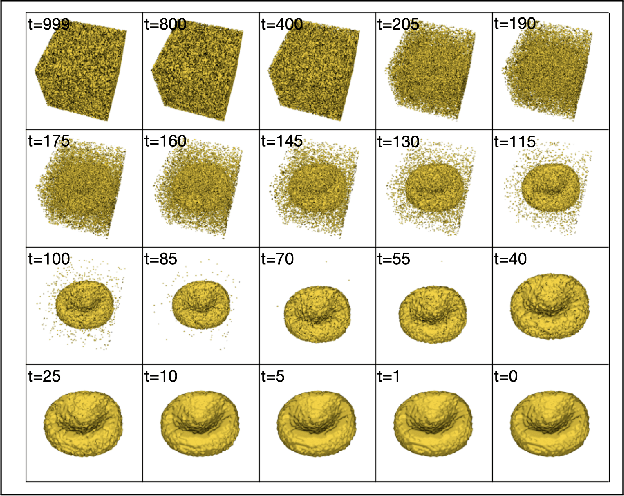
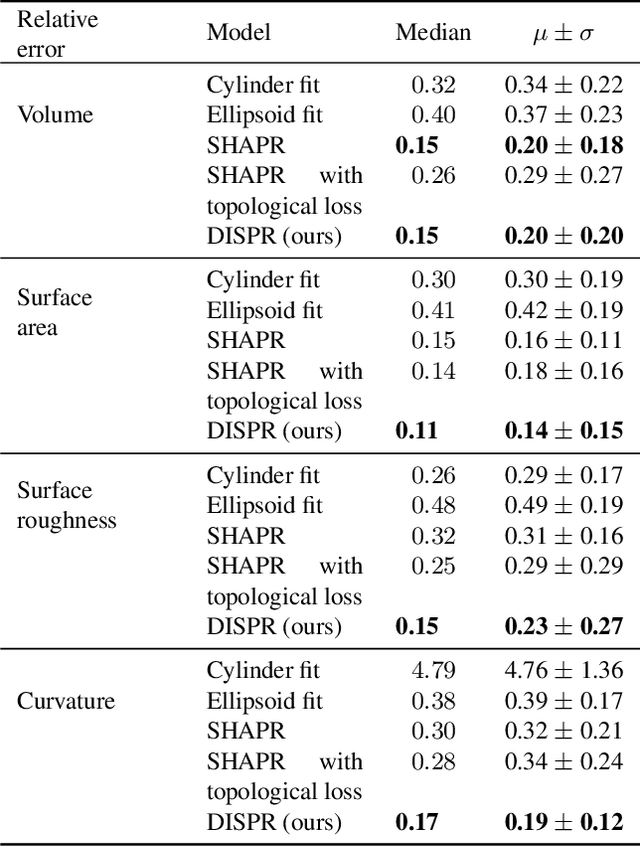
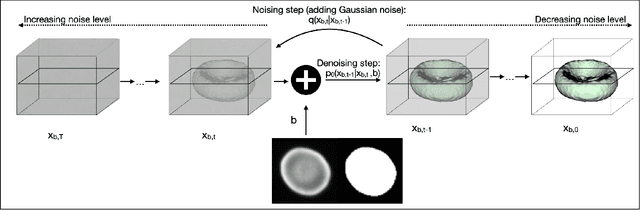
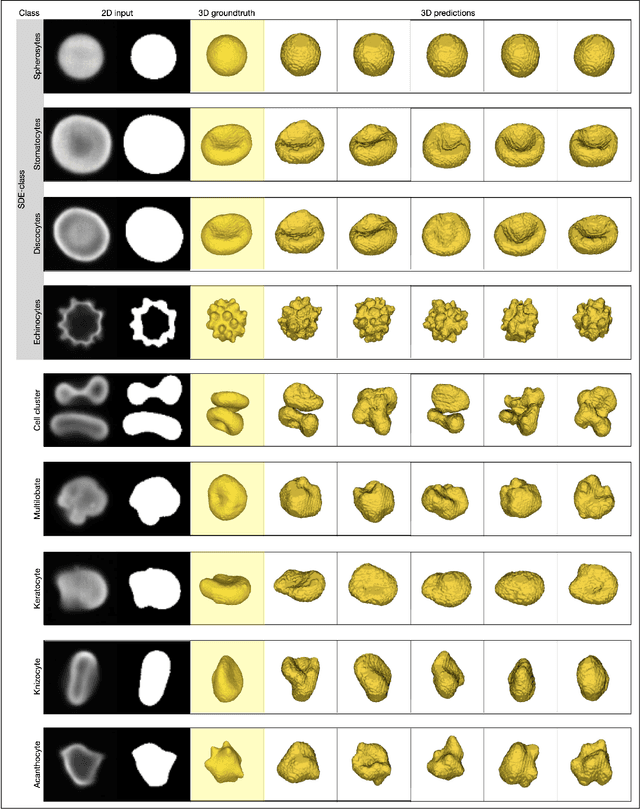
Diffusion models are a class of generative models, showing superior performance as compared to other generative models in creating realistic images when trained on natural image datasets. We introduce DISPR, a diffusion-based model for solving the inverse problem of three-dimensional (3D) cell shape prediction from two-dimensional (2D) single cell microscopy images. Using the 2D microscopy image as a prior, DISPR is conditioned to predict realistic 3D shape reconstructions. To showcase the applicability of DISPR as a data augmentation tool in a feature-based single cell classification task, we extract morphological features from the cells grouped into six highly imbalanced classes. Adding features from predictions of DISPR to the three minority classes improved the macro F1 score from $F1_\text{macro} = 55.2 \pm 4.6\%$ to $F1_\text{macro} = 72.2 \pm 4.9\%$. With our method being the first to employ a diffusion-based model in this context, we demonstrate that diffusion models can be applied to inverse problems in 3D, and that they learn to reconstruct 3D shapes with realistic morphological features from 2D microscopy images.
Utilizing Excess Resources in Training Neural Networks
Jul 12, 2022


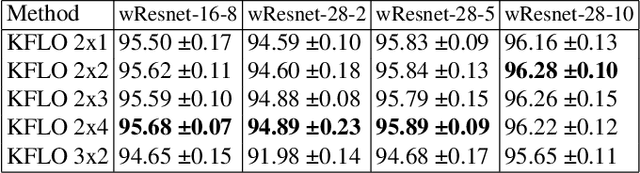
In this work, we suggest Kernel Filtering Linear Overparameterization (KFLO), where a linear cascade of filtering layers is used during training to improve network performance in test time. We implement this cascade in a kernel filtering fashion, which prevents the trained architecture from becoming unnecessarily deeper. This also allows using our approach with almost any network architecture and let combining the filtering layers into a single layer in test time. Thus, our approach does not add computational complexity during inference. We demonstrate the advantage of KFLO on various network models and datasets in supervised learning.