 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonlinear Inductive Matrix Completion based on One-layer Neural Networks
May 26, 2018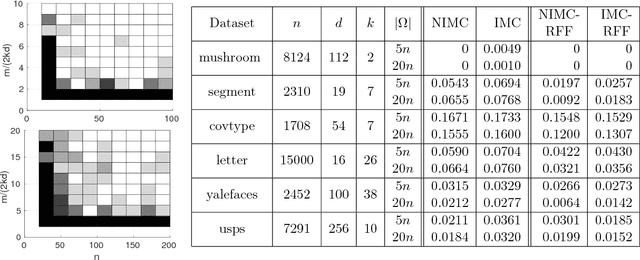

The goal of a recommendation system is to predict the interest of a user in a given item by exploiting the existing set of ratings as well as certain user/item features. A standard approach to modeling this problem is Inductive Matrix Completion where the predicted rating is modeled as an inner product of the user and the item features projected onto a latent space. In order to learn the parameters effectively from a small number of observed ratings, the latent space is constrained to be low-dimensional which implies that the parameter matrix is constrained to be low-rank. However, such bilinear modeling of the ratings can be limiting in practice and non-linear prediction functions can lead to significant improvements. A natural approach to introducing non-linearity in the prediction function is to apply a non-linear activation function on top of the projected user/item features. Imposition of non-linearities further complicates an already challenging problem that has two sources of non-convexity: a) low-rank structure of the parameter matrix, and b) non-linear activation function. We show that one can still solve the non-linear Inductive Matrix Completion problem using gradient descent type methods as long as the solution is initialized well. That is, close to the optima, the optimization function is strongly convex and hence admits standard optimization techniques, at least for certain activation functions, such as Sigmoid and tanh. We also highlight the importance of the activation function and show how ReLU can behave significantly differently than say a sigmoid function. Finally, we apply our proposed technique to recommendation systems and semi-supervised clustering, and show that our method can lead to much better performance than standard linear Inductive Matrix Completion methods.
Smoothed analysis for low-rank solutions to semidefinite programs in quadratic penalty form
Mar 01, 2018Semidefinite programs (SDP) are important in learning and combinatorial optimization with numerous applications. In pursuit of low-rank solutions and low complexity algorithms, we consider the Burer--Monteiro factorization approach for solving SDPs. We show that all approximate local optima are global optima for the penalty formulation of appropriately rank-constrained SDPs as long as the number of constraints scales sub-quadratically with the desired rank of the optimal solution. Our result is based on a simple penalty function formulation of the rank-constrained SDP along with a smoothed analysis to avoid worst-case cost matrices. We particularize our results to two applications, namely, Max-Cut and matrix completion.
Non-convex Optimization for Machine Learning
Dec 21, 2017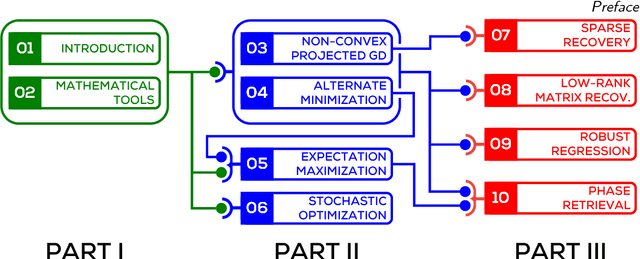

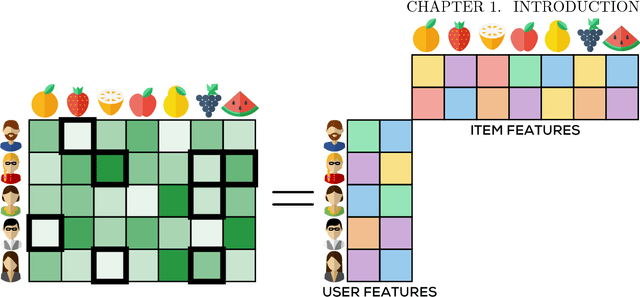

A vast majority of machine learning algorithms train their models and perform inference by solving optimization problems. In order to capture the learning and prediction problems accurately, structural constraints such as sparsity or low rank are frequently imposed or else the objective itself is designed to be a non-convex function. This is especially true of algorithms that operate in high-dimensional spaces or that train non-linear models such as tensor models and deep networks. The freedom to express the learning problem as a non-convex optimization problem gives immense modeling power to the algorithm designer, but often such problems are NP-hard to solve. A popular workaround to this has been to relax non-convex problems to convex ones and use traditional methods to solve the (convex) relaxed optimization problems. However this approach may be lossy and nevertheless presents significant challenges for large scale optimization. On the other hand, direct approaches to non-convex optimization have met with resounding success in several domains and remain the methods of choice for the practitioner, as they frequently outperform relaxation-based techniques - popular heuristics include projected gradient descent and alternating minimization. However, these are often poorly understood in terms of their convergence and other properties. This monograph presents a selection of recent advances that bridge a long-standing gap in our understanding of these heuristics. The monograph will lead the reader through several widely used non-convex optimization techniques, as well as applications thereof. The goal of this monograph is to both, introduce the rich literature in this area, as well as equip the reader with the tools and techniques needed to analyze these simple procedures for non-convex problems.
* The official publication is available from now publishers via http://dx.doi.org/10.1561/2200000058
Leveraging Distributional Semantics for Multi-Label Learning
Nov 10, 2017

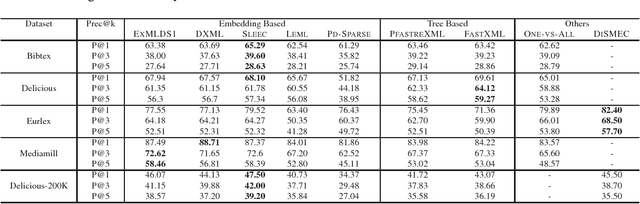
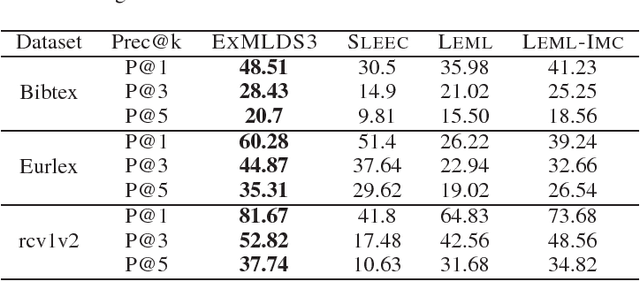
We present a novel and scalable label embedding framework for large-scale multi-label learning a.k.a ExMLDS (Extreme Multi-Label Learning using Distributional Semantics). Our approach draws inspiration from ideas rooted in distributional semantics, specifically the Skip Gram Negative Sampling (SGNS) approach, widely used to learn word embeddings for natural language processing tasks. Learning such embeddings can be reduced to a certain matrix factorization. Our approach is novel in that it highlights interesting connections between label embedding methods used for multi-label learning and paragraph/document embedding methods commonly used for learning representations of text data. The framework can also be easily extended to incorporate auxiliary information such as label-label correlations; this is crucial especially when there are a lot of missing labels in the training data. We demonstrate the effectiveness of our approach through an extensive set of experiments on a variety of benchmark datasets, and show that the proposed learning methods perform favorably compared to several baselines and state-of-the-art methods for large-scale multi-label learning. To facilitate end-to-end learning, we develop a joint learning algorithm that can learn the embeddings as well as a regression model that predicts these embeddings given input features, via efficient gradient-based methods.
FlashProfile: Interactive Synthesis of Syntactic Profiles
Sep 17, 2017

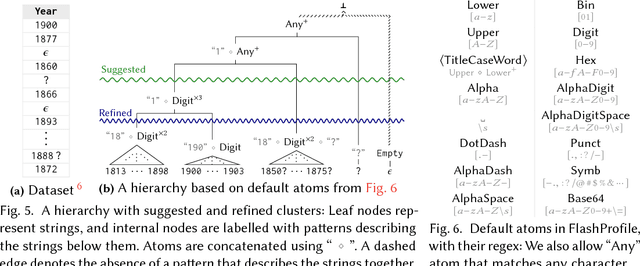
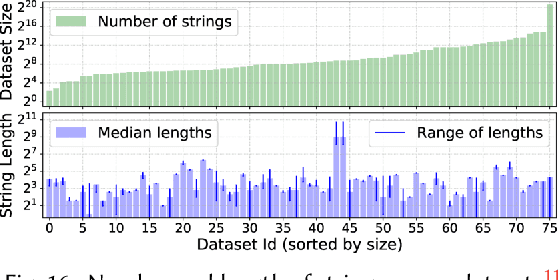
We address the problem of learning comprehensive syntactic profiles for a set of strings. Real-world datasets, typically curated from multiple sources, often contain data in various formats. Thus any data processing task is preceded by the critical step of data format identification. However, manual inspection of data to identify various formats is infeasible in standard big-data scenarios. We present a technique for generating comprehensive syntactic profiles in terms of user-defined patterns that also allows for interactive refinement. We define a syntactic profile as a set of succinct patterns that describe the entire dataset. Our approach efficiently learns such profiles, and allows refinement by exposing a desired number of patterns. Our implementation, FlashProfile, shows a median profiling time of 0.7s over 142 tasks on 74 real datasets. We also show that access to the generated data profiles allow for more accurate synthesis of programs, using fewer examples in programming-by-example workflows.
Learning Mixture of Gaussians with Streaming Data
Jul 08, 2017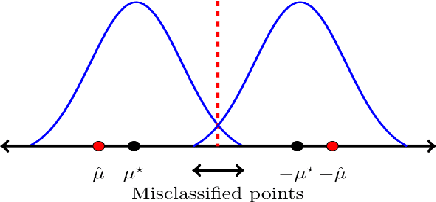
In this paper, we study the problem of learning a mixture of Gaussians with streaming data: given a stream of $N$ points in $d$ dimensions generated by an unknown mixture of $k$ spherical Gaussians, the goal is to estimate the model parameters using a single pass over the data stream. We analyze a streaming version of the popular Lloyd's heuristic and show that the algorithm estimates all the unknown centers of the component Gaussians accurately if they are sufficiently separated. Assuming each pair of centers are $C\sigma$ distant with $C=\Omega((k\log k)^{1/4}\sigma)$ and where $\sigma^2$ is the maximum variance of any Gaussian component, we show that asymptotically the algorithm estimates the centers optimally (up to constants); our center separation requirement matches the best known result for spherical Gaussians \citep{vempalawang}. For finite samples, we show that a bias term based on the initial estimate decreases at $O(1/{\rm poly}(N))$ rate while variance decreases at nearly optimal rate of $\sigma^2 d/N$. Our analysis requires seeding the algorithm with a good initial estimate of the true cluster centers for which we provide an online PCA based clustering algorithm. Indeed, the asymptotic per-step time complexity of our algorithm is the optimal $d\cdot k$ while space complexity of our algorithm is $O(dk\log k)$. In addition to the bias and variance terms which tend to $0$, the hard-thresholding based updates of streaming Lloyd's algorithm is agnostic to the data distribution and hence incurs an approximation error that cannot be avoided. However, by using a streaming version of the classical (soft-thresholding-based) EM method that exploits the Gaussian distribution explicitly, we show that for a mixture of two Gaussians the true means can be estimated consistently, with estimation error decreasing at nearly optimal rate, and tending to $0$ for $N\rightarrow \infty$.
Recovery Guarantees for One-hidden-layer Neural Networks
Jun 10, 2017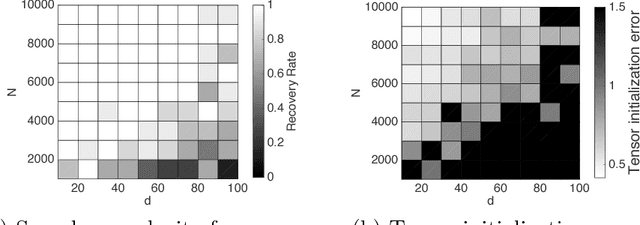

In this paper, we consider regression problems with one-hidden-layer neural networks (1NNs). We distill some properties of activation functions that lead to $\mathit{local~strong~convexity}$ in the neighborhood of the ground-truth parameters for the 1NN squared-loss objective. Most popular nonlinear activation functions satisfy the distilled properties, including rectified linear units (ReLUs), leaky ReLUs, squared ReLUs and sigmoids. For activation functions that are also smooth, we show $\mathit{local~linear~convergence}$ guarantees of gradient descent under a resampling rule. For homogeneous activations, we show tensor methods are able to initialize the parameters to fall into the local strong convexity region. As a result, tensor initialization followed by gradient descent is guaranteed to recover the ground truth with sample complexity $ d \cdot \log(1/\epsilon) \cdot \mathrm{poly}(k,\lambda )$ and computational complexity $n\cdot d \cdot \mathrm{poly}(k,\lambda) $ for smooth homogeneous activations with high probability, where $d$ is the dimension of the input, $k$ ($k\leq d$) is the number of hidden nodes, $\lambda$ is a conditioning property of the ground-truth parameter matrix between the input layer and the hidden layer, $\epsilon$ is the targeted precision and $n$ is the number of samples. To the best of our knowledge, this is the first work that provides recovery guarantees for 1NNs with both sample complexity and computational complexity $\mathit{linear}$ in the input dimension and $\mathit{logarithmic}$ in the precision.
Fast Second-order Cone Programming for Safe Mission Planning
Feb 27, 2017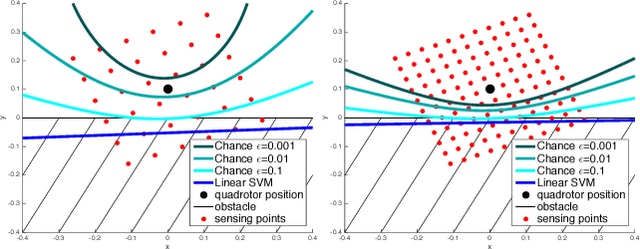
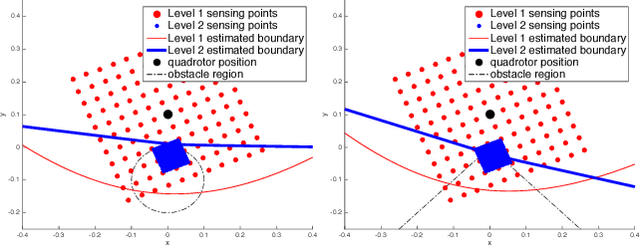
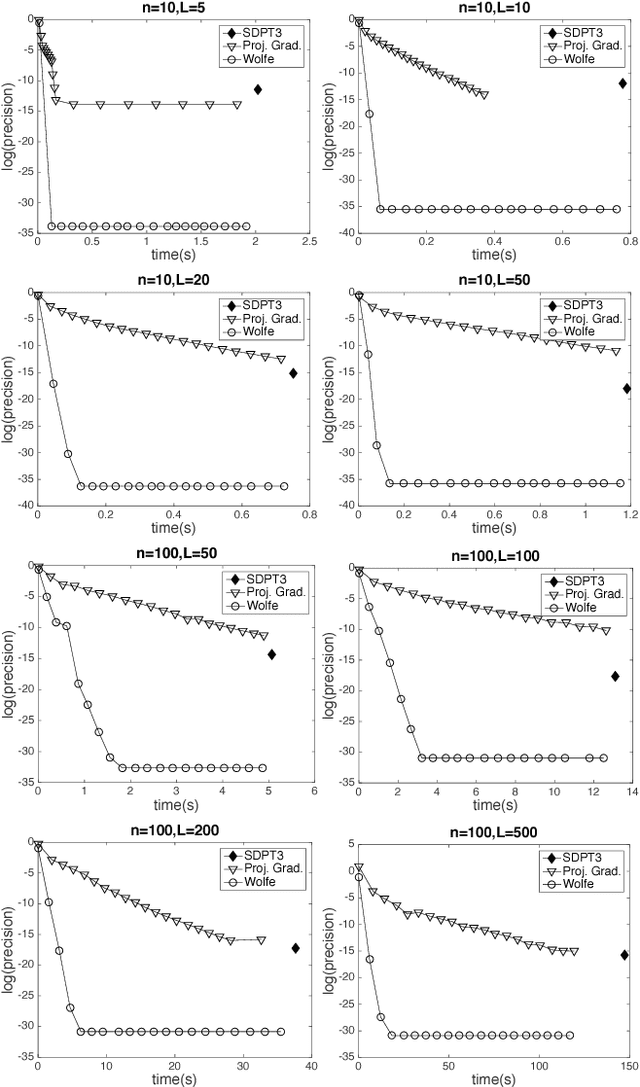
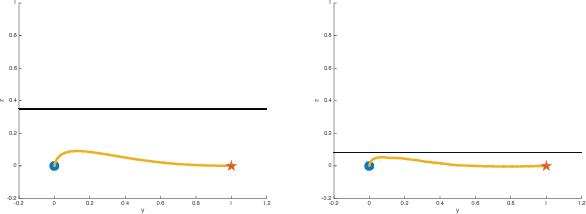
This paper considers the problem of safe mission planning of dynamic systems operating under uncertain environments. Much of the prior work on achieving robust and safe control requires solving second-order cone programs (SOCP). Unfortunately, existing general purpose SOCP methods are often infeasible for real-time robotic tasks due to high memory and computational requirements imposed by existing general optimization methods. The key contribution of this paper is a fast and memory-efficient algorithm for SOCP that would enable robust and safe mission planning on-board robots in real-time. Our algorithm does not have any external dependency, can efficiently utilize warm start provided in safe planning settings, and in fact leads to significant speed up over standard optimization packages (like SDPT3) for even standard SOCP problems. For example, for a standard quadrotor problem, our method leads to speedup of 1000x over SDPT3 without any deterioration in the solution quality. Our method is based on two insights: a) SOCPs can be interpreted as optimizing a function over a polytope with infinite sides, b) a linear function can be efficiently optimized over this polytope. We combine the above observations with a novel utilization of Wolfe's algorithm to obtain an efficient optimization method that can be easily implemented on small embedded devices. In addition to the above mentioned algorithm, we also design a two-level sensing method based on Gaussian Process for complex obstacles with non-linear boundaries such as a cylinder.
Thresholding based Efficient Outlier Robust PCA
Feb 18, 2017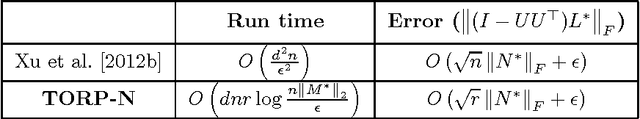
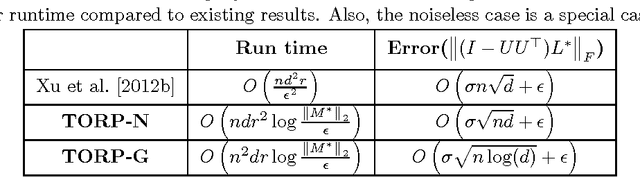
We consider the problem of outlier robust PCA (OR-PCA) where the goal is to recover principal directions despite the presence of outlier data points. That is, given a data matrix $M^*$, where $(1-\alpha)$ fraction of the points are noisy samples from a low-dimensional subspace while $\alpha$ fraction of the points can be arbitrary outliers, the goal is to recover the subspace accurately. Existing results for \OR-PCA have serious drawbacks: while some results are quite weak in the presence of noise, other results have runtime quadratic in dimension, rendering them impractical for large scale applications. In this work, we provide a novel thresholding based iterative algorithm with per-iteration complexity at most linear in the data size. Moreover, the fraction of outliers, $\alpha$, that our method can handle is tight up to constants while providing nearly optimal computational complexity for a general noise setting. For the special case where the inliers are obtained from a low-dimensional subspace with additive Gaussian noise, we show that a modification of our thresholding based method leads to significant improvement in recovery error (of the subspace) even in the presence of a large fraction of outliers.
Nearly-optimal Robust Matrix Completion
Dec 08, 2016

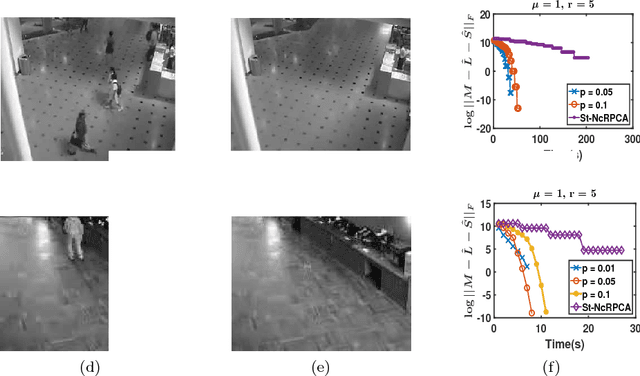
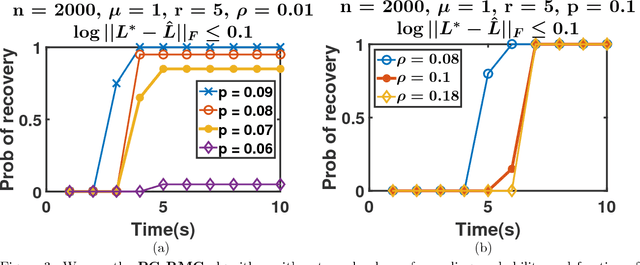
In this paper, we consider the problem of Robust Matrix Completion (RMC) where the goal is to recover a low-rank matrix by observing a small number of its entries out of which a few can be arbitrarily corrupted. We propose a simple projected gradient descent method to estimate the low-rank matrix that alternately performs a projected gradient descent step and cleans up a few of the corrupted entries using hard-thresholding. Our algorithm solves RMC using nearly optimal number of observations as well as nearly optimal number of corruptions. Our result also implies significant improvement over the existing time complexity bounds for the low-rank matrix completion problem. Finally, an application of our result to the robust PCA problem (low-rank+sparse matrix separation) leads to nearly linear time (in matrix dimensions) algorithm for the same; existing state-of-the-art methods require quadratic time. Our empirical results corroborate our theoretical results and show that even for moderate sized problems, our method for robust PCA is an an order of magnitude faster than the existing methods.