 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuromorphic Online Learning for Spatiotemporal Patterns with a Forward-only Timeline
Jul 21, 2023Spiking neural networks (SNNs) are bio-plausible computing models with high energy efficiency. The temporal dynamics of neurons and synapses enable them to detect temporal patterns and generate sequences. While Backpropagation Through Time (BPTT) is traditionally used to train SNNs, it is not suitable for online learning of embedded applications due to its high computation and memory cost as well as extended latency. Previous works have proposed online learning algorithms, but they often utilize highly simplified spiking neuron models without synaptic dynamics and reset feedback, resulting in subpar performance. In this work, we present Spatiotemporal Online Learning for Synaptic Adaptation (SOLSA), specifically designed for online learning of SNNs composed of Leaky Integrate and Fire (LIF) neurons with exponentially decayed synapses and soft reset. The algorithm not only learns the synaptic weight but also adapts the temporal filters associated to the synapses. Compared to the BPTT algorithm, SOLSA has much lower memory requirement and achieves a more balanced temporal workload distribution. Moreover, SOLSA incorporates enhancement techniques such as scheduled weight update, early stop training and adaptive synapse filter, which speed up the convergence and enhance the learning performance. When compared to other non-BPTT based SNN learning, SOLSA demonstrates an average learning accuracy improvement of 14.2%. Furthermore, compared to BPTT, SOLSA achieves a 5% higher average learning accuracy with a 72% reduction in memory cost.
In-Hardware Learning of Multilayer Spiking Neural Networks on a Neuromorphic Processor
May 08, 2021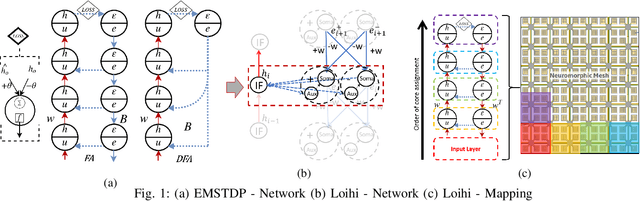
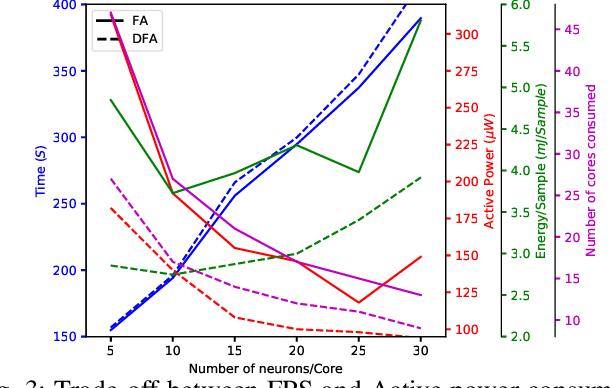
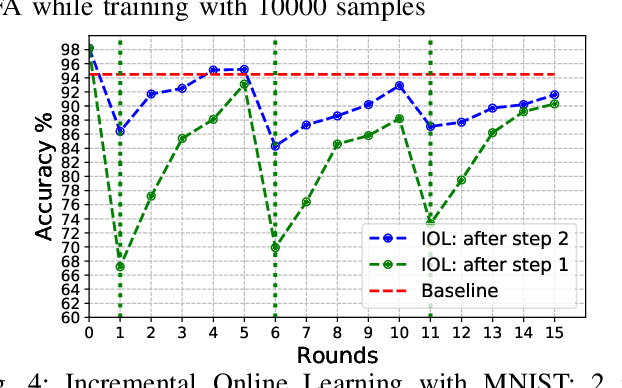
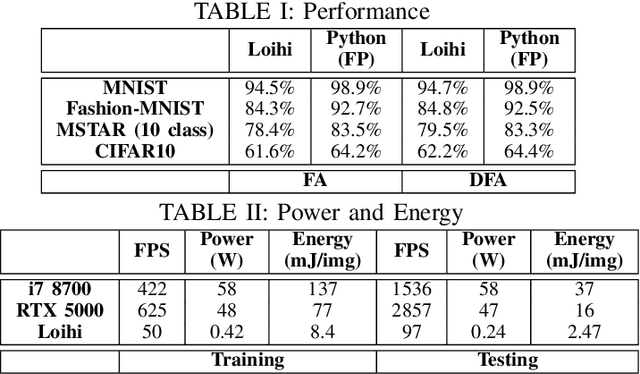
Although widely used in machine learning, backpropagation cannot directly be applied to SNN training and is not feasible on a neuromorphic processor that emulates biological neuron and synapses. This work presents a spike-based backpropagation algorithm with biological plausible local update rules and adapts it to fit the constraint in a neuromorphic hardware. The algorithm is implemented on Intel Loihi chip enabling low power in-hardware supervised online learning of multilayered SNNs for mobile applications. We test this implementation on MNIST, Fashion-MNIST, CIFAR-10 and MSTAR datasets with promising performance and energy-efficiency, and demonstrate a possibility of incremental online learning with the implementation.
Neuromorphic Algorithm-hardware Codesign for Temporal Pattern Learning
May 07, 2021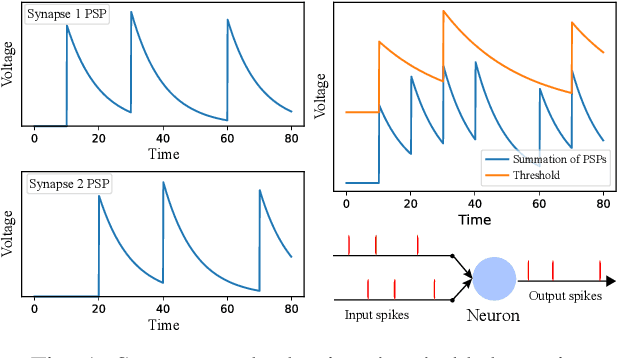
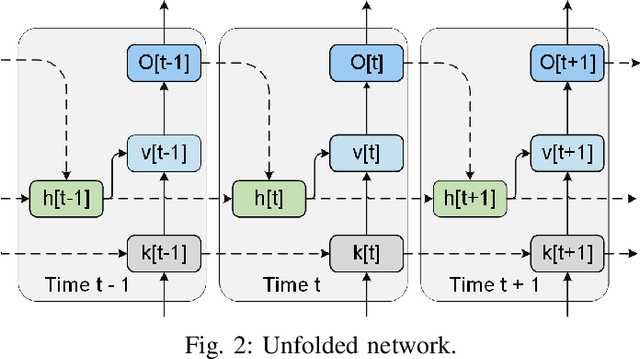
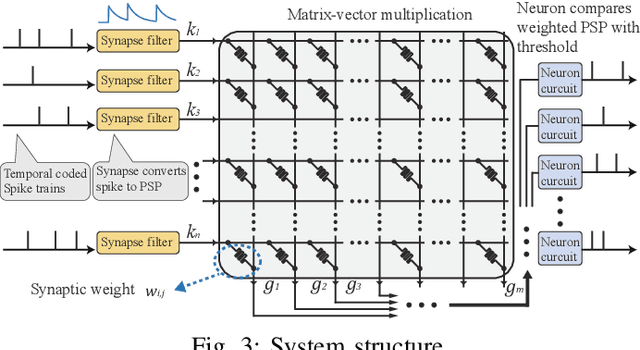
Neuromorphic computing and spiking neural networks (SNN) mimic the behavior of biological systems and have drawn interest for their potential to perform cognitive tasks with high energy efficiency. However, some factors such as temporal dynamics and spike timings prove critical for information processing but are often ignored by existing works, limiting the performance and applications of neuromorphic computing. On one hand, due to the lack of effective SNN training algorithms, it is difficult to utilize the temporal neural dynamics. Many existing algorithms still treat neuron activation statistically. On the other hand, utilizing temporal neural dynamics also poses challenges to hardware design. Synapses exhibit temporal dynamics, serving as memory units that hold historical information, but are often simplified as a connection with weight. Most current models integrate synaptic activations in some storage medium to represent membrane potential and institute a hard reset of membrane potential after the neuron emits a spike. This is done for its simplicity in hardware, requiring only a "clear" signal to wipe the storage medium, but destroys temporal information stored in the neuron. In this work, we derive an efficient training algorithm for Leaky Integrate and Fire neurons, which is capable of training a SNN to learn complex spatial temporal patterns. We achieved competitive accuracy on two complex datasets. We also demonstrate the advantage of our model by a novel temporal pattern association task. Codesigned with this algorithm, we have developed a CMOS circuit implementation for a memristor-based network of neuron and synapses which retains critical neural dynamics with reduced complexity. This circuit implementation of the neuron model is simulated to demonstrate its ability to react to temporal spiking patterns with an adaptive threshold.
Multivariate Time Series Classification Using Spiking Neural Networks
Jul 07, 2020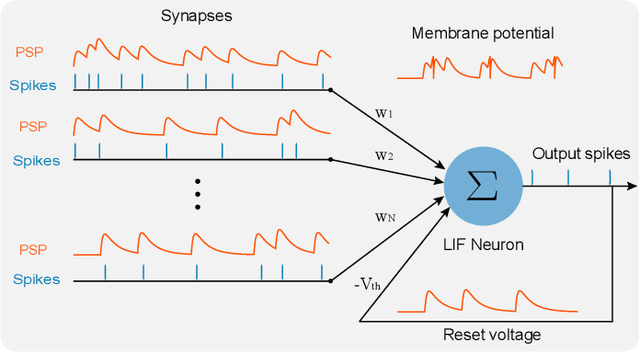
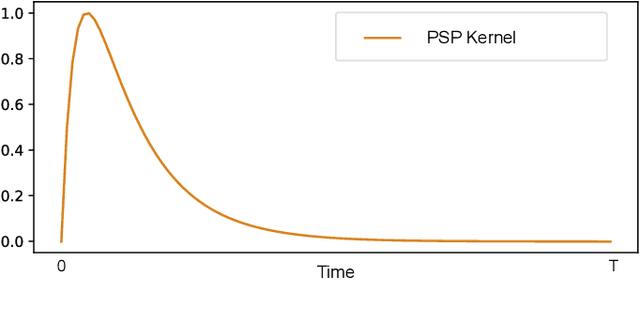
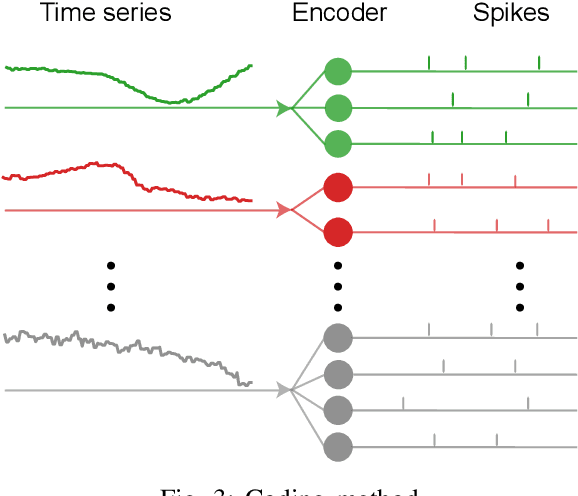
There is an increasing demand to process streams of temporal data in energy-limited scenarios such as embedded devices, driven by the advancement and expansion of Internet of Things (IoT) and Cyber-Physical Systems (CPS). Spiking neural network has drawn attention as it enables low power consumption by encoding and processing information as sparse spike events, which can be exploited for event-driven computation. Recent works also show SNNs' capability to process spatial temporal information. Such advantages can be exploited by power-limited devices to process real-time sensor data. However, most existing SNN training algorithms focus on vision tasks and temporal credit assignment is not addressed. Furthermore, widely adopted rate encoding ignores temporal information, hence it's not suitable for representing time series. In this work, we present an encoding scheme to convert time series into sparse spatial temporal spike patterns. A training algorithm to classify spatial temporal patterns is also proposed. Proposed approach is evaluated on multiple time series datasets in the UCR repository and achieved performance comparable to deep neural networks.
MAGNet: Multi-Region Attention-Assisted Grounding of Natural Language Queries at Phrase Level
Jun 06, 2020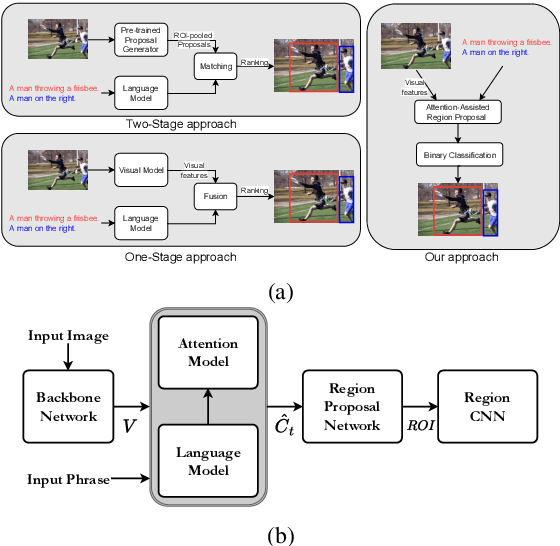
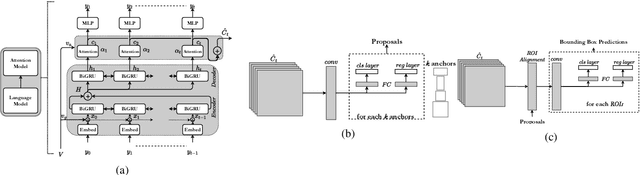


Grounding free-form textual queries necessitates an understanding of these textual phrases and its relation to the visual cues to reliably reason about the described locations. Spatial attention networks are known to learn this relationship and focus its gaze on salient objects in the image. Thus, we propose to utilize spatial attention networks for image-level visual-textual fusion preserving local (word) and global (phrase) information to refine region proposals with an in-network Region Proposal Network (RPN) and detect single or multiple regions for a phrase query. We focus only on the phrase query - ground truth pair (referring expression) for a model independent of the constraints of the datasets i.e. additional attributes, context etc. For such referring expression dataset ReferIt game, our Multi-region Attention-assisted Grounding network (MAGNet) achieves over 12\% improvement over the state-of-the-art. Without the context from image captions and attribute information in Flickr30k Entities, we still achieve competitive results compared to the state-of-the-art.
GISNet: Graph-Based Information Sharing Network For Vehicle Trajectory Prediction
Mar 22, 2020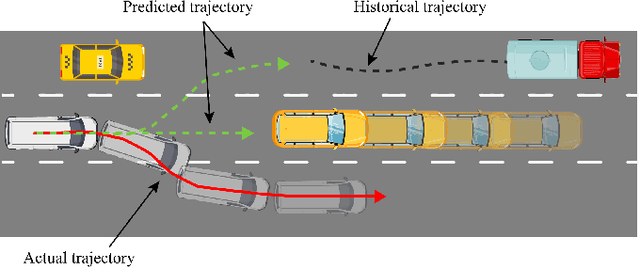
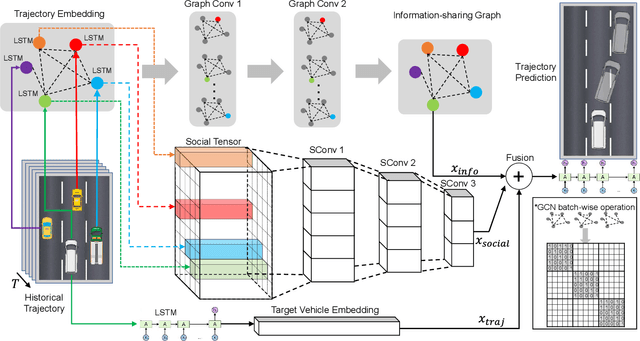
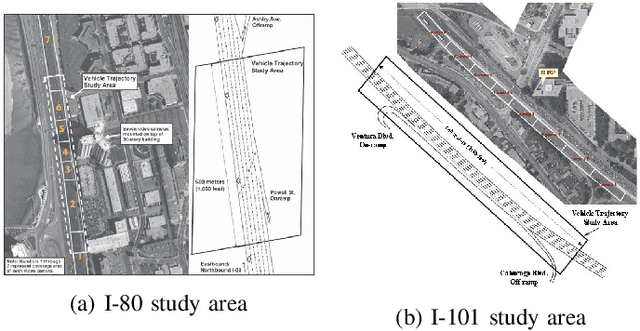
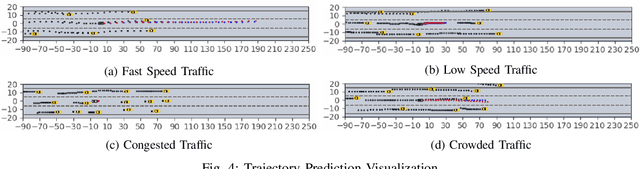
The trajectory prediction is a critical and challenging problem in the design of an autonomous driving system. Many AI-oriented companies, such as Google Waymo, Uber and DiDi, are investigating more accurate vehicle trajectory prediction algorithms. However, the prediction performance is governed by lots of entangled factors, such as the stochastic behaviors of surrounding vehicles, historical information of self-trajectory, and relative positions of neighbors, etc. In this paper, we propose a novel graph-based information sharing network (GISNet) that allows the information sharing between the target vehicle and its surrounding vehicles. Meanwhile, the model encodes the historical trajectory information of all the vehicles in the scene. Experiments are carried out on the public NGSIM US-101 and I-80 Dataset and the prediction performance is measured by the Root Mean Square Error (RMSE). The quantitative and qualitative experimental results show that our model significantly improves the trajectory prediction accuracy, by up to 50.00%, compared to existing models.
Mission-Aware Spatio-Temporal Deep Learning Model for UAS Instantaneous Density Prediction
Mar 22, 2020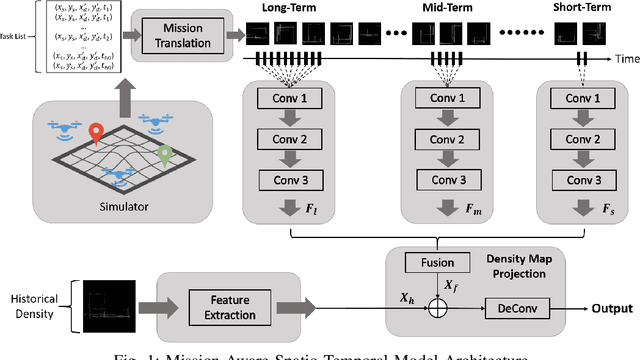
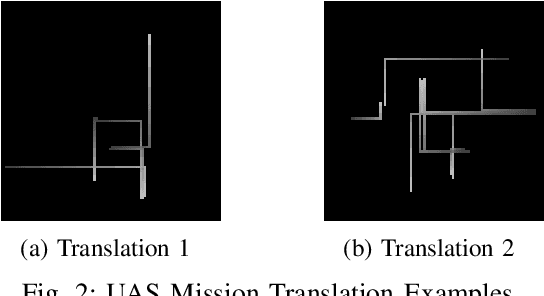
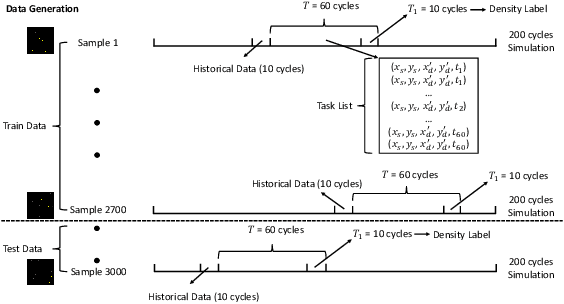
The number of daily sUAS operations in uncontrolled low altitude airspace is expected to reach into the millions in a few years. Therefore, UAS density prediction has become an emerging and challenging problem. In this paper, a deep learning-based UAS instantaneous density prediction model is presented. The model takes two types of data as input: 1) the historical density generated from the historical data, and 2) the future sUAS mission information. The architecture of our model contains four components: Historical Density Formulation module, UAS Mission Translation module, Mission Feature Extraction module, and Density Map Projection module. The training and testing data are generated by a python based simulator which is inspired by the multi-agent air traffic resource usage simulator (MATRUS) framework. The quality of prediction is measured by the correlation score and the Area Under the Receiver Operating Characteristics (AUROC) between the predicted value and simulated value. The experimental results demonstrate outstanding performance of the deep learning-based UAS density predictor. Compared to the baseline models, for simplified traffic scenario where no-fly zones and safe distance among sUASs are not considered, our model improves the prediction accuracy by more than 15.2% and its correlation score reaches 0.947. In a more realistic scenario, where the no-fly zone avoidance and the safe distance among sUASs are maintained using A* routing algorithm, our model can still achieve 0.823 correlation score. Meanwhile, the AUROC can reach 0.951 for the hot spot prediction.
Exploiting Neuron and Synapse Filter Dynamics in Spatial Temporal Learning of Deep Spiking Neural Network
Feb 19, 2020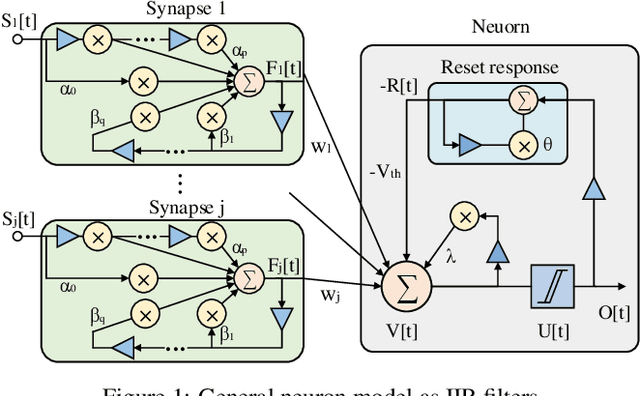
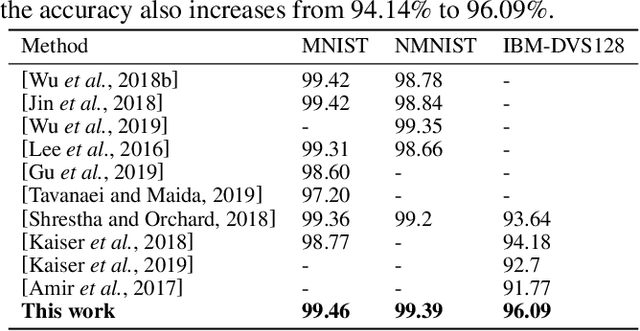
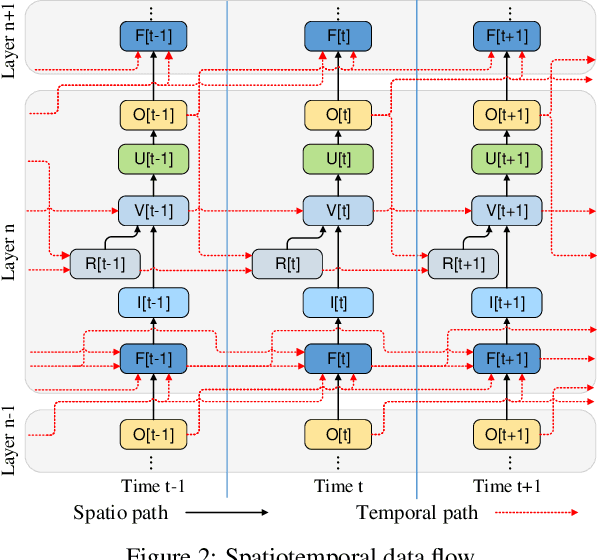
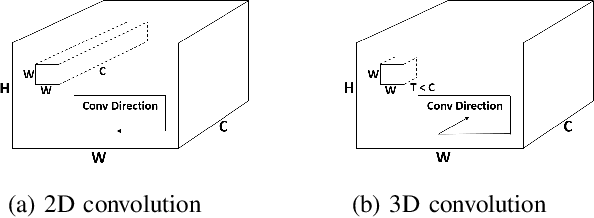
The recent discovered spatial-temporal information processing capability of bio-inspired Spiking neural networks (SNN) has enabled some interesting models and applications. However designing large-scale and high-performance model is yet a challenge due to the lack of robust training algorithms. A bio-plausible SNN model with spatial-temporal property is a complex dynamic system. Each synapse and neuron behave as filters capable of preserving temporal information. As such neuron dynamics and filter effects are ignored in existing training algorithms, the SNN downgrades into a memoryless system and loses the ability of temporal signal processing. Furthermore, spike timing plays an important role in information representation, but conventional rate-based spike coding models only consider spike trains statistically, and discard information carried by its temporal structures. To address the above issues, and exploit the temporal dynamics of SNNs, we formulate SNN as a network of infinite impulse response (IIR) filters with neuron nonlinearity. We proposed a training algorithm that is capable to learn spatial-temporal patterns by searching for the optimal synapse filter kernels and weights. The proposed model and training algorithm are applied to construct associative memories and classifiers for synthetic and public datasets including MNIST, NMNIST, DVS 128 etc.; and their accuracy outperforms state-of-art approaches.
Embedding Compression with Isotropic Iterative Quantization
Jan 23, 2020
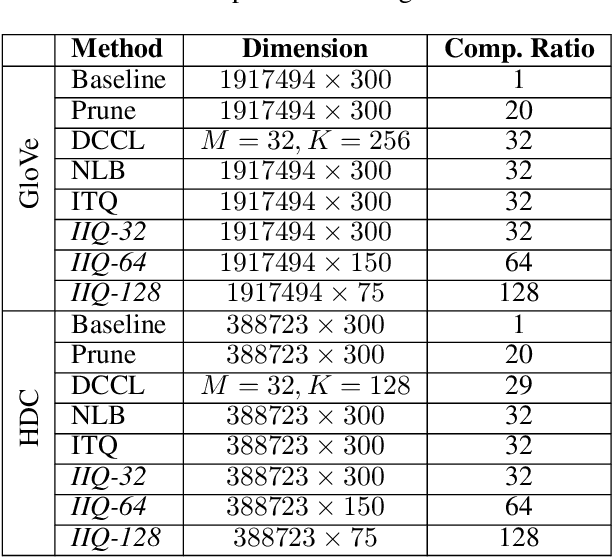
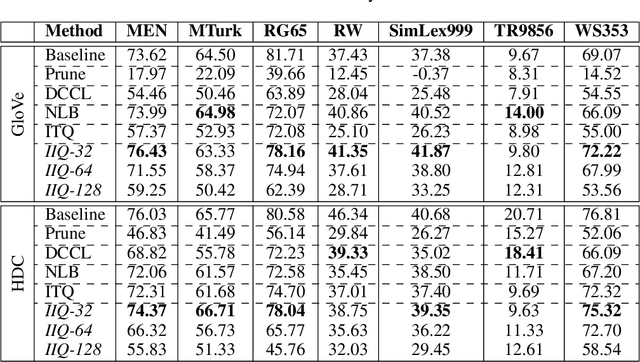
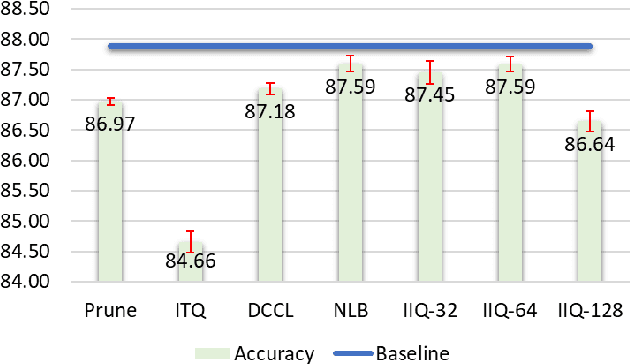
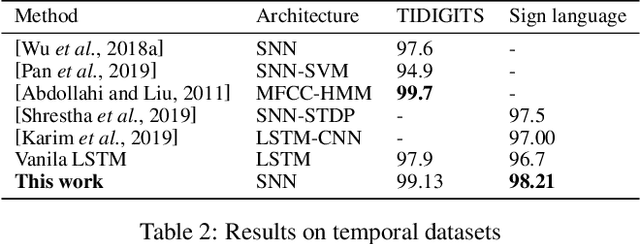
Continuous representation of words is a standard component in deep learning-based NLP models. However, representing a large vocabulary requires significant memory, which can cause problems, particularly on resource-constrained platforms. Therefore, in this paper we propose an isotropic iterative quantization (IIQ) approach for compressing embedding vectors into binary ones, leveraging the iterative quantization technique well established for image retrieval, while satisfying the desired isotropic property of PMI based models. Experiments with pre-trained embeddings (i.e., GloVe and HDC) demonstrate a more than thirty-fold compression ratio with comparable and sometimes even improved performance over the original real-valued embedding vectors.
High-Level Plan for Behavioral Robot Navigation with Natural Language Directions and R-NET
Jan 08, 2020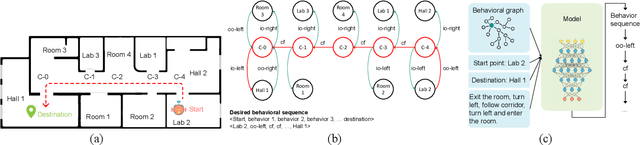

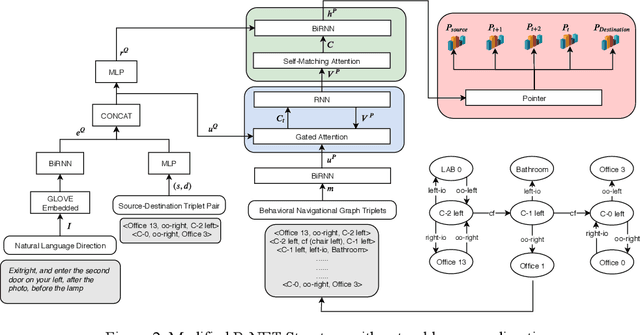

When the navigational environment is known, it can be represented as a graph where landmarks are nodes, the robot behaviors that move from node to node are edges, and the route is a set of behavioral instructions. The route path from source to destination can be viewed as a class of combinatorial optimization problems where the path is a sequential subset from a set of discrete items. The pointer network is an attention-based recurrent network that is suitable for such a task. In this paper, we utilize a modified R-NET with gated attention and self-matching attention translating natural language instructions to a high-level plan for behavioral robot navigation by developing an understanding of the behavioral navigational graph to enable the pointer network to produce a sequence of behaviors representing the path. Tests on the navigation graph dataset show that our model outperforms the state-of-the-art approach for both known and unknown environments.