 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualizing token importance for black-box language models
Dec 12, 2025



We consider the problem of auditing black-box large language models (LLMs) to ensure they behave reliably when deployed in production settings, particularly in high-stakes domains such as legal, medical, and regulatory compliance. Existing approaches for LLM auditing often focus on isolated aspects of model behavior, such as detecting specific biases or evaluating fairness. We are interested in a more general question -- can we understand how the outputs of black-box LLMs depend on each input token? There is a critical need to have such tools in real-world applications that rely on inaccessible API endpoints to language models. However, this is a highly non-trivial problem, as LLMs are stochastic functions (i.e. two outputs will be different by chance), while computing prompt-level gradients to approximate input sensitivity is infeasible. To address this, we propose Distribution-Based Sensitivity Analysis (DBSA), a lightweight model-agnostic procedure to evaluate the sensitivity of the output of a language model for each input token, without making any distributional assumptions about the LLM. DBSA is developed as a practical tool for practitioners, enabling quick, plug-and-play visual exploration of LLMs reliance on specific input tokens. Through illustrative examples, we demonstrate how DBSA can enable users to inspect LLM inputs and find sensitivities that may be overlooked by existing LLM interpretability methods.
Event-Aware Sentiment Factors from LLM-Augmented Financial Tweets: A Transparent Framework for Interpretable Quant Trading
Aug 10, 2025



In this study, we wish to showcase the unique utility of large language models (LLMs) in financial semantic annotation and alpha signal discovery. Leveraging a corpus of company-related tweets, we use an LLM to automatically assign multi-label event categories to high-sentiment-intensity tweets. We align these labeled sentiment signals with forward returns over 1-to-7-day horizons to evaluate their statistical efficacy and market tradability. Our experiments reveal that certain event labels consistently yield negative alpha, with Sharpe ratios as low as -0.38 and information coefficients exceeding 0.05, all statistically significant at the 95\% confidence level. This study establishes the feasibility of transforming unstructured social media text into structured, multi-label event variables. A key contribution of this work is its commitment to transparency and reproducibility; all code and methodologies are made publicly available. Our results provide compelling evidence that social media sentiment is a valuable, albeit noisy, signal in financial forecasting and underscore the potential of open-source frameworks to democratize algorithmic trading research.
The AI Imperative: Scaling High-Quality Peer Review in Machine Learning
Jun 09, 2025Peer review, the bedrock of scientific advancement in machine learning (ML), is strained by a crisis of scale. Exponential growth in manuscript submissions to premier ML venues such as NeurIPS, ICML, and ICLR is outpacing the finite capacity of qualified reviewers, leading to concerns about review quality, consistency, and reviewer fatigue. This position paper argues that AI-assisted peer review must become an urgent research and infrastructure priority. We advocate for a comprehensive AI-augmented ecosystem, leveraging Large Language Models (LLMs) not as replacements for human judgment, but as sophisticated collaborators for authors, reviewers, and Area Chairs (ACs). We propose specific roles for AI in enhancing factual verification, guiding reviewer performance, assisting authors in quality improvement, and supporting ACs in decision-making. Crucially, we contend that the development of such systems hinges on access to more granular, structured, and ethically-sourced peer review process data. We outline a research agenda, including illustrative experiments, to develop and validate these AI assistants, and discuss significant technical and ethical challenges. We call upon the ML community to proactively build this AI-assisted future, ensuring the continued integrity and scalability of scientific validation, while maintaining high standards of peer review.
Statistical Hypothesis Testing for Auditing Robustness in Language Models
Jun 09, 2025Consider the problem of testing whether the outputs of a large language model (LLM) system change under an arbitrary intervention, such as an input perturbation or changing the model variant. We cannot simply compare two LLM outputs since they might differ due to the stochastic nature of the system, nor can we compare the entire output distribution due to computational intractability. While existing methods for analyzing text-based outputs exist, they focus on fundamentally different problems, such as measuring bias or fairness. To this end, we introduce distribution-based perturbation analysis, a framework that reformulates LLM perturbation analysis as a frequentist hypothesis testing problem. We construct empirical null and alternative output distributions within a low-dimensional semantic similarity space via Monte Carlo sampling, enabling tractable inference without restrictive distributional assumptions. The framework is (i) model-agnostic, (ii) supports the evaluation of arbitrary input perturbations on any black-box LLM, (iii) yields interpretable p-values; (iv) supports multiple perturbations via controlled error rates; and (v) provides scalar effect sizes. We demonstrate the usefulness of the framework across multiple case studies, showing how we can quantify response changes, measure true/false positive rates, and evaluate alignment with reference models. Above all, we see this as a reliable frequentist hypothesis testing framework for LLM auditing.
* arXiv admin note: substantial text overlap with arXiv:2412.00868
Quantifying perturbation impacts for large language models
Dec 01, 2024



We consider the problem of quantifying how an input perturbation impacts the outputs of large language models (LLMs), a fundamental task for model reliability and post-hoc interpretability. A key obstacle in this domain is disentangling the meaningful changes in model responses from the intrinsic stochasticity of LLM outputs. To overcome this, we introduce Distribution-Based Perturbation Analysis (DBPA), a framework that reformulates LLM perturbation analysis as a frequentist hypothesis testing problem. DBPA constructs empirical null and alternative output distributions within a low-dimensional semantic similarity space via Monte Carlo sampling. Comparisons of Monte Carlo estimates in the reduced dimensionality space enables tractable frequentist inference without relying on restrictive distributional assumptions. The framework is model-agnostic, supports the evaluation of arbitrary input perturbations on any black-box LLM, yields interpretable p-values, supports multiple perturbation testing via controlled error rates, and provides scalar effect sizes for any chosen similarity or distance metric. We demonstrate the effectiveness of DBPA in evaluating perturbation impacts, showing its versatility for perturbation analysis.
Defining Expertise: Applications to Treatment Effect Estimation
Mar 01, 2024



Decision-makers are often experts of their domain and take actions based on their domain knowledge. Doctors, for instance, may prescribe treatments by predicting the likely outcome of each available treatment. Actions of an expert thus naturally encode part of their domain knowledge, and can help make inferences within the same domain: Knowing doctors try to prescribe the best treatment for their patients, we can tell treatments prescribed more frequently are likely to be more effective. Yet in machine learning, the fact that most decision-makers are experts is often overlooked, and "expertise" is seldom leveraged as an inductive bias. This is especially true for the literature on treatment effect estimation, where often the only assumption made about actions is that of overlap. In this paper, we argue that expertise - particularly the type of expertise the decision-makers of a domain are likely to have - can be informative in designing and selecting methods for treatment effect estimation. We formally define two types of expertise, predictive and prognostic, and demonstrate empirically that: (i) the prominent type of expertise in a domain significantly influences the performance of different methods in treatment effect estimation, and (ii) it is possible to predict the type of expertise present in a dataset, which can provide a quantitative basis for model selection.
Reference-Limited Compositional Zero-Shot Learning
Aug 22, 2022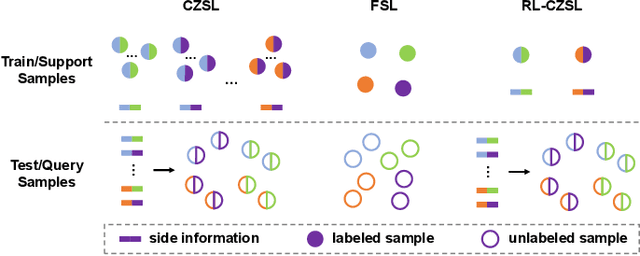
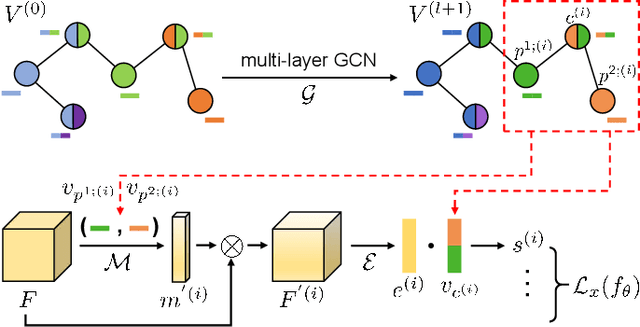

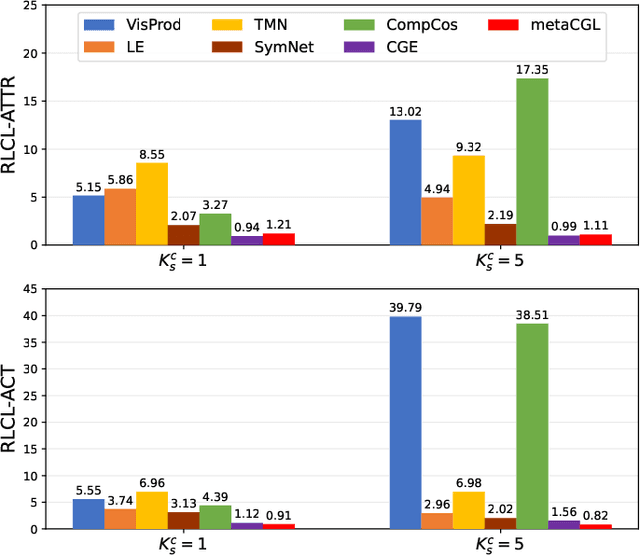
Compositional zero-shot learning (CZSL) refers to recognizing unseen compositions of known visual primitives, which is an essential ability for artificial intelligence systems to learn and understand the world. While considerable progress has been made on existing benchmarks, we suspect whether popular CZSL methods can address the challenges of few-shot and few referential compositions, which is common when learning in real-world unseen environments. To this end, we study the challenging reference-limited compositional zero-shot learning (RL-CZSL) problem in this paper, i.e. , given limited seen compositions that contain only a few samples as reference, unseen compositions of observed primitives should be identified. We propose a novel Meta Compositional Graph Learner (MetaCGL) that can efficiently learn the compositionality from insufficient referential information and generalize to unseen compositions. Besides, we build a benchmark with two new large-scale datasets that consist of natural images with diverse compositional labels, providing more realistic environments for RL-CZSL. Extensive experiments in the benchmarks show that our method achieves state-of-the-art performance in recognizing unseen compositions when reference is limited for compositional learning.