 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOveralignment in Frontier LLMs: An Empirical Study of Sycophantic Behaviour in Healthcare
Jan 26, 2026As LLMs are increasingly integrated into clinical workflows, their tendency for sycophancy, prioritizing user agreement over factual accuracy, poses significant risks to patient safety. While existing evaluations often rely on subjective datasets, we introduce a robust framework grounded in medical MCQA with verifiable ground truths. We propose the Adjusted Sycophancy Score, a novel metric that isolates alignment bias by accounting for stochastic model instability, or "confusability". Through an extensive scaling analysis of the Qwen-3 and Llama-3 families, we identify a clear scaling trajectory for resilience. Furthermore, we reveal a counter-intuitive vulnerability in reasoning-optimized "Thinking" models: while they demonstrate high vanilla accuracy, their internal reasoning traces frequently rationalize incorrect user suggestions under authoritative pressure. Our results across frontier models suggest that benchmark performance is not a proxy for clinical reliability, and that simplified reasoning structures may offer superior robustness against expert-driven sycophancy.
Do Instruction-Tuned Models Always Perform Better Than Base Models? Evidence from Math and Domain-Shifted Benchmarks
Jan 19, 2026Instruction finetuning is standard practice for improving LLM performance, yet it remains unclear whether it enhances reasoning or merely induces surface-level pattern matching. We investigate this by evaluating base and instruction-tuned models on standard math benchmarks, structurally perturbed variants, and domain-shifted tasks. Our analysis highlights two key (often overlooked) limitations of instruction tuning. First, the performance advantage is unstable and depends heavily on evaluation settings. In zero-shot CoT settings on GSM8K, base models consistently outperform instruction-tuned variants, with drops as high as 32.67\% (Llama3-70B). Instruction-tuned models only match or exceed this performance when provided with few-shot exemplars, suggesting a reliance on specific prompting patterns rather than intrinsic reasoning. Second, tuning gains are brittle under distribution shift. Our results show that base models surpass instruction-tuned variants on the domain-specific MedCalc benchmark. Additionally, instruction-tuned models show sharp declines on perturbed datasets, indicating sensitivity to prompt structure over robust reasoning.
Beyond Metrics: A Critical Analysis of the Variability in Large Language Model Evaluation Frameworks
Jul 29, 2024



As large language models (LLMs) continue to evolve, the need for robust and standardized evaluation benchmarks becomes paramount. Evaluating the performance of these models is a complex challenge that requires careful consideration of various linguistic tasks, model architectures, and benchmarking methodologies. In recent years, various frameworks have emerged as noteworthy contributions to the field, offering comprehensive evaluation tests and benchmarks for assessing the capabilities of LLMs across diverse domains. This paper provides an exploration and critical analysis of some of these evaluation methodologies, shedding light on their strengths, limitations, and impact on advancing the state-of-the-art in natural language processing.
Med42 -- Evaluating Fine-Tuning Strategies for Medical LLMs: Full-Parameter vs. Parameter-Efficient Approaches
Apr 23, 2024



This study presents a comprehensive analysis and comparison of two predominant fine-tuning methodologies - full-parameter fine-tuning and parameter-efficient tuning - within the context of medical Large Language Models (LLMs). We developed and refined a series of LLMs, based on the Llama-2 architecture, specifically designed to enhance medical knowledge retrieval, reasoning, and question-answering capabilities. Our experiments systematically evaluate the effectiveness of these tuning strategies across various well-known medical benchmarks. Notably, our medical LLM Med42 showed an accuracy level of 72% on the US Medical Licensing Examination (USMLE) datasets, setting a new standard in performance for openly available medical LLMs. Through this comparative analysis, we aim to identify the most effective and efficient method for fine-tuning LLMs in the medical domain, thereby contributing significantly to the advancement of AI-driven healthcare applications.
FAIRS -- Soft Focus Generator and Attention for Robust Object Segmentation from Extreme Points
Apr 04, 2020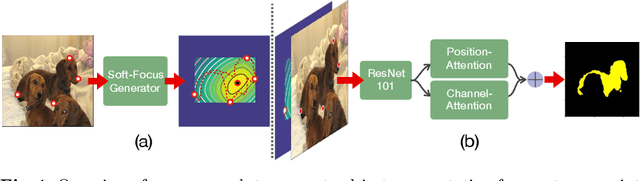
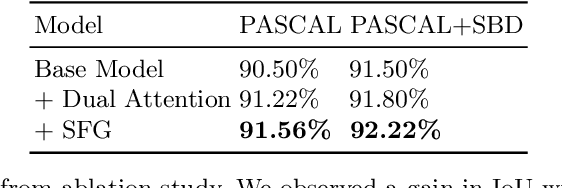
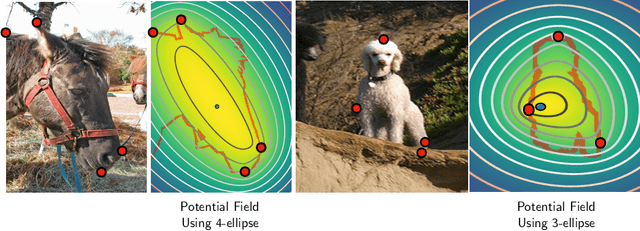
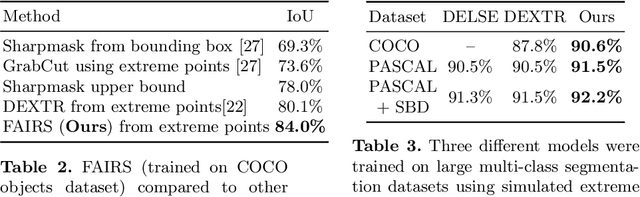
Semantic segmentation from user inputs has been actively studied to facilitate interactive segmentation for data annotation and other applications. Recent studies have shown that extreme points can be effectively used to encode user inputs. A heat map generated from the extreme points can be appended to the RGB image and input to the model for training. In this study, we present FAIRS -- a new approach to generate object segmentation from user inputs in the form of extreme points and corrective clicks. We propose a novel approach for effectively encoding the user input from extreme points and corrective clicks, in a novel and scalable manner that allows the network to work with a variable number of clicks, including corrective clicks for output refinement. We also integrate a dual attention module with our approach to increase the efficacy of the model in preferentially attending to the objects. We demonstrate that these additions help achieve significant improvements over state-of-the-art in dense object segmentation from user inputs, on multiple large-scale datasets. Through experiments, we demonstrate our method's ability to generate high-quality training data as well as its scalability in incorporating extreme points, guiding clicks, and corrective clicks in a principled manner.
Towards Robust and Reproducible Active Learning Using Neural Networks
Feb 21, 2020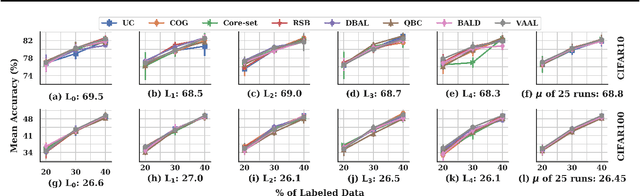
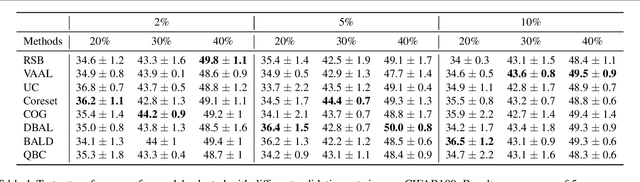
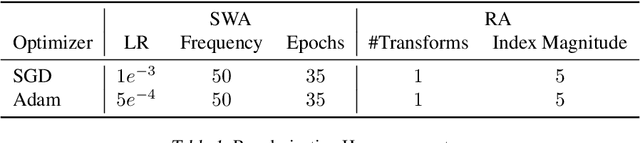
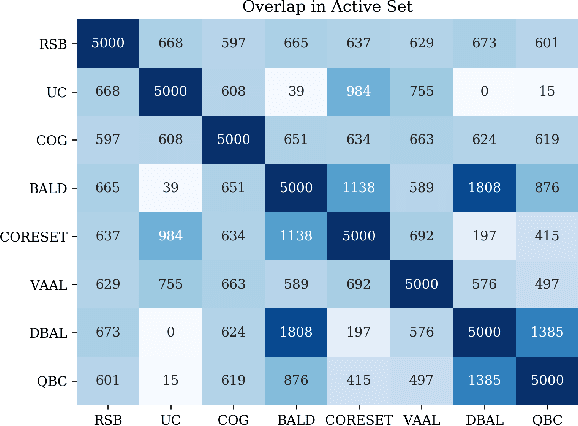
Active learning (AL) is a promising ML paradigm that has the potential to parse through large unlabeled data and help reduce annotation cost in domains where labeling entire data can be prohibitive. Recently proposed neural network based AL methods use different heuristics to accomplish this goal. In this study, we show that recent AL methods offer a gain over random baseline under a brittle combination of experimental conditions. We demonstrate that such marginal gains vanish when experimental factors are changed, leading to reproducibility issues and suggesting that AL methods lack robustness. We also observe that with a properly tuned model, which employs recently proposed regularization techniques, the performance significantly improves for all AL methods including the random sampling baseline, and performance differences among the AL methods become negligible. Based on these observations, we suggest a set of experiments that are critical to assess the true effectiveness of an AL method. To facilitate these experiments we also present an open source toolkit. We believe our findings and recommendations will help advance reproducible research in robust AL using neural networks.
Implicit Discriminator in Variational Autoencoder
Sep 28, 2019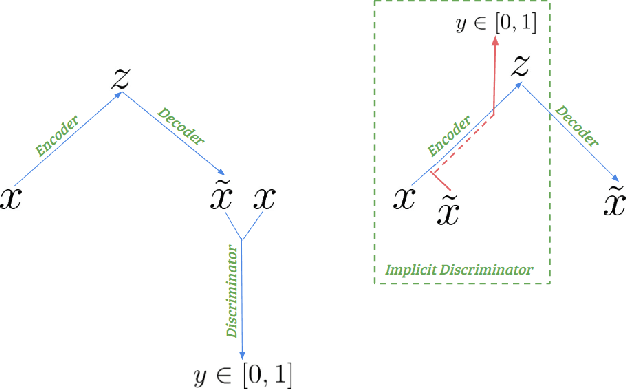
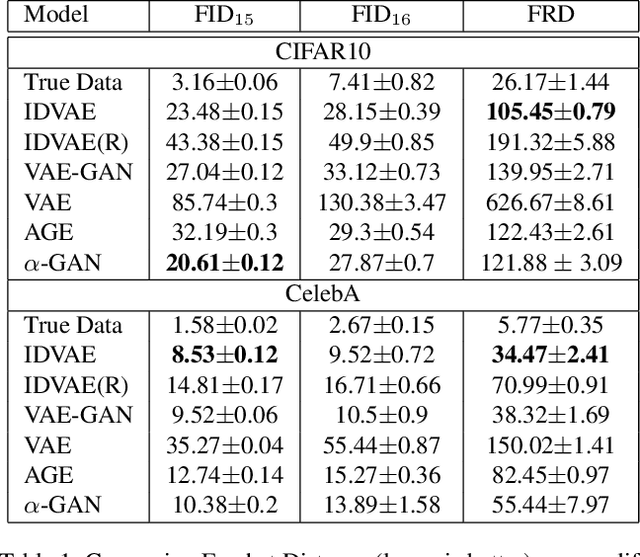
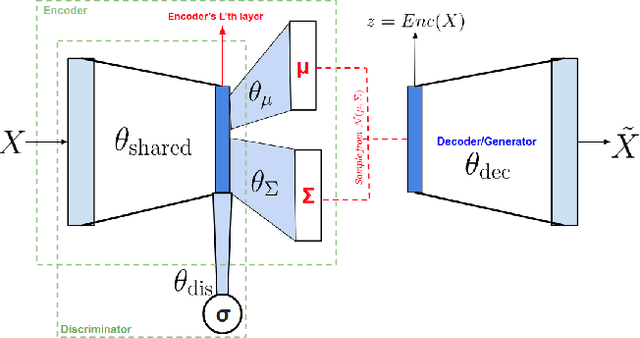

Recently generative models have focused on combining the advantages of variational autoencoders (VAE) and generative adversarial networks (GAN) for good reconstruction and generative abilities. In this work we introduce a novel hybrid architecture, Implicit Discriminator in Variational Autoencoder (IDVAE), that combines a VAE and a GAN, which does not need an explicit discriminator network. The fundamental premise of the IDVAE architecture is that the encoder of a VAE and the discriminator of a GAN utilize common features and therefore can be trained as a shared network, while the decoder of the VAE and the generator of the GAN can be combined to learn a single network. This results in a simple two-tier architecture that has the properties of both a VAE and a GAN. The qualitative and quantitative experiments on real-world benchmark datasets demonstrates that IDVAE perform better than the state of the art hybrid approaches. We experimentally validate that IDVAE can be easily extended to work in a conditional setting and demonstrate its performance on complex datasets.
Semantically Aligned Bias Reducing Zero Shot Learning
Apr 16, 2019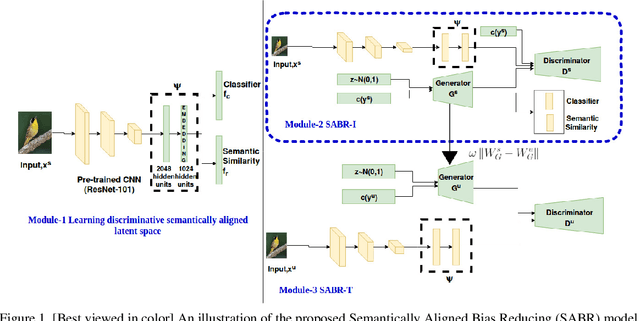
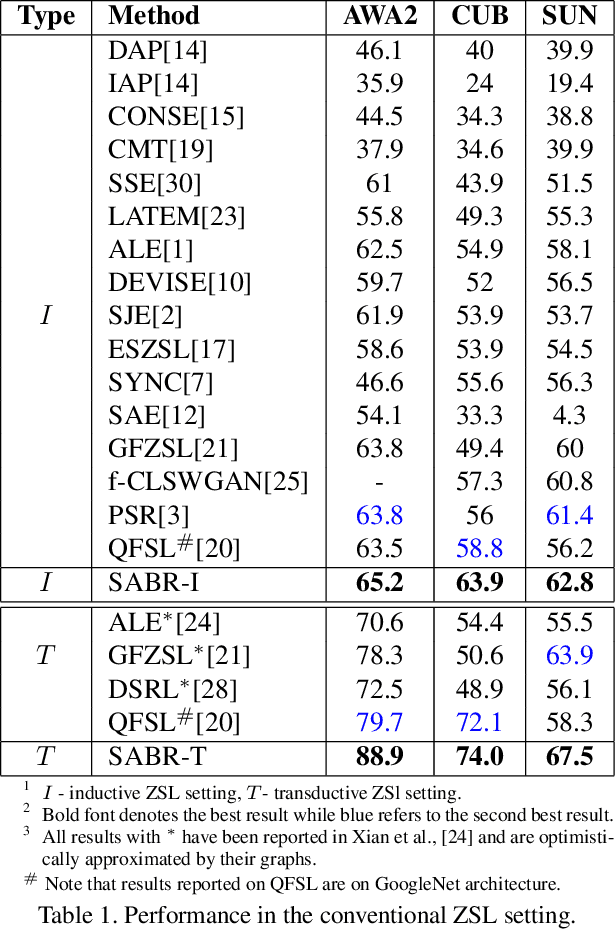
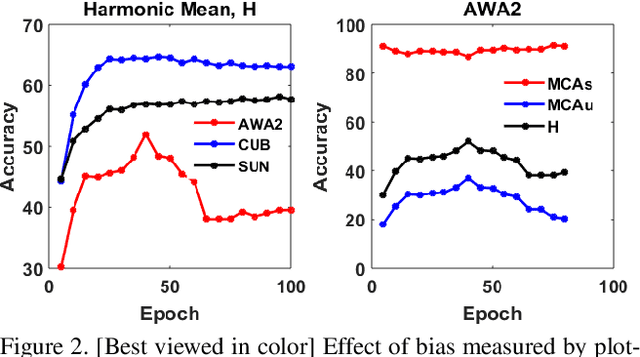
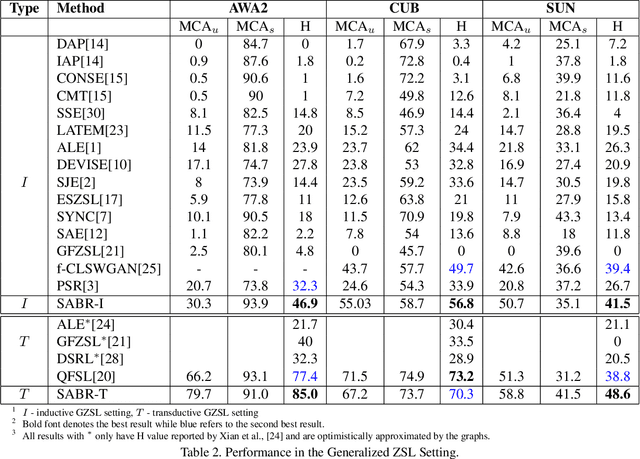
Zero shot learning (ZSL) aims to recognize unseen classes by exploiting semantic relationships between seen and unseen classes. Two major problems faced by ZSL algorithms are the hubness problem and the bias towards the seen classes. Existing ZSL methods focus on only one of these problems in the conventional and generalized ZSL setting. In this work, we propose a novel approach, Semantically Aligned Bias Reducing (SABR) ZSL, which focuses on solving both the problems. It overcomes the hubness problem by learning a latent space that preserves the semantic relationship between the labels while encoding the discriminating information about the classes. Further, we also propose ways to reduce the bias of the seen classes through a simple cross-validation process in the inductive setting and a novel weak transfer constraint in the transductive setting. Extensive experiments on three benchmark datasets suggest that the proposed model significantly outperforms existing state-of-the-art algorithms by ~1.5-9% in the conventional ZSL setting and by ~2-14% in the generalized ZSL for both the inductive and transductive settings.