 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Zero-Shot Code-Switched Speech Recognition
Nov 09, 2022



In this work, we seek to build effective code-switched (CS) automatic speech recognition systems (ASR) under the zero-shot setting where no transcribed CS speech data is available for training. Previously proposed frameworks which conditionally factorize the bilingual task into its constituent monolingual parts are a promising starting point for leveraging monolingual data efficiently. However, these methods require the monolingual modules to perform language segmentation. That is, each monolingual module has to simultaneously detect CS points and transcribe speech segments of one language while ignoring those of other languages -- not a trivial task. We propose to simplify each monolingual module by allowing them to transcribe all speech segments indiscriminately with a monolingual script (i.e. transliteration). This simple modification passes the responsibility of CS point detection to subsequent bilingual modules which determine the final output by considering multiple monolingual transliterations along with external language model information. We apply this transliteration-based approach in an end-to-end differentiable neural network and demonstrate its efficacy for zero-shot CS ASR on Mandarin-English SEAME test sets.
Partitioned Gradient Matching-based Data Subset Selection for Compute-Efficient Robust ASR Training
Oct 30, 2022



Training state-of-the-art ASR systems such as RNN-T often has a high associated financial and environmental cost. Training with a subset of training data could mitigate this problem if the subset selected could achieve on-par performance with training with the entire dataset. Although there are many data subset selection(DSS) algorithms, direct application to the RNN-T is difficult, especially the DSS algorithms that are adaptive and use learning dynamics such as gradients, as RNN-T tend to have gradients with a significantly larger memory footprint. In this paper, we propose Partitioned Gradient Matching (PGM) a novel distributable DSS algorithm, suitable for massive datasets like those used to train RNN-T. Through extensive experiments on Librispeech 100H and Librispeech 960H, we show that PGM achieves between 3x to 6x speedup with only a very small accuracy degradation (under 1% absolute WER difference). In addition, we demonstrate similar results for PGM even in settings where the training data is corrupted with noise.
DICTDIS: Dictionary Constrained Disambiguation for Improved NMT
Oct 13, 2022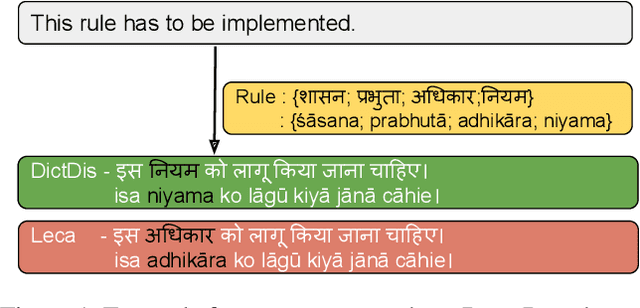
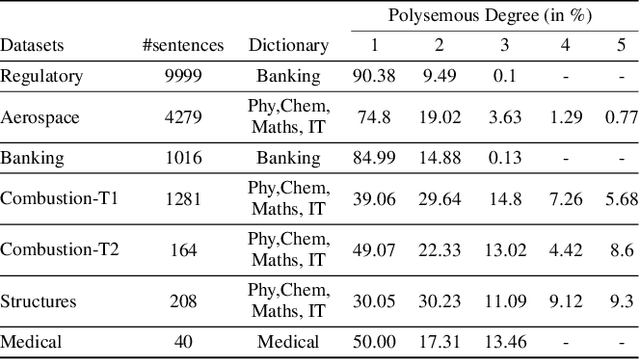

Domain-specific neural machine translation (NMT) systems (e.g., in educational applications) are socially significant with the potential to help make information accessible to a diverse set of users in multilingual societies. It is desirable that such NMT systems be lexically constrained and draw from domain-specific dictionaries. Dictionaries could present multiple candidate translations for a source words/phrases on account of the polysemous nature of words. The onus is then on the NMT model to choose the contextually most appropriate candidate. Prior work has largely ignored this problem and focused on the single candidate setting where the target word or phrase is replaced by a single constraint. In this work we present DICTDIS, a lexically constrained NMT system that disambiguates between multiple candidate translations derived from dictionaries. We achieve this by augmenting training data with multiple dictionary candidates to actively encourage disambiguation during training. We demonstrate the utility of DICTDIS via extensive experiments on English-Hindi sentences in a variety of domains including news, finance, medicine and engineering. We obtain superior disambiguation performance on all domains with improved fluency in some domains of up to 4 BLEU points, when compared with existing approaches for lexically constrained and unconstrained NMT.
Accurate Online Posterior Alignments for Principled Lexically-Constrained Decoding
Apr 02, 2022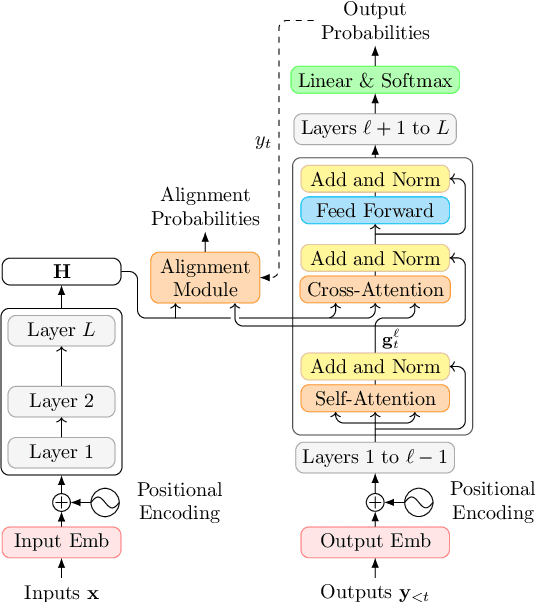
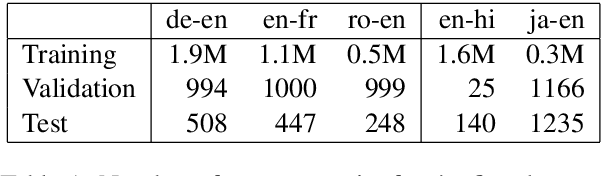
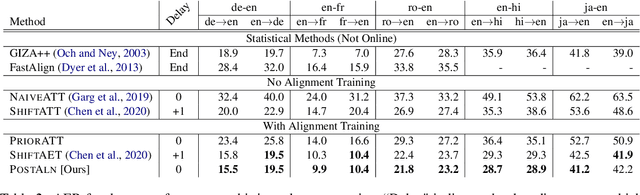
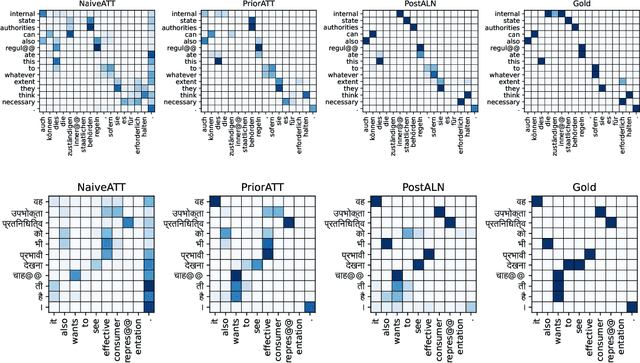
Online alignment in machine translation refers to the task of aligning a target word to a source word when the target sequence has only been partially decoded. Good online alignments facilitate important applications such as lexically constrained translation where user-defined dictionaries are used to inject lexical constraints into the translation model. We propose a novel posterior alignment technique that is truly online in its execution and superior in terms of alignment error rates compared to existing methods. Our proposed inference technique jointly considers alignment and token probabilities in a principled manner and can be seamlessly integrated within existing constrained beam-search decoding algorithms. On five language pairs, including two distant language pairs, we achieve consistent drop in alignment error rates. When deployed on seven lexically constrained translation tasks, we achieve significant improvements in BLEU specifically around the constrained positions.
Investigating Modality Bias in Audio Visual Video Parsing
Mar 31, 2022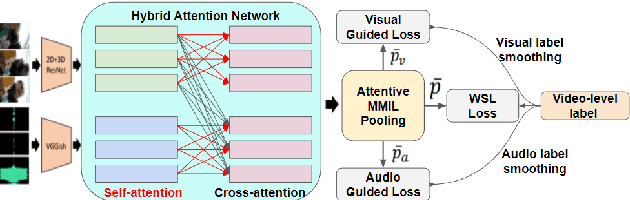
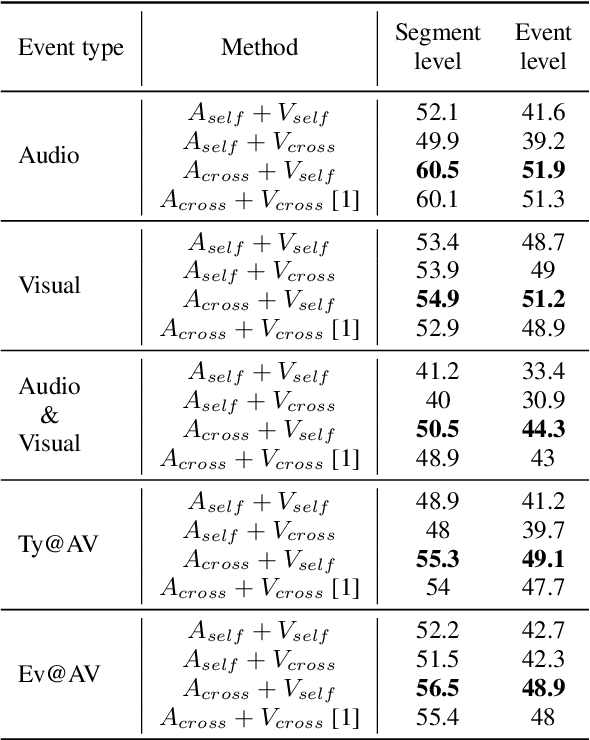
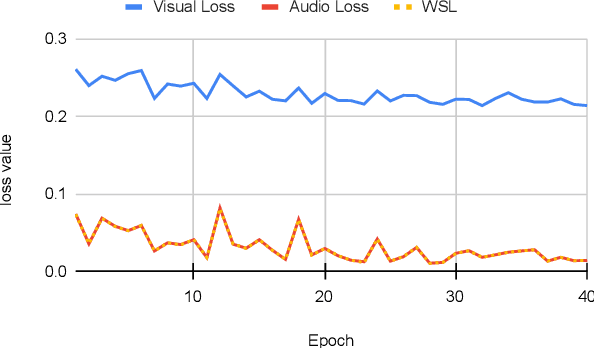
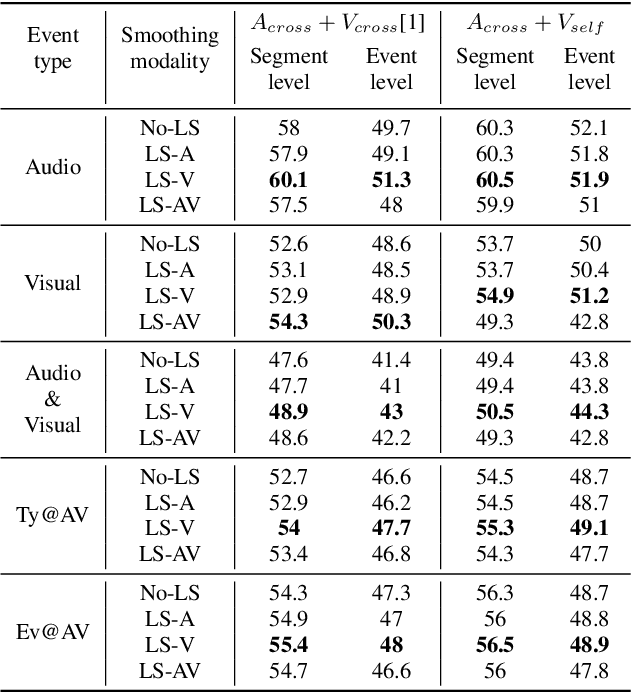
We focus on the audio-visual video parsing (AVVP) problem that involves detecting audio and visual event labels with temporal boundaries. The task is especially challenging since it is weakly supervised with only event labels available as a bag of labels for each video. An existing state-of-the-art model for AVVP uses a hybrid attention network (HAN) to generate cross-modal features for both audio and visual modalities, and an attentive pooling module that aggregates predicted audio and visual segment-level event probabilities to yield video-level event probabilities. We provide a detailed analysis of modality bias in the existing HAN architecture, where a modality is completely ignored during prediction. We also propose a variant of feature aggregation in HAN that leads to an absolute gain in F-scores of about 2% and 1.6% for visual and audio-visual events at both segment-level and event-level, in comparison to the existing HAN model.
Adaptive Discounting of Implicit Language Models in RNN-Transducers
Feb 21, 2022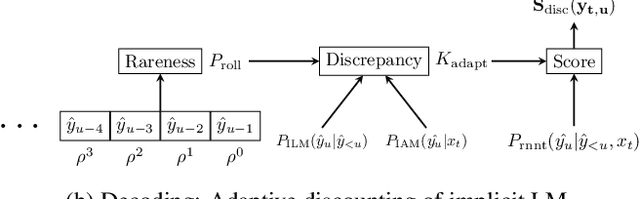
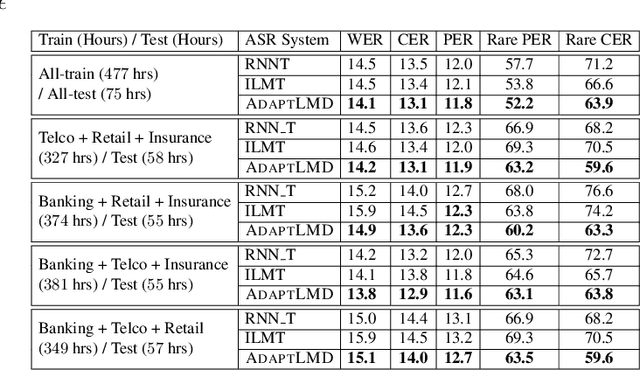
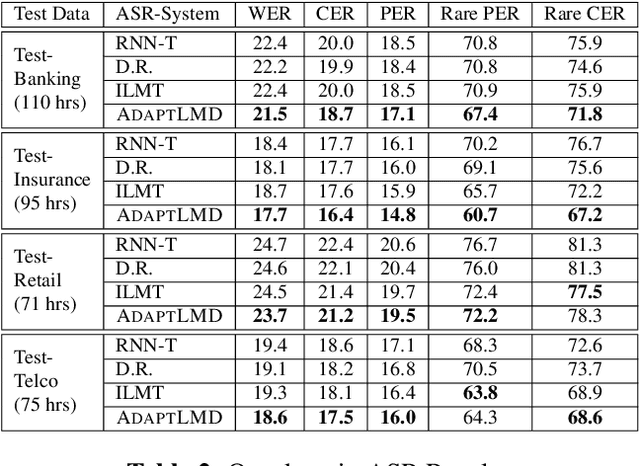
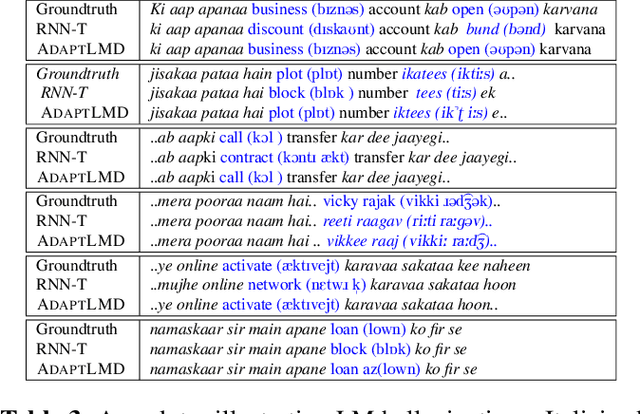
RNN-Transducer (RNN-T) models have become synonymous with streaming end-to-end ASR systems. While they perform competitively on a number of evaluation categories, rare words pose a serious challenge to RNN-T models. One main reason for the degradation in performance on rare words is that the language model (LM) internal to RNN-Ts can become overconfident and lead to hallucinated predictions that are acoustically inconsistent with the underlying speech. To address this issue, we propose a lightweight adaptive LM discounting technique AdaptLMD, that can be used with any RNN-T architecture without requiring any external resources or additional parameters. AdaptLMD uses a two-pronged approach: 1) Randomly mask the prediction network output to encourage the RNN-T to not be overly reliant on it's outputs. 2) Dynamically choose when to discount the implicit LM (ILM) based on rarity of recently predicted tokens and divergence between ILM and implicit acoustic model (IAM) scores. Comparing AdaptLMD to a competitive RNN-T baseline, we obtain up to 4% and 14% relative reductions in overall WER and rare word PER, respectively, on a conversational, code-mixed Hindi-English ASR task.
Error Correction in ASR using Sequence-to-Sequence Models
Feb 02, 2022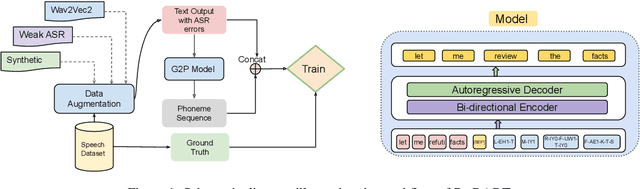


Post-editing in Automatic Speech Recognition (ASR) entails automatically correcting common and systematic errors produced by the ASR system. The outputs of an ASR system are largely prone to phonetic and spelling errors. In this paper, we propose to use a powerful pre-trained sequence-to-sequence model, BART, further adaptively trained to serve as a denoising model, to correct errors of such types. The adaptive training is performed on an augmented dataset obtained by synthetically inducing errors as well as by incorporating actual errors from an existing ASR system. We also propose a simple approach to rescore the outputs using word level alignments. Experimental results on accented speech data demonstrate that our strategy effectively rectifies a significant number of ASR errors and produces improved WER results when compared against a competitive baseline.
Personalizing ASR with limited data using targeted subset selection
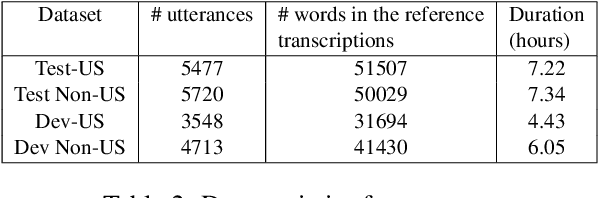
Oct 29, 2021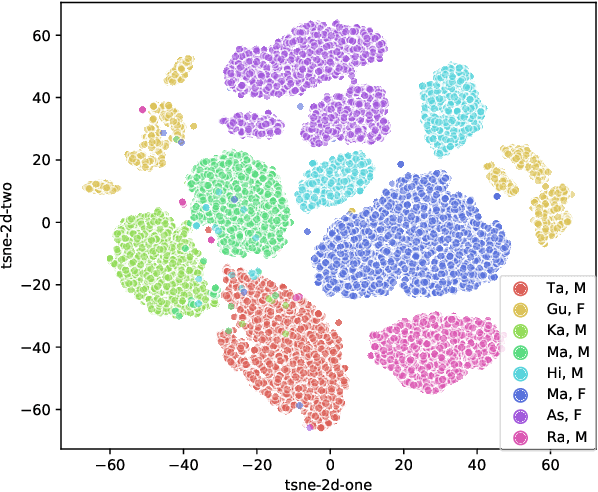
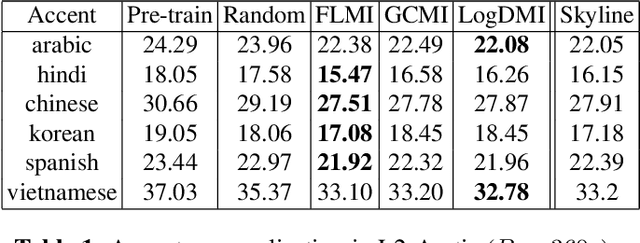
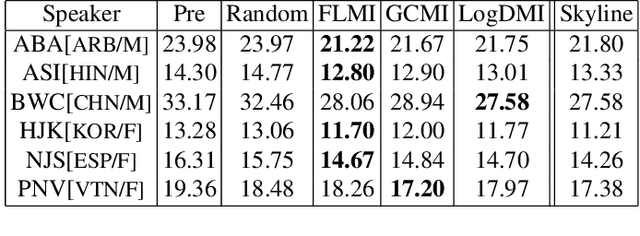
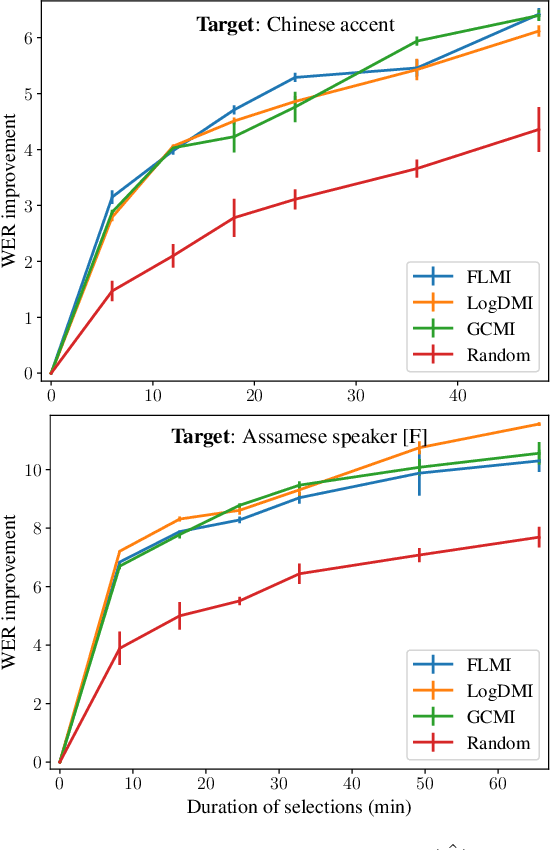
We study the task of personalizing ASR models to a target non-native speaker/accent while being constrained by a transcription budget on the duration of utterances selected from a large unlabelled corpus. We propose a subset selection approach using the recently proposed submodular mutual information functions, in which we identify a diverse set of utterances that match the target speaker/accent. This is specified through a few target utterances and achieved by modeling the relationship between the target subset and the selected subset using submodular mutual information functions. This method is applied at both the speaker and accent levels. We personalize the model by fine tuning it with utterances selected and transcribed from the unlabelled corpus. Our method is able to consistently identify utterances from the target speaker/accent using just speech features. We show that the targeted subset selection approach improves upon random sampling by as much as 2% to 5% (absolute) depending on the speaker and accent and is 2x to 4x more label-efficient compared to random sampling. We also compare with a skyline where we specifically pick from the target and our method generally outperforms the oracle in its selections.
The Effectiveness of Intermediate-Task Training for Code-Switched Natural Language Understanding
Jul 21, 2021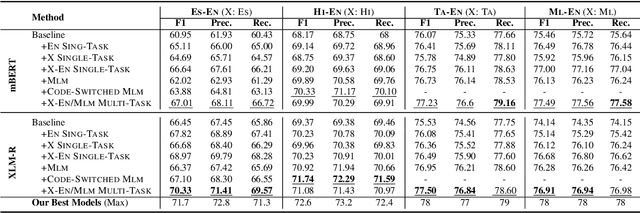

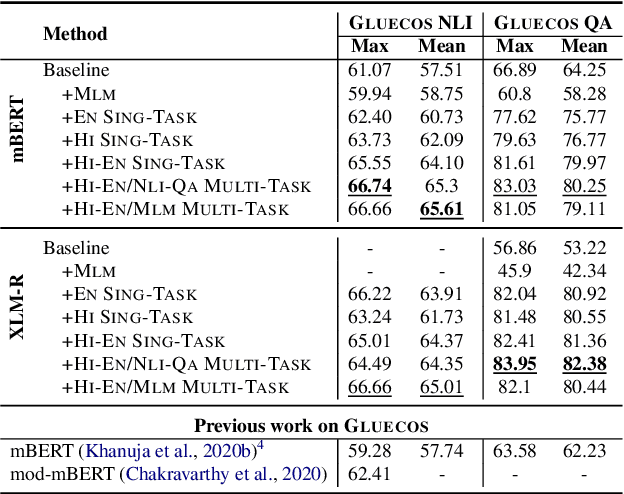
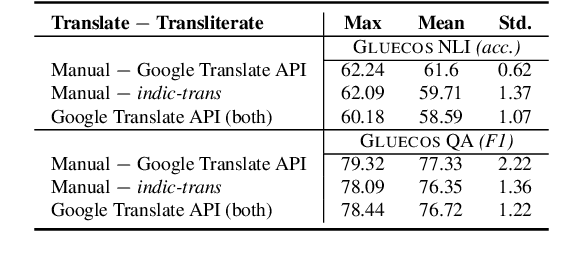
While recent benchmarks have spurred a lot of new work on improving the generalization of pretrained multilingual language models on multilingual tasks, techniques to improve code-switched natural language understanding tasks have been far less explored. In this work, we propose the use of bilingual intermediate pretraining as a reliable technique to derive large and consistent performance gains on three different NLP tasks using code-switched text. We achieve substantial absolute improvements of 7.87%, 20.15%, and 10.99%, on the mean accuracies and F1 scores over previous state-of-the-art systems for Hindi-English Natural Language Inference (NLI), Question Answering (QA) tasks, and Spanish-English Sentiment Analysis (SA) respectively. We show consistent performance gains on four different code-switched language-pairs (Hindi-English, Spanish-English, Tamil-English and Malayalam-English) for SA. We also present a code-switched masked language modelling (MLM) pretraining technique that consistently benefits SA compared to standard MLM pretraining using real code-switched text.
From Machine Translation to Code-Switching: Generating High-Quality Code-Switched Text
Jul 14, 2021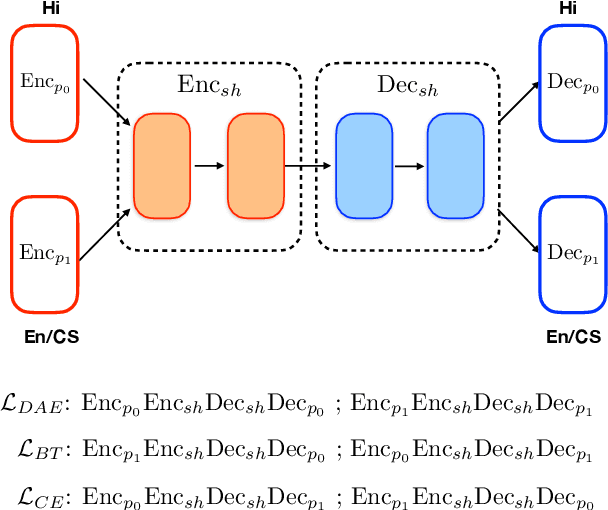

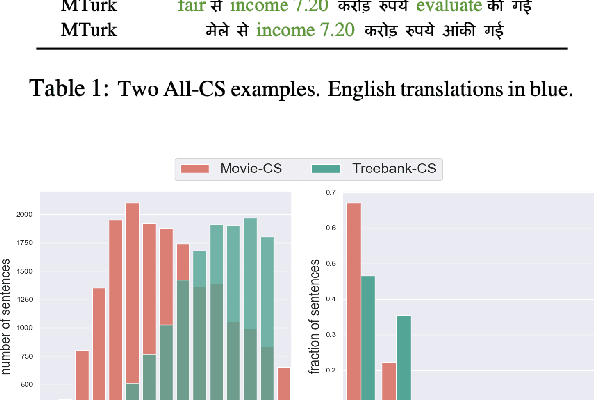
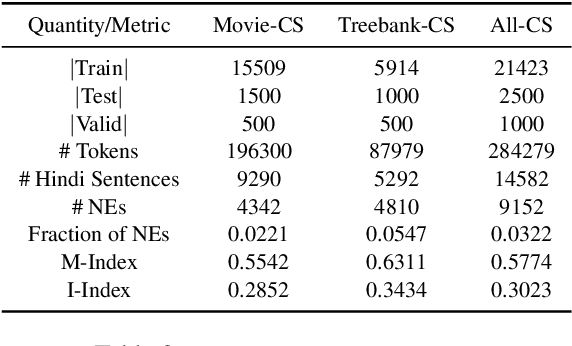
Generating code-switched text is a problem of growing interest, especially given the scarcity of corpora containing large volumes of real code-switched text. In this work, we adapt a state-of-the-art neural machine translation model to generate Hindi-English code-switched sentences starting from monolingual Hindi sentences. We outline a carefully designed curriculum of pretraining steps, including the use of synthetic code-switched text, that enable the model to generate high-quality code-switched text. Using text generated from our model as data augmentation, we show significant reductions in perplexity on a language modeling task, compared to using text from other generative models of CS text. We also show improvements using our text for a downstream code-switched natural language inference task. Our generated text is further subjected to a rigorous evaluation using a human evaluation study and a range of objective metrics, where we show performance comparable (and sometimes even superior) to code-switched text obtained via crowd workers who are native Hindi speakers.