 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Examination Framework: A Task-Agnostic Diagnostic for Information Fidelity in Text-to-Text Generation
Jan 27, 2026Traditional metrics like BLEU and BERTScore fail to capture semantic fidelity in generative text-to-text tasks. We adapt the Cross-Examination Framework (CEF) for a reference-free, multi-dimensional evaluation by treating the source and candidate as independent knowledge bases. CEF generates verifiable questions from each text and performs a cross-examination to derive three interpretable scores: Coverage, Conformity, and Consistency. Validated across translation, summarization and clinical note-generation, our framework identifies critical errors, such as content omissions and factual contradictions, missed by standard metrics. A key contribution is a systematic robustness analysis to select a stable judge model. Crucially, the strong correlation between our reference-free and with-reference modes validates CEF's reliability without gold references. Furthermore, human expert validation demonstrates that CEF mismatching questions align with meaning-altering semantic errors higher than with non-semantic errors, particularly excelling at identifying entity-based and relational distortions.
Overalignment in Frontier LLMs: An Empirical Study of Sycophantic Behaviour in Healthcare
Jan 26, 2026As LLMs are increasingly integrated into clinical workflows, their tendency for sycophancy, prioritizing user agreement over factual accuracy, poses significant risks to patient safety. While existing evaluations often rely on subjective datasets, we introduce a robust framework grounded in medical MCQA with verifiable ground truths. We propose the Adjusted Sycophancy Score, a novel metric that isolates alignment bias by accounting for stochastic model instability, or "confusability". Through an extensive scaling analysis of the Qwen-3 and Llama-3 families, we identify a clear scaling trajectory for resilience. Furthermore, we reveal a counter-intuitive vulnerability in reasoning-optimized "Thinking" models: while they demonstrate high vanilla accuracy, their internal reasoning traces frequently rationalize incorrect user suggestions under authoritative pressure. Our results across frontier models suggest that benchmark performance is not a proxy for clinical reliability, and that simplified reasoning structures may offer superior robustness against expert-driven sycophancy.
Named Clinical Entity Recognition Benchmark
Oct 07, 2024



This technical report introduces a Named Clinical Entity Recognition Benchmark for evaluating language models in healthcare, addressing the crucial natural language processing (NLP) task of extracting structured information from clinical narratives to support applications like automated coding, clinical trial cohort identification, and clinical decision support. The leaderboard provides a standardized platform for assessing diverse language models, including encoder and decoder architectures, on their ability to identify and classify clinical entities across multiple medical domains. A curated collection of openly available clinical datasets is utilized, encompassing entities such as diseases, symptoms, medications, procedures, and laboratory measurements. Importantly, these entities are standardized according to the Observational Medical Outcomes Partnership (OMOP) Common Data Model, ensuring consistency and interoperability across different healthcare systems and datasets, and a comprehensive evaluation of model performance. Performance of models is primarily assessed using the F1-score, and it is complemented by various assessment modes to provide comprehensive insights into model performance. The report also includes a brief analysis of models evaluated to date, highlighting observed trends and limitations. By establishing this benchmarking framework, the leaderboard aims to promote transparency, facilitate comparative analyses, and drive innovation in clinical entity recognition tasks, addressing the need for robust evaluation methods in healthcare NLP.
MEDIC: Towards a Comprehensive Framework for Evaluating LLMs in Clinical Applications
Sep 11, 2024



The rapid development of Large Language Models (LLMs) for healthcare applications has spurred calls for holistic evaluation beyond frequently-cited benchmarks like USMLE, to better reflect real-world performance. While real-world assessments are valuable indicators of utility, they often lag behind the pace of LLM evolution, likely rendering findings obsolete upon deployment. This temporal disconnect necessitates a comprehensive upfront evaluation that can guide model selection for specific clinical applications. We introduce MEDIC, a framework assessing LLMs across five critical dimensions of clinical competence: medical reasoning, ethics and bias, data and language understanding, in-context learning, and clinical safety. MEDIC features a novel cross-examination framework quantifying LLM performance across areas like coverage and hallucination detection, without requiring reference outputs. We apply MEDIC to evaluate LLMs on medical question-answering, safety, summarization, note generation, and other tasks. Our results show performance disparities across model sizes, baseline vs medically finetuned models, and have implications on model selection for applications requiring specific model strengths, such as low hallucination or lower cost of inference. MEDIC's multifaceted evaluation reveals these performance trade-offs, bridging the gap between theoretical capabilities and practical implementation in healthcare settings, ensuring that the most promising models are identified and adapted for diverse healthcare applications.
Med42-v2: A Suite of Clinical LLMs
Aug 12, 2024



Med42-v2 introduces a suite of clinical large language models (LLMs) designed to address the limitations of generic models in healthcare settings. These models are built on Llama3 architecture and fine-tuned using specialized clinical data. They underwent multi-stage preference alignment to effectively respond to natural prompts. While generic models are often preference-aligned to avoid answering clinical queries as a precaution, Med42-v2 is specifically trained to overcome this limitation, enabling its use in clinical settings. Med42-v2 models demonstrate superior performance compared to the original Llama3 models in both 8B and 70B parameter configurations and GPT-4 across various medical benchmarks. These LLMs are developed to understand clinical queries, perform reasoning tasks, and provide valuable assistance in clinical environments. The models are now publicly available at \href{https://huggingface.co/m42-health}{https://huggingface.co/m42-health}.
Beyond Metrics: A Critical Analysis of the Variability in Large Language Model Evaluation Frameworks
Jul 29, 2024



As large language models (LLMs) continue to evolve, the need for robust and standardized evaluation benchmarks becomes paramount. Evaluating the performance of these models is a complex challenge that requires careful consideration of various linguistic tasks, model architectures, and benchmarking methodologies. In recent years, various frameworks have emerged as noteworthy contributions to the field, offering comprehensive evaluation tests and benchmarks for assessing the capabilities of LLMs across diverse domains. This paper provides an exploration and critical analysis of some of these evaluation methodologies, shedding light on their strengths, limitations, and impact on advancing the state-of-the-art in natural language processing.
iREL at SemEval-2024 Task 9: Improving Conventional Prompting Methods for Brain Teasers
May 25, 2024



This paper describes our approach for SemEval-2024 Task 9: BRAINTEASER: A Novel Task Defying Common Sense. The BRAINTEASER task comprises multiple-choice Question Answering designed to evaluate the models' lateral thinking capabilities. It consists of Sentence Puzzle and Word Puzzle subtasks that require models to defy default common-sense associations and exhibit unconventional thinking. We propose a unique strategy to improve the performance of pre-trained language models, notably the Gemini 1.0 Pro Model, in both subtasks. We employ static and dynamic few-shot prompting techniques and introduce a model-generated reasoning strategy that utilizes the LLM's reasoning capabilities to improve performance. Our approach demonstrated significant improvements, showing that it performed better than the baseline models by a considerable margin but fell short of performing as well as the human annotators, thus highlighting the efficacy of the proposed strategies.
Med42 -- Evaluating Fine-Tuning Strategies for Medical LLMs: Full-Parameter vs. Parameter-Efficient Approaches
Apr 23, 2024



This study presents a comprehensive analysis and comparison of two predominant fine-tuning methodologies - full-parameter fine-tuning and parameter-efficient tuning - within the context of medical Large Language Models (LLMs). We developed and refined a series of LLMs, based on the Llama-2 architecture, specifically designed to enhance medical knowledge retrieval, reasoning, and question-answering capabilities. Our experiments systematically evaluate the effectiveness of these tuning strategies across various well-known medical benchmarks. Notably, our medical LLM Med42 showed an accuracy level of 72% on the US Medical Licensing Examination (USMLE) datasets, setting a new standard in performance for openly available medical LLMs. Through this comparative analysis, we aim to identify the most effective and efficient method for fine-tuning LLMs in the medical domain, thereby contributing significantly to the advancement of AI-driven healthcare applications.
Neural models for Factual Inconsistency Classification with Explanations
Jun 15, 2023



Factual consistency is one of the most important requirements when editing high quality documents. It is extremely important for automatic text generation systems like summarization, question answering, dialog modeling, and language modeling. Still, automated factual inconsistency detection is rather under-studied. Existing work has focused on (a) finding fake news keeping a knowledge base in context, or (b) detecting broad contradiction (as part of natural language inference literature). However, there has been no work on detecting and explaining types of factual inconsistencies in text, without any knowledge base in context. In this paper, we leverage existing work in linguistics to formally define five types of factual inconsistencies. Based on this categorization, we contribute a novel dataset, FICLE (Factual Inconsistency CLassification with Explanation), with ~8K samples where each sample consists of two sentences (claim and context) annotated with type and span of inconsistency. When the inconsistency relates to an entity type, it is labeled as well at two levels (coarse and fine-grained). Further, we leverage this dataset to train a pipeline of four neural models to predict inconsistency type with explanations, given a (claim, context) sentence pair. Explanations include inconsistent claim fact triple, inconsistent context span, inconsistent claim component, coarse and fine-grained inconsistent entity types. The proposed system first predicts inconsistent spans from claim and context; and then uses them to predict inconsistency types and inconsistent entity types (when inconsistency is due to entities). We experiment with multiple Transformer-based natural language classification as well as generative models, and find that DeBERTa performs the best. Our proposed methods provide a weighted F1 of ~87% for inconsistency type classification across the five classes.
Identifying COVID-19 Fake News in Social Media
Feb 01, 2021
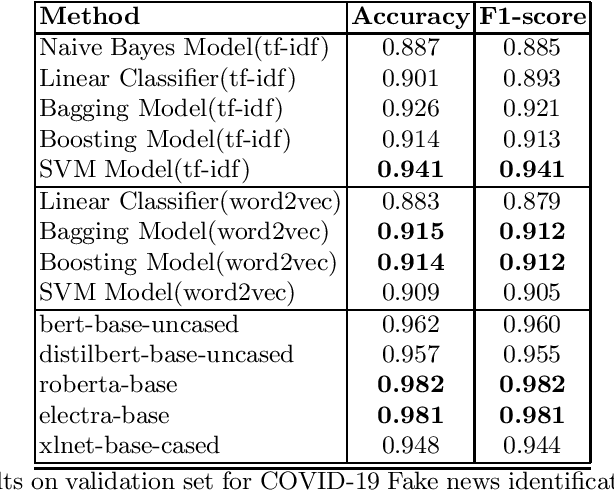
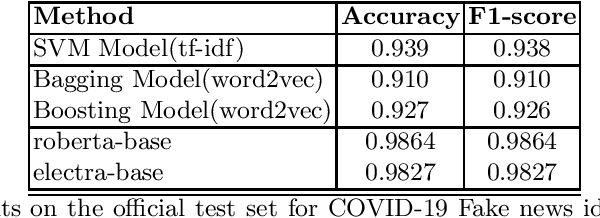
The evolution of social media platforms have empowered everyone to access information easily. Social media users can easily share information with the rest of the world. This may sometimes encourage spread of fake news, which can result in undesirable consequences. In this work, we train models which can identify health news related to COVID-19 pandemic as real or fake. Our models achieve a high F1-score of 98.64%. Our models achieve second place on the leaderboard, tailing the first position with a very narrow margin 0.05% points.