 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DN: 3D Deformation Network
Mar 08, 2019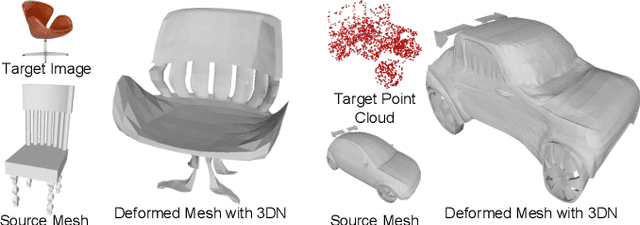
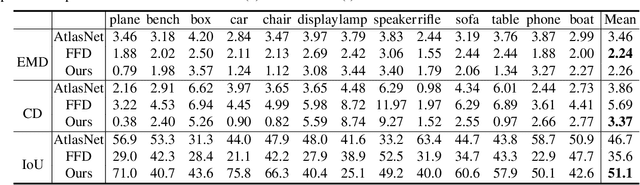
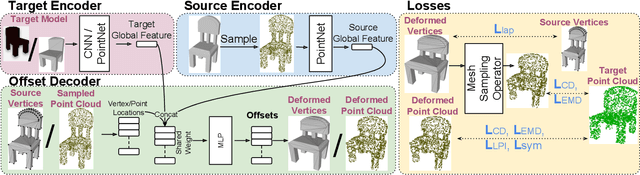
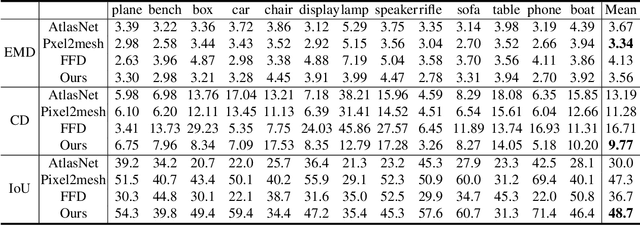
Applications in virtual and augmented reality create a demand for rapid creation and easy access to large sets of 3D models. An effective way to address this demand is to edit or deform existing 3D models based on a reference, e.g., a 2D image which is very easy to acquire. Given such a source 3D model and a target which can be a 2D image, 3D model, or a point cloud acquired as a depth scan, we introduce 3DN, an end-to-end network that deforms the source model to resemble the target. Our method infers per-vertex offset displacements while keeping the mesh connectivity of the source model fixed. We present a training strategy which uses a novel differentiable operation, mesh sampling operator, to generalize our method across source and target models with varying mesh densities. Mesh sampling operator can be seamlessly integrated into the network to handle meshes with different topologies. Qualitative and quantitative results show that our method generates higher quality results compared to the state-of-the art learning-based methods for 3D shape generation. Code is available at github.com/laughtervv/3DN.
Photo-Sketching: Inferring Contour Drawings from Images
Jan 02, 2019


Edges, boundaries and contours are important subjects of study in both computer graphics and computer vision. On one hand, they are the 2D elements that convey 3D shapes, on the other hand, they are indicative of occlusion events and thus separation of objects or semantic concepts. In this paper, we aim to generate contour drawings, boundary-like drawings that capture the outline of the visual scene. Prior art often cast this problem as boundary detection. However, the set of visual cues presented in the boundary detection output are different from the ones in contour drawings, and also the artistic style is ignored. We address these issues by collecting a new dataset of contour drawings and proposing a learning-based method that resolves diversity in the annotation and, unlike boundary detectors, can work with imperfect alignment of the annotation and the actual ground truth. Our method surpasses previous methods quantitatively and qualitatively. Surprisingly, when our model fine-tunes on BSDS500, we achieve the state-of-the-art performance in salient boundary detection, suggesting contour drawing might be a scalable alternative to boundary annotation, which at the same time is easier and more interesting for annotators to draw.
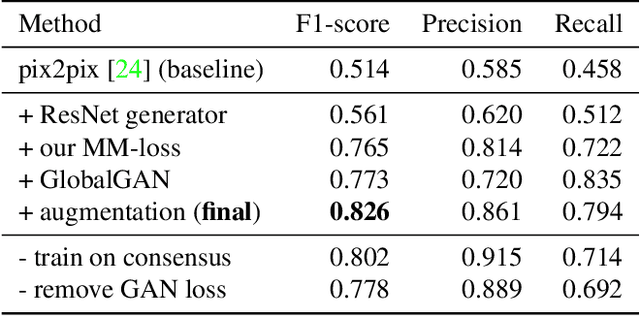
Learning to Detect Multiple Photographic Defects
Mar 08, 2018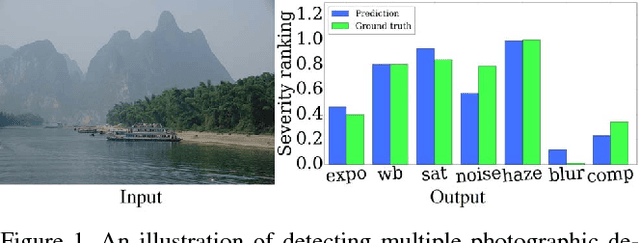


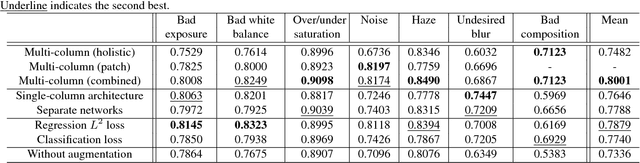
In this paper, we introduce the problem of simultaneously detecting multiple photographic defects. We aim at detecting the existence, severity, and potential locations of common photographic defects related to color, noise, blur and composition. The automatic detection of such defects could be used to provide users with suggestions for how to improve photos without the need to laboriously try various correction methods. Defect detection could also help users select photos of higher quality while filtering out those with severe defects in photo curation and summarization. To investigate this problem, we collected a large-scale dataset of user annotations on seven common photographic defects, which allows us to evaluate algorithms by measuring their consistency with human judgments. Our new dataset enables us to formulate the problem as a multi-task learning problem and train a multi-column deep convolutional neural network (CNN) to simultaneously predict the severity of all the defects. Unlike some existing single-defect estimation methods that rely on low-level statistics and may fail in many cases on natural photographs, our model is able to understand image contents and quality at a higher level. As a result, in our experiments, we show that our model has predictions with much higher consistency with human judgments than low-level methods as well as several baseline CNN models. Our model also performs better than an average human from our user study.
Recognizing and Curating Photo Albums via Event-Specific Image Importance
Jul 19, 2017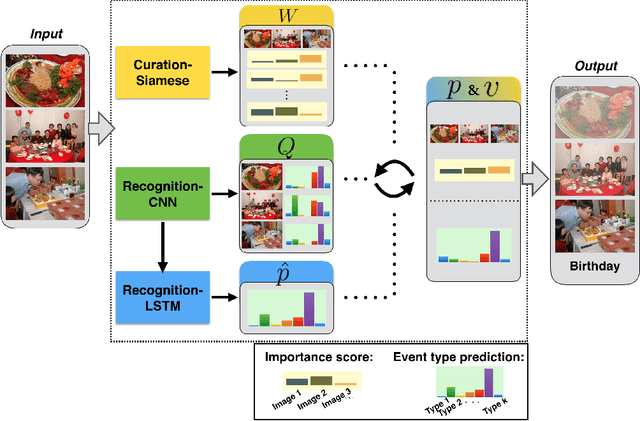
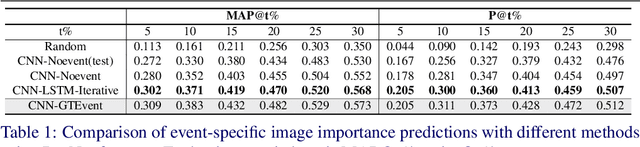
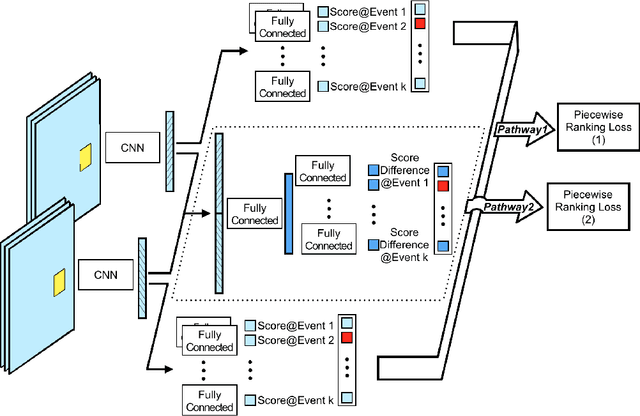
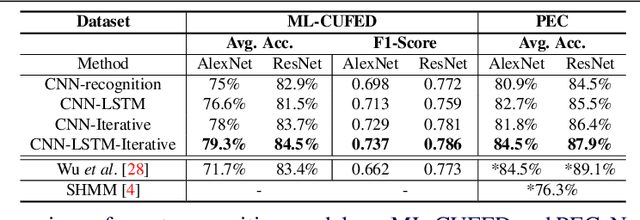
Automatic organization of personal photos is a problem with many real world ap- plications, and can be divided into two main tasks: recognizing the event type of the photo collection, and selecting interesting images from the collection. In this paper, we attempt to simultaneously solve both tasks: album-wise event recognition and image- wise importance prediction. We collected an album dataset with both event type labels and image importance labels, refined from an existing CUFED dataset. We propose a hybrid system consisting of three parts: A siamese network-based event-specific image importance prediction, a Convolutional Neural Network (CNN) that recognizes the event type, and a Long Short-Term Memory (LSTM)-based sequence level event recognizer. We propose an iterative updating procedure for event type and image importance score prediction. We experimentally verified that image importance score prediction and event type recognition can each help the performance of the other.
Photo Aesthetics Ranking Network with Attributes and Content Adaptation
Jul 27, 2016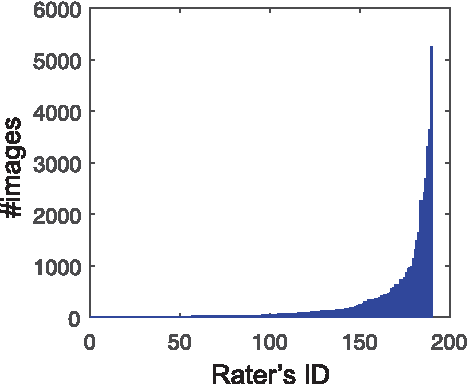

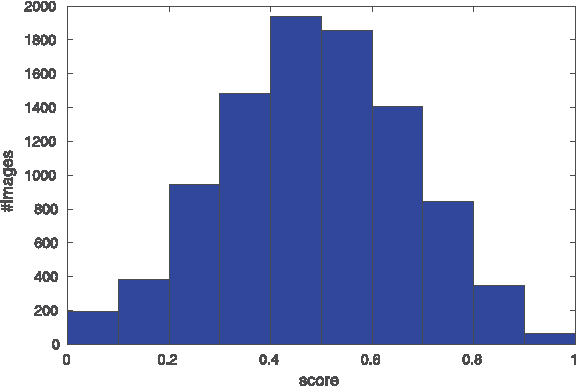
Real-world applications could benefit from the ability to automatically generate a fine-grained ranking of photo aesthetics. However, previous methods for image aesthetics analysis have primarily focused on the coarse, binary categorization of images into high- or low-aesthetic categories. In this work, we propose to learn a deep convolutional neural network to rank photo aesthetics in which the relative ranking of photo aesthetics are directly modeled in the loss function. Our model incorporates joint learning of meaningful photographic attributes and image content information which can help regularize the complicated photo aesthetics rating problem. To train and analyze this model, we have assembled a new aesthetics and attributes database (AADB) which contains aesthetic scores and meaningful attributes assigned to each image by multiple human raters. Anonymized rater identities are recorded across images allowing us to exploit intra-rater consistency using a novel sampling strategy when computing the ranking loss of training image pairs. We show the proposed sampling strategy is very effective and robust in face of subjective judgement of image aesthetics by individuals with different aesthetic tastes. Experiments demonstrate that our unified model can generate aesthetic rankings that are more consistent with human ratings. To further validate our model, we show that by simply thresholding the estimated aesthetic scores, we are able to achieve state-or-the-art classification performance on the existing AVA dataset benchmark.
Salient Object Subitizing
Jul 26, 2016



We study the problem of Salient Object Subitizing, i.e. predicting the existence and the number of salient objects in an image using holistic cues. This task is inspired by the ability of people to quickly and accurately identify the number of items within the subitizing range (1-4). To this end, we present a salient object subitizing image dataset of about 14K everyday images which are annotated using an online crowdsourcing marketplace. We show that using an end-to-end trained Convolutional Neural Network (CNN) model, we achieve prediction accuracy comparable to human performance in identifying images with zero or one salient object. For images with multiple salient objects, our model also provides significantly better than chance performance without requiring any localization process. Moreover, we propose a method to improve the training of the CNN subitizing model by leveraging synthetic images. In experiments, we demonstrate the accuracy and generalizability of our CNN subitizing model and its applications in salient object detection and image retrieval.