 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeENTRA: Entropy-Based Redundancy Avoidance in Large Language Model Reasoning
Jan 12, 2026Large Reasoning Models (LRMs) often suffer from overthinking, generating unnecessarily long reasoning chains even for simple tasks. This leads to substantial computational overhead with limited performance gain, primarily due to redundant verification and repetitive generation. While prior work typically constrains output length or optimizes correctness, such coarse supervision fails to guide models toward concise yet accurate inference. In this paper, we propose ENTRA, an entropy-based training framework that suppresses redundant reasoning while preserving performance. ENTRA first estimates the token-level importance using a lightweight Bidirectional Importance Estimation (BIE) method, which accounts for both prediction confidence and forward influence. It then computes a redundancy reward based on the entropy of low-importance tokens, normalized by its theoretical upper bound, and optimizes this reward via reinforcement learning. Experiments on mathematical reasoning benchmarks demonstrate that ENTRA reduces output length by 37% to 53% with no loss-and in some cases, gains-in accuracy. Our approach offers a principled and efficient solution to reduce overthinking in LRMs, and provides a generalizable path toward redundancy-aware reasoning optimization.
From Large to Tiny: Distilling and Refining Mathematical Expertise for Math Word Problems with Weakly Supervision
Mar 21, 2024Addressing the challenge of high annotation costs in solving Math Word Problems (MWPs) through full supervision with intermediate equations, recent works have proposed weakly supervised task settings that rely solely on the final answer as a supervised signal. Existing leading approaches typically employ various search techniques to infer intermediate equations, but cannot ensure their semantic consistency with natural language descriptions. The rise of Large Language Models (LLMs) like ChatGPT has opened up new possibilities for addressing MWPs directly. However, the computational demands of LLMs make them less than ideal for use in settings where resources are tight. In light of these challenges, we introduce an innovative two-stage framework that adeptly transfers mathematical Expertise from large to tiny language models. In \emph{Distillation Stage}, we propose a series of extraction processes that satisfy the properties of MWPs to distill mathematical knowledge from LLMs to construct problem-equation pairs required for supervised training. In \emph{Refinement Stage}, Due to Knowledge distilling method cannot guarantee the full utilization of all data, we further utilize the unsuccessfully searched data effectively by Knowledge Refine method. Finally, We train a small model using distilled data generated through two-stage methods. As our method fully leverages the semantic understanding capabilities during the searching 'problem-equation' pair, it demonstrates significantly improved performance on the Math23K and Weak12K datasets compared to existing small model methods, while maintaining a much lower computational cost than ChatGPT.
Analysing Wideband Absorbance Immittance in Normal and Ears with Otitis Media with Effusion Using Machine Learning
Mar 04, 2021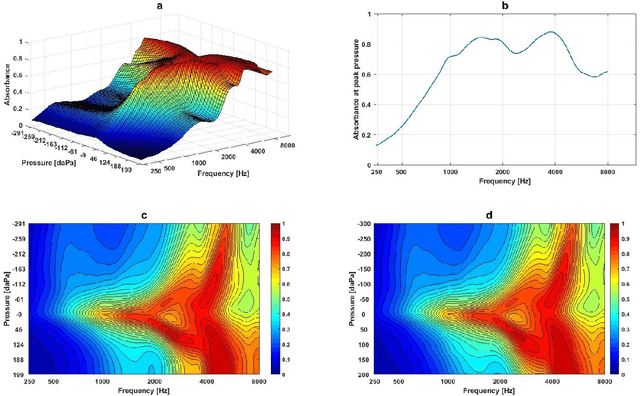
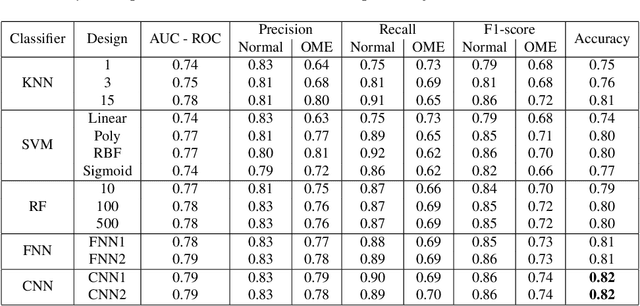
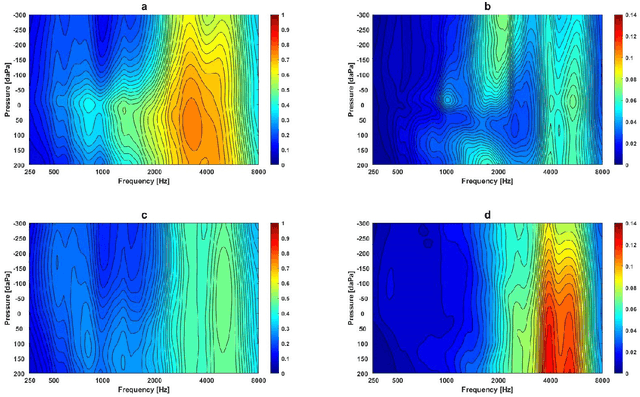
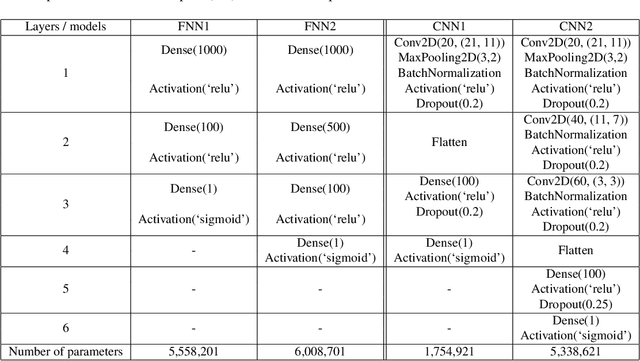
Wideband Absorbance Immittance (WAI) has been available for more than a decade, however its clinical use still faces the challenges of limited understanding and poor interpretation of WAI results. This study aimed to develop Machine Learning (ML) tools to identify the WAI absorbance characteristics across different frequency-pressure regions in the normal middle ear and ears with otitis media with effusion (OME) to enable diagnosis of middle ear conditions automatically. Data analysis including pre-processing of the WAI data, statistical analysis and classification model development, together with key regions extraction from the 2D frequency-pressure WAI images are conducted in this study. Our experimental results show that ML tools appear to hold great potential for the automated diagnosis of middle ear diseases from WAI data. The identified key regions in the WAI provide guidance to practitioners to better understand and interpret WAI data and offer the prospect of quick and accurate diagnostic decisions.