 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Consistent Robust Time Series Analysis
Jul 01, 2016
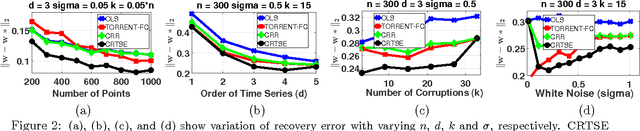
We study the problem of robust time series analysis under the standard auto-regressive (AR) time series model in the presence of arbitrary outliers. We devise an efficient hard thresholding based algorithm which can obtain a consistent estimate of the optimal AR model despite a large fraction of the time series points being corrupted. Our algorithm alternately estimates the corrupted set of points and the model parameters, and is inspired by recent advances in robust regression and hard-thresholding methods. However, a direct application of existing techniques is hindered by a critical difference in the time-series domain: each point is correlated with all previous points rendering existing tools inapplicable directly. We show how to overcome this hurdle using novel proof techniques. Using our techniques, we are also able to provide the first efficient and provably consistent estimator for the robust regression problem where a standard linear observation model with white additive noise is corrupted arbitrarily. We illustrate our methods on synthetic datasets and show that our methods indeed are able to consistently recover the optimal parameters despite a large fraction of points being corrupted.
Regret Bounds for Non-decomposable Metrics with Missing Labels
Jun 07, 2016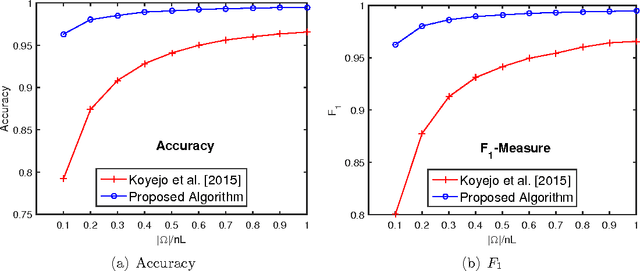
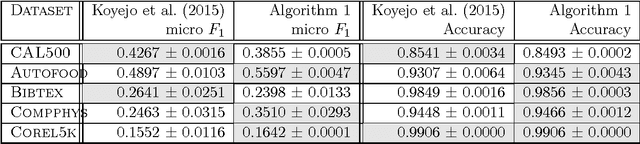
We consider the problem of recommending relevant labels (items) for a given data point (user). In particular, we are interested in the practically important setting where the evaluation is with respect to non-decomposable (over labels) performance metrics like the $F_1$ measure, and the training data has missing labels. To this end, we propose a generic framework that given a performance metric $\Psi$, can devise a regularized objective function and a threshold such that all the values in the predicted score vector above and only above the threshold are selected to be positive. We show that the regret or generalization error in the given metric $\Psi$ is bounded ultimately by estimation error of certain underlying parameters. In particular, we derive regret bounds under three popular settings: a) collaborative filtering, b) multilabel classification, and c) PU (positive-unlabeled) learning. For each of the above problems, we can obtain precise non-asymptotic regret bound which is small even when a large fraction of labels is missing. Our empirical results on synthetic and benchmark datasets demonstrate that by explicitly modeling for missing labels and optimizing the desired performance metric, our algorithm indeed achieves significantly better performance (like $F_1$ score) when compared to methods that do not model missing label information carefully.
Structured Sparse Regression via Greedy Hard-Thresholding
May 27, 2016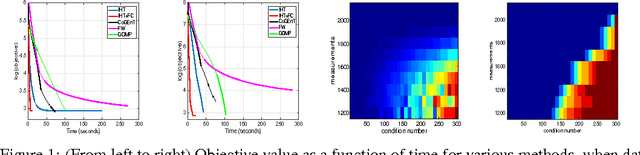
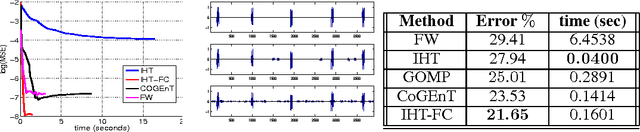
Several learning applications require solving high-dimensional regression problems where the relevant features belong to a small number of (overlapping) groups. For very large datasets and under standard sparsity constraints, hard thresholding methods have proven to be extremely efficient, but such methods require NP hard projections when dealing with overlapping groups. In this paper, we show that such NP-hard projections can not only be avoided by appealing to submodular optimization, but such methods come with strong theoretical guarantees even in the presence of poorly conditioned data (i.e. say when two features have correlation $\geq 0.99$), which existing analyses cannot handle. These methods exhibit an interesting computation-accuracy trade-off and can be extended to significantly harder problems such as sparse overlapping groups. Experiments on both real and synthetic data validate our claims and demonstrate that the proposed methods are orders of magnitude faster than other greedy and convex relaxation techniques for learning with group-structured sparsity.
Tensor vs Matrix Methods: Robust Tensor Decomposition under Block Sparse Perturbations
Apr 27, 2016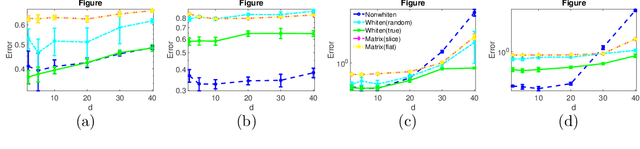
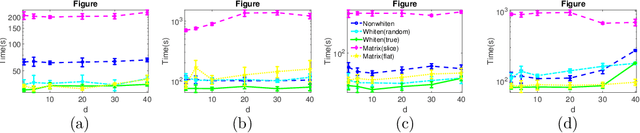

Robust tensor CP decomposition involves decomposing a tensor into low rank and sparse components. We propose a novel non-convex iterative algorithm with guaranteed recovery. It alternates between low-rank CP decomposition through gradient ascent (a variant of the tensor power method), and hard thresholding of the residual. We prove convergence to the globally optimal solution under natural incoherence conditions on the low rank component, and bounded level of sparse perturbations. We compare our method with natural baselines which apply robust matrix PCA either to the {\em flattened} tensor, or to the matrix slices of the tensor. Our method can provably handle a far greater level of perturbation when the sparse tensor is block-structured. This naturally occurs in many applications such as the activity detection task in videos. Our experiments validate these findings. Thus, we establish that tensor methods can tolerate a higher level of gross corruptions compared to matrix methods.
Streaming PCA: Matching Matrix Bernstein and Near-Optimal Finite Sample Guarantees for Oja's Algorithm
Mar 28, 2016
This work provides improved guarantees for streaming principle component analysis (PCA). Given $A_1, \ldots, A_n\in \mathbb{R}^{d\times d}$ sampled independently from distributions satisfying $\mathbb{E}[A_i] = \Sigma$ for $\Sigma \succeq \mathbf{0}$, this work provides an $O(d)$-space linear-time single-pass streaming algorithm for estimating the top eigenvector of $\Sigma$. The algorithm nearly matches (and in certain cases improves upon) the accuracy obtained by the standard batch method that computes top eigenvector of the empirical covariance $\frac{1}{n} \sum_{i \in [n]} A_i$ as analyzed by the matrix Bernstein inequality. Moreover, to achieve constant accuracy, our algorithm improves upon the best previous known sample complexities of streaming algorithms by either a multiplicative factor of $O(d)$ or $1/\mathrm{gap}$ where $\mathrm{gap}$ is the relative distance between the top two eigenvalues of $\Sigma$. These results are achieved through a novel analysis of the classic Oja's algorithm, one of the oldest and most popular algorithms for streaming PCA. In particular, this work shows that simply picking a random initial point $w_0$ and applying the update rule $w_{i + 1} = w_i + \eta_i A_i w_i$ suffices to accurately estimate the top eigenvector, with a suitable choice of $\eta_i$. We believe our result sheds light on how to efficiently perform streaming PCA both in theory and in practice and we hope that our analysis may serve as the basis for analyzing many variants and extensions of streaming PCA.
Locally Non-linear Embeddings for Extreme Multi-label Learning
Jul 09, 2015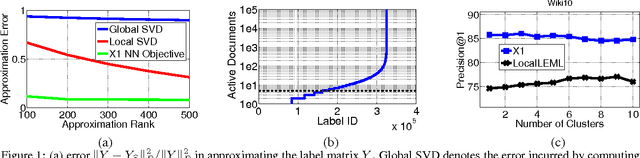
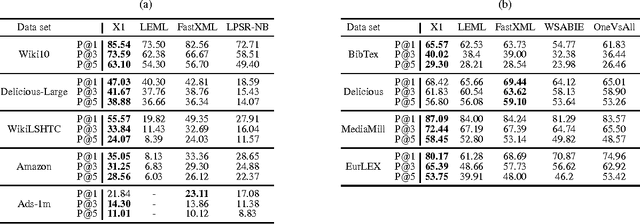

The objective in extreme multi-label learning is to train a classifier that can automatically tag a novel data point with the most relevant subset of labels from an extremely large label set. Embedding based approaches make training and prediction tractable by assuming that the training label matrix is low-rank and hence the effective number of labels can be reduced by projecting the high dimensional label vectors onto a low dimensional linear subspace. Still, leading embedding approaches have been unable to deliver high prediction accuracies or scale to large problems as the low rank assumption is violated in most real world applications. This paper develops the X-One classifier to address both limitations. The main technical contribution in X-One is a formulation for learning a small ensemble of local distance preserving embeddings which can accurately predict infrequently occurring (tail) labels. This allows X-One to break free of the traditional low-rank assumption and boost classification accuracy by learning embeddings which preserve pairwise distances between only the nearest label vectors. We conducted extensive experiments on several real-world as well as benchmark data sets and compared our method against state-of-the-art methods for extreme multi-label classification. Experiments reveal that X-One can make significantly more accurate predictions then the state-of-the-art methods including both embeddings (by as much as 35%) as well as trees (by as much as 6%). X-One can also scale efficiently to data sets with a million labels which are beyond the pale of leading embedding methods.
Phase Retrieval using Alternating Minimization
Jun 12, 2015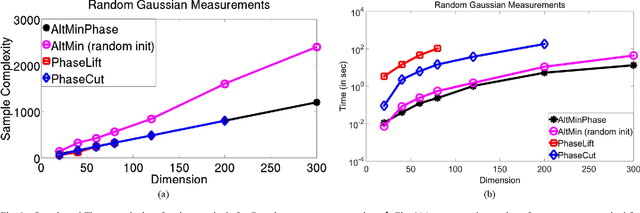
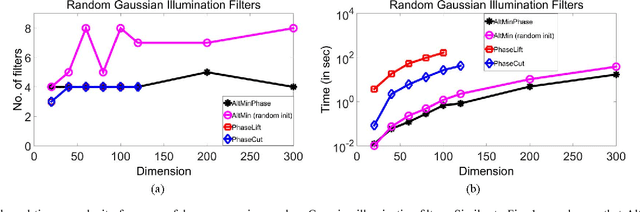
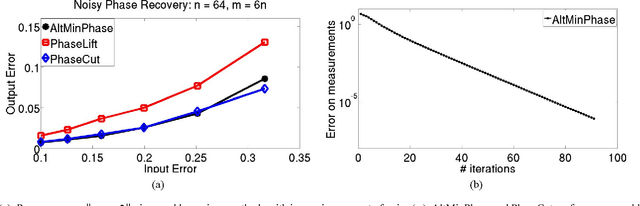

Phase retrieval problems involve solving linear equations, but with missing sign (or phase, for complex numbers) information. More than four decades after it was first proposed, the seminal error reduction algorithm of (Gerchberg and Saxton 1972) and (Fienup 1982) is still the popular choice for solving many variants of this problem. The algorithm is based on alternating minimization; i.e. it alternates between estimating the missing phase information, and the candidate solution. Despite its wide usage in practice, no global convergence guarantees for this algorithm are known. In this paper, we show that a (resampling) variant of this approach converges geometrically to the solution of one such problem -- finding a vector $\mathbf{x}$ from $\mathbf{y},\mathbf{A}$, where $\mathbf{y} = \left|\mathbf{A}^{\top}\mathbf{x}\right|$ and $|\mathbf{z}|$ denotes a vector of element-wise magnitudes of $\mathbf{z}$ -- under the assumption that $\mathbf{A}$ is Gaussian. Empirically, we demonstrate that alternating minimization performs similar to recently proposed convex techniques for this problem (which are based on "lifting" to a convex matrix problem) in sample complexity and robustness to noise. However, it is much more efficient and can scale to large problems. Analytically, for a resampling version of alternating minimization, we show geometric convergence to the solution, and sample complexity that is off by log factors from obvious lower bounds. We also establish close to optimal scaling for the case when the unknown vector is sparse. Our work represents the first theoretical guarantee for alternating minimization (albeit with resampling) for any variant of phase retrieval problems in the non-convex setting.
Robust Regression via Hard Thresholding
Jun 08, 2015


We study the problem of Robust Least Squares Regression (RLSR) where several response variables can be adversarially corrupted. More specifically, for a data matrix X \in R^{p x n} and an underlying model w*, the response vector is generated as y = X'w* + b where b \in R^n is the corruption vector supported over at most C.n coordinates. Existing exact recovery results for RLSR focus solely on L1-penalty based convex formulations and impose relatively strict model assumptions such as requiring the corruptions b to be selected independently of X. In this work, we study a simple hard-thresholding algorithm called TORRENT which, under mild conditions on X, can recover w* exactly even if b corrupts the response variables in an adversarial manner, i.e. both the support and entries of b are selected adversarially after observing X and w*. Our results hold under deterministic assumptions which are satisfied if X is sampled from any sub-Gaussian distribution. Finally unlike existing results that apply only to a fixed w*, generated independently of X, our results are universal and hold for any w* \in R^p. Next, we propose gradient descent-based extensions of TORRENT that can scale efficiently to large scale problems, such as high dimensional sparse recovery and prove similar recovery guarantees for these extensions. Empirically we find TORRENT, and more so its extensions, offering significantly faster recovery than the state-of-the-art L1 solvers. For instance, even on moderate-sized datasets (with p = 50K) with around 40% corrupted responses, a variant of our proposed method called TORRENT-HYB is more than 20x faster than the best L1 solver.
Surrogate Functions for Maximizing Precision at the Top
May 26, 2015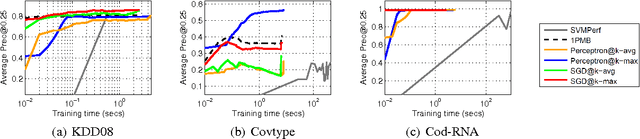
The problem of maximizing precision at the top of a ranked list, often dubbed Precision@k (prec@k), finds relevance in myriad learning applications such as ranking, multi-label classification, and learning with severe label imbalance. However, despite its popularity, there exist significant gaps in our understanding of this problem and its associated performance measure. The most notable of these is the lack of a convex upper bounding surrogate for prec@k. We also lack scalable perceptron and stochastic gradient descent algorithms for optimizing this performance measure. In this paper we make key contributions in these directions. At the heart of our results is a family of truly upper bounding surrogates for prec@k. These surrogates are motivated in a principled manner and enjoy attractive properties such as consistency to prec@k under various natural margin/noise conditions. These surrogates are then used to design a class of novel perceptron algorithms for optimizing prec@k with provable mistake bounds. We also devise scalable stochastic gradient descent style methods for this problem with provable convergence bounds. Our proofs rely on novel uniform convergence bounds which require an in-depth analysis of the structural properties of prec@k and its surrogates. We conclude with experimental results comparing our algorithms with state-of-the-art cutting plane and stochastic gradient algorithms for maximizing prec@k.
* To appear in the the proceedings of the 32nd International Conference on Machine Learning (ICML 2015)
Optimizing Non-decomposable Performance Measures: A Tale of Two Classes
May 26, 2015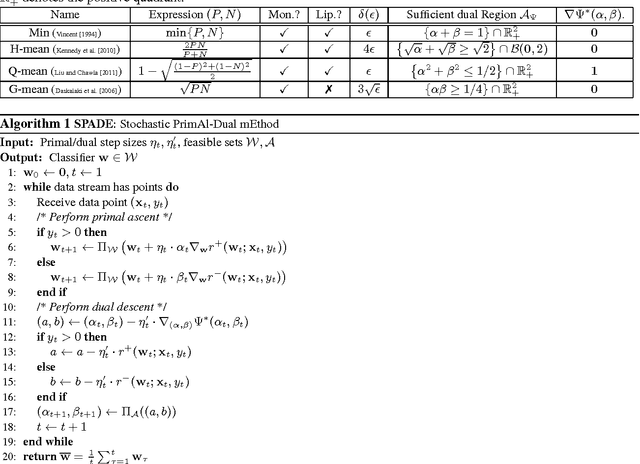



Modern classification problems frequently present mild to severe label imbalance as well as specific requirements on classification characteristics, and require optimizing performance measures that are non-decomposable over the dataset, such as F-measure. Such measures have spurred much interest and pose specific challenges to learning algorithms since their non-additive nature precludes a direct application of well-studied large scale optimization methods such as stochastic gradient descent. In this paper we reveal that for two large families of performance measures that can be expressed as functions of true positive/negative rates, it is indeed possible to implement point stochastic updates. The families we consider are concave and pseudo-linear functions of TPR, TNR which cover several popularly used performance measures such as F-measure, G-mean and H-mean. Our core contribution is an adaptive linearization scheme for these families, using which we develop optimization techniques that enable truly point-based stochastic updates. For concave performance measures we propose SPADE, a stochastic primal dual solver; for pseudo-linear measures we propose STAMP, a stochastic alternate maximization procedure. Both methods have crisp convergence guarantees, demonstrate significant speedups over existing methods - often by an order of magnitude or more, and give similar or more accurate predictions on test data.
* To appear in proceedings of the 32nd International Conference on Machine Learning (ICML 2015)