 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace Authentication from Grayscale Coded Light Field
May 31, 2020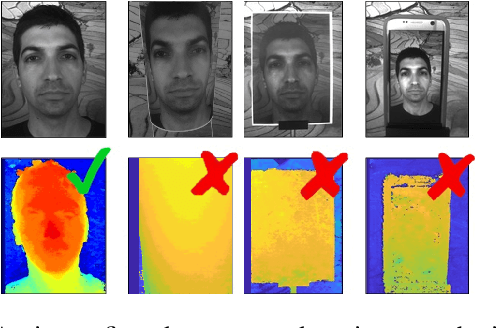


Face verification is a fast-growing authentication tool for everyday systems, such as smartphones. While current 2D face recognition methods are very accurate, it has been suggested recently that one may wish to add a 3D sensor to such solutions to make them more reliable and robust to spoofing, e.g., using a 2D print of a person's face. Yet, this requires an additional relatively expensive depth sensor. To mitigate this, we propose a novel authentication system, based on slim grayscale coded light field imaging. We provide a reconstruction free fast anti-spoofing mechanism, working directly on the coded image. It is followed by a multi-view, multi-modal face verification network that given grayscale data together with a low-res depth map achieves competitive results to the RGB case. We demonstrate the effectiveness of our solution on a simulated 3D (RGBD) version of LFW, which will be made public, and a set of real faces acquired by a light field computational camera.
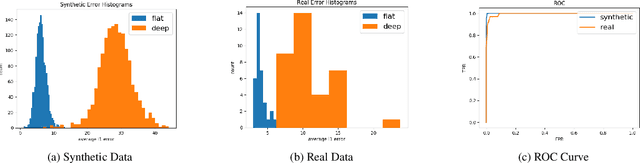
Point2Mesh: A Self-Prior for Deformable Meshes
May 22, 2020
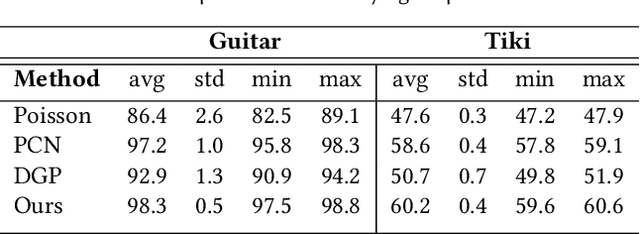

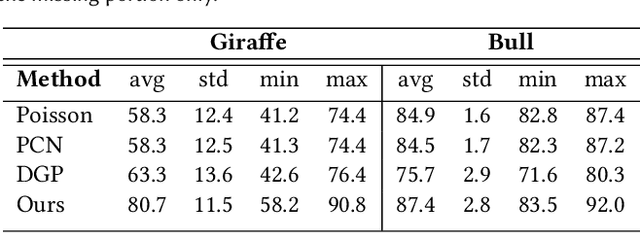
In this paper, we introduce Point2Mesh, a technique for reconstructing a surface mesh from an input point cloud. Instead of explicitly specifying a prior that encodes the expected shape properties, the prior is defined automatically using the input point cloud, which we refer to as a self-prior. The self-prior encapsulates reoccurring geometric repetitions from a single shape within the weights of a deep neural network. We optimize the network weights to deform an initial mesh to shrink-wrap a single input point cloud. This explicitly considers the entire reconstructed shape, since shared local kernels are calculated to fit the overall object. The convolutional kernels are optimized globally across the entire shape, which inherently encourages local-scale geometric self-similarity across the shape surface. We show that shrink-wrapping a point cloud with a self-prior converges to a desirable solution; compared to a prescribed smoothness prior, which often becomes trapped in undesirable local minima. While the performance of traditional reconstruction approaches degrades in non-ideal conditions that are often present in real world scanning, i.e., unoriented normals, noise and missing (low density) parts, Point2Mesh is robust to non-ideal conditions. We demonstrate the performance of Point2Mesh on a large variety of shapes with varying complexity.
On the Convergence Rate of Projected Gradient Descent for a Back-Projection based Objective
May 03, 2020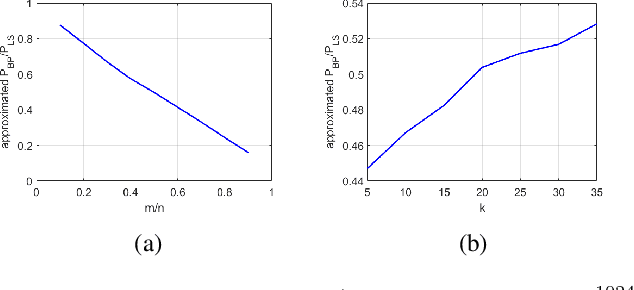
Ill-posed linear inverse problems appear in many fields of imaging science and engineering, and are typically addressed by solving optimization problems, which are composed of fidelity and prior terms or constraints. Traditionally, the research has been focused on different prior models, while the least squares (LS) objective has been the common choice for the fidelity term. However, recently a few works have considered a back-projection (BP) based fidelity term as an alternative to the LS, and demonstrated excellent reconstruction results for popular inverse problems. These prior works have also empirically shown that using the BP term, rather than the LS term, requires fewer iterations of plain and accelerated proximal gradient algorithms. In the current paper, we examine the convergence rate of the BP objective for the projected gradient descent (PGD) algorithm and identify an inherent source for its faster convergence compared to the LS objective. Numerical experiments with both $\ell_1$-norm and GAN-based priors corroborate our theoretical results for PGD. We also draw the connection to the observed behavior for proximal methods.
A function space analysis of finite neural networks with insights from sampling theory
Apr 15, 2020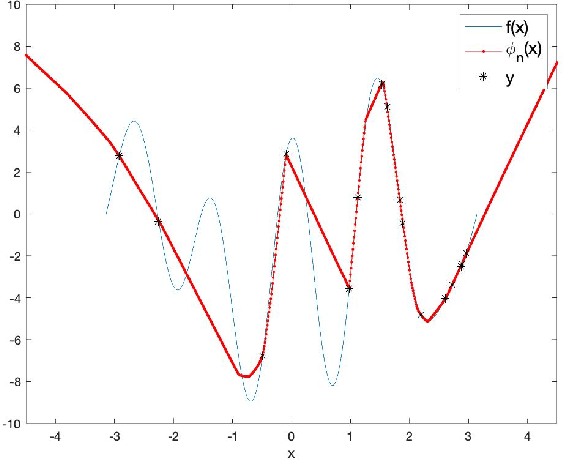
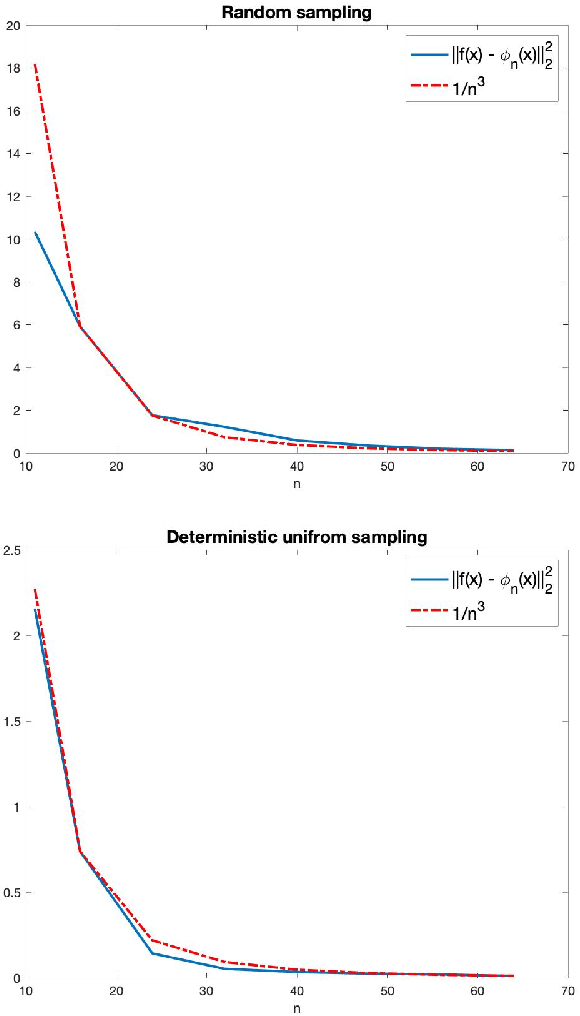
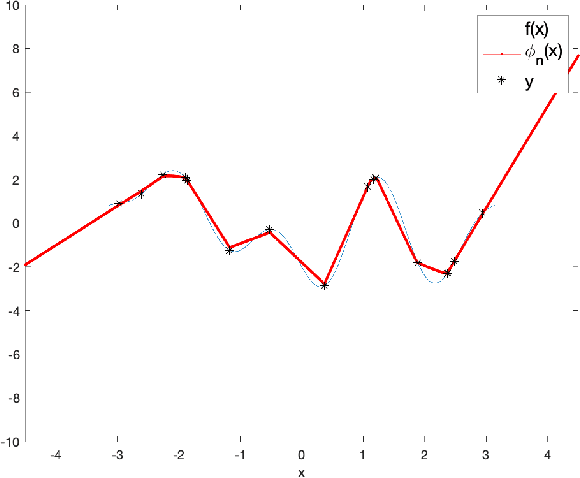
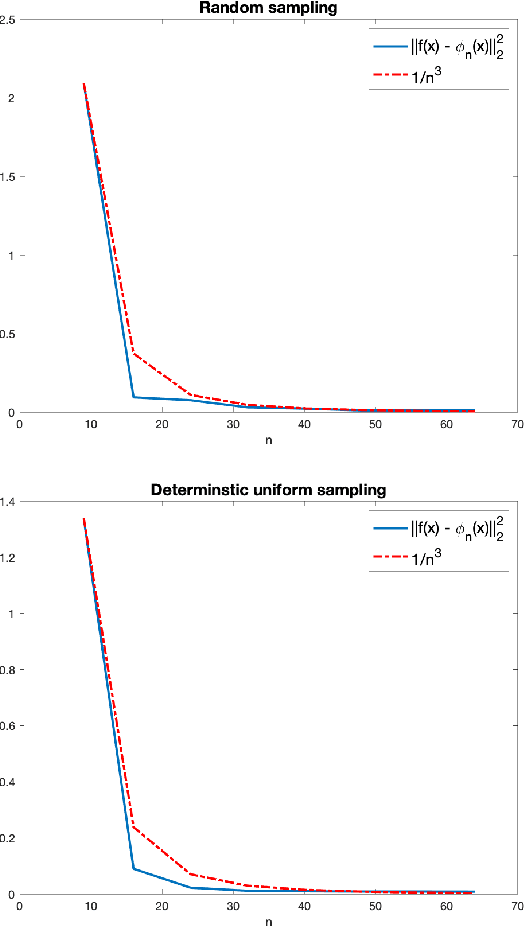
This work suggests using sampling theory to analyze the function space represented by neural networks. First, it shows, under the assumption of a finite input domain, which is the common case in training neural networks, that the function space generated by multi-layer networks with non-expansive activation functions is smooth. This extends over previous works that show results for the case of infinite width ReLU networks. Then, under the assumption that the input is band-limited, we provide novel error bounds for univariate neural networks. We analyze both deterministic uniform and random sampling showing the advantage of the former.
PointGMM: a Neural GMM Network for Point Clouds
Mar 30, 2020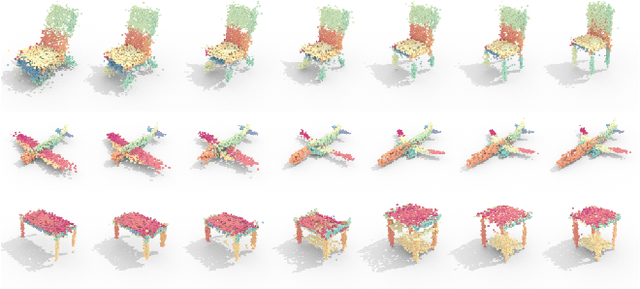
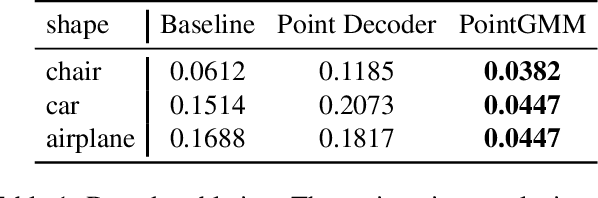
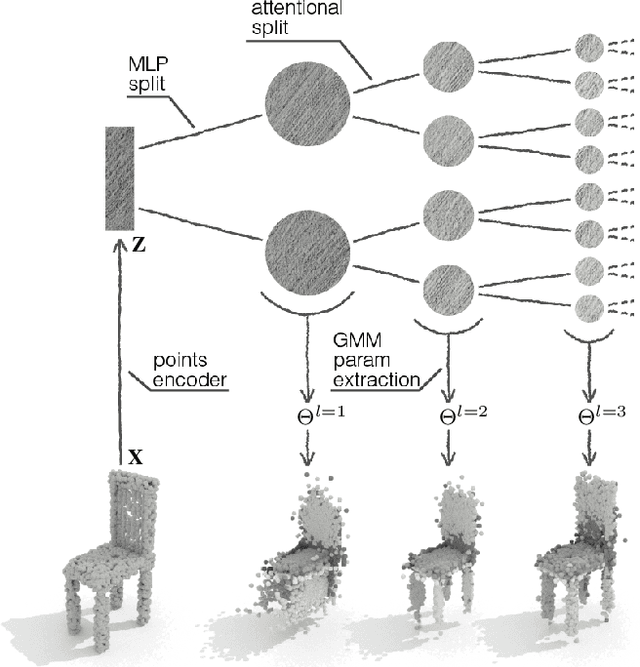
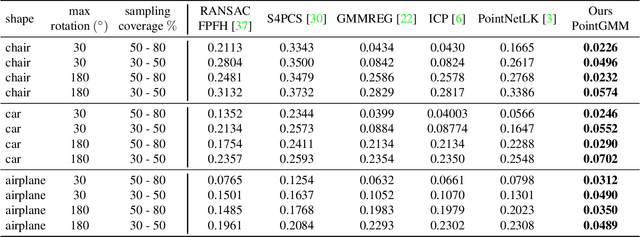
Point clouds are a popular representation for 3D shapes. However, they encode a particular sampling without accounting for shape priors or non-local information. We advocate for the use of a hierarchical Gaussian mixture model (hGMM), which is a compact, adaptive and lightweight representation that probabilistically defines the underlying 3D surface. We present PointGMM, a neural network that learns to generate hGMMs which are characteristic of the shape class, and also coincide with the input point cloud. PointGMM is trained over a collection of shapes to learn a class-specific prior. The hierarchical representation has two main advantages: (i) coarse-to-fine learning, which avoids converging to poor local-minima; and (ii) (an unsupervised) consistent partitioning of the input shape. We show that as a generative model, PointGMM learns a meaningful latent space which enables generating consistent interpolations between existing shapes, as well as synthesizing novel shapes. We also present a novel framework for rigid registration using PointGMM, that learns to disentangle orientation from structure of an input shape.
StarNet: towards weakly supervised few-shot detection and explainable few-shot classification
Mar 15, 2020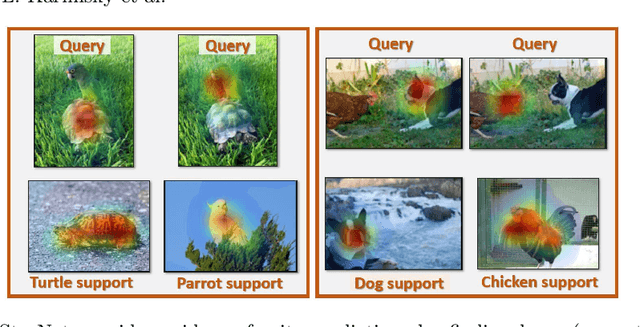
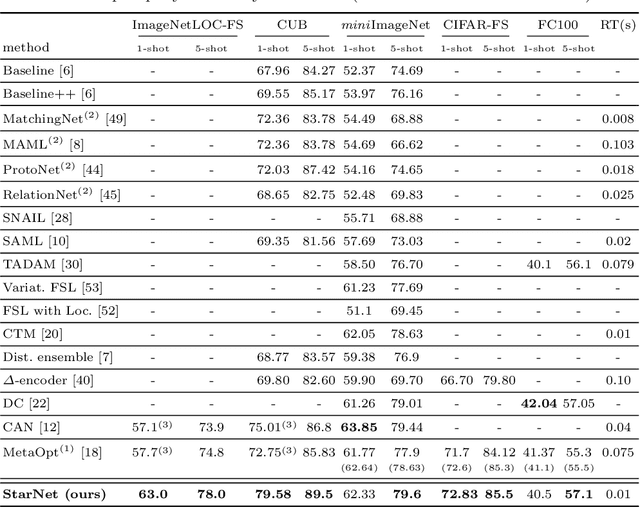
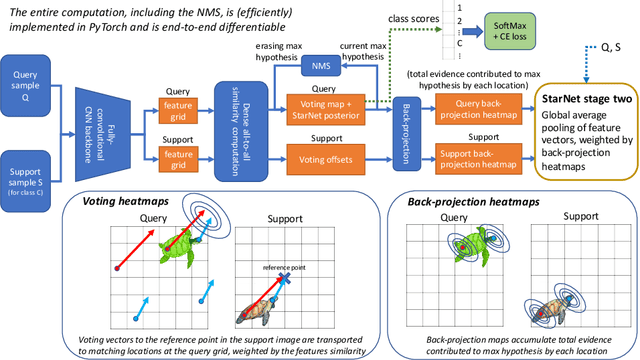
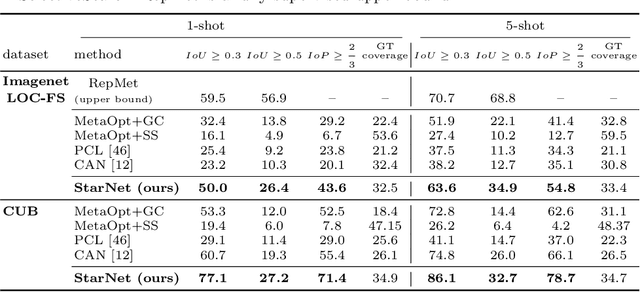
In this paper, we propose a new few-shot learning method called StarNet, which is an end-to-end trainable non-parametric star-model few-shot classifier. While being meta-trained using only image-level class labels, StarNet learns not only to predict the class labels for each query image of a few-shot task, but also to localize (via a heatmap) what it believes to be the key image regions supporting its prediction, thus effectively detecting the instances of the novel categories. The localization is enabled by the StarNet's ability to find large, arbitrarily shaped, semantically matching regions between all pairs of support and query images of a few-shot task. We evaluate StarNet on multiple few-shot classification benchmarks attaining significant state-of-the-art improvement on the CUB and ImageNetLOC-FS, and smaller improvements on other benchmarks. At the same time, in many cases, StarNet provides plausible explanations for its class label predictions, by highlighting the correctly paired novel category instances on the query and on its best matching support (for the predicted class). In addition, we test the proposed approach on the previously unexplored and challenging task of Weakly Supervised Few-Shot Object Detection (WS-FSOD), obtaining significant improvements over the baselines.
TAFSSL: Task-Adaptive Feature Sub-Space Learning for few-shot classification
Mar 14, 2020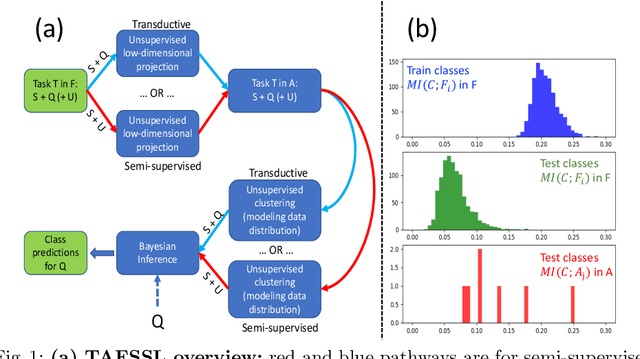
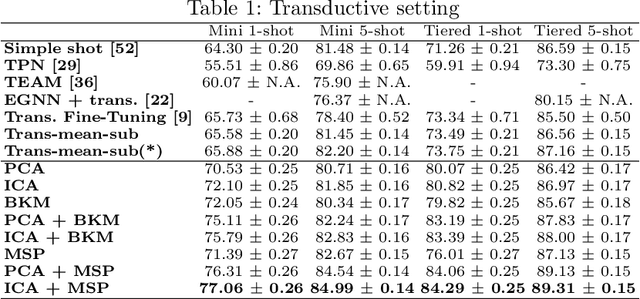
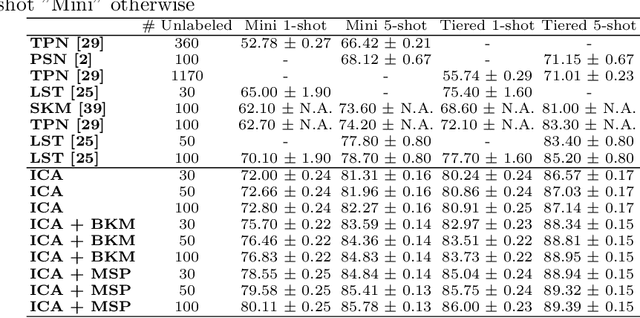
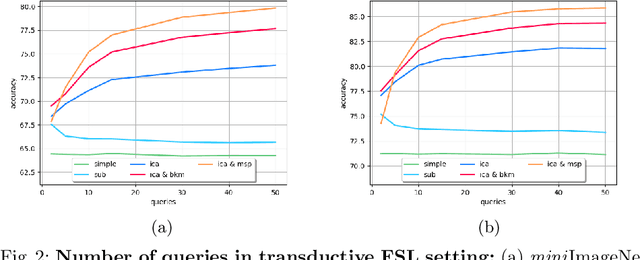
The field of Few-Shot Learning (FSL), or learning from very few (typically $1$ or $5$) examples per novel class (unseen during training), has received a lot of attention and significant performance advances in the recent literature. While number of techniques have been proposed for FSL, several factors have emerged as most important for FSL performance, awarding SOTA even to the simplest of techniques. These are: the backbone architecture (bigger is better), type of pre-training on the base classes (meta-training vs regular multi-class, currently regular wins), quantity and diversity of the base classes set (the more the merrier, resulting in richer and better adaptive features), and the use of self-supervised tasks during pre-training (serving as a proxy for increasing the diversity of the base set). In this paper we propose yet another simple technique that is important for the few shot learning performance - a search for a compact feature sub-space that is discriminative for a given few-shot test task. We show that the Task-Adaptive Feature Sub-Space Learning (TAFSSL) can significantly boost the performance in FSL scenarios when some additional unlabeled data accompanies the novel few-shot task, be it either the set of unlabeled queries (transductive FSL) or some additional set of unlabeled data samples (semi-supervised FSL). Specifically, we show that on the challenging miniImageNet and tieredImageNet benchmarks, TAFSSL can improve the current state-of-the-art in both transductive and semi-supervised FSL settings by more than $5\%$, while increasing the benefit of using unlabeled data in FSL to above $10\%$ performance gain.
Autoencoders
Mar 12, 2020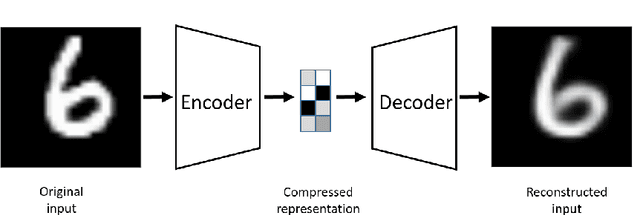
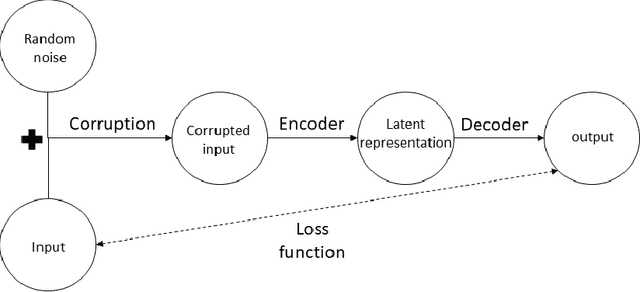

An autoencoder is a specific type of a neural network, which is mainlydesigned to encode the input into a compressed and meaningful representation, andthen decode it back such that the reconstructed input is similar as possible to theoriginal one. This chapter surveys the different types of autoencoders that are mainlyused today. It also describes various applications and use-cases of autoencoders.
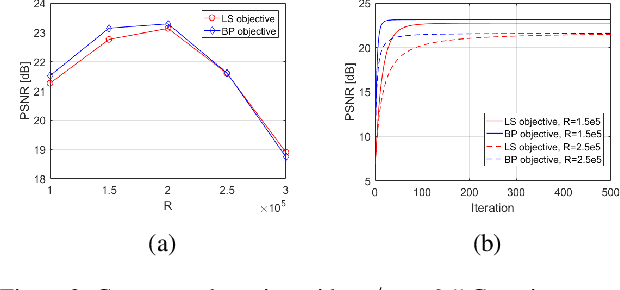
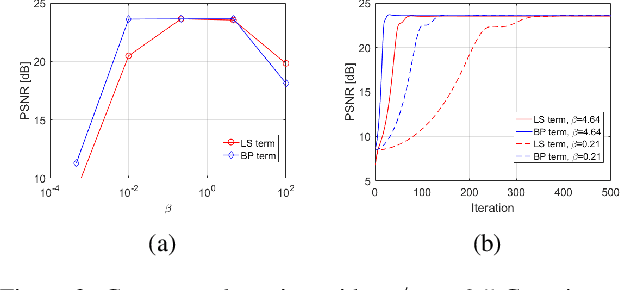
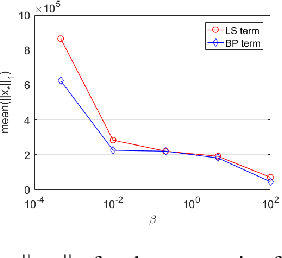
BP-DIP: A Backprojection based Deep Image Prior
Mar 11, 2020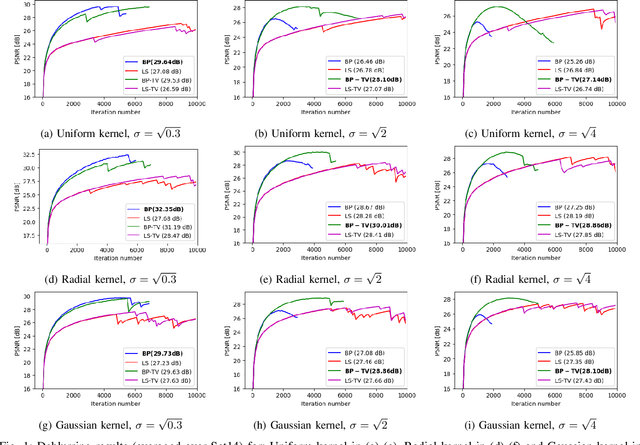



Deep neural networks are a very powerful tool for many computer vision tasks, including image restoration, exhibiting state-of-the-art results. However, the performance of deep learning methods tends to drop once the observation model used in training mismatches the one in test time. In addition, most deep learning methods require vast amounts of training data, which are not accessible in many applications. To mitigate these disadvantages, we propose to combine two image restoration approaches: (i) Deep Image Prior (DIP), which trains a convolutional neural network (CNN) from scratch in test time using the given degraded image. It does not require any training data and builds on the implicit prior imposed by the CNN architecture; and (ii) a backprojection (BP) fidelity term, which is an alternative to the standard least squares loss that is usually used in previous DIP works. We demonstrate the performance of the proposed method, termed BP-DIP, on the deblurring task and show its advantages over the plain DIP, with both higher PSNR values and better inference run-time.
Introduction to deep learning
Feb 29, 2020
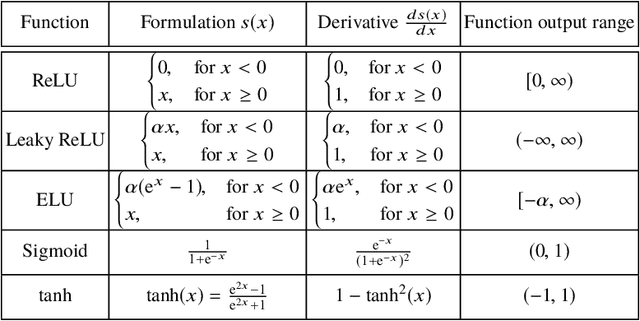
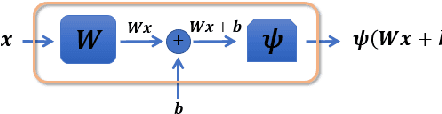

Deep Learning (DL) has made a major impact on data science in the last decade. This chapter introduces the basic concepts of this field. It includes both the basic structures used to design deep neural networks and a brief survey of some of its popular use cases.