 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Top-Down Just Noticeable Difference Estimation of Natural Images
Aug 11, 2021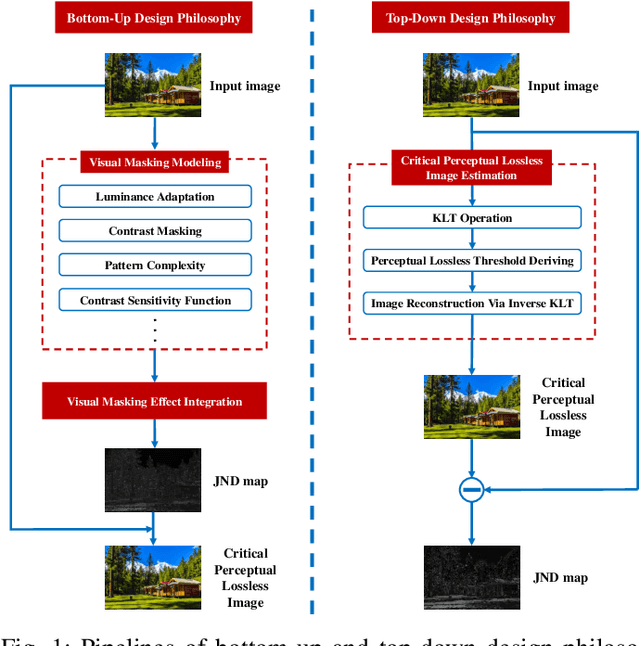

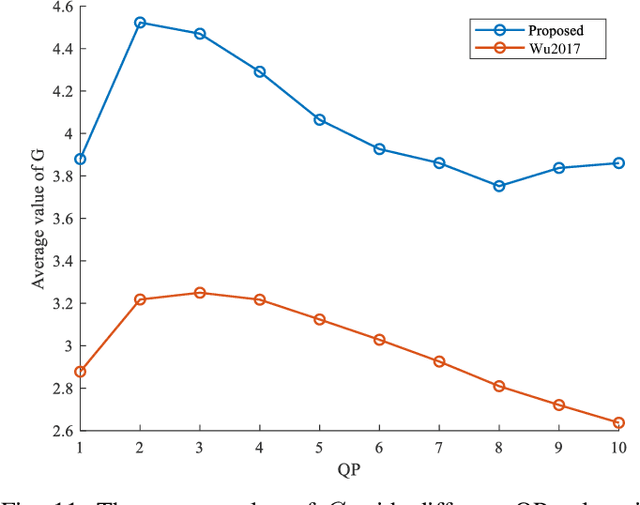

Existing efforts on Just noticeable difference (JND) estimation mainly dedicate to modeling the visibility masking effects of different factors in spatial and frequency domains, and then fusing them into an overall JND estimate. However, the overall visibility masking effect can be related with more contributing factors beyond those have been considered in the literature and it is also insufficiently accurate to formulate the masking effect even for an individual factor. Moreover, the potential interactions among different masking effects are also difficult to be characterized with a simple fusion model. In this work, we turn to a dramatically different way to address these problems with a top-down design philosophy. Instead of formulating and fusing multiple masking effects in a bottom-up way, the proposed JND estimation model directly generates a critical perceptual lossless (CPL) image from a top-down perspective and calculates the difference map between the original image and the CPL image as the final JND map. Given an input image, an adaptively critical point (perceptual lossless threshold), defined as the minimum number of spectral components in Karhunen-Lo\'{e}ve Transform (KLT) used for perceptual lossless image reconstruction, is derived by exploiting the convergence characteristics of KLT coefficient energy. Then, the CPL image can be reconstructed via inverse KLT according to the derived critical point. Finally, the difference map between the original image and the CPL image is calculated as the JND map. The performance of the proposed JND model is evaluated with two applications including JND-guided noise injection and JND-guided image compression. Experimental results have demonstrated that our proposed JND model can achieve better performance than several latest JND models.
No-Reference Quality Assessment for 360-degree Images by Analysis of Multi-frequency Information and Local-global Naturalness
Feb 22, 2021
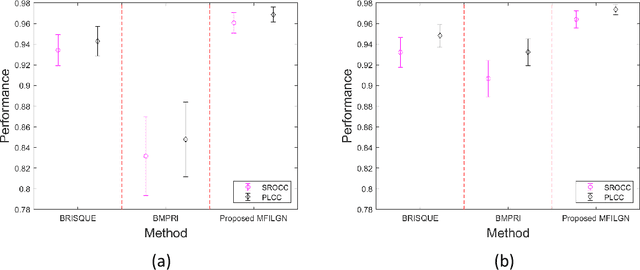
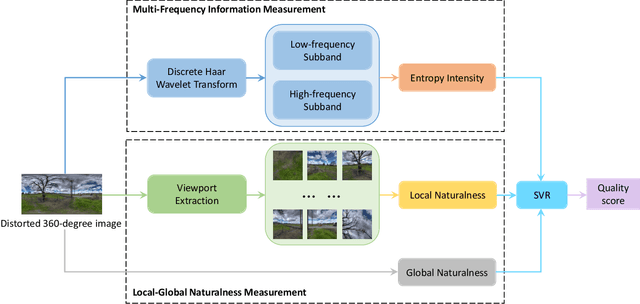

360-degree/omnidirectional images (OIs) have achieved remarkable attentions due to the increasing applications of virtual reality (VR). Compared to conventional 2D images, OIs can provide more immersive experience to consumers, benefitting from the higher resolution and plentiful field of views (FoVs). Moreover, observing OIs is usually in the head mounted display (HMD) without references. Therefore, an efficient blind quality assessment method, which is specifically designed for 360-degree images, is urgently desired. In this paper, motivated by the characteristics of the human visual system (HVS) and the viewing process of VR visual contents, we propose a novel and effective no-reference omnidirectional image quality assessment (NR OIQA) algorithm by Multi-Frequency Information and Local-Global Naturalness (MFILGN). Specifically, inspired by the frequency-dependent property of visual cortex, we first decompose the projected equirectangular projection (ERP) maps into wavelet subbands. Then, the entropy intensities of low and high frequency subbands are exploited to measure the multi-frequency information of OIs. Besides, except for considering the global naturalness of ERP maps, owing to the browsed FoVs, we extract the natural scene statistics features from each viewport image as the measure of local naturalness. With the proposed multi-frequency information measurement and local-global naturalness measurement, we utilize support vector regression as the final image quality regressor to train the quality evaluation model from visual quality-related features to human ratings. To our knowledge, the proposed model is the first no-reference quality assessment method for 360-degreee images that combines multi-frequency information and image naturalness. Experimental results on two publicly available OIQA databases demonstrate that our proposed MFILGN outperforms state-of-the-art approaches.
Progressive Self-Guided Loss for Salient Object Detection
Jan 07, 2021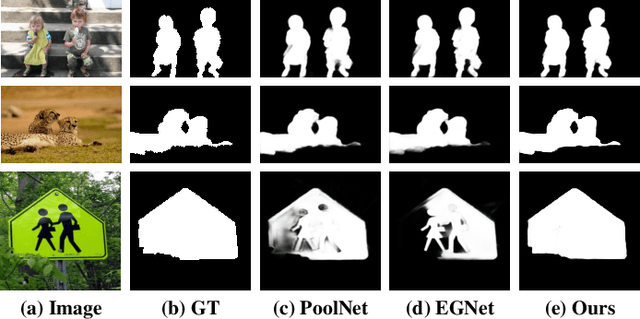
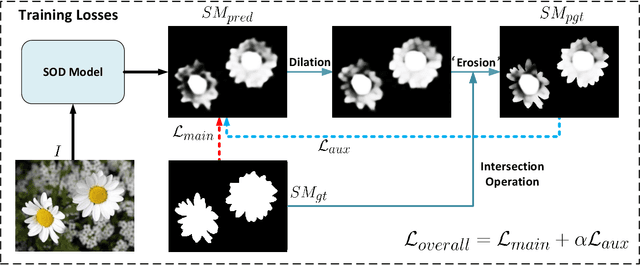
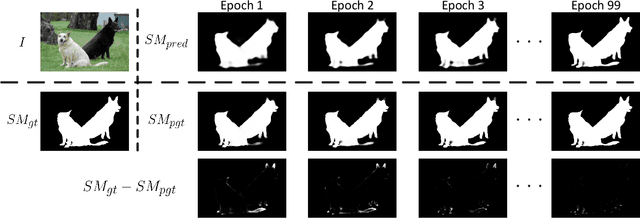
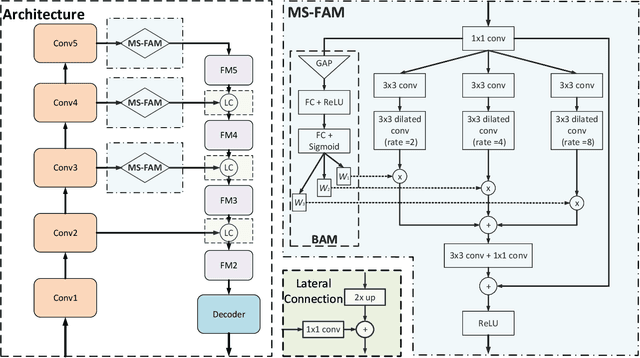
We present a simple yet effective progressive self-guided loss function to facilitate deep learning-based salient object detection (SOD) in images. The saliency maps produced by the most relevant works still suffer from incomplete predictions due to the internal complexity of salient objects. Our proposed progressive self-guided loss simulates a morphological closing operation on the model predictions for epoch-wisely creating progressive and auxiliary training supervisions to step-wisely guide the training process. We demonstrate that this new loss function can guide the SOD model to highlight more complete salient objects step-by-step and meanwhile help to uncover the spatial dependencies of the salient object pixels in a region growing manner. Moreover, a new feature aggregation module is proposed to capture multi-scale features and aggregate them adaptively by a branch-wise attention mechanism. Benefiting from this module, our SOD framework takes advantage of adaptively aggregated multi-scale features to locate and detect salient objects effectively. Experimental results on several benchmark datasets show that our loss function not only advances the performance of existing SOD models without architecture modification but also helps our proposed framework to achieve state-of-the-art performance.
Blind Quality Assessment for Image Superresolution Using Deep Two-Stream Convolutional Networks
Apr 13, 2020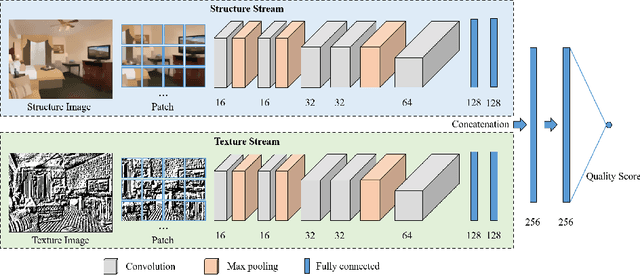
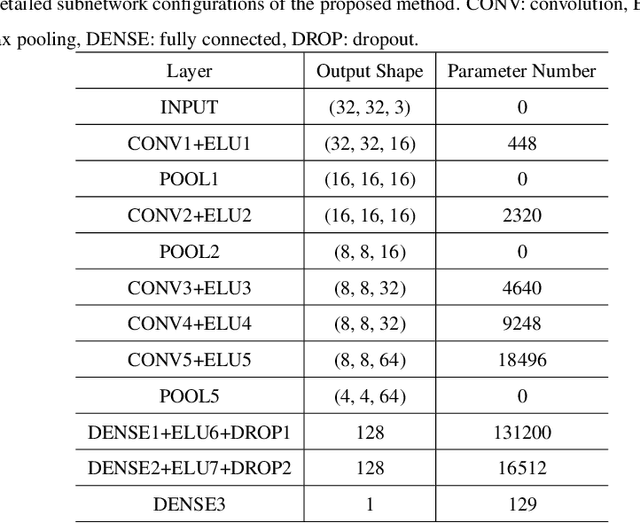

Numerous image superresolution (SR) algorithms have been proposed for reconstructing high-resolution (HR) images from input images with lower spatial resolutions. However, effectively evaluating the perceptual quality of SR images remains a challenging research problem. In this paper, we propose a no-reference/blind deep neural network-based SR image quality assessor (DeepSRQ). To learn more discriminative feature representations of various distorted SR images, the proposed DeepSRQ is a two-stream convolutional network including two subcomponents for distorted structure and texture SR images. Different from traditional image distortions, the artifacts of SR images cause both image structure and texture quality degradation. Therefore, we choose the two-stream scheme that captures different properties of SR inputs instead of directly learning features from one image stream. Considering the human visual system (HVS) characteristics, the structure stream focuses on extracting features in structural degradations, while the texture stream focuses on the change in textural distributions. In addition, to augment the training data and ensure the category balance, we propose a stride-based adaptive cropping approach for further improvement. Experimental results on three publicly available SR image quality databases demonstrate the effectiveness and generalization ability of our proposed DeepSRQ method compared with state-of-the-art image quality assessment algorithms.
A Dilated Inception Network for Visual Saliency Prediction
May 09, 2019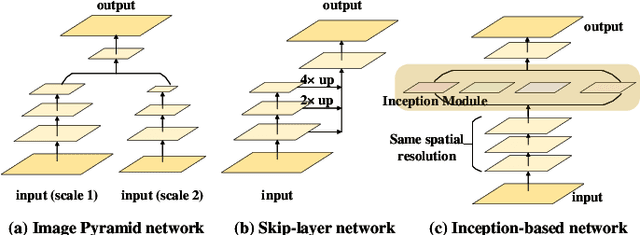
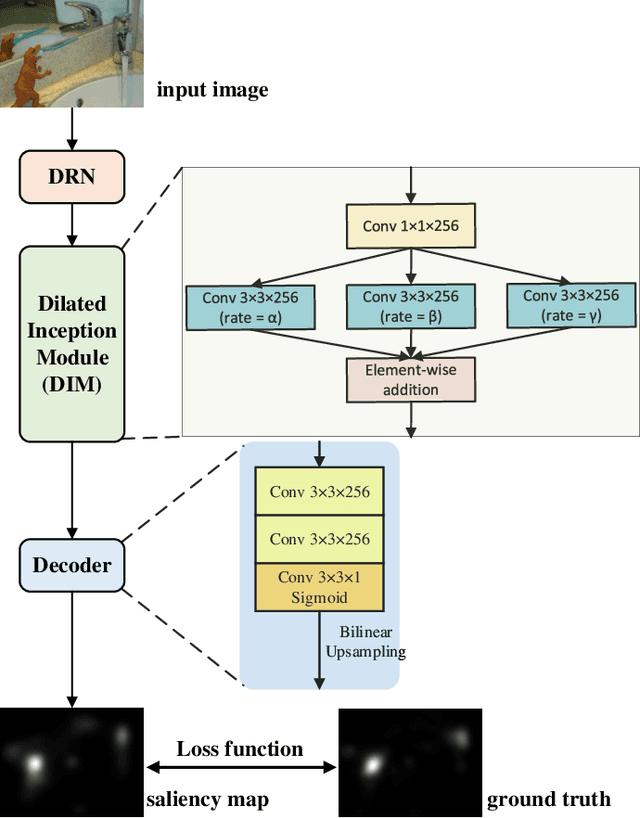
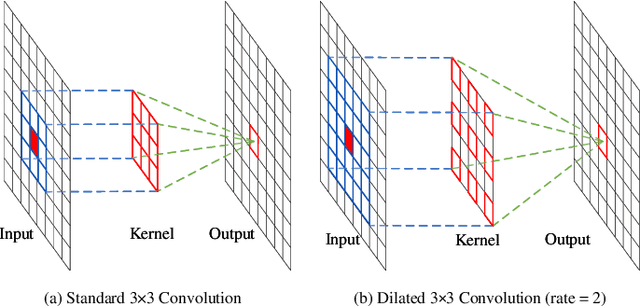
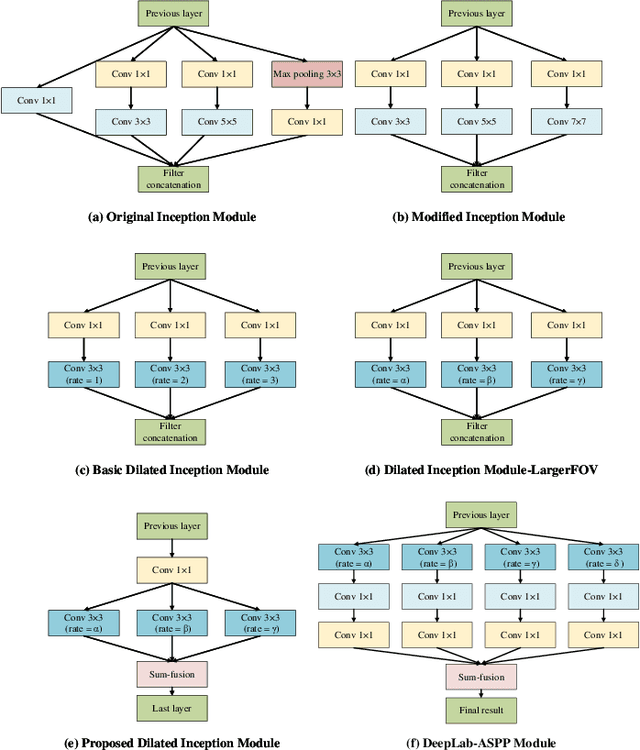
Recently, with the advent of deep convolutional neural networks (DCNN), the improvements in visual saliency prediction research are impressive. One possible direction to approach the next improvement is to fully characterize the multi-scale saliency-influential factors with a computationally-friendly module in DCNN architectures. In this work, we proposed an end-to-end dilated inception network (DINet) for visual saliency prediction. It captures multi-scale contextual features effectively with very limited extra parameters. Instead of utilizing parallel standard convolutions with different kernel sizes as the existing inception module, our proposed dilated inception module (DIM) uses parallel dilated convolutions with different dilation rates which can significantly reduce the computation load while enriching the diversity of receptive fields in feature maps. Moreover, the performance of our saliency model is further improved by using a set of linear normalization-based probability distribution distance metrics as loss functions. As such, we can formulate saliency prediction as a probability distribution prediction task for global saliency inference instead of a typical pixel-wise regression problem. Experimental results on several challenging saliency benchmark datasets demonstrate that our DINet with proposed loss functions can achieve state-of-the-art performance with shorter inference time.