 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Cold-Start Recommendation via BPE Token-Level Embedding Initialization with LLM
Sep 16, 2025The cold-start issue is the challenge when we talk about recommender systems, especially in the case when we do not have the past interaction data of new users or new items. Content-based features or hybrid solutions are common as conventional solutions, but they can only work in a sparse metadata environment with shallow patterns. In this paper, the efficient cold-start recommendation strategy is presented, which is based on the sub word-level representations by applying Byte Pair Encoding (BPE) tokenization and pre-trained Large Language Model (LLM) embedding in the initialization procedure. We obtain fine-grained token-level vectors that are aligned with the BPE vocabulary as opposed to using coarse-grained sentence embeddings. Together, these token embeddings can be used as dense semantic priors on unseen entities, making immediate recommendation performance possible without user-item interaction history. Our mechanism can be compared to collaborative filtering systems and tested over benchmark datasets with stringent cold-start assumptions. Experimental findings show that the given BPE-LLM method achieves higher Recall@k, NDCG@k, and Hit Rate measurements compared to the standard baseline and displays the same capability of sufficient computational performance. Furthermore, we demonstrate that using subword-aware embeddings yields better generalizability and is more interpretable, especially within a multilingual and sparse input setting. The practical application of token-level semantic initialization as a lightweight, but nevertheless effective extension to modern recommender systems in the zero-shot setting is indicated within this work.
Enhancing Text Authenticity: A Novel Hybrid Approach for AI-Generated Text Detection
Jun 01, 2024


The rapid advancement of Large Language Models (LLMs) has ushered in an era where AI-generated text is increasingly indistinguishable from human-generated content. Detecting AI-generated text has become imperative to combat misinformation, ensure content authenticity, and safeguard against malicious uses of AI. In this paper, we propose a novel hybrid approach that combines traditional TF-IDF techniques with advanced machine learning models, including Bayesian classifiers, Stochastic Gradient Descent (SGD), Categorical Gradient Boosting (CatBoost), and 12 instances of Deberta-v3-large models. Our approach aims to address the challenges associated with detecting AI-generated text by leveraging the strengths of both traditional feature extraction methods and state-of-the-art deep learning models. Through extensive experiments on a comprehensive dataset, we demonstrate the effectiveness of our proposed method in accurately distinguishing between human and AI-generated text. Our approach achieves superior performance compared to existing methods. This research contributes to the advancement of AI-generated text detection techniques and lays the foundation for developing robust solutions to mitigate the challenges posed by AI-generated content.
Optimizing Contrail Detection: A Deep Learning Approach with EfficientNet-b4 Encoding
Apr 20, 2024


In the pursuit of environmental sustainability, the aviation industry faces the challenge of minimizing its ecological footprint. Among the key solutions is contrail avoidance, targeting the linear ice-crystal clouds produced by aircraft exhaust. These contrails exacerbate global warming by trapping atmospheric heat, necessitating precise segmentation and comprehensive analysis of contrail images to gauge their environmental impact. However, this segmentation task is complex due to the varying appearances of contrails under different atmospheric conditions and potential misalignment issues in predictive modeling. This paper presents an innovative deep-learning approach utilizing the efficient net-b4 encoder for feature extraction, seamlessly integrating misalignment correction, soft labeling, and pseudo-labeling techniques to enhance the accuracy and efficiency of contrail detection in satellite imagery. The proposed methodology aims to redefine contrail image analysis and contribute to the objectives of sustainable aviation by providing a robust framework for precise contrail detection and analysis in satellite imagery, thus aiding in the mitigation of aviation's environmental impact.
On The Construction of Extreme Learning Machine for Online and Offline One-Class Classification - An Expanded Toolbox
Jan 17, 2017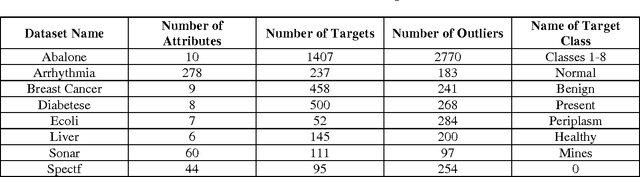
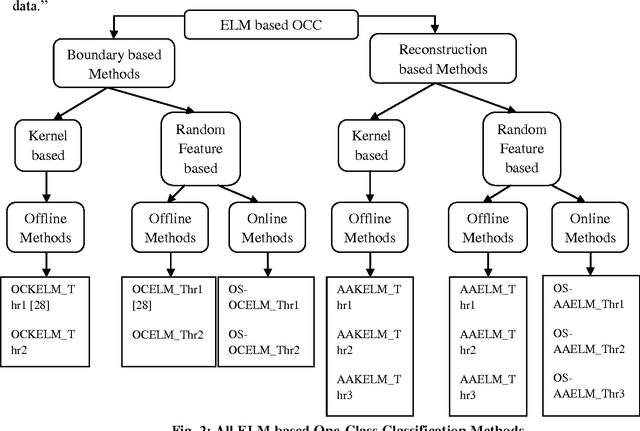
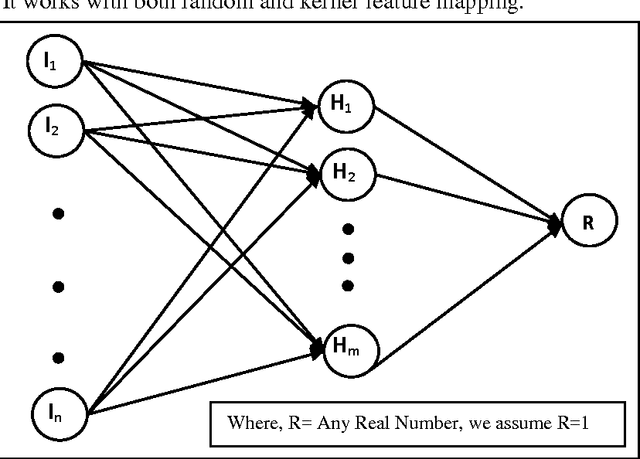
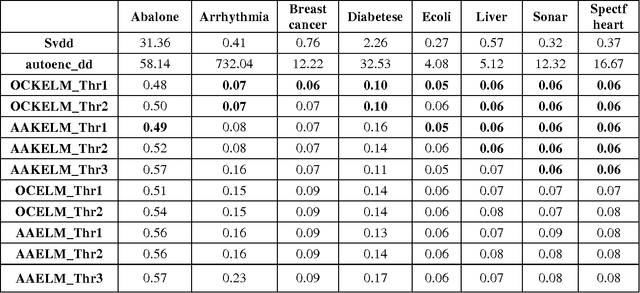
One-Class Classification (OCC) has been prime concern for researchers and effectively employed in various disciplines. But, traditional methods based one-class classifiers are very time consuming due to its iterative process and various parameters tuning. In this paper, we present six OCC methods based on extreme learning machine (ELM) and Online Sequential ELM (OSELM). Our proposed classifiers mainly lie in two categories: reconstruction based and boundary based, which supports both types of learning viz., online and offline learning. Out of various proposed methods, four are offline and remaining two are online methods. Out of four offline methods, two methods perform random feature mapping and two methods perform kernel feature mapping. Kernel feature mapping based approaches have been tested with RBF kernel and online version of one-class classifiers are tested with both types of nodes viz., additive and RBF. It is well known fact that threshold decision is a crucial factor in case of OCC, so, three different threshold deciding criteria have been employed so far and analyses the effectiveness of one threshold deciding criteria over another. Further, these methods are tested on two artificial datasets to check there boundary construction capability and on eight benchmark datasets from different discipline to evaluate the performance of the classifiers. Our proposed classifiers exhibit better performance compared to ten traditional one-class classifiers and ELM based two one-class classifiers. Through proposed one-class classifiers, we intend to expand the functionality of the most used toolbox for OCC i.e. DD toolbox. All of our methods are totally compatible with all the present features of the toolbox.