 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLASS: Graph and Vision-Language Assisted Semantic Shape Correspondence
Mar 08, 2026Establishing dense correspondence across 3D shapes is crucial for fundamental downstream tasks, including texture transfer, shape interpolation, and robotic manipulation. However, learning these mappings without manual supervision remains a formidable challenge, particularly under severe non-isometric deformations and in inter-class settings where geometric cues are ambiguous. Conventional functional map methods, while elegant, typically struggle in these regimes due to their reliance on isometry. To address this, we present GLASS, a framework that bridges the gap by integrating geometric spectral analysis with rich semantic priors from vision-language foundation models. GLASS introduces three key innovations: (i) a view-consistent strategy that enables robust multi-view visual feature extraction from powerful vision foundation models; (ii) the injection of language embeddings into vertex descriptors via zero-shot 3D segmentation, capturing high-level part semantics; and (iii) a graph-assisted contrastive loss that enforces structural consistency between regions (e.g., source's head'' $\leftrightarrow$ target's head'') by leveraging geodesic and topological relationships between regions. This design allows GLASS to learn globally coherent and semantically consistent maps without ground-truth supervision. Extensive experiments demonstrate that GLASS achieves state-of-the-art performance across all regimes, maintaining high accuracy on standard near-isometric tasks while significantly advancing performance in challenging settings. Specifically, it achieves average geodesic errors of 0.21, 4.5, and 5.6 on the inter-class benchmark SNIS and non-isometric benchmarks SMAL and TOPKIDS, reducing errors from URSSM baselines of 0.49, 6.0, and 8.9 by 57%, 25%, and 37%, respectively.
Universal 3D Shape Matching via Coarse-to-Fine Language Guidance
Feb 24, 2026Establishing dense correspondences between shapes is a crucial task in computer vision and graphics, while prior approaches depend on near-isometric assumptions and homogeneous subject types (i.e., only operate for human shapes). However, building semantic correspondences for cross-category objects remains challenging and has received relatively little attention. To achieve this, we propose UniMatch, a semantic-aware, coarse-to-fine framework for constructing dense semantic correspondences between strongly non-isometric shapes without restricting object categories. The key insight is to lift "coarse" semantic cues into "fine" correspondence, which is achieved through two stages. In the "coarse" stage, we perform class-agnostic 3D segmentation to obtain non-overlapping semantic parts and prompt multimodal large language models (MLLMs) to identify part names. Then, we employ pretrained vision language models (VLMs) to extract text embeddings, enabling the construction of matched semantic parts. In the "fine" stage, we leverage these coarse correspondences to guide the learning of dense correspondences through a dedicated rank-based contrastive scheme. Thanks to class-agnostic segmentation, language guiding, and rank-based contrastive learning, our method is versatile for universal object categories and requires no predefined part proposals, enabling universal matching for inter-class and non-isometric shapes. Extensive experiments demonstrate UniMatch consistently outperforms competing methods in various challenging scenarios.
Memory-augmented Adversarial Autoencoders for Multivariate Time-series Anomaly Detection with Deep Reconstruction and Prediction
Oct 15, 2021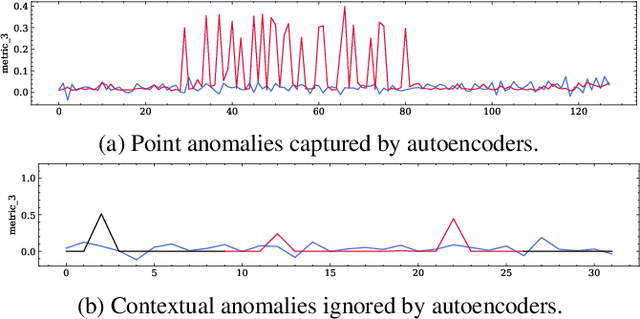
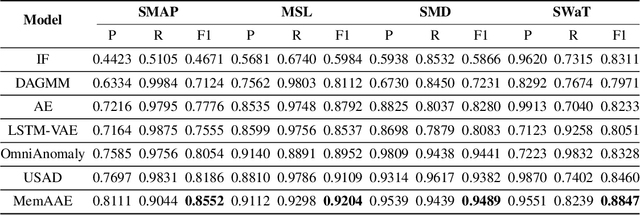
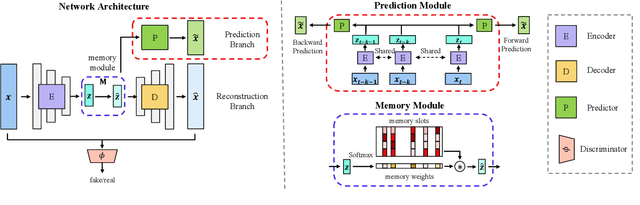
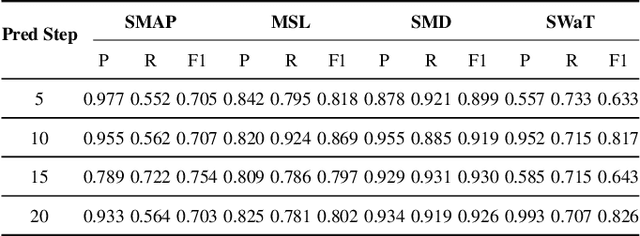
Detecting anomalies for multivariate time-series without manual supervision continues a challenging problem due to the increased scale of dimensions and complexity of today's IT monitoring systems. Recent progress of unsupervised time-series anomaly detection mainly use deep autoencoders to solve this problem, i.e. training on normal samples and producing significant reconstruction error on abnormal inputs. However, in practice, autoencoders can reconstruct anomalies so well, due to powerful capabilites of neural networks. Besides, these approaches can be ineffective for identifying non-point anomalies, e.g. contextual anomalies and collective anomalies, since they solely utilze a point-wise reconstruction objective. To tackle the above issues, we propose MemAAE (\textit{Memory-augmented Adversarial Autoencoders with Deep Reconstruction and Prediction}), a novel unsupervised anomaly detection method for time-series. By jointly training two complementary proxy tasks, reconstruction and prediction, with a shared network architecture, we show that detecting anomalies via multiple tasks obtains superior performance rather than single-task training. Additionally, a compressive memory module is introduced to preserve normal patterns, avoiding unexpected generalization on abnormal inputs. Through extensive experiments, MemAAE achieves an overall F1 score of 0.90 on four public datasets, significantly outperforming the best baseline by 0.02.
SleepPriorCL: Contrastive Representation Learning with Prior Knowledge-based Positive Mining and Adaptive Temperature for Sleep Staging
Oct 15, 2021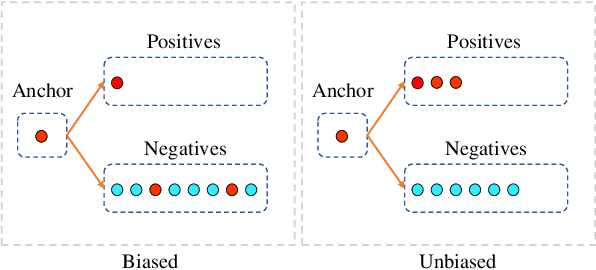
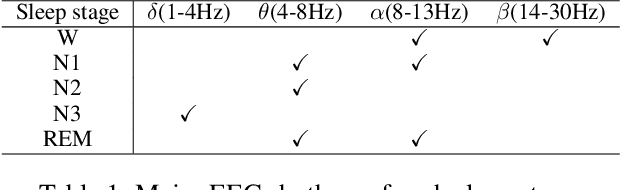
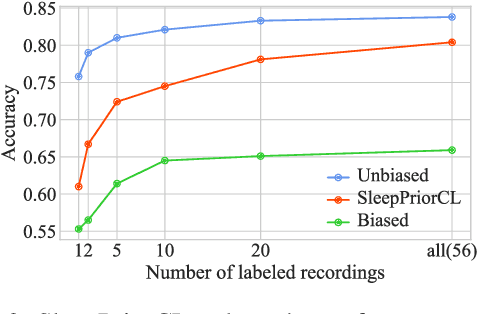
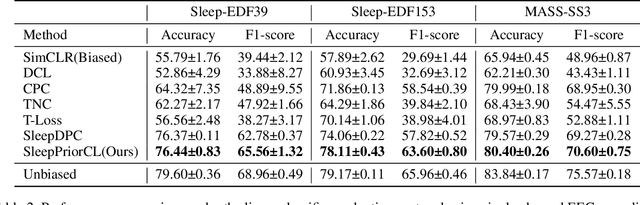
The objective of this paper is to learn semantic representations for sleep stage classification from raw physiological time series. Although supervised methods have gained remarkable performance, they are limited in clinical situations due to the requirement of fully labeled data. Self-supervised learning (SSL) based on contrasting semantically similar (positive) and dissimilar (negative) pairs of samples have achieved promising success. However, existing SSL methods suffer the problem that many semantically similar positives are still uncovered and even treated as negatives. In this paper, we propose a novel SSL approach named SleepPriorCL to alleviate the above problem. Advances of our approach over existing SSL methods are two-fold: 1) by incorporating prior domain knowledge into the training regime of SSL, more semantically similar positives are discovered without accessing ground-truth labels; 2) via investigating the influence of the temperature in contrastive loss, an adaptive temperature mechanism for each sample according to prior domain knowledge is further proposed, leading to better performance. Extensive experiments demonstrate that our method achieves state-of-the-art performance and consistently outperforms baselines.