 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterization of Multi-Model Agentic AI Systems on General Tasks via Trace-Driven Simulation
Jun 01, 2026Agentic AI completes tasks through iterative planning, tool use, and reasoning based on observed outcomes. Despite its popularity, its system-level behavior remains poorly understood, particularly for complex datasets and agent architectures-owing to highly non-deterministic execution, prohibitive evaluation costs, and limited visibility into proprietary models. This paper presents GAIATrace, the first token-level trace dataset of two state-of-the-art agentic systems (MiroThinker and OWL) running GAIA, a benchmark composed of a heterogeneous mix of general-purpose tasks. Unlike prior trace datasets, GAIATrace captures full reasoning tokens, task-level structures, and activities of every major participating LLMs, enabling in-depth systems research. Complementing the dataset, we present Vidur-Agent, a trace-driven simulator that can replay GAIATrace to perform reproducible, low-cost system evaluation across diverse simulated environments. Using both artifacts, we characterize how modern agentic systems handle general tasks and how various system design choices shape their behavior, yielding several unique findings.
The Case for Claim Difficulty Assessment in Automatic Fact Checking
Sep 20, 2021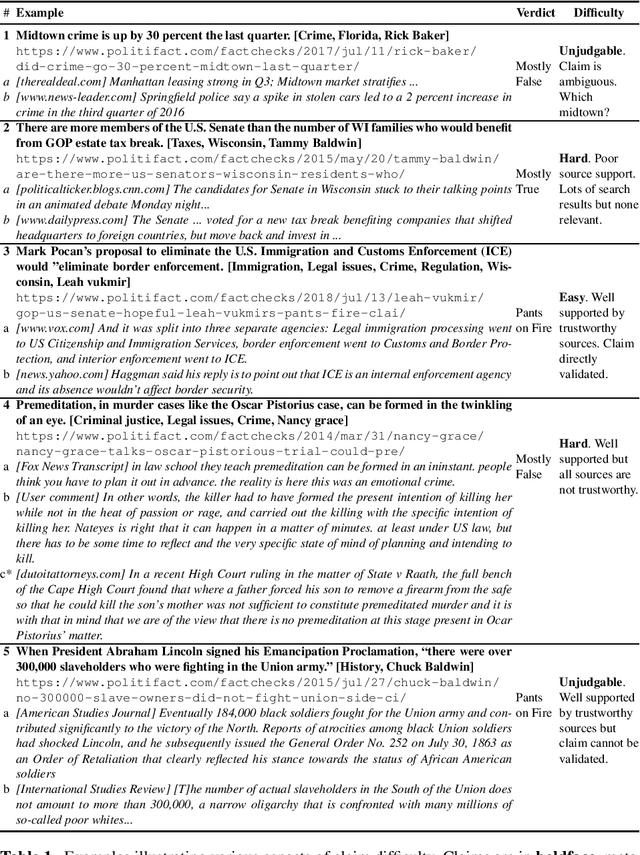
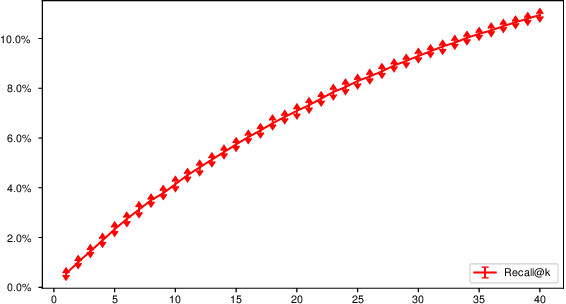
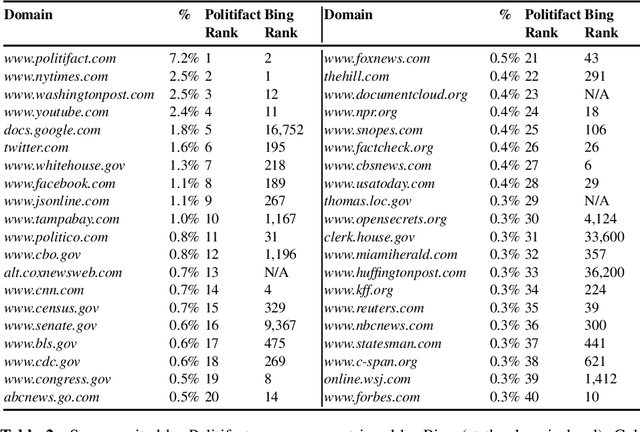

Fact-checking is the process (human, automated, or hybrid) by which claims (i.e., purported facts) are evaluated for veracity. In this article, we raise an issue that has received little attention in prior work - that some claims are far more difficult to fact-check than others. We discuss the implications this has for both practical fact-checking and research on automated fact-checking, including task formulation and dataset design. We report a manual analysis undertaken to explore factors underlying varying claim difficulty and categorize several distinct types of difficulty. We argue that prediction of claim difficulty is a missing component of today's automated fact-checking architectures, and we describe how this difficulty prediction task might be split into a set of distinct subtasks.