 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggregating LLM-Based Weak Verifiers for Spatial Layout Generation
Jun 03, 2026We present a pipeline for building and aggregating task-specific, LLM-generated weak (imperfect) verifiers into a strong verifier for spatial layout domains. Given a task description, our pipeline asks an LLM to synthesize a collection of verifier programs using a layout verification DSL. Each individual LLM-generated verifier usually provides an imperfect check for a match between the layout and the corresponding task description. We show that by aggregating the responses of many such verifiers we can produce a stronger verifier. Moreover, by applying techniques from weak learning, our pipeline can learn how to aggregate the weak verifiers from a very sparse set of human labeled example layouts (about 10). We find that the strong verifiers produced by our pipeline outperform the status-quo approach of using a set of LLM judges to directly check whether a layout matches a task description, raising F1-scores by up to 7X across a variety of 3D room layout and 2D poster design tasks. We also demonstrate that verifier-guided layout generation using natural language feedback from our strong verifiers improves layout quality of a base layout generator by up to 66.2% according to a human evaluator.
Self-Consistency for LLM-Based Motion Trajectory Generation and Verification
Mar 31, 2026Self-consistency has proven to be an effective technique for improving LLM performance on natural language reasoning tasks in a lightweight, unsupervised manner. In this work, we study how to adapt self-consistency to visual domains. Specifically, we consider the generation and verification of LLM-produced motion graphics trajectories. Given a prompt (e.g., "Move the circle in a spiral path"), we first sample diverse motion trajectories from an LLM, and then identify groups of consistent trajectories via clustering. Our key insight is to model the family of shapes associated with a prompt as a prototype trajectory paired with a group of geometric transformations (e.g., rigid, similarity, and affine). Two trajectories can then be considered consistent if one can be transformed into the other under the warps allowable by the transformation group. We propose an algorithm that automatically recovers a shape family, using hierarchical relationships between a set of candidate transformation groups. Our approach improves the accuracy of LLM-based trajectory generation by 4-6%. We further extend our method to support verification, observing 11% precision gains over VLM baselines. Our code and dataset are available at https://majiaju.io/trajectory-self-consistency .
ShapeLib: designing a library of procedural 3D shape abstractions with Large Language Models
Feb 13, 2025



Procedural representations are desirable, versatile, and popular shape encodings. Authoring them, either manually or using data-driven procedures, remains challenging, as a well-designed procedural representation should be compact, intuitive, and easy to manipulate. A long-standing problem in shape analysis studies how to discover a reusable library of procedural functions, with semantically aligned exposed parameters, that can explain an entire shape family. We present ShapeLib as the first method that leverages the priors of frontier LLMs to design a library of 3D shape abstraction functions. Our system accepts two forms of design intent: text descriptions of functions to include in the library and a seed set of exemplar shapes. We discover procedural abstractions that match this design intent by proposing, and then validating, function applications and implementations. The discovered shape functions in the library are not only expressive but also generalize beyond the seed set to a full family of shapes. We train a recognition network that learns to infer shape programs based on our library from different visual modalities (primitives, voxels, point clouds). Our shape functions have parameters that are semantically interpretable and can be modified to produce plausible shape variations. We show that this allows inferred programs to be successfully manipulated by an LLM given a text prompt. We evaluate ShapeLib on different datasets and show clear advantages over existing methods and alternative formulations.
Learning to Edit Visual Programs with Self-Supervision
Jun 04, 2024We design a system that learns how to edit visual programs. Our edit network consumes a complete input program and a visual target. From this input, we task our network with predicting a local edit operation that could be applied to the input program to improve its similarity to the target. In order to apply this scheme for domains that lack program annotations, we develop a self-supervised learning approach that integrates this edit network into a bootstrapped finetuning loop along with a network that predicts entire programs in one-shot. Our joint finetuning scheme, when coupled with an inference procedure that initializes a population from the one-shot model and evolves members of this population with the edit network, helps to infer more accurate visual programs. Over multiple domains, we experimentally compare our method against the alternative of using only the one-shot model, and find that even under equal search-time budgets, our editing-based paradigm provides significant advantages.
ParSEL: Parameterized Shape Editing with Language
May 31, 2024The ability to edit 3D assets from natural language presents a compelling paradigm to aid in the democratization of 3D content creation. However, while natural language is often effective at communicating general intent, it is poorly suited for specifying precise manipulation. To address this gap, we introduce ParSEL, a system that enables controllable editing of high-quality 3D assets from natural language. Given a segmented 3D mesh and an editing request, ParSEL produces a parameterized editing program. Adjusting the program parameters allows users to explore shape variations with a precise control over the magnitudes of edits. To infer editing programs which align with an input edit request, we leverage the abilities of large-language models (LLMs). However, while we find that LLMs excel at identifying initial edit operations, they often fail to infer complete editing programs, and produce outputs that violate shape semantics. To overcome this issue, we introduce Analytical Edit Propagation (AEP), an algorithm which extends a seed edit with additional operations until a complete editing program has been formed. Unlike prior methods, AEP searches for analytical editing operations compatible with a range of possible user edits through the integration of computer algebra systems for geometric analysis. Experimentally we demonstrate ParSEL's effectiveness in enabling controllable editing of 3D objects through natural language requests over alternative system designs.
Learning to Infer Generative Template Programs for Visual Concepts
Mar 20, 2024



People grasp flexible visual concepts from a few examples. We explore a neurosymbolic system that learns how to infer programs that capture visual concepts in a domain-general fashion. We introduce Template Programs: programmatic expressions from a domain-specific language that specify structural and parametric patterns common to an input concept. Our framework supports multiple concept-related tasks, including few-shot generation and co-segmentation through parsing. We develop a learning paradigm that allows us to train networks that infer Template Programs directly from visual datasets that contain concept groupings. We run experiments across multiple visual domains: 2D layouts, Omniglot characters, and 3D shapes. We find that our method outperforms task-specific alternatives, and performs competitively against domain-specific approaches for the limited domains where they exist.
Improving Unsupervised Visual Program Inference with Code Rewriting Families
Sep 26, 2023Programs offer compactness and structure that makes them an attractive representation for visual data. We explore how code rewriting can be used to improve systems for inferring programs from visual data. We first propose Sparse Intermittent Rewrite Injection (SIRI), a framework for unsupervised bootstrapped learning. SIRI sparsely applies code rewrite operations over a dataset of training programs, injecting the improved programs back into the training set. We design a family of rewriters for visual programming domains: parameter optimization, code pruning, and code grafting. For three shape programming languages in 2D and 3D, we show that using SIRI with our family of rewriters improves performance: better reconstructions and faster convergence rates, compared with bootstrapped learning methods that do not use rewriters or use them naively. Finally, we demonstrate that our family of rewriters can be effectively used at test time to improve the output of SIRI predictions. For 2D and 3D CSG, we outperform or match the reconstruction performance of recent domain-specific neural architectures, while producing more parsimonious programs that use significantly fewer primitives.
ShapeCoder: Discovering Abstractions for Visual Programs from Unstructured Primitives
May 09, 2023Programs are an increasingly popular representation for visual data, exposing compact, interpretable structure that supports manipulation. Visual programs are usually written in domain-specific languages (DSLs). Finding "good" programs, that only expose meaningful degrees of freedom, requires access to a DSL with a "good" library of functions, both of which are typically authored by domain experts. We present ShapeCoder, the first system capable of taking a dataset of shapes, represented with unstructured primitives, and jointly discovering (i) useful abstraction functions and (ii) programs that use these abstractions to explain the input shapes. The discovered abstractions capture common patterns (both structural and parametric) across the dataset, so that programs rewritten with these abstractions are more compact, and expose fewer degrees of freedom. ShapeCoder improves upon previous abstraction discovery methods, finding better abstractions, for more complex inputs, under less stringent input assumptions. This is principally made possible by two methodological advancements: (a) a shape to program recognition network that learns to solve sub-problems and (b) the use of e-graphs, augmented with a conditional rewrite scheme, to determine when abstractions with complex parametric expressions can be applied, in a tractable manner. We evaluate ShapeCoder on multiple datasets of 3D shapes, where primitive decompositions are either parsed from manual annotations or produced by an unsupervised cuboid abstraction method. In all domains, ShapeCoder discovers a library of abstractions that capture high-level relationships, remove extraneous degrees of freedom, and achieve better dataset compression compared with alternative approaches. Finally, we investigate how programs rewritten to use discovered abstractions prove useful for downstream tasks.
SHRED: 3D Shape Region Decomposition with Learned Local Operations
Jun 07, 2022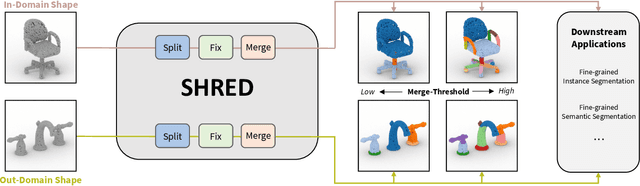
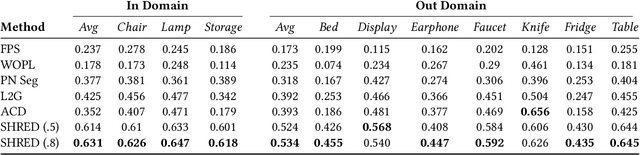
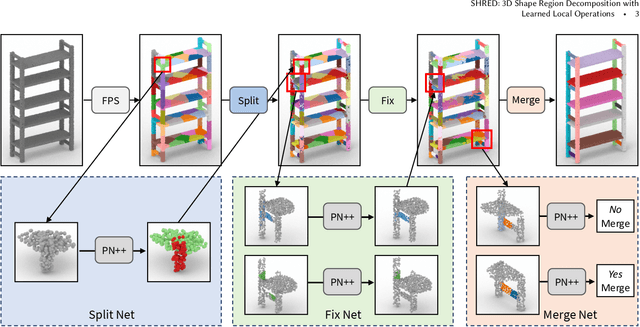
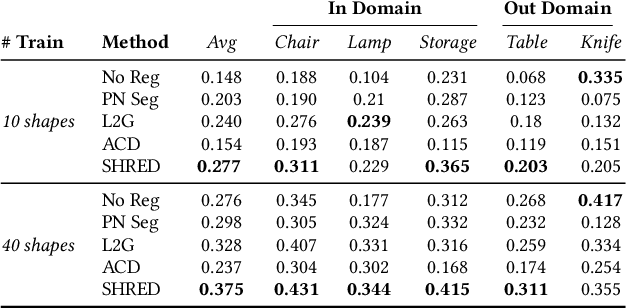
We present SHRED, a method for 3D SHape REgion Decomposition. SHRED takes a 3D point cloud as input and uses learned local operations to produce a segmentation that approximates fine-grained part instances. We endow SHRED with three decomposition operations: splitting regions, fixing the boundaries between regions, and merging regions together. Modules are trained independently and locally, allowing SHRED to generate high-quality segmentations for categories not seen during training. We train and evaluate SHRED with fine-grained segmentations from PartNet; using its merge-threshold hyperparameter, we show that SHRED produces segmentations that better respect ground-truth annotations compared with baseline methods, at any desired decomposition granularity. Finally, we demonstrate that SHRED is useful for downstream applications, out-performing all baselines on zero-shot fine-grained part instance segmentation and few-shot fine-grained semantic segmentation when combined with methods that learn to label shape regions.
Learning Body-Aware 3D Shape Generative Models
Dec 16, 2021

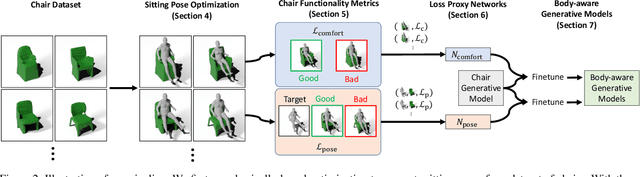
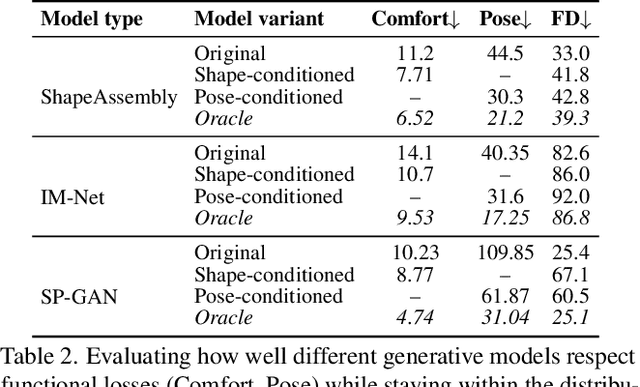
The shape of many objects in the built environment is dictated by their relationships to the human body: how will a person interact with this object? Existing data-driven generative models of 3D shapes produce plausible objects but do not reason about the relationship of those objects to the human body. In this paper, we learn body-aware generative models of 3D shapes. Specifically, we train generative models of chairs, an ubiquitous shape category, which can be conditioned on a given body shape or sitting pose. The body-shape-conditioned models produce chairs which will be comfortable for a person with the given body shape; the pose-conditioned models produce chairs which accommodate the given sitting pose. To train these models, we define a "sitting pose matching" metric and a novel "sitting comfort" metric. Calculating these metrics requires an expensive optimization to sit the body into the chair, which is too slow to be used as a loss function for training a generative model. Thus, we train neural networks to efficiently approximate these metrics. We use our approach to train three body-aware generative shape models: a structured part-based generator, a point cloud generator, and an implicit surface generator. In all cases, our approach produces models which adapt their output chair shapes to input human body specifications.