 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Active Speaker Faces for Diarization in TV shows
Mar 30, 2022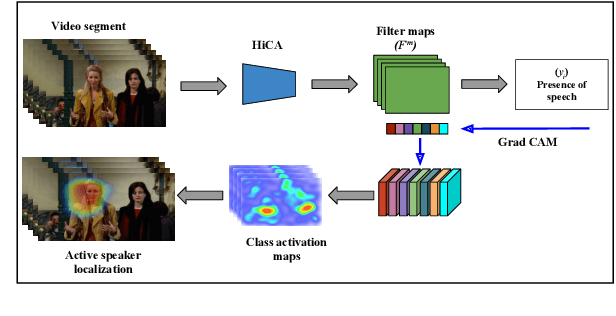
Speaker diarization is one of the critical components of computational media intelligence as it enables a character-level analysis of story portrayals and media content understanding. Automated audio-based speaker diarization of entertainment media poses challenges due to the diverse acoustic conditions present in media content, be it background music, overlapping speakers, or sound effects. At the same time, speaking faces in the visual modality provide complementary information and not prone to the errors seen in the audio modality. In this paper, we address the problem of speaker diarization in TV shows using the active speaker faces. We perform face clustering on the active speaker faces and show superior speaker diarization performance compared to the state-of-the-art audio-based diarization methods. We additionally report a systematic analysis of the impact of active speaker face detection quality on the diarization performance. We also observe that a moderately well-performing active speaker system could outperform the audio-based diarization systems.
Audio visual character profiles for detecting background characters in entertainment media
Mar 21, 2022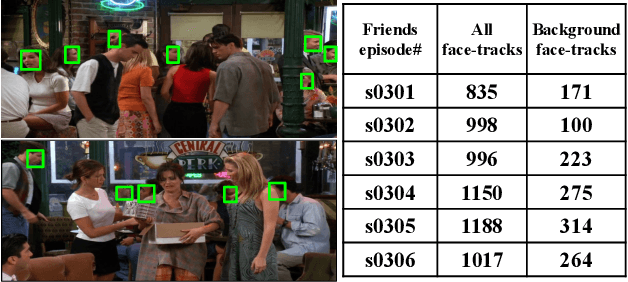
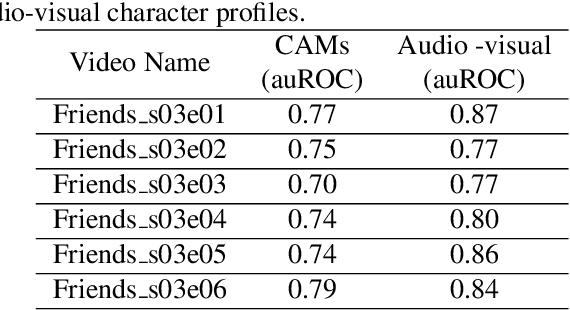
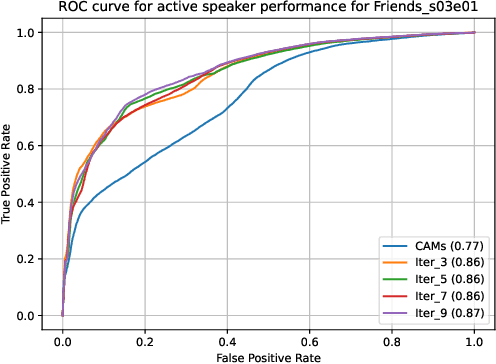
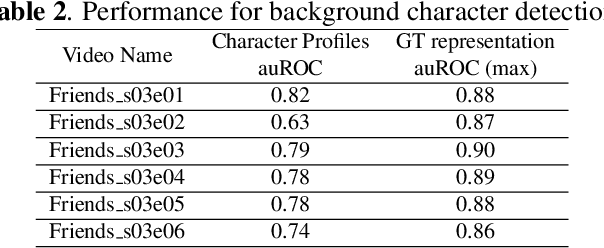
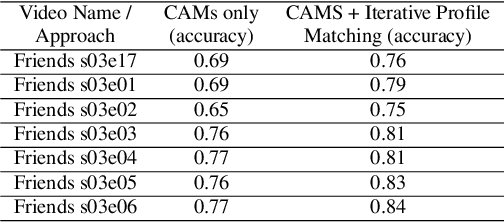
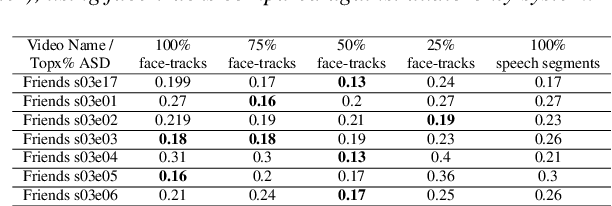
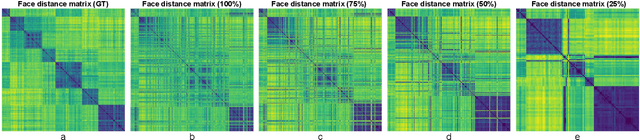
An essential goal of computational media intelligence is to support understanding how media stories -- be it news, commercial or entertainment media -- represent and reflect society and these portrayals are perceived. People are a central element of media stories. This paper focuses on understanding the representation and depiction of background characters in media depictions, primarily movies and TV shows. We define the background characters as those who do not participate vocally in any scene throughout the movie and address the problem of localizing background characters in videos. We use an active speaker localization system to extract high-confidence face-speech associations and generate audio-visual profiles for talking characters in a movie by automatically clustering them. Using a face verification system, we then prune all the face-tracks which match any of the generated character profiles and obtain the background character face-tracks. We curate a background character dataset which provides annotations for background character for a set of TV shows, and use it to evaluate the performance of the background character detection framework.
Phonetic Word Embeddings
Sep 30, 2021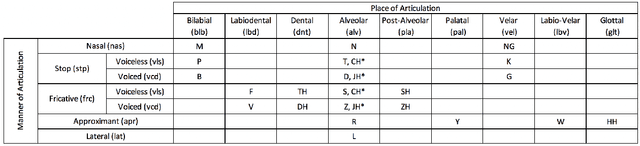
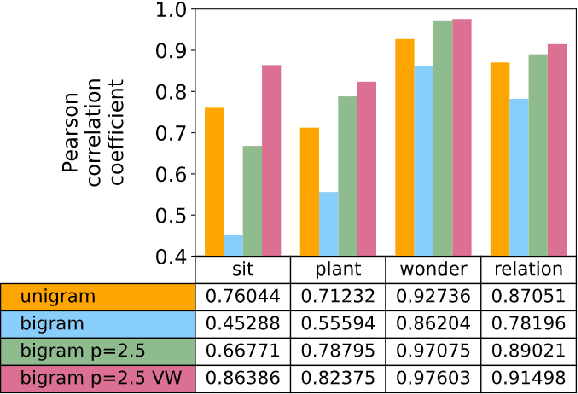
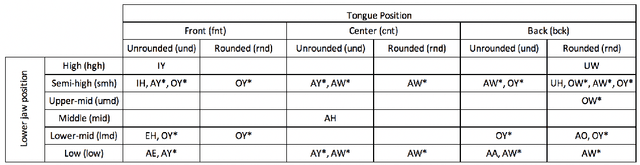
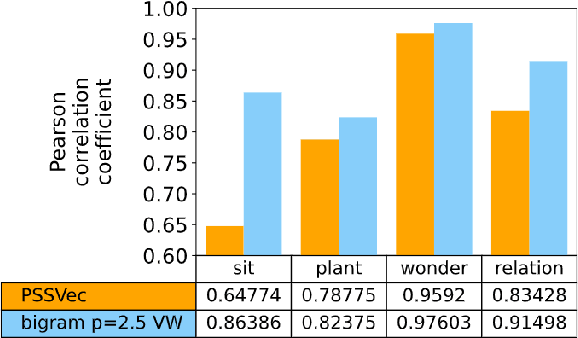
This work presents a novel methodology for calculating the phonetic similarity between words taking motivation from the human perception of sounds. This metric is employed to learn a continuous vector embedding space that groups similar sounding words together and can be used for various downstream computational phonology tasks. The efficacy of the method is presented for two different languages (English, Hindi) and performance gains over previous reported works are discussed on established tests for predicting phonetic similarity. To address limited benchmarking mechanisms in this field, we also introduce a heterographic pun dataset based evaluation methodology to compare the effectiveness of acoustic similarity algorithms. Further, a visualization of the embedding space is presented with a discussion on the various possible use-cases of this novel algorithm. An open-source implementation is also shared to aid reproducibility and enable adoption in related tasks.
MAFIA: Machine Learning Acceleration on FPGAs for IoT Applications
Jul 08, 2021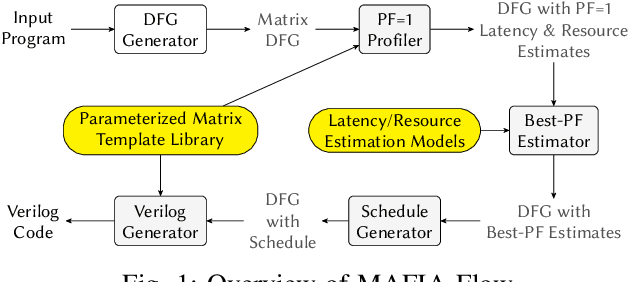
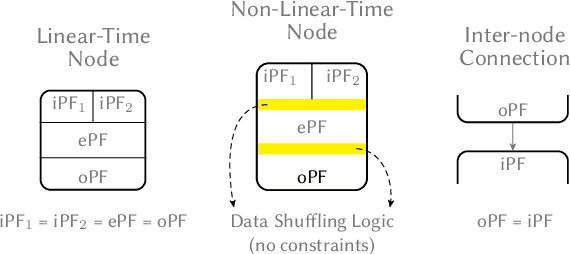
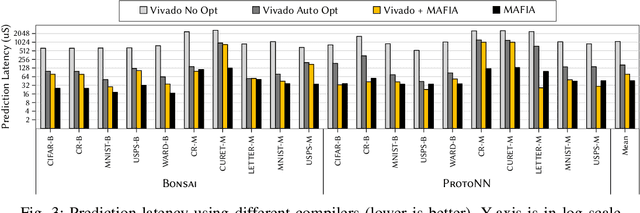
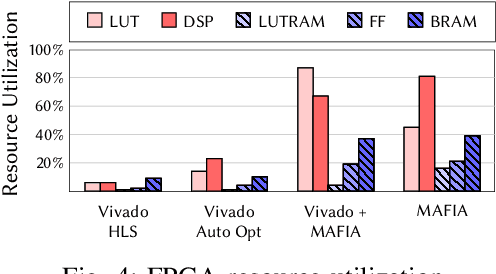
Recent breakthroughs in ML have produced new classes of models that allow ML inference to run directly on milliwatt-powered IoT devices. On one hand, existing ML-to-FPGA compilers are designed for deep neural-networks on large FPGAs. On the other hand, general-purpose HLS tools fail to exploit properties specific to ML inference, thereby resulting in suboptimal performance. We propose MAFIA, a tool to compile ML inference on small form-factor FPGAs for IoT applications. MAFIA provides native support for linear algebra operations and can express a variety of ML algorithms, including state-of-the-art models. We show that MAFIA-generated programs outperform best-performing variant of a commercial HLS compiler by 2.5x on average.
SIRNN: A Math Library for Secure RNN Inference
May 10, 2021
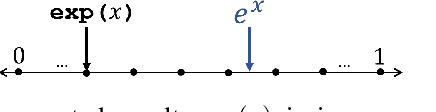


Complex machine learning (ML) inference algorithms like recurrent neural networks (RNNs) use standard functions from math libraries like exponentiation, sigmoid, tanh, and reciprocal of square root. Although prior work on secure 2-party inference provides specialized protocols for convolutional neural networks (CNNs), existing secure implementations of these math operators rely on generic 2-party computation (2PC) protocols that suffer from high communication. We provide new specialized 2PC protocols for math functions that crucially rely on lookup-tables and mixed-bitwidths to address this performance overhead; our protocols for math functions communicate up to 423x less data than prior work. Some of the mixed bitwidth operations used by our math implementations are (zero and signed) extensions, different forms of truncations, multiplication of operands of mixed-bitwidths, and digit decomposition (a generalization of bit decomposition to larger digits). For each of these primitive operations, we construct specialized 2PC protocols that are more communication efficient than generic 2PC, and can be of independent interest. Furthermore, our math implementations are numerically precise, which ensures that the secure implementations preserve model accuracy of cleartext. We build on top of our novel protocols to build SIRNN, a library for end-to-end secure 2-party DNN inference, that provides the first secure implementations of an RNN operating on time series sensor data, an RNN operating on speech data, and a state-of-the-art ML architecture that combines CNNs and RNNs for identifying all heads present in images. Our evaluation shows that SIRNN achieves up to three orders of magnitude of performance improvement when compared to inference of these models using an existing state-of-the-art 2PC framework.
Variational Rejection Particle Filtering
Mar 29, 2021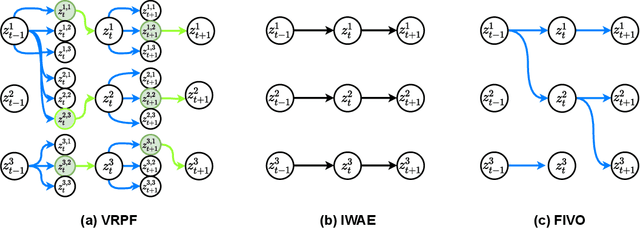
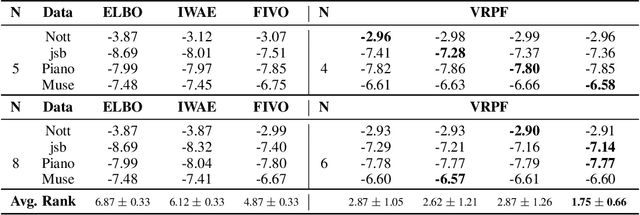
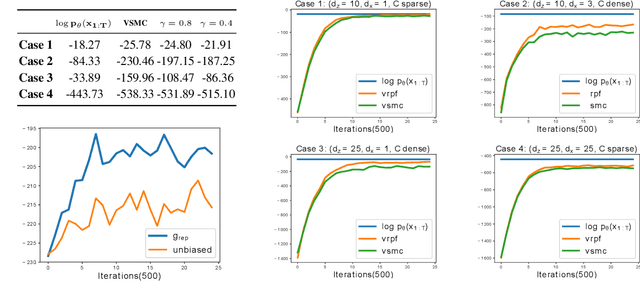
We present a variational inference (VI) framework that unifies and leverages sequential Monte-Carlo (particle filtering) with \emph{approximate} rejection sampling to construct a flexible family of variational distributions. Furthermore, we augment this approach with a resampling step via Bernoulli race, a generalization of a Bernoulli factory, to obtain a low-variance estimator of the marginal likelihood. Our framework, Variational Rejection Particle Filtering (VRPF), leads to novel variational bounds on the marginal likelihood, which can be optimized efficiently with respect to the variational parameters and generalizes several existing approaches in the VI literature. We also present theoretical properties of the variational bound and demonstrate experiments on various models of sequential data, such as the Gaussian state-space model and variational recurrent neural net (VRNN), on which VRPF outperforms various existing state-of-the-art VI methods.
CrypTFlow2: Practical 2-Party Secure Inference
Oct 13, 2020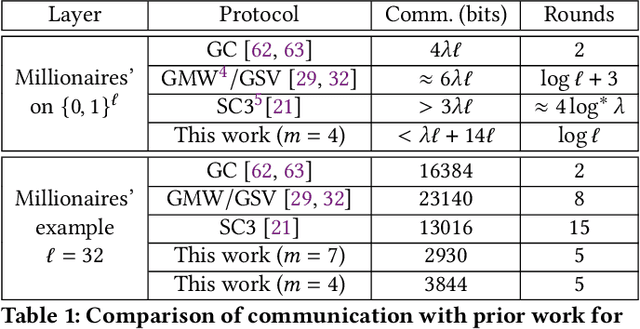
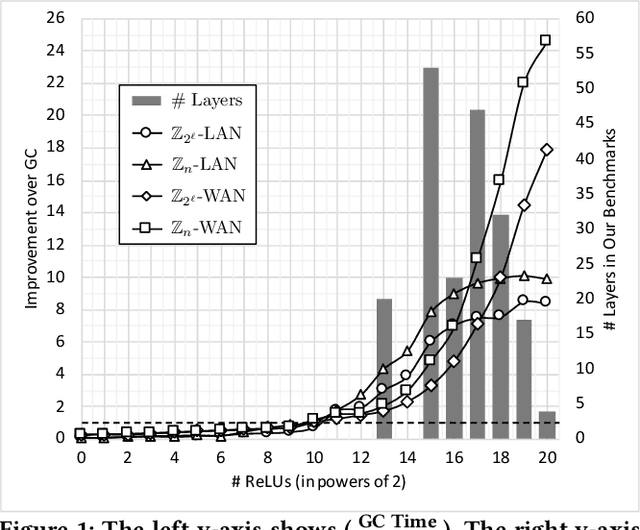
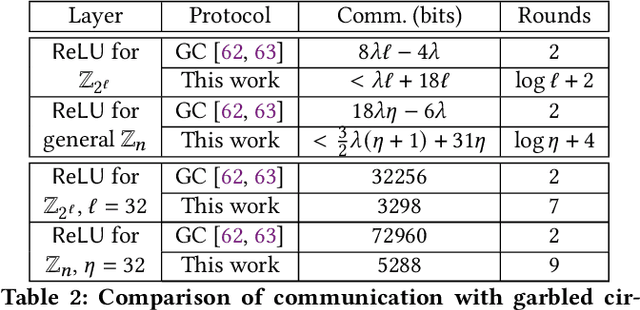
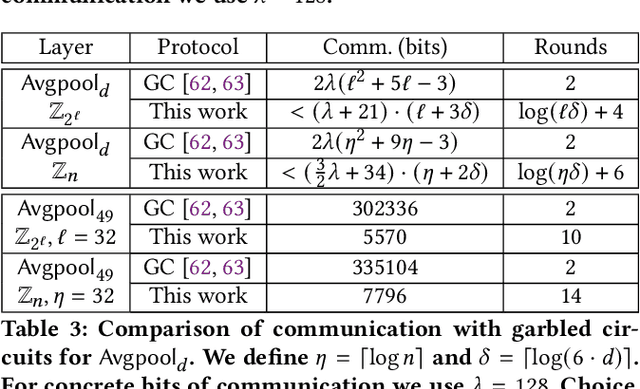
We present CrypTFlow2, a cryptographic framework for secure inference over realistic Deep Neural Networks (DNNs) using secure 2-party computation. CrypTFlow2 protocols are both correct -- i.e., their outputs are bitwise equivalent to the cleartext execution -- and efficient -- they outperform the state-of-the-art protocols in both latency and scale. At the core of CrypTFlow2, we have new 2PC protocols for secure comparison and division, designed carefully to balance round and communication complexity for secure inference tasks. Using CrypTFlow2, we present the first secure inference over ImageNet-scale DNNs like ResNet50 and DenseNet121. These DNNs are at least an order of magnitude larger than those considered in the prior work of 2-party DNN inference. Even on the benchmarks considered by prior work, CrypTFlow2 requires an order of magnitude less communication and 20x-30x less time than the state-of-the-art.
Crossmodal learning for audio-visual speech event localization
Mar 09, 2020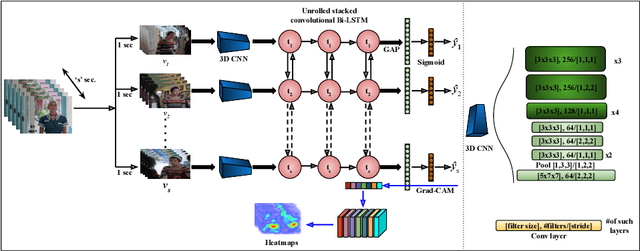
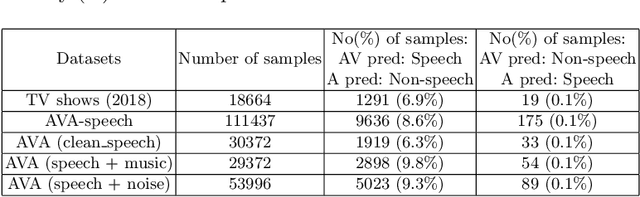


An objective understanding of media depictions, such as about inclusive portrayals of how much someone is heard and seen on screen in film and television, requires the machines to discern automatically who, when, how and where someone is talking. Media content is rich in multiple modalities such as visuals and audio which can be used to learn speaker activity in videos. In this work, we present visual representations that have implicit information about when someone is talking and where. We propose a crossmodal neural network for audio speech event detection using the visual frames. We use the learned representations for two downstream tasks: i) audio-visual voice activity detection ii) active speaker localization in video frames. We present a state-of-the-art audio-visual voice activity detection system and demonstrate that the learned embeddings can effectively localize to active speakers in the visual frames.
OASIS: ILP-Guided Synthesis of Loop Invariants
Nov 26, 2019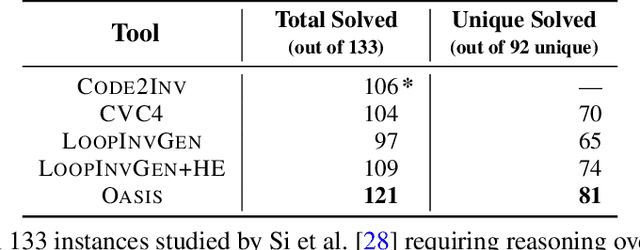
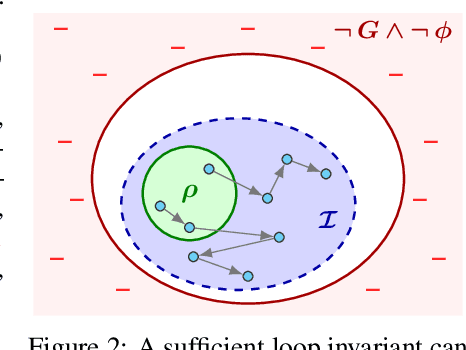

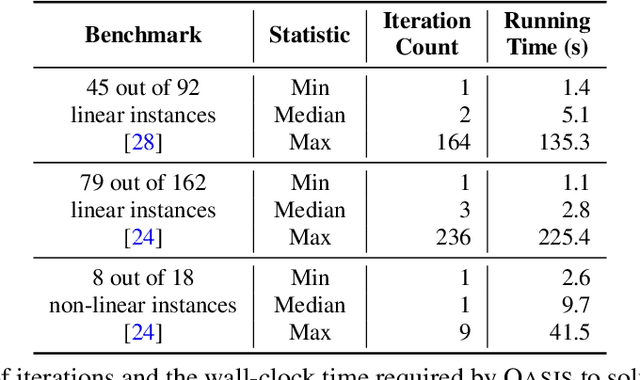
Finding appropriate inductive loop invariants for a program is a key challenge in verifying its functional properties. Although the problem is undecidable in general, several heuristics have been proposed to handle practical programs that tend to have simple control-flow structures. However, these heuristics only work well when the space of invariants is small. On the other hand, machine-learned techniques that use continuous optimization have a high sample complexity, i.e., the number of invariant guesses and the associated counterexamples, since the invariant is required to exactly satisfy a specification. We propose a novel technique that is able to solve complex verification problems involving programs with larger number of variables and non-linear specifications. We formulate an invariant as a piecewise low-degree polynomial, and reduce the problem of synthesizing it to a set of integer linear programming (ILP) problems. This enables the use of state-of-the-art ILP techniques that combine enumerative search with continuous optimization; thus ensuring fast convergence for a large class of verification tasks while still ensuring low sample complexity. We instantiate our technique as the open-source oasis tool using an off-the-shelf ILP solver, and evaluate it on more than 300 benchmark tasks collected from the annual SyGuS competition and recent prior work. Our experiments show that oasis outperforms the state-of-the-art tools, including the winner of last year's SyGuS competition, and is able to solve 9 challenging tasks that existing tools fail on.
Refined $α$-Divergence Variational Inference via Rejection Sampling
Oct 29, 2019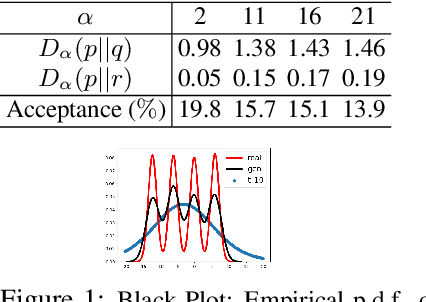
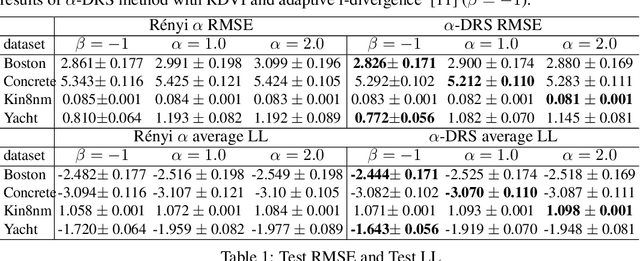
We present an approximate inference method, based on a synergistic combination of R\'enyi $\alpha$-divergence variational inference (RDVI) and rejection sampling (RS). RDVI is based on minimization of R\'enyi $\alpha$-divergence $D_\alpha(p||q)$ between the true distribution $p(x)$ and a variational approximation $q(x)$; RS draws samples from a distribution $p(x) = \tilde{p}(x)/Z_{p}$ using a proposal $q(x)$, s.t. $Mq(x) \geq \tilde{p}(x), \forall x$. Our inference method is based on a crucial observation that $D_\infty(p||q)$ equals $\log M(\theta)$ where $M(\theta)$ is the optimal value of the RS constant for a given proposal $q_\theta(x)$. This enables us to develop a \emph{two-stage} hybrid inference algorithm. Stage-1 performs RDVI to learn $q_\theta$ by minimizing an estimator of $D_\alpha(p||q)$, and uses the learned $q_\theta$ to find an (approximately) optimal $\tilde{M}(\theta)$. Stage-2 performs RS using the constant $\tilde{M}(\theta)$ to improve the approximate distribution $q_\theta$ and obtain a sample-based approximation. We prove that this two-stage method allows us to learn considerably more accurate approximations of the target distribution as compared to RDVI. We demonstrate our method's efficacy via several experiments on synthetic and real datasets.