 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREST: Robust and Efficient Neural Networks for Sleep Monitoring in the Wild
Jan 29, 2020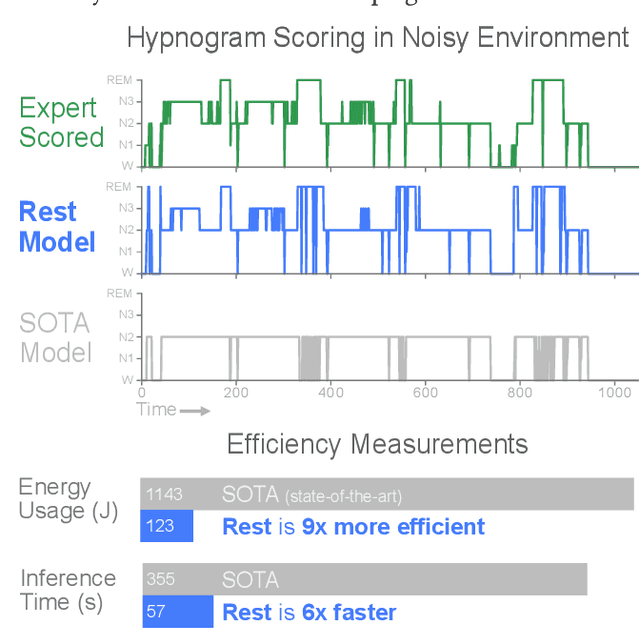
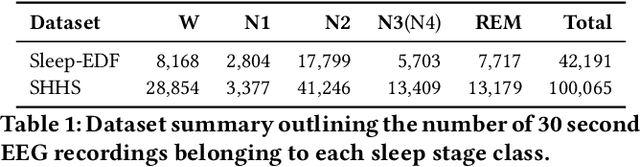
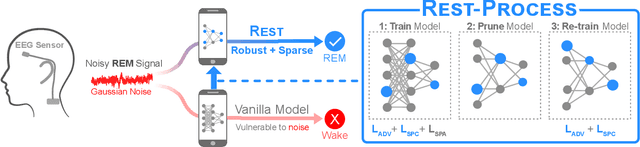
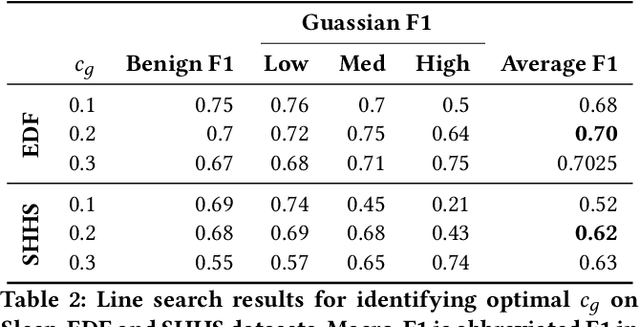
In recent years, significant attention has been devoted towards integrating deep learning technologies in the healthcare domain. However, to safely and practically deploy deep learning models for home health monitoring, two significant challenges must be addressed: the models should be (1) robust against noise; and (2) compact and energy-efficient. We propose REST, a new method that simultaneously tackles both issues via 1) adversarial training and controlling the Lipschitz constant of the neural network through spectral regularization while 2) enabling neural network compression through sparsity regularization. We demonstrate that REST produces highly-robust and efficient models that substantially outperform the original full-sized models in the presence of noise. For the sleep staging task over single-channel electroencephalogram (EEG), the REST model achieves a macro-F1 score of 0.67 vs. 0.39 achieved by a state-of-the-art model in the presence of Gaussian noise while obtaining 19x parameter reduction and 15x MFLOPS reduction on two large, real-world EEG datasets. By deploying these models to an Android application on a smartphone, we quantitatively observe that REST allows models to achieve up to 17x energy reduction and 9x faster inference. We open-source the code repository with this paper: https://github.com/duggalrahul/REST.
CUP: Cluster Pruning for Compressing Deep Neural Networks
Nov 19, 2019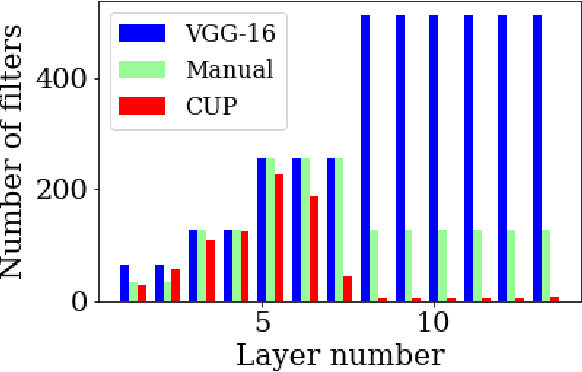
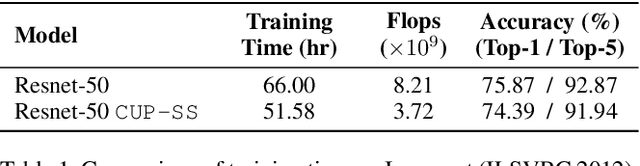
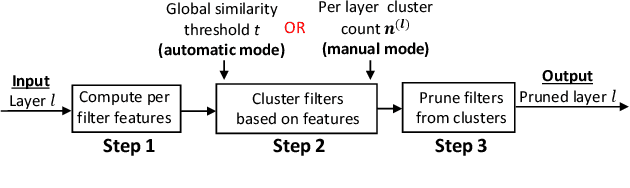
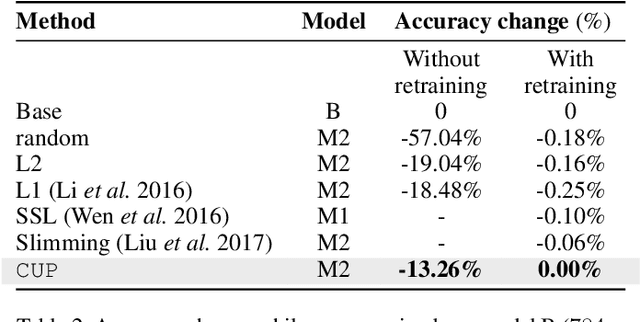
We propose Cluster Pruning (CUP) for compressing and accelerating deep neural networks. Our approach prunes similar filters by clustering them based on features derived from both the incoming and outgoing weight connections. With CUP, we overcome two limitations of prior work-(1) non-uniform pruning: CUP can efficiently determine the ideal number of filters to prune in each layer of a neural network. This is in contrast to prior methods that either prune all layers uniformly or otherwise use resource-intensive methods such as manual sensitivity analysis or reinforcement learning to determine the ideal number. (2) Single-shot operation: We extend CUP to CUP-SS (for CUP single shot) whereby pruning is integrated into the initial training phase itself. This leads to large savings in training time compared to traditional pruning pipelines. Through extensive evaluation on multiple datasets (MNIST, CIFAR-10, and Imagenet) and models(VGG-16, Resnets-18/34/56) we show that CUP outperforms recent state of the art. Specifically, CUP-SS achieves 2.2x flops reduction for a Resnet-50 model trained on Imagenet while staying within 0.9% top-5 accuracy. It saves over 14 hours in training time with respect to the original Resnet-50. The code to reproduce results is available.
2017 Robotic Instrument Segmentation Challenge
Feb 21, 2019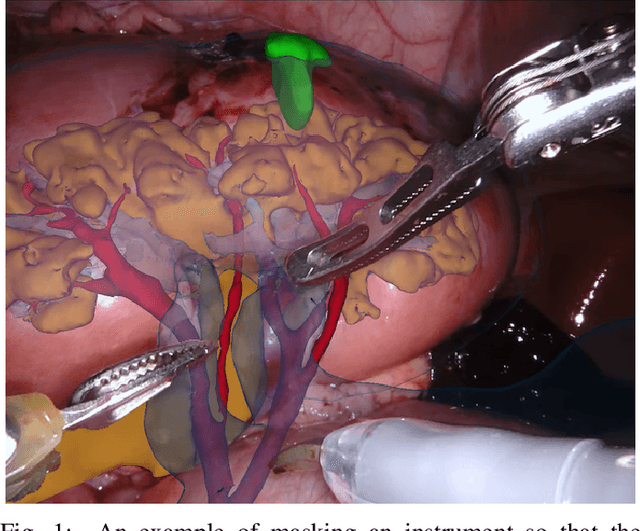
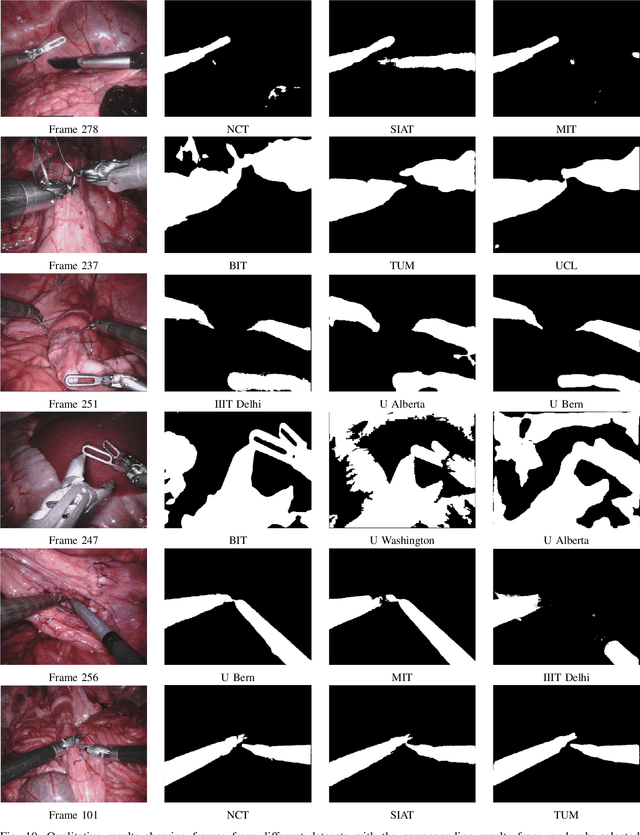
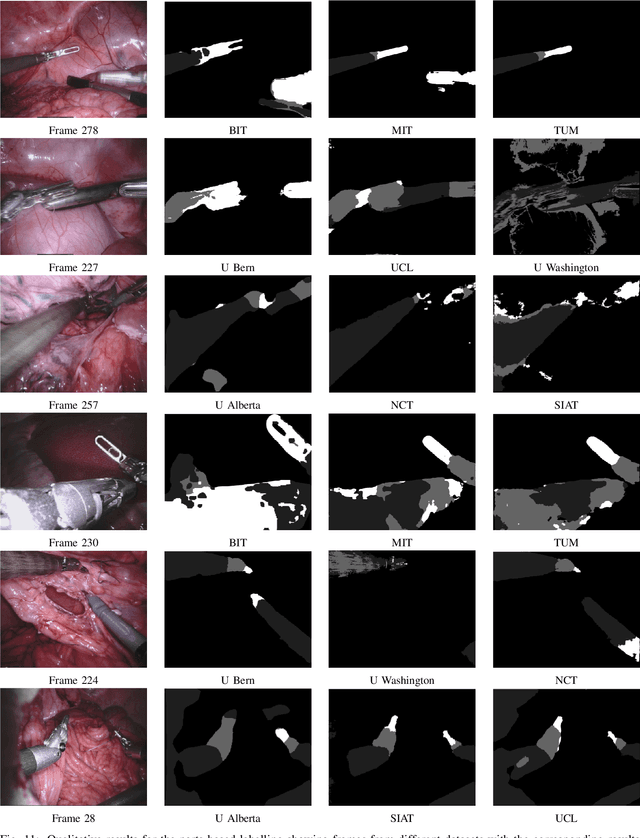

In mainstream computer vision and machine learning, public datasets such as ImageNet, COCO and KITTI have helped drive enormous improvements by enabling researchers to understand the strengths and limitations of different algorithms via performance comparison. However, this type of approach has had limited translation to problems in robotic assisted surgery as this field has never established the same level of common datasets and benchmarking methods. In 2015 a sub-challenge was introduced at the EndoVis workshop where a set of robotic images were provided with automatically generated annotations from robot forward kinematics. However, there were issues with this dataset due to the limited background variation, lack of complex motion and inaccuracies in the annotation. In this work we present the results of the 2017 challenge on robotic instrument segmentation which involved 10 teams participating in binary, parts and type based segmentation of articulated da Vinci robotic instruments.
Design of Image Matched Non-Separable Wavelet using Convolutional Neural Network
Dec 15, 2016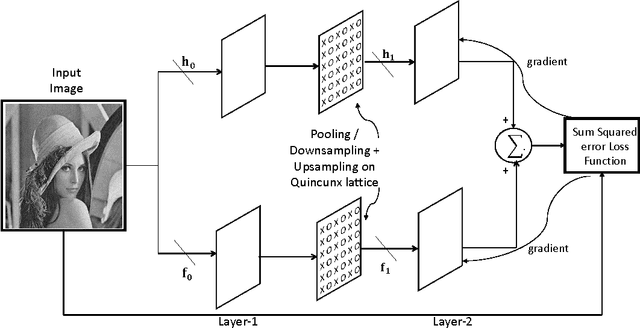
Image-matched nonseparable wavelets can find potential use in many applications including image classification, segmen- tation, compressive sensing, etc. This paper proposes a novel design methodology that utilizes convolutional neural net- work (CNN) to design two-channel non-separable wavelet matched to a given image. The design is proposed on quin- cunx lattice. The loss function of the convolutional neural network is setup with total squared error between the given input image to CNN and the reconstructed image at the output of CNN, leading to perfect reconstruction at the end of train- ing. Simulation results have been shown on some standard images.